Look Before You Leap: Autonomous Exploration for LLM Agents
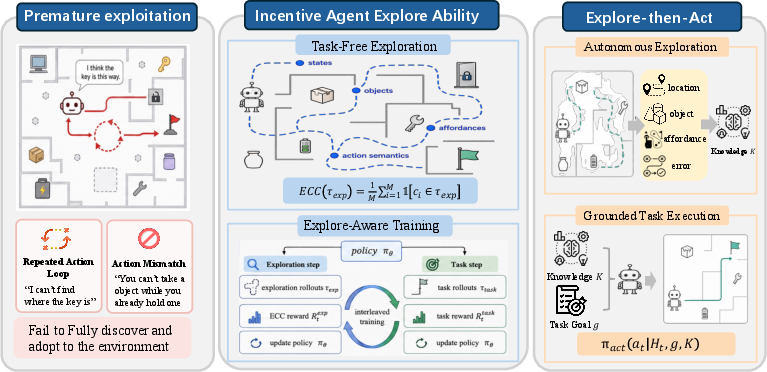
Abstract: LLM based agents often fail in unfamiliar environments due to premature exploitation: a tendency to act on prior knowledge before acquiring sufficient environment-specific information. We identify autonomous exploration as a critical yet underexplored capability for building adaptive agents. To formalize and quantify this capability, we introduce Exploration Checkpoint Coverage, a verifiable metric that measures how broadly an agent discovers key states, objects, and affordances. Our systematic evaluation reveals that agents trained with standard task-oriented reinforcement learning consistently exhibit narrow and repetitive behaviors that impede downstream performance. To address this limitation, we develop a training strategy that interleaves task-execution rollouts and exploration rollouts, with each type of rollout optimized by its corresponding verifiable reward. Building on this training strategy, we propose the Explore-then-Act paradigm, which decouples information-gathering from task execution: agents first utilize an interaction budget to acquire grounded environmental knowledge, then leverage it for task resolution. Our results demonstrate that learning to systematically explore is imperative for building generalizable and real-world-ready agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI “agents” (powered by LLMs) to explore new places before trying to solve tasks there. The authors show that many current agents rush in and act based on guesses from past experience, which often makes them fail in unfamiliar situations. They propose a way to measure and train exploration so agents first learn the lay of the land, then use that knowledge to do the job better.
What questions did the researchers ask?
- Can we measure how well an AI explores a new environment (like a virtual house, lab, or game) before doing a task?
- Do today’s agents, which are mostly trained to finish tasks directly, actually explore well?
- If we train agents to explore on purpose, will they do better on tasks—especially in new or changed environments?
- Is it helpful to split the process into two parts: first explore, then act?
How did they study it?
Think of an AI agent like a smart helper dropped into a new building. It needs to figure out the rooms, doors, tools, and rules before it can complete a mission.
Here’s the approach, in everyday terms:
- Measuring exploration (ECC): The authors invent Exploration Checkpoint Coverage (ECC). Imagine a scavenger hunt with a list of “checkpoints”—important places, objects, and actions to discover (like “find the kitchen,” “figure out how to open the toolbox,” “learn which switch turns on the light”). ECC is the score: how many checkpoints did the agent find during its free exploration time?
- Training for exploration: Instead of only rewarding the agent when it completes the task, the authors also give it points for good exploration (high ECC). They use a training method similar to grading on a curve in a group: an agent gets more credit when it explores better than the others sampled at the same time. This makes it learn patterns that uncover more of the environment.
- Interleaved practice: The agent alternates between two kinds of practice:
- Task practice: Try to complete missions and get rewarded for success.
- Exploration practice: Roam around with no specific mission and get rewarded for finding more checkpoints.
- Mixing both helps the agent learn to explore and to solve tasks.
- Explore-then-Act: At test time, the agent first spends some steps exploring (like touring a new school before the first day of class), writing down what it learned (a short “knowledge summary”). Then it uses that summary to solve the task. This separates “learning the environment” from “doing the mission.”
