- The paper introduces a continuous memory system, CoMEM, enabling vision-language models to encode external knowledge as dense, compressed embeddings.
- CoMEM leverages a lightweight Q-Former and updates only 1.2% of parameters, achieving 80× compression and significant accuracy gains across benchmarks.
- CoMEM demonstrates practical plug-and-play integration for multimodal and multilingual reasoning, outperforming discrete token-based retrieval methods.
General Continuous Memory for Vision-LLMs: A Technical Overview
Vision-LLMs (VLMs) have achieved notable progress in multimodal reasoning tasks but remain limited when reasoning requires integrating complex, multimodal or multilingual knowledge. Existing retrieval-augmented generation (RAG) paradigms concatenate retrieved image and text tokens, escalating input context length and degrading model performance due to token overload. Token pruning methods are prone to loss of essential information and incomplete context. This paper proposes a fundamentally different approach: representing external knowledge as a compact set of continuous multimodal embeddings. The key insight is that a VLM can serve as its own continuous memory encoder, leveraging its cross-modal semantic alignment and compressibility. This design enables efficient storage and retrieval, minimizes training overhead, and offers plug-and-play compatibility with downstream tasks, addressing both scalability and generalization.
CoMEM Architecture and Training Recipe
The proposed method, CoMEM (Continuous Memory for VLMs), uses a VLM paired with a lightweight Q-Former to encode retrieved vision-language knowledge items into dense continuous embeddings. Each multimodal knowledge item (image-text pair) is encoded by the VLM, and the Q-Former compresses these representations to just 8 continuous vectors per item, corresponding to an 80× compression over typical token counts.
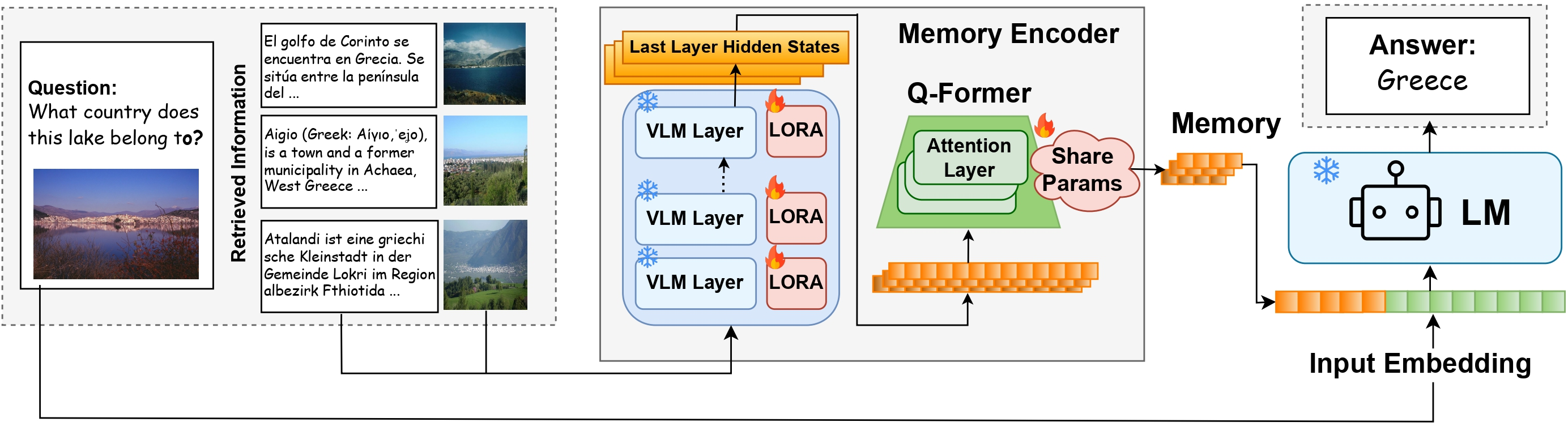
Figure 1: Overview of the CoMEM architecture encoding retrieved multimodal knowledge into dense memory embeddings, which are prepended to a frozen VLM for answer generation.
