Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
Abstract: LLM-based autonomous agents have demonstrated strong capabilities in reasoning, planning, and tool use, yet remain limited when tasks require sustained coordination across roles, tools, and environments. Multi-agent systems address this through structured collaboration among specialized agents, but tighter coordination also amplifies a less explored risk: errors can propagate across agents and interaction rounds, producing failures that are difficult to diagnose and rarely translate into structural self-improvement. Existing surveys cover individual agent capabilities, multi-agent collaboration, or agent self-evolution separately, leaving the causal dependencies among them unexamined. This survey provides a unified review organized around four causally linked stages, which we term the LIFE progression: Lay the capability foundation, Integrate agents through collaboration, Find faults through attribution, and Evolve through autonomous self-improvement. For each stage, we provide systematic taxonomies and formally characterize the dependencies between adjacent stages, revealing how each stage both depends on and constrains the next. Beyond synthesizing existing work, we identify open challenges at stage boundaries and propose a cross-stage research agenda for closed-loop multi-agent systems capable of continuously diagnosing failures, reorganizing structures, and refining agent behaviors, extending current coordination frameworks toward more self-organizing forms of collective intelligence. By bridging these previously fragmented research threads, this survey aims to offer both a systematic reference and a conceptual roadmap toward autonomous, self-improving multi-agent intelligence.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Overview
This paper is a big “map of the land” for AI agents that use LLMs. Instead of looking at a single smart AI working alone, it explains how teams of AIs can work together, how mistakes spread in a team, how to figure out who or what caused a mistake, and how the whole team can learn to do better next time—all by itself.
To organize everything, the authors use an easy-to-remember path called LIFE:
- L = Lay the capability foundation (make one agent strong at thinking, remembering, planning, and using tools)
- I = Integrate agents through collaboration (make multiple agents work together like a team)
- F = Find faults through attribution (trace where and why things went wrong)