They tested this on three text-based worlds:
- ALFWorld: a virtual home where you navigate rooms and use objects.
- ScienceWorld: a science-themed world where you discover rules and cause-effect.
- TextCraft: a resource and crafting game with hidden recipes.
What did they find, and why is it important?
Key findings:
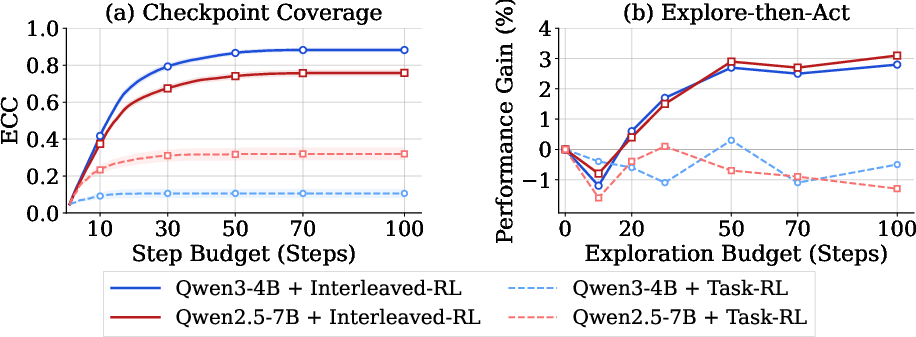
- Task-only training leads to shallow exploration. Many agents repeat the same actions, get stuck in loops, or stop early. Their ECC scores are low, meaning they miss important places, objects, and rules. This makes them fragile in new situations.
- Just exploring randomly isn’t enough—but training with an exploration reward helps a lot. When agents were explicitly trained to explore (using ECC), they discovered more checkpoints and later performed better on tasks.
- Explore-then-Act works when the agent is good at exploring. If the agent explores poorly, the “knowledge” it collects is noisy and can even hurt performance. But after exploration-focused training, Explore-then-Act consistently boosts success rates.
- Better behavior even without a separate exploration phase. Agents trained to explore became less repetitive, more curious, and better at recovering from mistakes, which also improved direct task performance.
- More robust to changes. In trickier versions of environments (objects moved, rules tweaked), exploration-trained agents handled surprises better than task-only agents.
Why this matters:
- Real-world environments change. You can’t pre-encode all knowledge into the model ahead of time. Agents must learn to learn—gathering fresh, grounded information on the fly.
- A clear metric (ECC) lets researchers track and improve exploration, not just final task success.
- Splitting “look first” and “act later” makes agents more reliable and adaptable.
What could this change in the future?
- More adaptable assistants and robots: From web-browsing helpers to home robots, agents could first investigate what’s available, what’s allowed, and how things work, then use that knowledge to act safely and effectively.
- Better training recipes: Mixing exploration and task practice could become standard, leading to agents that handle new apps, tools, or interfaces without retraining.
- Fairer evaluations: With ECC, we can compare agents on how well they understand new environments, not just how often they guess right.
- Stronger generalization: Agents that learn to explore can handle surprises, making them more trustworthy in real-life, ever-changing settings.
In short, the paper argues that “look before you leap” isn’t just good advice for people—it’s essential for AI agents too. By measuring and training exploration, agents become smarter, more flexible, and better at solving tasks in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves missing, uncertain, or unexplored so future researchers can act on them:
- ECC design and generality: How to automatically construct exploration checkpoints in new environments without manual engineering; how to ensure checkpoints are task-relevant and not biased toward curated tasks; how ECC correlates with downstream task success across domains; how to adapt ECC to continuous, partially observable, or multimodal (GUI, web, robotics) environments.
- Verifiability at scale: How to instrument real-world environments (web/GUI/OS/robots) to provide verifiable ECC signals without bespoke scaffolding; methods for programmatic checkpoint discovery/verification when environment internals are inaccessible.