CoMEM's memory encoder is fine-tuned in a data- and parameter-efficient manner: only 1.2% of total parameters are updated, using merely 15.6k self-synthesized multimodal and multilingual samples. The VLM remains frozen at inference, ensuring semantic compatibility and transferability. Memory embeddings are directly prepended to input representations, enabling seamless augmentation without architecturally altering the inference-time VLM.
Empirical Analysis: Compressibility and Semantic Alignment
The empirical evaluation demonstrates that VLMs can effectively serve as their own memory encoders. Extracted continuous embeddings retain key information and outperform discrete token-based RAG methods under high compression rates. Specifically, using attention-based strategies to select a small subset of embeddings achieves significant gains in complex reasoning benchmarks. This verifies both the semantic alignment and robust compressibility of continuous VLM-generated memory.
Experimental Results
CoMEM is evaluated on six multimodal reasoning benchmarks (InfoSeek, OVEN, MRAG-Bench, OK-VQA, A-OKVQA, ViQuAE) and two multilingual benchmarks (CVQA and multilingual InfoSeek), measuring performance across diverse linguistic and visual contexts. Compared to both vanilla VLMs, RAG-augmented models, and advanced retrieval approaches, CoMEM consistently delivers superior accuracy, with average improvements of +8.0% (Qwen2-Instruct-VL) and +7.7% (Qwen2.5-Instruct-VL) in English, and +5.1%/+4.3% in multilingual settings. Gains are especially pronounced for low-resource languages (e.g., Bulgarian, Russian), validating the method's cross-lingual robustness.

Figure 2: Case studies comparing answer quality and reasoning depth of CoMEM versus baseline VLM and token-concatenation RAG approaches.
CoMEM's plug-and-play memory mechanism exhibits stable performance with increasing memory length, circumventing the performance drop observed in discrete token-based systems as retrieval scale increases. Furthermore, the transferability study demonstrates that memory encoded by CoMEM's VLM can be leveraged by a pure LLM, offering a promising direction for cross-modal knowledge transfer and multimodal augmentation in language-only models.
Comparative Analysis and Efficiency
Relative to multimodal RAG, context compression, and LM memory approaches, CoMEM achieves competitive or superior functionality at a fraction of the training data (15.6k vs. millions) and parameter update (1.2% vs. up to full model). It operates fully in continuous embedding space, supports both multimodal and multilingual contexts, and maintains plug-and-play compatibility. Increased data or additional parameters do not significantly boost performance, confirming CoMEM's training efficiency.
Practical and Theoretical Implications
CoMEM establishes that a VLM, when augmented with a parameter- and data-efficient memory encoder, can reliably condense and utilize complex, multimodal, and multilingual external knowledge for grounded reasoning. This approach moves beyond the limits of discrete context concatenation and pruning, enabling scalable, unified memory augmentation. The plug-and-play design facilitates easy integration across tasks and models, and the demonstrated transferability to pure LLMs suggests broadly applicable cross-modal knowledge sharing. The architecture holds significant promise for deploying knowledge-intensive agents, supporting long-context reasoning scenarios, and adapting to low-resource settings.
Future Perspectives
This work opens multiple future avenues: scaling CoMEM to multi-agent settings, extending memory transfer to other architectures, investigating its impact on planning tasks, and evaluating real-world applications involving dynamic or noisy inputs. The continuous memory paradigm introduced here could underpin next-generation multimodal reasoning systems, enhance generalization in unseen domains, and provide a foundation for unified multimodal knowledge repositories.
Conclusion
CoMEM enables efficient, effective, and flexible multimodal memory integration for vision-LLMs by leveraging continuous dense embeddings and intrinsic VLM alignment. Empirical results verify performance gains in both English and multilingual benchmarks, especially for low-resource languages and complex reasoning tasks. The approach supports plug-and-play augmentation, scalable memory capacity, and cross-modal transfer to pure LLMs—advancing the state-of-the-art in multimodal reasoning architectures and offering a pragmatic model for future developments in AI memory systems.