- E = Evolve through self-improvement (change the team or the rules so the same mistake doesn’t happen again)
Key Questions (in plain language)
The paper asks:
- What does a single AI agent need to be useful on its own?
- How do we make many agents collaborate well, like players on a sports team with different roles?
- When the team fails, how can we figure out what went wrong and who needs to change?
- How can the system fix itself—changing roles, rules, or habits—without waiting for a human to rebuild it?
What Did the Authors Do? (Their approach)
This is a survey paper. That means the authors:
- Read and compared lots of research papers on AI agents.
- Grouped ideas into the four LIFE stages to show how they connect.
- Explained common patterns (taxonomies), like different ways agents store memory or communicate.
- Pointed out how problems in one stage affect the next (for example, bad teamwork makes it harder to find who caused a mistake).
- Collected resources and examples in a public repository to help other researchers.
Think of it as building a field guide: they didn’t run a single experiment; they organized the many existing ideas into one clear roadmap.
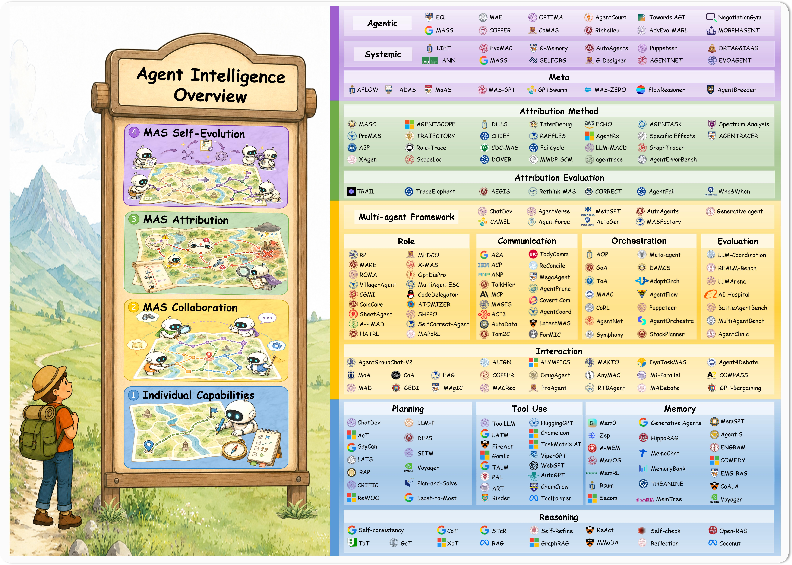
The Four LIFE Stages, Explained
L: Lay the capability foundation (a strong single agent)
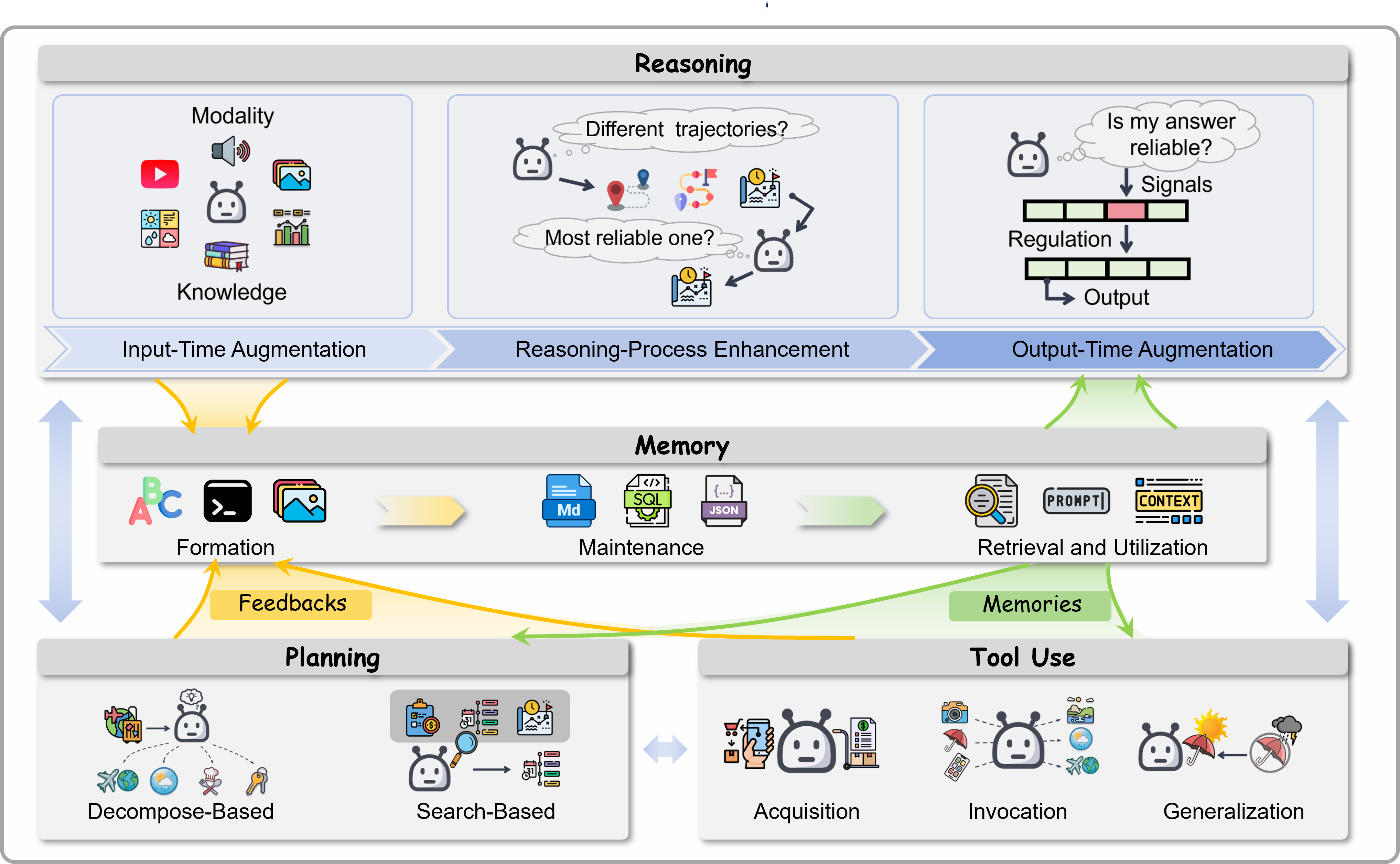
A single agent needs four core skills:
- Reasoning: thinking step by step (like showing your work in math).
- Memory: remembering important facts and past experiences, then using them later.
- Planning: breaking big goals into smaller steps and deciding what to do first.
- Tool use: calling calculators, web search, code runners, or other apps to get things done.
Analogy: This is like training a player to dribble, pass, shoot, and read the game before joining a team.
Why it matters: If individual agents can’t think clearly, remember, plan, and use tools, teamwork won’t help much.
What the survey highlights:
- Ways to make reasoning more reliable (e.g., “try multiple solutions and pick the best,” or “check your own work”).
- Different memory styles (raw logs, summaries, knowledge graphs) and how to keep or forget information wisely.
- Planning strategies for multi-step tasks.
- Using external tools safely and effectively.
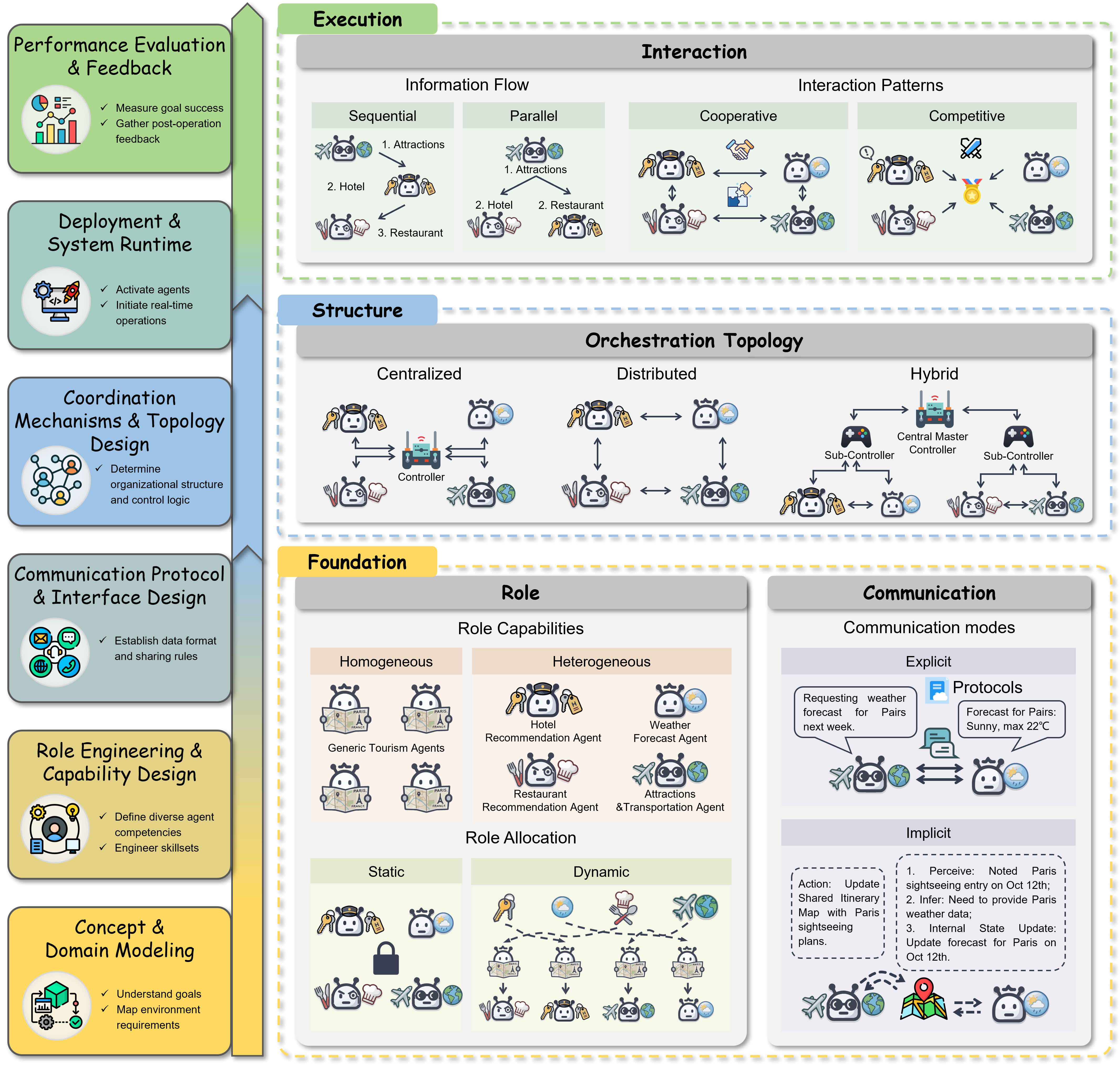
I: Integrate agents through collaboration (teamwork)
Multiple agents can split roles:
- A planner agent lays out the steps.