- Reward hacking and metric robustness: Whether policies can game ECC (e.g., cheaply “touching” checkpoints without meaningful understanding); mechanisms (e.g., novelty penalties, anti-loop checks, temporal consistency tests) to prevent superficial coverage.
- Comparative baselines for exploration: Missing head-to-head evaluations against established intrinsic objectives (curiosity, RND, ICM, empowerment, information gain, count-based novelty) and hybrid approaches; ablations isolating ECC’s contribution vs. generic diversity-seeking.
- Theory and guarantees: Lack of formal analysis linking ECC coverage to task success or sample complexity; conditions under which explore-then-act provides provable benefits over direct execution.
- Interleaving schedule design: How to adaptively tune the task:exploration rollout ratio beyond the fixed 5:1 (e.g., automatic scheduling, curriculum learning, environment- or episode-conditional ratios); analysis of stability, convergence, and interference between the two objectives.
- RL algorithm choices: Whether alternative algorithms (PPO/AWR/IMPALA/off-policy with replay) improve sample efficiency or stability over GRPO; impact of group size, reward normalization, KL weight, and reference model selection on exploration competence.
- Adaptive exploration budgeting: How to learn when to stop exploring (budget N) and switch to acting via confidence/uncertainty estimates, value-of-information, or learned stopping rules; online arbitration between explore/exploit within an episode.
- Knowledge summarization (K) reliability: Concrete methods for building, verifying, and using K (structured graphs vs. free text); mitigating hallucinations and contradictions; automatic validation against the environment; ablations on representation, size, and retrieval strategies.
- Context and memory constraints: How to compress, store, and retrieve exploration knowledge without exceeding context limits; integration of external memory, vector databases, or episodic memory modules; policies for long-horizon or multi-episode knowledge accumulation.
- Robustness beyond textual simulators: Extending evaluation to multimodal, stochastic, and dynamically changing environments (web, GUI, OS, real robots); handling noisy observations, non-determinism, and delayed/partial observability.
- Safety-aware exploration: Incorporating risk-sensitive objectives, constraint enforcement, and safe-to-explore sets to prevent destructive or irreversible actions during the exploration phase.
- Task-relevance of exploration: Mechanisms to bias exploration toward affordances most predictive of future tasks (e.g., task-conditioned ECC variants, posterior sampling of task distributions), avoiding exhaustive but irrelevant coverage.
- Lifelong and cross-episode learning: Persisting environment knowledge across tasks/users/sessions; strategies for continual learning, consolidation, and avoiding catastrophic forgetting of exploration skills and world models.
- Action-semantic grounding: Methods for autonomously inferring action schemas, tool arguments, and preconditions from interaction traces (e.g., schema induction, program synthesis), beyond just covering checkpoints.
- Executor-agnostic utility: The paper measures E-t-A gains with a fixed executor; open question whether exploration knowledge transfers to diverse executors/backbones, tool-use stacks, or planning frameworks.
- Sensitivity and reproducibility: Systematic sensitivity analyses for ECC weighting, exploration group size, random seeds, and sampling temperature; reporting variance and statistical significance of performance gains.
- Efficiency and cost-benefit tradeoffs: Modeling the compute/latency cost of exploration vs. task gains; learning cost-aware policies that optimize expected success per unit budget or wall-clock time.
- Multi-agent exploration: Potential benefits of parallel or coordinated explorers sharing partial maps/affordances; protocols for merging and de-duplicating knowledge from multiple agents.
- Curriculum and checkpoint acquisition: Automated curricula that gradually increase environment complexity or checkpoint density; bootstrapping ECC from weak signals when no checkpoints exist initially (e.g., self-discovered landmarks).
- Robustness to perturbations and adversarial affordances: Stress tests with misleading cues, distractors, or adversarially perturbed semantics; defenses to maintain exploration utility under hostile or shifting conditions.
