- The paper introduces AsymFlow, which projects high-dimensional noise into a low-rank subspace to mitigate capacity saturation during pixel-space generation.
- It leverages patch-wise orthogonal projections and variance reduction to effectively bridge latent and pixel spaces for enhanced image synthesis.
- Empirical results on ImageNet and text-to-image tasks demonstrate improved FID scores and human preference, confirming the method's superior stability and detail.
Asymmetric Flow Models: Rank-Asymmetric Parameterization for High-Dimensional Generative Modeling
Introduction
The paper "Asymmetric Flow Models" (2605.12964) introduces Asymmetric Flow Modeling (AsymFlow), an innovative approach for generative modeling in high-dimensional output spaces such as pixel-space image generation. The authors address significant scaling bottlenecks encountered by contemporary diffusion-based image and video synthesis methods—particularly with plain transformer architectures—where high-dimensional noise prediction can saturate network capacity and degrade sample quality. AsymFlow proposes a rank-asymmetric parameterization: the data component of the target remains full-dimensional, but the noise component is projected into a patch-wise low-rank subspace. This enables scalable pixel-space modeling and facilitates the finetuning of large pretrained latent generators into high-fidelity pixel-space image generators.

Figure 1: AsymFLUX.2 klein generations. AsymFlow finetunes FLUX.2 klein into a pixel-space flow model, producing highly realistic images with rich visual styles and fine detail.
Motivation and Technical Challenges
Contemporary flow- and diffusion-based generative models excel in compressed latent spaces, where noise prediction is tractable relative to the model width. However, direct generation in high-dimensional spaces (e.g., pixels at 256×256+) exposes a critical bottleneck: the network must model high-dimensional Gaussian noise, which pollutes internal representations. Legacy pixel-space diffusion leveraged U-Net skip connections to route noise, while modern scalable transformers lack these architectural bypasses. Architectural workarounds—such as U-ViT variants or decoder heads—add complexity and detract from the scalability seen in plain diffusion transformers.
Parameterization alternatives (e.g., x0-prediction vs. ϵ-prediction) pose trade-offs: x0-prediction is numerically unstable at low noise levels, while ϵ-prediction demands full-rank noise regression. AsymFlow circumvents both issues by leveraging low-rank noise parameterization, preserving tractability and stability without architectural modification.
Asymmetric Flow Parameterization
Let the standard flow velocity target for a noisy point xt be ϵ−x0, where ϵ is Gaussian noise and x0 is the clean data. AsymFlow restricts the noise term to a patch-wise low-rank subspace via an orthogonal projection operator P=UU⊤ (with U∈RD×r denoting the rank-ϵ0 patch basis):
ϵ1
The network is trained to regress ϵ2. To recover the full-rank velocity needed for sampling and loss computation, the authors derive an analytic mapping from the asymmetric velocity back to a standard full-rank velocity. Orthogonally, AsymFlow behaves as ϵ3-prediction within the low-rank subspace and as ϵ4-prediction in the complementary subspace, making ϵ5 equivalent to ϵ6-prediction and ϵ7 equivalent to ϵ8-prediction. This formulates a family of parameterizations interpolating between these endpoints.