- A coder agent writes code.
- A checker agent verifies results.
- A communicator agent talks to users or other systems.
They also need clear rules to talk to each other (protocols) and structures for who leads and how decisions are made (like star-topology with a coordinator, or a more democratic network).
Analogy: A school project team where each person has a job—research, writing, editing—and they follow a plan to finish on time.
Why it matters: Some real-world tasks (like building software, running experiments, or controlling robots) are too big for one agent.
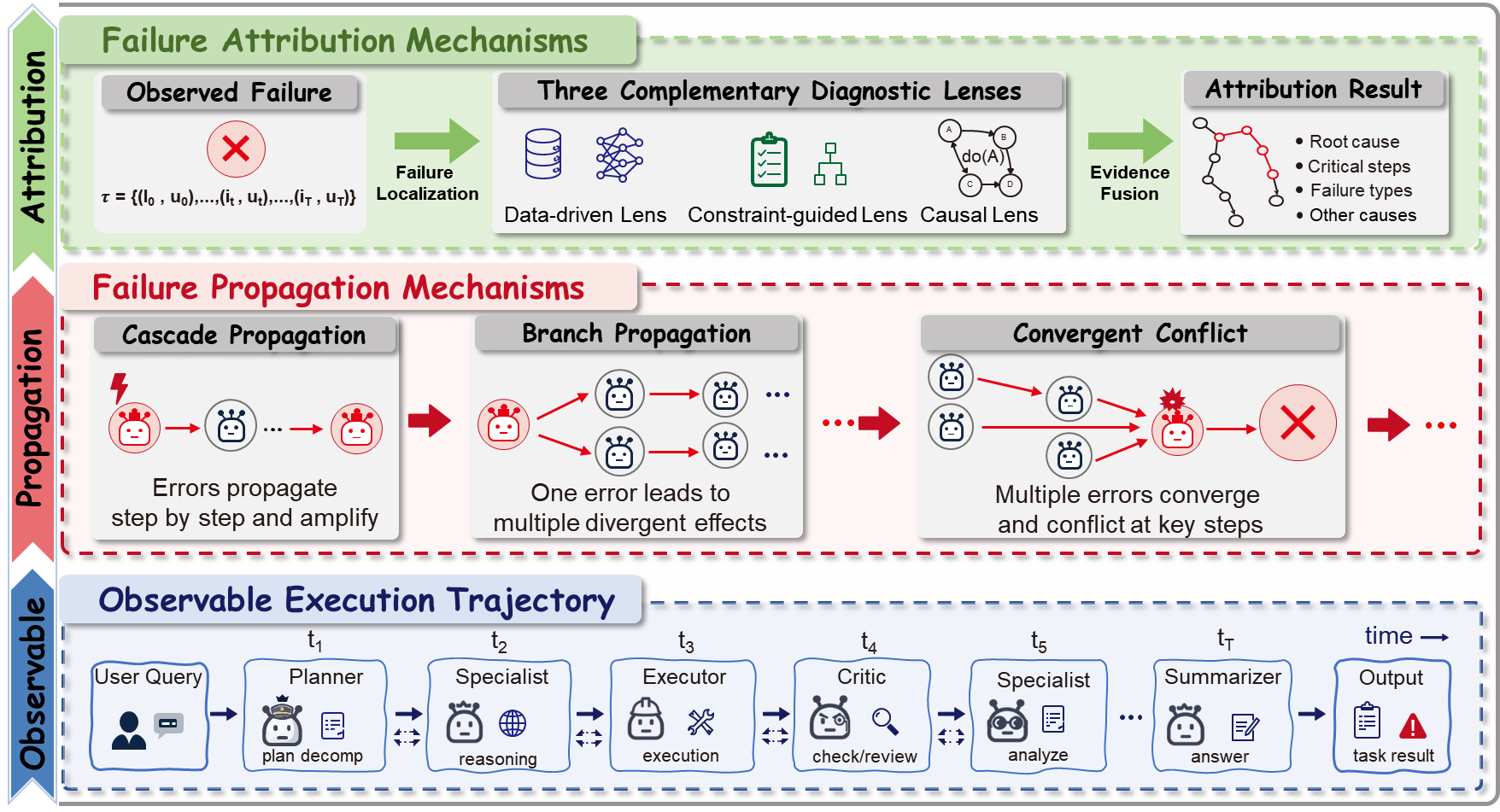
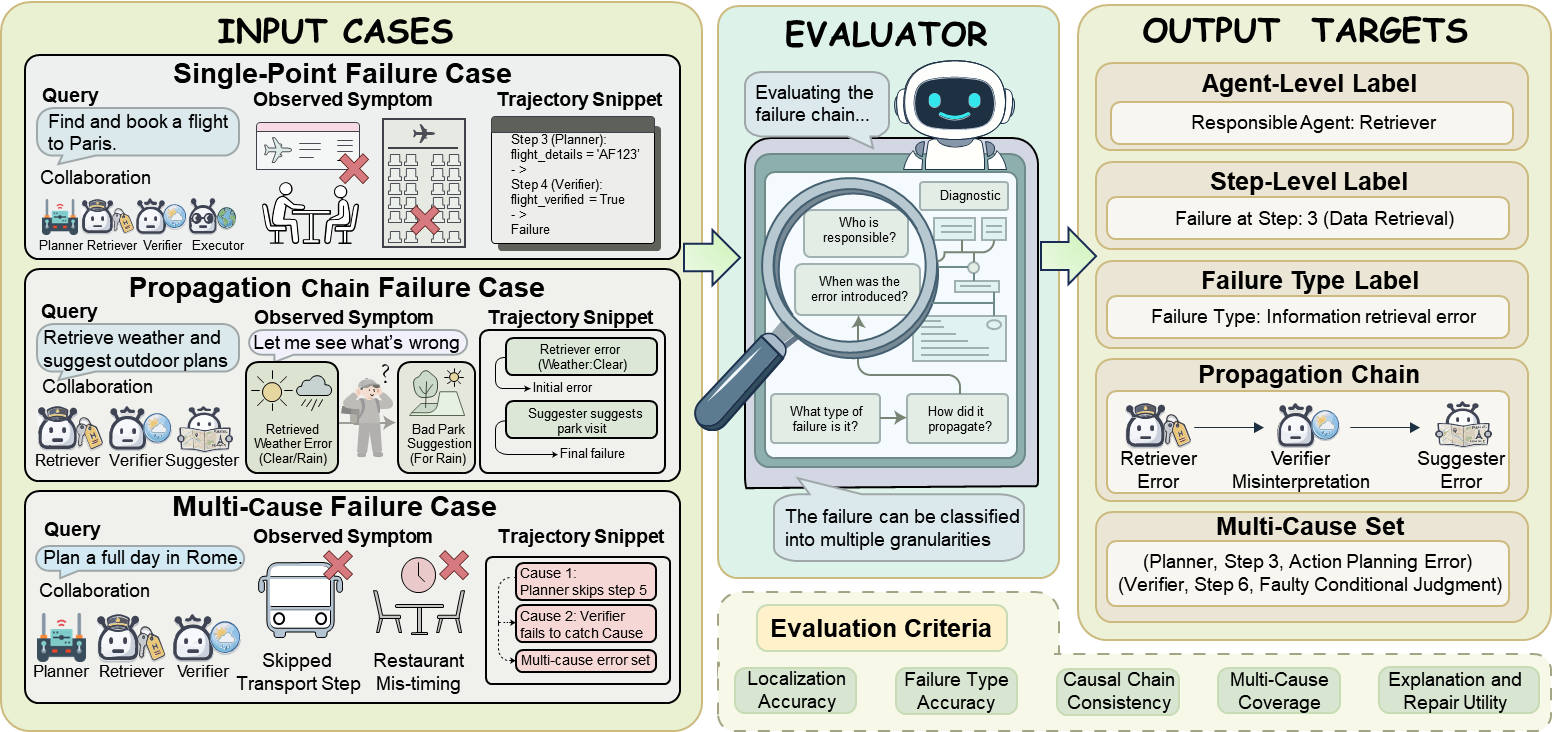
F: Find faults through attribution (who/what caused the mistake?)
