- The paper presents a feed-forward method that employs Z-order serialization and sparse attention to efficiently infer compact Gaussian scene representations.
- It combines multi-view image encoding, depth estimation, and ZFormer blocks to achieve faster inference with superior metrics like PSNR and SSIM.
- Experimental results demonstrate scalability, robust cross-dataset generalization, and up to 1000x speed improvements over optimization-based methods.
Introduction
The paper "Z-Order Transformer for Feed-Forward Gaussian Splatting" (2605.13465) presents a novel transformer-based framework for scene reconstruction and novel view synthesis using 3D Gaussian Splatting (3DGS). Distinguishing itself from gradient-based optimization approaches, the proposed method employs a feed-forward architecture that infers compact, high-fidelity Gaussian scene representations from arbitrary multi-view images. This is achieved by introducing a Z-order (Morton order) framework for spatially-coherent ordering and a sparse attention mechanism specialized for the highly unstructured and high-cardinality nature of Gaussian point sets in 3D space.
Conventional 3DGS optimizes a cloud of anisotropic Gaussians per scene, achieving photorealistic synthesis at the cost of extensive per-scene gradient descent and poor scalability for applications such as real-time reconstruction and rapid scene generalization. Feed-forward methods attempt to bypass this bottleneck by directly predicting Gaussian attributes from images. However, two key problems persist: (1) pixel-wise allocation of Gaussians typically results in excessive memory consumption and unnecessary redundancy; (2) voxel-based aggregation, while alleviating redundancy, introduces quantization artifacts and inefficiencies, especially in irregular or sparse regions.
The Z-order transformer addresses both issues by providing a locality-preserving serialization of point sets, reminiscent of approaches in spatial databases and point cloud analysis, but tailored to the requirements of neural rendering and Gaussian splatting.
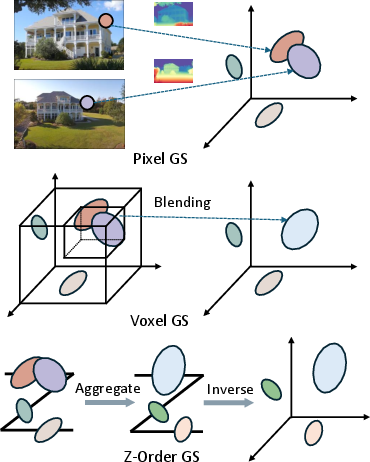
Figure 1: Gaussian representations in feed-forward GS highlight limitations of dense pixel-aligned and voxel-based aggregation strategies.
Methodology
System Pipeline
Given arbitrary multi-view images, the method follows a structured pipeline: image encoding and depth estimation, 3D point projection, feature aggregation via ZFormer blocks, and feed-forward prediction of Gaussian attributes.
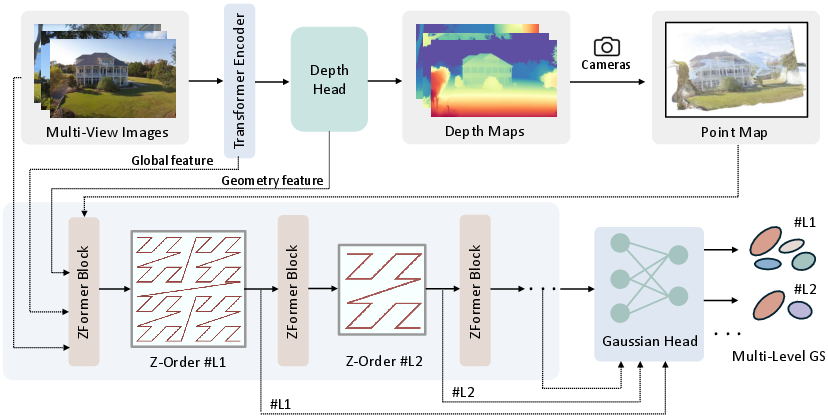
Figure 2: System pipeline. Multi-view images are encoded, depth maps estimated and projected to 3D points. ZFormer blocks process features in Z-order for compact Gaussian representation, rendered by the Gaussian head.