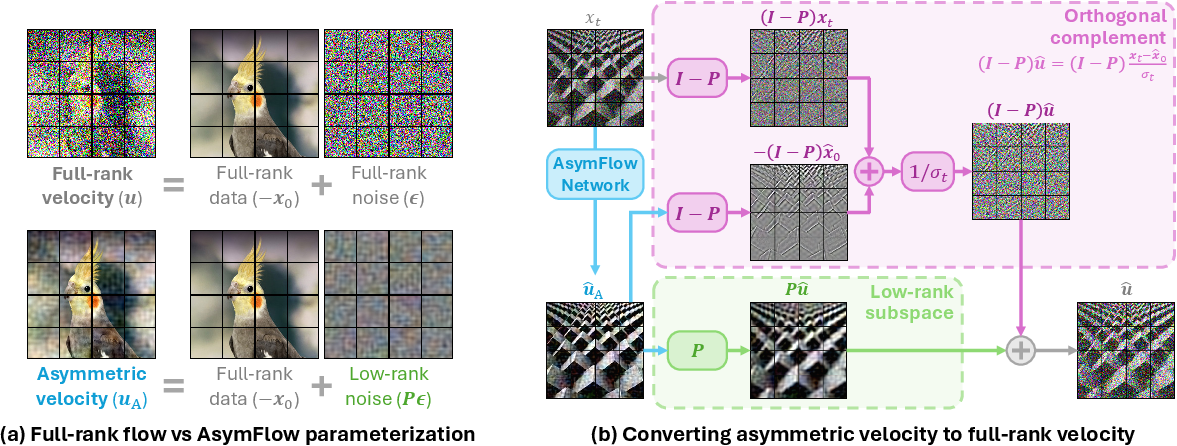
Figure 2: AsymFlow parameterization and recovery. (a) Standard velocity target is modified by projecting the noise to a low-rank subspace. (b) Full-rank velocity is analytically recovered during training and inference.
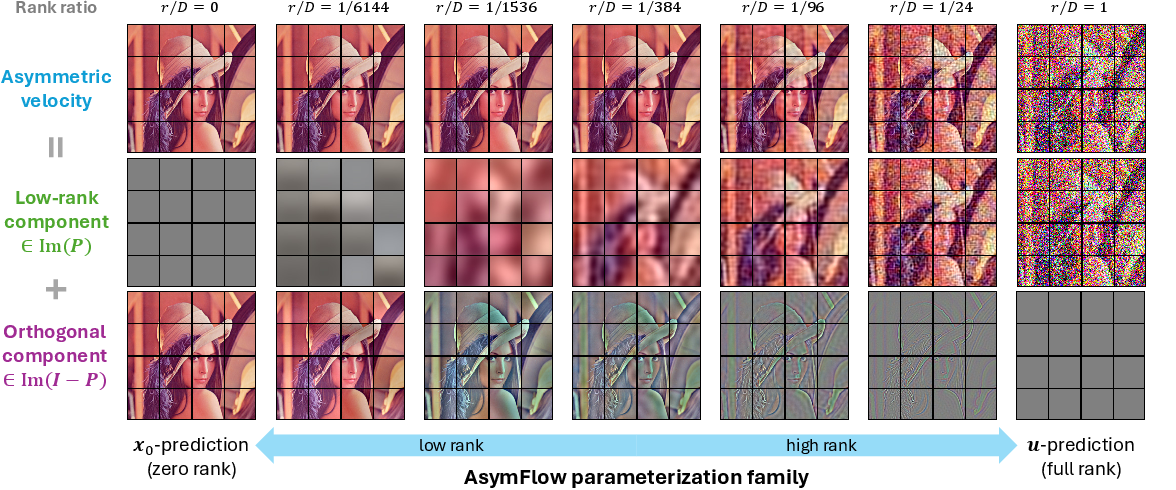
Figure 3: Orthogonal component view of AsymFlow. The parameterization is split between low-rank (velocity-style) and orthogonal (data-style) components, with rank ϵ9 controlling the trade-off.
Patch-wise projections leverage image structure (e.g., PCA on patches), capturing the subspace of dominant data variation, ensuring the low-rank noise term is informative. This is crucial both for training from scratch and for finetuning from latent space.
Latent-to-Pixel Lifting and Finetuning
One of AsymFlow's key capabilities is to seamlessly lift pretrained latent generators into pixel-space without architectural change. The latent-to-pixel alignment is achieved via a patch-wise orthogonal Procrustes mapping between latent and pixel spaces, initializing the pixel model such that its generated samples are structurally and semantically coupled to the base latent model. The full-dimensional gap between low-rank lifted pixels and real pixels is then resolved by finetuning on pixel targets.
Theoretical identification is provided showing coupled ODE trajectories: the lifted pixel and latent ODEs are provably synchronized in relevant subspaces, ensuring faithful transfer of semantics and structure (see mathematical proofs in the appendix).
To accelerate convergence and enhance fine detail, the paper leverages a variance-reduced finetuning objective based on anchored control variates, further augmented by a perceptual LPIPS-corrected loss that addresses low-rank approximation artifacts:
- Anchored variance reduction utilizes paired low-rank predictions as control variates, reducing gradient noise.
- The LPIPS term is adaptively weighted to correct for residual low-rank subspace error at low diffusion noise levels.
Empirical Results
Pixel Diffusion on ImageNet
On ImageNet 256×256, AsymFlow with a patch-wise PCA subspace (x00) and standard REPA loss achieves 1.57 FID, surpassing DiT/JiT-style models and closing the gap to hierarchical CNNs and U-ViT architectures, but using a scalable plain transformer backbone. Notably, the improvement in final sample quality is accompanied by superior sample sharpness and more robust numerical stability at low noise levels.
Comparative ablations verify:
- Optimal rank (x01) outperforms both x02- and x03-prediction in sample quality and training speed.
- Random subspace projection is ineffective, underscoring the necessity of patch-level data-adaptive subspaces.
Large-Scale Text-to-Image Generation
Finetuning the 9B FLUX.2 klein latent model with AsymFlow yields AsymFLUX.2 klein, a state-of-the-art pixel-space generator. It outperforms its latent ancestor and PixelDiT baselines on HPSv3 (human preference), DPG-Bench (fine-grained prompt alignment), and GenEval (entity-compositionality).