In tightly connected teams, small errors can snowball:
- One agent hallucinates a fact.
- Another agent trusts it and makes a wrong tool call.
- The final answer fails, and it’s hard to see where things started to go wrong.
Attribution means tracing the steps back to the root cause:
- Which agent?
- At what moment?
- With which message or tool call?
Analogy: A group rumor goes wrong; you trace the story back to the first person who changed the facts.
Why it matters: If you can’t diagnose the problem, you can’t fix the system effectively.
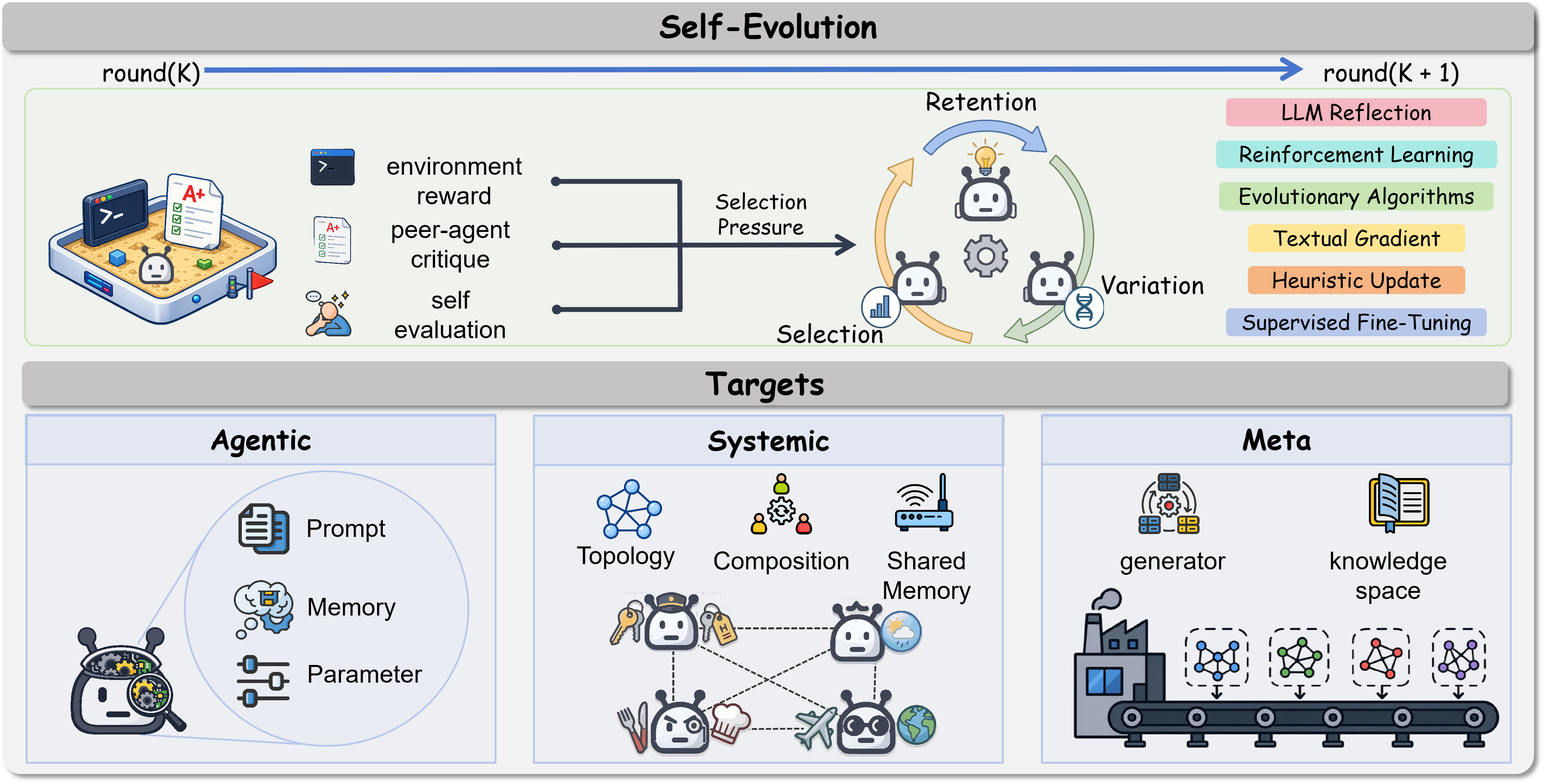
E: Evolve through self-improvement (learn and reorganize)
Once you know what went wrong, the system should improve itself:
- Update prompts, rules, or memory.