Z-Order Serialization
The Z-order curve establishes a mapping from 3D Euclidean positions to a one-dimensional sequence via bitwise interleaving of coordinates. This serialization ensures that spatially adjacent points are likely ordered closely, which enables efficient blockwise attention and grouping operations. The process natively supports dynamic scene densities and irregular geometric structures.
Sparse Attention
The ZFormer block, central to the model, performs group (block) attention on serialized sequences, followed by a top-K selection mechanism. Group attention averages within local blocks, efficiently capturing intra-block relations; top-K selection attends only to the most salient blocks globally, drastically reducing attention complexity without discarding key contextual cues.
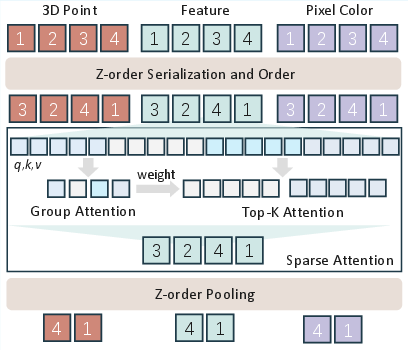
Figure 3: ZFormer Block serialization, sparse self-attention (group and top-K), and Z-order pooling for compact feature aggregation.
Hierarchical Z-Order Pooling
Poolings at configurable Z-order depths successively aggregate spatially-local Gaussians, allowing multi-scale control over primitive compression. The Gaussian head then regresses mean, orientation, scale, opacity, and color (in SH basis) attributes.
Training Regime and Inference Optimization
A pre-trained depth estimator is used for initial supervision, but the depth head is trained jointly to adapt to challenging scene fragments. Auxiliary distillation loss is imposed to ensure depth map consistency. Color supervision is provided by MSE and LPIPS losses on rendered outputs.
At inference, redundant input views are pruned efficiently using a greedy Z-order Maximum Coverage Viewpoint Selection algorithm, leveraging the spatial coverage metric in Morton-coded 3D space.
Experimental Evaluation
Quantitative Comparisons
The framework is evaluated on RealEstate10K, DL3DV, and ACID datasets, using standard protocols. Results across varying view counts establish the superiority of the method in both photometric and perceptual metrics—including PSNR, SSIM, and LPIPS, with consistently superior performance especially for sparse input views, where prior approaches degrade steeply.
Strong numerical results include:
Ablation Studies
Component-level ablations confirm that:
- Removing Z-order serialization or sparse attention yields substantial metric drops and degraded reconstructions.
- Joint depth training and SH parameter initialization from image color are both critical for fidelity.
- Two-stage Z-order pooling provides an optimal tradeoff between compression and fine detail; more layers lead to quality degradation.

Figure 5: Visual ablation study evidences the indispensability of ZFormer structure, sparse attention, and SH initialization.

Figure 6: Layer selection ablation highlights that two Z-order blocks prevent degradation yet keep primitive counts low.
Generalization and View Selection
The framework demonstrates robust cross-dataset generalization and effective scalability with respect to view count. The Z-order based view selection outperforms random sampling, striking a balance between computational efficiency and rendering quality.
Implications and Future Directions
This work provides a significant architectural advance in feed-forward neural scene representation by co-designing the data structure (Z-order curve) and attention mechanism for efficiency and scalability. The ability to synthesize novel views with far fewer Gaussian primitives, minimal quantization artifacts, and substantial reductions in runtime and memory positions this approach as a strong candidate for real-time, interactive systems, edge deployment, and scalable dataset generation.
From a theoretical standpoint, this architecture bridges spatial serialization and learned sparse aggregation in high-dimensional settings, suggesting that similar ordering-attention co-design could be beneficial for other modalities (e.g., point cloud transformers, high-cardinality geospatial prediction, or large-scale neural radiance fields).
Potential future enhancements include hierarchical multi-resolution Z-order aggregation, learnable block structure, or integration with neural radiance/hybrid representations. The trade-off between compression ratio and detail preservation at extreme scales (high-res, dense scenes) remains an open challenge.
Conclusion
The Z-order transformer for feed-forward Gaussian splatting innovatively leverages spatially-coherent serialization, realistic sparse attention, and adaptive viewpoint selection to produce state-of-the-art performance in novel view synthesis. The empirical superiority in both quality and efficiency, combined with robust generalization, establishes a new baseline for real-time generalizable scene reconstruction in neural graphics.