- Post-exploration verification loops: Online procedures to detect low-quality or misleading K and trigger targeted re-exploration or counterfactual checks before acting.
- Downstream integration strategies: Beyond prompt injection, investigating learned adapters, planning modules, or retrieval-augmented policies that explicitly condition on K; comparative study of integration mechanisms.
- Evaluation coverage: Expanding benchmarks beyond ALFWorld, ScienceWorld, and TextCraft; standardized suites for exploration quality and E-t-A utility with public ECC definitions to enable cross-paper comparisons.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today by adapting the paper’s Explore-then-Act paradigm, ECC metric, and interleaved exploration training in environments where checkpoints (states, objects, affordances) can be defined and verified (e.g., web/GUI, APIs, simulated backends).
- Bold title — sectors
- What it enables
- Tools/products/workflows
- Assumptions/dependencies
- Robust RPA/WebAgent “dry-run” before execution — software, e-commerce, travel, finance
- What: Run an exploratory session on a website or internal tool to discover forms, buttons, valid arguments, and error states before performing a transaction (booking, checkout, claim submission). Use the learned knowledge K to reduce live errors.
- Tools/workflows: Explore-then-Act mode in RPA; an Exploration Knowledge Cache injected into prompts; ECC-Tracker to verify coverage of UI elements and tool arguments.
- Assumptions: Safe sandbox or staging environment; UI instrumented to expose verifiable checkpoints (e.g., DOM roles, API parameter schemas); limited drift between exploration and action; interaction budget k acceptable for latency/cost.
- ECC-gated release and regression testing for agent products — software/MLOps
- What: Add ECC as a verifiable coverage metric in CI/CD to catch regressions (e.g., agent covers fewer UI affordances after a model or prompt change).
- Tools/workflows: ECC dashboards, ECC-based failing criteria, PR checks, synthetic exploration test suites.
- Assumptions: Stable checkpoint specs per environment; replayable test harness; logging to compute ECC.
- Rapid onboarding to new SaaS tools for enterprise copilots — productivity, enterprise IT
- What: Copilots explore a newly adopted SaaS (CRM, HRIS) to learn page layouts, entity types, constraints (required fields), then guide users and automate flows reliably.
- Tools/workflows: Automated first-run “explore” jobs; knowledge K stored per tenant; retrieval-augmented prompts using K.
- Assumptions: Staging accounts; instrumentation for checkpoints (e.g., API introspection); privacy controls for exploration data.
- API/tool-use acclimation in customer support bots — customer service, software
- What: Before handling tickets, a bot explores internal tooling to learn function arguments, rate limits, and error codes; it uses K to reduce action-environment mismatches.
- Tools/workflows: Pre-shift exploration budget; ECC-based readiness score; fallback to human if ECC below threshold.
- Assumptions: Test endpoints or mock servers; verifiable affordances (API specs, contract tests); auditable logs.
- Safer change management for DevOps runbooks — IT operations, cloud
- What: Agents explore clusters or dashboards to verify current states (deployments, config maps, permissions) before executing runbooks, lowering risk of repeated invalid actions.
- Tools/workflows: Explore-first operational playbooks; ECC checkpoints tied to K8s/Cloud API resources; auto-generation of K injected into incident workflows.
- Assumptions: Read-only exploration permissions; deterministic or bounded-stochastic control-plane responses; well-defined checkpoints.
- Supplier portal and marketplace automation — e-commerce, supply chain
- What: Explore portals to discover required artifacts (file formats, mandatory metadata), available actions, and submission constraints; only then submit listings or invoices.
- Tools/workflows: Portal-specific exploration policies; ECC verification of affordances (upload endpoints, validators); reuse K across similar portals.
- Assumptions: Sandbox vendor accounts; consistent affordance identifiers; bounded portal variability.