- Reassign roles or change the team structure.
- Adjust when to double-check, ask for help, or refuse to answer.
- Swap in better tools or policies based on past failures.
Analogy: After a lost game, the team studies replays, changes the lineup, and practices weak spots to avoid the same mistakes.
Why it matters: This makes multi-agent systems more resilient and less dependent on humans to fix every problem.
Main Findings and Why They Matter
Here are the main takeaways the authors emphasize:
- One coherent progression (LIFE) links four areas that are usually studied separately: single-agent skills, collaboration, diagnosis, and self-improvement.
- Stronger teamwork increases both power and risk: the more tightly agents depend on each other, the more easily errors can spread and hide.
- Attribution and evolution should form a closed loop: finding the cause of failure should directly trigger focused improvements (not random tweaks).
- Each stage limits and enables the next: for example, poor memory design makes attribution harder; poor attribution makes evolution guessy and ineffective.
- There are still big gaps: especially in reliably tracing errors and automatically reorganizing teams based on what was learned.
What Could This Change?
If researchers follow this LIFE roadmap, future AI teams could:
- Handle long, complex tasks more reliably (software engineering, science, robotics).
- Explain what went wrong in plain terms and fix themselves without starting over.
- Become more “self-organizing,” needing less manual babysitting from humans.
- Share common infrastructure (standard ways to talk, log actions, and learn) so systems from different labs work together.
In short, this paper doesn’t build a new agent—it shows how to connect many good ideas into a full life cycle. That blueprint could help the field move from clever demos to durable, trustworthy, and self-improving AI teams.
Quick Recap
- Purpose: Organize the fast-growing world of LLM-based multi-agent systems into one clear, connected framework (LIFE).
- Objectives: Clarify what single agents need, how teams collaborate, how to trace failures, and how systems can improve themselves.
- Approach: A structured survey with taxonomies, design patterns, and a closed-loop view linking failure diagnosis to self-evolution.
- Key insights: Tight teamwork is powerful but risky; attribution must feed directly into targeted improvements.
- Impact: A practical roadmap for building AI teams that are more reliable, explainable, and able to keep getting better on their own.
Knowledge Gaps
Below is a single, consolidated list of specific knowledge gaps, limitations, and open questions that remain unresolved by the paper and that future researchers could address.
- Formalize the LIFE dependencies: Provide an executable mathematical framework (e.g., an augmented Markov game/state-transition model) that quantitatively links “Lay → Integrate → Find → Evolve,” including measurable variables and causal constraints between stages.
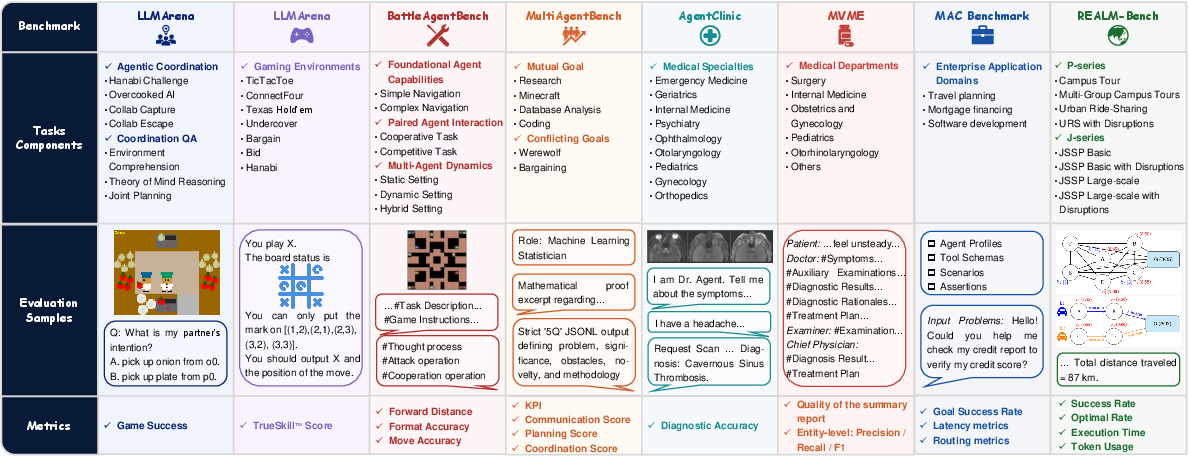
- Closed-loop benchmarks: Create end-to-end tasks where failure attribution must trigger structural evolution and demonstrate measurable post-evolution gains, with standardized protocols for repeated evaluation over “LIFE cycles.”
- Attribution ground truth: Develop datasets with step-level, cross-agent ground truth for root causes, including message-level IDs, tool calls, and environment states to enable precise evaluation of multi-agent credit assignment.
- Telemetry standards: Define interoperable logging/telemetry schemas for MAS (message lineage, tool-call provenance, timestamps, state diffs) to support reproducible attribution across heterogeneous agent frameworks and protocols.
- Causal attribution methods: Move beyond correlational diagnostics to interventional, counterfactual, and causal discovery techniques that isolate which agent, step, message, or tool invocation was necessary and sufficient for a failure.
- Attribution metrics: Standardize evaluation metrics for attribution quality (e.g., root-cause precision/recall, time-to-diagnosis, counterfactual validity) and their relation to downstream evolution effectiveness.
- From diagnosis to edit policies: Design algorithms that translate attribution outputs into constrained structural edits (role reassignment, topology reconfiguration, communication policy changes) with guarantees on safety and performance.
- Stability and safety of self-evolution: Establish theoretical and empirical guarantees (e.g., regret bounds, convergence, monotonic improvement, rollback criteria) to prevent oscillations or degradation during autonomous system evolution.
- Cost-aware orchestration: Develop compute- and budget-allocation policies across agents that adaptively route test-time compute (search, verification, tool use) where it most improves outcomes under cost and latency constraints.