Figure 4: Qualitative comparison of T2I diffusion models. AsymFLUX.2 klein generates more realistic, diverse, and richly detailed images than prior pixel and latent models.

Figure 5: Ablation of AsymFLUX.2 klein finetuning. AsymFlow alone excels in fine detail; variance reduction enhances texture but yields artifacts; perceptual correction suppresses artifacts and preserves realism.

Figure 6: Additional qualitative text-to-image comparisons (part A).

Figure 7: Additional qualitative text-to-image comparisons (part B).
Quantitative results highlight the effectiveness of the low-rank lifting and finetuning approach:
- Variance-reduced objective and perceptual correction consistently improve fine-grained details and perceptual metrics.
- The method is parameter-efficient: only lightweight projection layers and LoRA adapters are finetuned, while the large model is frozen, decoupling text and image representation learning.
Implications and Future Directions
AsymFlow demonstrates that rank-asymmetric parameterization fundamentally relaxes the representational burden of high-dimensional noise prediction in pure-transformer diffusion models, enabling both efficient training from scratch and effective exploitation of large-scale pretrained latent models for high-fidelity pixel-space synthesis. The bridging between latent and pixel spaces opens a marked avenue for model reuse and enhances transferability across generative modeling regimes.
Theoretically, AsymFlow generalizes existing diffusion parameterizations and unifies them within a rigorous analytic recovery framework. Practically, it advances the state of the art in pixel-based image synthesis with significant gains in FID and human preference benchmarks.
Future directions include:
- Extension of AsymFlow to high-dimensional video, volumetric, or multimodal generative tasks
- Dynamic or data-adaptive rank selection for subspace projections
- Joint latent-pixel multi-resolution models leveraging hierarchical AsymFlow
- Application to non-image domains where high-dimensional generative modeling is challenging
Conclusion
AsymFlow presents a sophisticated solution to fundamental scalability limitations in generative modeling for high-dimensional data. Its rank-asymmetric target parameterization and analytic recovery enable both highly efficient training and the practical finetuning of transformer-based latent diffusion models into high-fidelity pixel-space generators. These contributions position AsymFlow as a pivotal framework for the next generation of image and vision generative models, with implications for fine-grained control, visual fidelity, and transfer learning capacities across the field.