- Security surface mapping and red teaming — security
- What: Exploration agents enumerate UI routes, tool entry points, and error states to improve coverage prior to fuzzing or policy checks; ECC used as an objective proxy for breadth.
- Tools/workflows: “Explorer-first” scanners; ECC coverage reports; feeds to DAST/SAST prioritization.
- Assumptions: Legal authorization and proper scoping; non-destructive exploration; sanitized logging.
- Education and training for exploration strategies — education, academia
- What: Use ECC to teach/grade exploration vs. exploitation trade-offs in agentic labs; students design checkpoints and measure coverage gains from strategy changes.
- Tools/workflows: Classroom sandboxes (TextWorld/WebArena-like); ECC rubrics; side-by-side “direct” vs. “Explore-then-Act” assignments.
- Assumptions: Accessible simulated environments; clear checkpoint schemas; instructor-provided harness.
- Agent evaluation benchmarks and leaderboards with ECC — academia, MLOps
- What: Publish ECC-driven benchmarks to compare exploration capability independent of task completion; report E-t-A deltas as a robustness indicator.
- Tools/workflows: Open ECC generators; standard logs-to-ECC pipelines; leaderboard metadata for ECC and E-t-A gains.
- Assumptions: Community consensus on checkpoint definitions; reproducible environment seeds; transparent verifiable rewards.
- “Explorer-as-a-Service” microservice in agent stacks — software platforms
- What: Decouple an explorer policy from the executor; expose an API that returns K and ECC scores for any target environment; executors consume K to act.
- Tools/workflows: Service orchestration (explore → summarize → cache → serve K); budget k tuning per environment; interleaved GRPO training jobs.
- Assumptions: Multi-tenant isolation; cost and latency budgets; standardized environment descriptors to trigger the right explorer.
- ECC-driven prompt and policy tuning — software/MLOps
- What: Optimize prompts or policies to improve ECC (and reduce loop/repetition rates) before optimizing for end-task success, yielding more robust direct execution.
- Tools/workflows: A/B tuning with ECC as primary metric; loop/repetition/error-recovery diagnostics from the paper; automatic early stopping on diminishing ECC returns.
- Assumptions: Inexpensive exploration data collection; correlation between ECC and downstream performance in target domain.
Long-Term Applications
These use cases extend the paper’s ideas to high-stakes, partially observable, continuous, or physical environments. They require further research on checkpoint design, safety, sensing, and scaling interleaved training beyond text-based settings.
- Bold title — sectors
- What it enables
- Tools/products/workflows
- Assumptions/dependencies
- Home and warehouse robotics that “look before acting” — robotics, logistics
- What: Robots allocate an exploration budget to discover room layouts, object locations/affordances, and task preconditions before manipulation; K guides task policy.
- Tools/workflows: ECC generalized to continuous state/spatial checkpoints (e.g., pose grids, grasp affordances); sim-to-real training with interleaved objectives.
- Assumptions: Reliable sensing (vision/tactile), safe exploratory motions, verifiable physical checkpoints, on-board compute or edge connectivity.
- Clinical software copilots exploring EHR workflows — healthcare, health IT
- What: Copilots explore EHR modules (orders, prior auth, formulary constraints) in sandbox mode to build K, then execute under clinician supervision.
- Tools/workflows: Strict audit trails, exploration whitelists, ECC for compliance-critical affordances; human-in-the-loop approvals.
- Assumptions: De-identified/sandboxed EHRs, regulatory clearance, robust PHI governance, high verifiability of checkpoints.
- Autonomous vehicle (AV) planning with exploration budgets — transportation
- What: AV stack allocates micro-exploration (simulation rollouts or conservative probing) to infer affordances (lane rules, construction patterns) in novel locales; K informs routing/policies.
- Tools/workflows: ECC over simulated scenario banks; Explore-then-Act across digital twins; regulatory-grade logging.