- Protocol-level effects: Empirically study how emerging agent protocols (e.g., MCP, A2A) impact observability, diagnosability, interoperability, and evolvability, including ablations on message structure and capability discovery.
- Long-horizon credit assignment: Create scalable algorithms for temporal credit assignment over hundreds of interaction rounds, distinguishing early hidden causes from late-stage symptoms in cascading failures.
- Tool reliability modeling: Build methods to estimate and attribute failures to external tools versus agent reasoning (tool trust scores, uncertainty, versioning), and to decide when redundant tool checks are warranted.
- Multimodal attribution: Localize errors across perception–reasoning–action pipelines (e.g., vision misgrounding vs. textual inference) and design diagnostics that can attribute faults in multimodal agents and environments.
- Shared/team memory design: Specify and evaluate team-level memory architectures (consistency, concurrency control, access control, conflict resolution) suitable for distributed MAS with partial observability.
- Memory poisoning and recovery: Detect, localize, and remediate corrupted or adversarially injected memories (quarantine, provenance tracing, snapshot/rollback, trust-weighted retrieval).
- Utility-driven memory policies in MAS: Learn maintenance/retrieval policies that optimize team-level utility (not just per-agent relevance), accounting for redundancy, coverage, and cross-agent dependencies.
- Schema standards for memory: Propose interoperable schemas and APIs for episodic/semantic/procedural memories to enable plug-and-play memory across agent frameworks and tasks.
- Evolution granularity: Determine when to prefer prompt-level edits, memory/tool updates, policy fine-tuning, or topology reorganization, and how to escalate across these levels based on diagnostic signals and risk.
- Human-in-the-loop escalation: Specify criteria for when diagnosis/evolution should solicit human intervention, including active-learning strategies to maximize information gain per annotation and minimize oversight burden.
- Robustness to adversarial/misaligned agents: Detect and contain deceptive, colluding, or compromised agents within teams; design incentive-compatible protocols and verification layers resilient to strategic behavior.
- Privacy and governance in MAS: Develop mechanisms for privacy-preserving team memory, differential access, redaction, and auditability that remain valid across self-evolution and role changes.
- Provenance continuity: Ensure decision and model-provenance trails remain traceable after structural evolution (e.g., mapping pre-/post-edit behaviors, reproducibility of historical results).
- Domain transfer of evolved structures: Evaluate whether evolved collaboration structures generalize to new domains and tasks; identify what elements transfer (roles, playbooks, memory schemas) and what must be relearned.
- Attribution-aware training signals: Integrate attribution outputs into training (e.g., PRMs, fine-tuning, RL) to directly optimize for diagnosability, error isolation, and post-edit responsiveness.
- Cascading-failure benchmarks: Construct controlled environments that elicit error propagation across agents and rounds, allowing systematic stress-testing of attribution and recovery mechanisms.
- Compute–accuracy trade-offs in reasoning search: Quantify how parallel sampling, PRMs, and search topologies scale in multi-agent settings, including policies for adaptive allocation across agents and tasks.
- Tool–agent co-design: Study how tool APIs, return schemas, and error messages can be co-designed with agents to improve traceability, error localization, and automatic recovery.
- Open vs. closed model reproducibility: Provide open, fully reproducible baselines (models, traces, seeds) to validate LIFE claims and reduce dependence on closed-source LLMs.
- Safety constraints during evolution: Formalize and enforce hard constraints (e.g., compliance, security, ethical guardrails) that must be preserved through any autonomous system self-modification.
Practical Applications
Overview
This survey connects four causally linked stages (LIFE: Lay capabilities, Integrate agents, Find faults, Evolve) into a closed loop for LLM-based multi-agent systems. The reviewed techniques around reasoning (e.g., CoT, search over thoughts, PRMs, hallucination control), memory (formation, maintenance, retrieval), collaboration (role-specialized teams, protocols), failure attribution, and self-evolution enable concrete deployments now and point to ambitious, longer-horizon systems. Below are practical applications organized by time-to-adoption, with sector tags, candidate tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Software: Agentic dev squads for maintenance and triage
- Use case: Multi-agent teams (planner, coder, tester, reviewer) handle bug triage, patch proposals, regression tests, and documentation updates.
- Tools/workflows: AutoGen/MetaGPT-style orchestration; ReAct/CoT; PRM-based reasoning checks; CRITIC/CoVe for tool-backed and post-hoc verification; RAG to pull API docs; memory stores (Mem0/ENGRAM) for design decisions and incident history.
- Assumptions/dependencies: CI/CD integration; repo/test coverage; structured trace logging for attribution; guardrails to prevent unsafe changes; developer-in-the-loop code review.
- Customer support and service desks (enterprise)
- Use case: Agent teams for triage, answer drafting, and escalation with evidence-linked responses and refusal when out-of-scope.
- Tools/workflows: Retrieval (Self-RAG, SubgraphRAG for structured KBs); FactTune/FActScore/Factcheck-GPT/CoVe for factuality; R-Tuning for calibrated refusals; typed memory (ENGRAM, Zep) for past resolutions and user context.
- Assumptions/dependencies: Up-to-date, well-structured KBs; PII handling and access control; audit trails for failure attribution and QA.
- Financial research copilots (finance)
- Use case: Multi-agent analyst workflows that synthesize filings/news, generate hypotheses, and produce source-cited briefs with uncertainty estimates.
- Tools/workflows: RAG over licensed data; CoVe/RARR for verify-then-revise; PRM-based step checking; SEAL/semantic entropy for confidence; memory timelines for issuer histories.
- Assumptions/dependencies: Data licensing and compliance; no autonomous trading; human analyst supervision; clear provenance tracking.
- Legal/policy drafting assistance (legal, public policy)
- Use case: First-draft generation and redlining with clause-level source verification and change logs; issue spotting with refusal when uncertain.
- Tools/workflows: Factcheck-GPT/FActScore; CAD/DoLa for hallucination suppression; chain-of-verification; episodic memory for matter history.
- Assumptions/dependencies: Attorney/policy expert review; confidentiality controls; jurisdiction-specific templates; robust citation retrieval.
- Clinical documentation and CDS-lite (healthcare)
- Use case: Summarize visits, reconcile meds, propose order set templates with explicit confidence and refusal on clinical decisions.