- Assumptions: High-fidelity sim-twins, safe on-road probing constraints, rigorous safety cases; translation of ECC from discrete to continuous dynamics.
- Automated labs for scientific discovery — science, pharma
- What: Agents explore instruments, protocols, and parameter spaces to learn constraints and failure modes; use K to design robust experiments.
- Tools/workflows: ECC for instrument affordances and state transitions; interleaved training across simulators and low-throughput wet labs.
- Assumptions: Reliable lab simulators; safe automated exploration; checkpoints tied to measurable lab states/outcomes.
- Industrial control and SCADA assistants — energy, manufacturing
- What: Agents explore HMIs/SCADA in digital twins to build K of devices, interlocks, alarm semantics; then perform supervised operational tasks.
- Tools/workflows: Twin-first Explore-then-Act; ECC on alarms, setpoints, permissives; strict execution gating policies.
- Assumptions: High-fidelity twins; safety certification; OT network constraints; robust fail-safes.
- Exchange/trading infrastructure acclimation — finance
- What: Agents explore new exchanges (testnets) to learn order types, rate-limits, margin rules, and error codes; K reduces failed orders in production.
- Tools/workflows: ECC for API/market-state affordances; Explore-then-Act with sandboxes; audit and compliance hooks.
- Assumptions: Access to testnets/mock markets; regulatory sign-off; formalized checkpoints from API contracts.
- Grid operations and DER orchestration — energy
- What: Explore feeder topology, device capabilities, and control constraints in sims to learn K before load-shifting or DER dispatch.
- Tools/workflows: ECC over network components/constraints; policy training with interleaved exploration; contingency sims.
- Assumptions: Trusted grid simulators; secure access; alignment with reliability standards.
- Procurement and policy standards for adaptive agents — policy, governance
- What: Specify ECC thresholds and E-t-A gains as procurement requirements for agentic systems in public services; mandate exploration logs for audits.
- Tools/workflows: Certification checklists (ECC ≥ X%, loop rate ≤ Y%); audit pipelines for K artifacts and exploration trajectories.
- Assumptions: Broad acceptance of ECC-like metrics; standardized benchmarks; oversight capacity.
- OS-level personal assistants that map new apps — consumer software
- What: Assistants explore newly installed apps to learn commands, file permissions, and UI flows; K enables safe cross-app automations.
- Tools/workflows: Per-app exploration manifests; ECC for permission and action coverage; privacy-preserving knowledge caches.
- Assumptions: OS sandboxing; app-provided descriptors; user consent and policy controls.
- Multi-agent “Explorer + Executor” marketplaces — platforms
- What: Specialized explorer agents offer K as a service to many executors; pricing by ECC achieved and staleness of K.
- Tools/workflows: Market APIs; K versioning and TTL; SLA bound on ECC and freshness.
- Assumptions: Standard environment descriptors; trust and billing infra; privacy and IP handling for K.
- Auto-curriculum and continual adaptation for agents — software/AutoML
- What: Use ECC rewards to generate curricula and tune exploration budgets; periodically re-explore to track environment drift and refresh K.
- Tools/workflows: Drift detectors triggering re-exploration; scheduled interleaved training; ECC-based early stopping.
- Assumptions: Cost-effective retraining; drift observability; stable correlations between ECC and task performance.
- Safety case development for high-stakes autonomy — cross-sector
- What: Integrate ECC and exploration diagnostics (loop rate, error recovery) into formal safety arguments that the system acquires sufficient situational awareness before acting.
- Tools/workflows: Safety monitors that require ECC thresholds prior to enabling high-risk actions; model cards reporting E-t-A gains and diagnostics.
- Assumptions: Accepted safety frameworks that recognize exploration evidence; rigorous telemetry; domain-specific risk thresholds.
Cross-cutting dependencies and risks to feasibility
- Verifiable checkpoints: Defining ECC requires instrumented environments with programmatically checkable states/affordances; in physical/continuous domains, this needs new representations and sensors.