- Tools/workflows: Multimodal-CoT for chart + text; R-Tuning for safe abstention; CRITIC to verify calculations and drug interactions via tools; memory maintenance to avoid stale facts.
- Assumptions/dependencies: EHR integration; HIPAA compliance; human oversight; strict guardrails (no fully autonomous care decisions).
- Personalized tutoring and coaching (education)
- Use case: Tutors that remember learner goals, misconceptions, and progress; generate step-by-step scaffolding with verified solutions.
- Tools/workflows: Typed memory (episodic/semantic/procedural via ENGRAM/CoALA); PRM-verified reasoning (Math-Shepherd/WizardMath); self-consistency; visual sketchpads for math/science tasks.
- Assumptions/dependencies: Consent and age-appropriate data policies; curriculum alignment; parental/teacher oversight; safe forgetting policies.
- Data/ops incident copilots (software/analytics)
- Use case: Attribute pipeline failures across services, propose fixes, and auto-generate runbooks.
- Tools/workflows: Agent collaboration over logs/metrics; attribution on agent/tool errors via structured traces; memory of prior incidents and mitigations; tool use for dashboards and ticketing.
- Assumptions/dependencies: Observability instrumentation; runbook libraries; change-management approvals.
- Web RPA with verification (software/IT)
- Use case: Reliable, multi-step web workflows (procurement, HR, reporting) with evidence-backed checks to reduce silent failures.
- Tools/workflows: ReAct/ToT for long-horizon planning; CRITIC for live page/tool verification; session memories; refusal on anti-automation blocks.
- Assumptions/dependencies: Site terms of service; stable selectors/APIs; sandboxing and monitoring.
- Marketing and knowledge publishing with guardrails (marketing/comms)
- Use case: Content generation that enforces factual claims and brand/legal constraints, with auto-citations.
- Tools/workflows: FactTune + CAD/DoLa; CoVe; semantic entropy for risk-aware routing (e.g., escalate to editors).
- Assumptions/dependencies: Approved source lists; style/policy checkers; regulated-claims review where applicable (e.g., healthcare).
- Security operations triage (cybersecurity)
- Use case: Blue-team assistants that correlate alerts, construct attack narratives, and recommend mitigations with evidence links.
- Tools/workflows: Tool-augmented reasoning (SIEM, EDR); PRM checks on analytic steps; memory of environment assets and past incidents; agent-level attribution for false positives.
- Assumptions/dependencies: Sandbox access; least-privilege credentials; SOC playbooks; strict audit logging.
Long-Term Applications
- Self-improving software organizations (software/DevOps)
- Use case: Multi-agent “digital orgs” that dynamically reassign roles/topologies based on attribution signals, continuously refining prompts, tools, and collaboration structures.
- Tools/workflows: Closed-loop attribution→evolution pipeline; orchestration protocols (MCP/A2A); MemOS-like lifecycle management; learned maintenance (MemRL).
- Assumptions/dependencies: Robust causal attribution of failures; governance for auto-changes; enterprise policy compliance; reliable evaluation harnesses.
- Autonomous R&D labs (science, pharma, materials)
- Use case: Agents design experiments, operate instruments, diagnose errors, and evolve protocols without constant human steering.
- Tools/workflows: Tool-use across lab devices; PRMs for step verification; multimodal reasoning; typed/procedural memory; self-evolution of workflows driven by attribution.
- Assumptions/dependencies: Safety certification; physical device APIs; compliance (GLP/GMP); human oversight and emergency stops.
- Care-pathway coordinators (healthcare)
- Use case: Cross-specialty agent teams that coordinate referrals, follow-ups, and insurance steps while attributing process failures and self-correcting.
- Tools/workflows: Collaboration protocols across roles; memory graphs (Zep/HippoRAG) for patient journeys; refusal and calibrated uncertainty; evolution of task routing policies from attribution data.
- Assumptions/dependencies: Interoperable EHRs; liability frameworks; rigorous validation and certification; patient consent and privacy.
- Lifelong learning companions (education)
- Use case: Decade-long learner models that adapt pedagogy, detect concept drift, and evolve strategies while honoring privacy and right-to-forget.
- Tools/workflows: Hierarchical memories (MemTree/A-MEM); dynamic maintenance (COMEDY/Mem0 operations); PRM-guided problem solving; self-evolution of curricula.
- Assumptions/dependencies: Portable, privacy-preserving identity; transparent data governance; bias and fairness audits.
- Autonomous financial research and execution under strict governance (finance)
- Use case: Research→proposal→risk review→execution loops with real-time attribution, scenario testing, and self-tuning strategies.
- Tools/workflows: PRM checks; CoVe with live market tools; agent-organization evolution based on error patterns; provenance-by-design.
- Assumptions/dependencies: Regulatory approval/sandboxes; robust controls (no unbounded autonomy); extreme auditability.
- Collaborative robotic fleets with self-evolving policies (robotics, logistics)
- Use case: Teams of robots that plan, coordinate, attribute failures (e.g., task allocation errors), and refine policies on- and off-device.
- Tools/workflows: Multimodal-CoT; PRM-like evaluators for planning steps; typed procedural memory; safe RL for evolution.
- Assumptions/dependencies: Real-time safety guarantees; sim-to-real pipelines; hardware interfaces; incident attribution standards.
- Grid and market operations copilot (energy)
- Use case: Multi-agent forecasting, dispatch planning, and contingency analysis with attribution of forecasting/control failures to avoid cascades.
- Tools/workflows: Graph-of-Thoughts over network topologies; evidence-backed simulation checks; organizational memory of events; adaptive reconfiguration of teams via evolution.
- Assumptions/dependencies: High-fidelity digital twins; utility regulations; cyber-physical security certifications.
- Policy co-creation and evaluation platforms (public policy, govtech)
- Use case: Multi-agent deliberation that drafts policies, runs impact simulations, attributes failure modes (equity, cost, feasibility), and iteratively improves proposals.
- Tools/workflows: Standardized agent communication (MCP/A2A); evidence-grounded verification; public provenance; memory of stakeholder feedback.
- Assumptions/dependencies: Transparent datasets; participatory oversight; legal mandate for AI-generated artifacts’ traceability.
- Multi-agent peer review and claim verification (academia, publishing)
- Use case: End-to-end paper vetting: evidence retrieval, step-level reasoning audits via PRMs, and structured attribution of weaknesses.