- Safe exploration: Sandbox or digital twins are ideal; in live systems, bounded probing and strong guardrails are mandatory.
- Interaction budget and latency: Explore-then-Act adds cost/latency; ROI depends on fewer failures vs. extra steps.
- Training pipeline: Interleaved GRPO or similar RLVR infrastructure, reproducible rollouts, and KL-regularized updates are needed to realize gains.
- Knowledge management: Summaries K must be accurate, fresh, and privacy-preserving; staleness can invert benefits (as shown for too-small budgets).
- Generalization limits: ECC improvements correlate with task gains in studied environments; validation is needed per domain to avoid overfitting exploration to surrogate checkpoints.
Glossary
- Action preconditions: Constraints that must be satisfied before an action can succeed in an environment. "with modifications to object locations, interaction preconditions, and distractor objects"
- Affordances: The possible actions or interactions an environment or object enables for an agent. "we introduce Exploration Checkpoint Coverage, a verifiable metric that measures how broadly an agent discovers key states, objects, and affordances."
- ALFWorld: A text-based household environment used to evaluate embodied agents on navigation and manipulation tasks. "We conduct experiments across three diverse interactive environments: ALFWorld~\citep{alfworld}, SciWorld~\citep{scienceworld}, TextCraft~\citep{agentgym}, and a challenging ALFWorld variant."
- Autonomous exploration: Goal-free, proactive information gathering by an agent to learn an unfamiliar environment’s structure and dynamics. "We identify autonomous exploration as a critical yet underexplored capability for building adaptive agents."
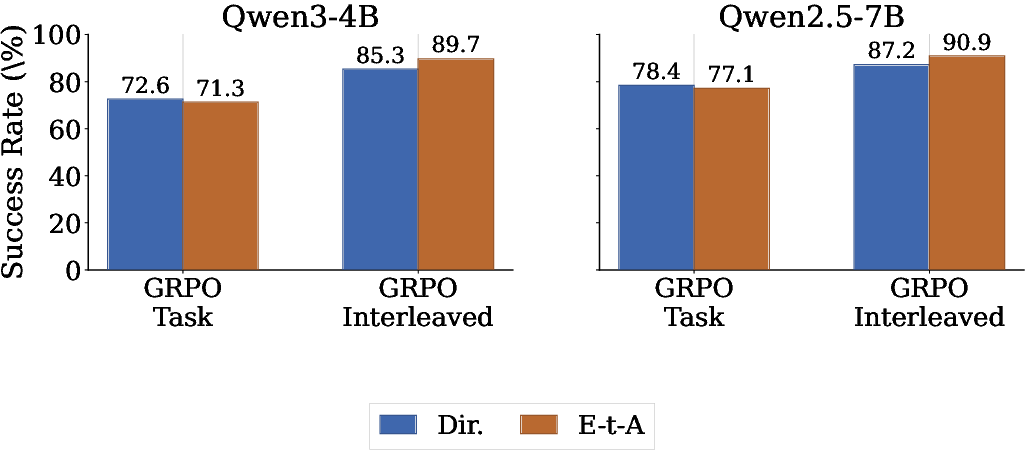
- Direct Execution (Dir.): An evaluation paradigm where the agent attempts tasks without a preceding exploration phase. "Models are evaluated under two execution paradigms: Direct Execution (Dir.) and Explore-then-Act (E-t-A)."
- Distractor objects: Irrelevant or misleading items in the environment that can confuse agents during tasks. "with modifications to object locations, interaction preconditions, and distractor objects"
- Distributional shifts: Changes between training and deployment data distributions that can degrade agent performance. "Consequently, they remain susceptible to premature exploitation when subjected to distributional shifts."