- Tools/workflows: Think-on-Graph/SubgraphRAG; CoVe/RARR; process-supervised scoring; memory of prior reviews and retractions.
- Assumptions/dependencies: Publisher adoption; standardized provenance schemas; incentive alignment with human reviewers.
- Crisis-response digital twins (public safety, smart cities)
- Use case: Preparedness teams that simulate scenarios, attribute coordination failures, and evolve SOPs before and during crises.
- Tools/workflows: Agent teams spanning logistics, health, communications; memory graphs of assets/people; attribution-driven SOP evolution.
- Assumptions/dependencies: Real-time data feeds; inter-agency data sharing; robust command authority and fail-safes.
Cross-cutting assumptions and dependencies
- Data and tools: High-quality, up-to-date knowledge bases; stable tool and system APIs; access control and secret management.
- Reliability: Structured trace logging for agent/tool actions; process-level supervision (PRMs); test-time compute budgets for self-consistency/verification.
- Governance and safety: Human-in-the-loop checkpoints; refusal/abstention policies; auditability and provenance-by-design; privacy (PII, HIPAA, FERPA) and retention/forgetting policies.
- Interoperability: Adoption of open agent protocols (MCP, A2A) and standardized schemas for memory, traces, and attribution.
- Evaluation: Domain-specific benchmarks (including failure-attribution datasets), offline sandboxes, and red-teaming before production deployment.
Glossary
- Abstractive distillation: Compressing raw interaction logs into concise, structured memories. "Abstractive distillation compresses raw experience into more compact representations, spanning a spectrum of granularity."
- Attention-head activations: Internal Transformer signals at attention heads that can be manipulated to alter generation behavior. "directly shifts attention-head activations along pre-identified truthfulness directions during inference."
- Bitemporal data model: A data model tracking both the time an event occurred and the time it was recorded. "and a bitemporal data model that tracks both event time and ingestion time."
- BM25: A probabilistic information retrieval ranking function used for keyword-based search. "combines semantic search, BM25 keyword matching, and graph traversal"
- Cascading failures: Errors that propagate across components or steps, causing subsequent errors and obscuring root causes. "triggering cascading failures that obscure the original root cause"
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning from LLMs. "Chain-of-Thought (CoT) prompting"
- Chain-of-Verification (CoVe): A verification approach where the model generates checks and revises answers based on them. "Chain-of-Verification (CoVe) takes an active approach"
- Contrastive decoding: An inference method that contrasts model outputs under different conditions to reduce hallucinations. "contrastive decoding suppresses hallucination by amplifying differences between distinct signal sources."
- Context window: The maximum token span a model can attend to as input at inference time. "when the context window approaches its limit"
- Cosine similarity: A vector-space similarity metric commonly used for embedding-based retrieval. "ranked by cosine similarity"
- Ebbinghaus forgetting curve: A model of memory decay describing how retention decreases over time. "applies the Ebbinghaus forgetting curve"
- Episodic memory: Memory of specific past experiences or episodes used to inform future decisions. "maintaining an episodic memory of past failures."
- Graph traversal: Navigating nodes and edges of a graph to retrieve or process related information. "combines semantic search, BM25 keyword matching, and graph traversal"
- Hallucination: Model-generated content that is not supported by facts or evidence. "commonly termed hallucination"
- Hippocampal indexing theory: A cognitive theory inspiring graph-based memory indexing and retrieval. "draws on hippocampal indexing theory"
- Logit distributions: The unnormalized output scores of a model before softmax, often compared for decoding strategies. "contrasts logit distributions from higher versus lower Transformer layers"
- Membership estimation: Using internal signals to assess whether content aligns with known or supported knowledge. "uses membership estimation scores from hidden states"
- Monte Carlo rollouts: Sampling-based simulations used to estimate quantities like step correctness. "by estimating step correctness through Monte Carlo rollouts"
- Monte Carlo Tree Search: A search algorithm that explores decision trees via randomized sampling and backpropagation of rewards. "via LLM-aided Monte Carlo Tree Search"
- Open information extraction: Unsupervised extraction of relational tuples from text without predefined schemas. "constructing a schemaless knowledge graph via open information extraction"
- Orchestration topologies: Structural patterns governing coordination and communication among multiple agents. "communication protocols, orchestration topologies, and interaction patterns"
- Parametric knowledge: Knowledge encoded in a model’s learned weights rather than external resources. "shifting from sole reliance on parametric knowledge toward dynamic integration of external information."
- Personalized PageRank: A graph-based ranking method biased toward particular nodes for relevance-focused retrieval. "and retrieving through Personalized PageRank."
- Process reward models (PRMs): Models that score or reward intermediate reasoning steps rather than only final outputs. "Process reward models (PRMs) address this limitation"
- Process supervision: Training or evaluation that provides feedback at intermediate reasoning steps. "process supervision is most effective when it shapes both the learned policy and the selection mechanism."
- Retrieval-Augmented Generation (RAG): Generation enhanced by retrieving external documents at inference time. "Retrieval-Augmented Generation (RAG) couples a parametric generator with a non-parametric retrieval module"
- Self-Consistency: An inference strategy that samples multiple reasoning chains and selects the prevailing answer. "Self-Consistency addresses this at the output level by sampling multiple chains and returning the majority answer"
- Semantic Entropy: An uncertainty measure based on clustering semantically equivalent outputs to gauge true confidence. "Semantic Entropy refines this by clustering semantically equivalent outputs"
- Stochastic abstention: A policy of refusing to answer when uncertainty is high, guided by learned calibration. "calibrated RL approaches incentivize stochastic abstention when confidence is insufficient."
- Tool invocation: Executing actions via external tools or APIs as part of an agent’s reasoning loop. "an incorrect tool invocation can propagate"
- Typed routing: Directing different kinds of memories into specialized stores (e.g., episodic, semantic, procedural). "Typed routing goes beyond deciding how much to abstract and additionally determines where each entry should be stored."
- Virtual memory systems: Operating system mechanisms that manage limited memory by swapping with secondary storage. "analogous to page swapping in virtual memory systems."
- Zettelkasten: A note-taking method emphasizing linked atomic notes, inspiring hierarchical memory designs. "Zettelkasten-inspired note-based architecture"
Collections
Sign up for free to add this paper to one or more collections.