- Environment-specific semantics: Context-dependent meanings and rules (e.g., tool arguments, UI behavior) that govern actions in a particular environment. "the agent might misinterpret environment-specific semantics, such as specific tool arguments or UI affordances"
- Exploration Checkpoint Coverage (ECC): A verifiable metric measuring how many predefined environment checkpoints (facts/affordances) an agent discovers. "we introduce Exploration Checkpoint Coverage (ECC), a verifiable metric that quantifies the extent to which an agent discovers key states, objects, and affordances in an unfamiliar environment."
- Exploration checkpoints: Predefined, verifiable environment facts or affordances that indicate successful discovery during exploration. "For each environment instance, we define a finite set of exploration checkpoints"
- Exploration rollouts: Trajectories generated during a goal-free exploration phase, optimized to maximize exploration metrics like ECC. "interleaves task-execution rollouts and exploration rollouts, with each type of rollout optimized by its corresponding verifiable reward."
- Exploration-aware training: Training that explicitly optimizes for exploration objectives (e.g., ECC), not just task completion. "Given that optimizing for task-specific rewards is insufficient for fostering exploration, we investigate whether reinforcement learning with explicit exploration-aware objectives can instill autonomous exploratory capabilities."
- Explore-then-Act paradigm: A two-stage protocol where the agent first explores to acquire knowledge, then uses that knowledge to execute the task. "we propose the Explore-then-Act paradigm, which decouples information-gathering from task execution"
- Extrinsic task rewards: External, task-defined reward signals given upon successful task completion, as opposed to intrinsic exploration signals. "evaluated solely by extrinsic task rewards."
- Group Relative Policy Optimization (GRPO): A policy optimization method that normalizes rewards within sampled groups to compute relative advantages for stable RL training. "We adapt the Group Relative Policy Optimization (GRPO) framework to directly reward exploration"
- Interaction budget: A fixed number of steps an agent is allowed to interact with the environment during exploration or execution. "agents first utilize an interaction budget to acquire grounded environmental knowledge"
- KL penalty: A regularization term that penalizes divergence from a reference policy to stabilize learning. "regularized by a KL penalty to maintain stability with respect to a reference model"
- Latent transition dynamics: The underlying probabilistic rules governing how states evolve in response to actions. "build an internal model of the environment's latent transition dynamics "
- Policy-gradient methods: Reinforcement learning algorithms that adjust policy parameters directly via gradients of expected returns. "agents are optimized via policy-gradient methods based on task-completion rewards."
- Premature exploitation: The tendency of agents to commit early to familiar actions based on priors without sufficient exploration. "current LLM-based agents often exhibit a pattern of premature exploitation."
- ReAct-style loop: An inference pattern that interleaves reasoning and acting steps under a unified goal-directed policy. "A canonical instantiation of this approach is the ReAct-style loop"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL framework where rewards are computed from objectively verifiable signals rather than subjective judgments. "With the advancement of Reinforcement Learning with Verifiable Rewards (RLVR), models have made substantial progress"
- Rollout: A sampled trajectory of observations and actions generated by a policy during interaction with the environment. "For an exploration-focused training step, we define the reward for a rollout as its Exploration Checkpoint Coverage"
- State space: The set of all possible states in an environment, including layouts and available items. "state space (e.g., map layout, available items)"
- Task-execution rollouts: Goal-directed trajectories generated to solve specified tasks and optimized using task-completion rewards. "interleaves task-execution rollouts and exploration rollouts, with each type of rollout optimized by its corresponding verifiable reward."
- Task-oriented training: Training focused solely on maximizing task reward, often at the expense of exploration. "We systematically demonstrate that task-oriented training, fails to reliably yield autonomous exploration."
- Training-time priors: Knowledge or biases learned during training that influence an agent’s behavior at deployment. "actions derived from training-time priors"
- Verifiable reward: A reward computed from environment-grounded, objectively checkable signals (e.g., ECC), rather than subjective evaluation. "with each type of rollout optimized by its corresponding verifiable reward."
Collections
Sign up for free to add this paper to one or more collections.

