SoFlow: Solution Flow Models for One-Step Generative Modeling
Abstract: The multi-step denoising process in diffusion and Flow Matching models causes major efficiency issues, which motivates research on few-step generation. We present Solution Flow Models (SoFlow), a framework for one-step generation from scratch. By analyzing the relationship between the velocity function and the solution function of the velocity ordinary differential equation (ODE), we propose a Flow Matching loss and a solution consistency loss to train our models. The Flow Matching loss allows our models to provide estimated velocity fields for Classifier-Free Guidance (CFG) during training, which improves generation performance. Notably, our consistency loss does not require the calculation of the Jacobian-vector product (JVP), a common requirement in recent works that is not well-optimized in deep learning frameworks like PyTorch. Experimental results indicate that, when trained from scratch using the same Diffusion Transformer (DiT) architecture and an equal number of training epochs, our models achieve better FID-50K scores than MeanFlow models on the ImageNet 256x256 dataset.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SoFlow, a new way to make AI-generated images in one step. Most popular image generators (like diffusion models) create pictures by cleaning up noise over many small steps, which is slow. SoFlow learns to jump directly from pure noise to a final image in a single move, making generation much faster while keeping image quality high.
What problem are they trying to solve?
In simple terms:
- Today’s powerful image generators take many steps to turn random noise into a detailed picture. That’s accurate but slow.
- Some newer “one-step” methods are fast but hard to train well and often can’t use a common quality-boosting trick called Classifier-Free Guidance (CFG).
- Other methods rely on a costly math operation (called a Jacobian–vector product, or JVP) that slows training and uses a lot of memory.
The paper asks: Can we build a one-step image generator that is easy to train, avoids expensive math, supports CFG, and makes high-quality images?
How does SoFlow work? (Everyday explanation)
Think of image generation as a journey through time:
- Imagine you start at “time 1” with pure noise and want to reach a clean image at “time 0.”
- The “speed” and “direction” you should move at any place and time is called a velocity field.
- Traditional methods solve this by taking many tiny steps, updating position using the velocity each time.
SoFlow does something different:
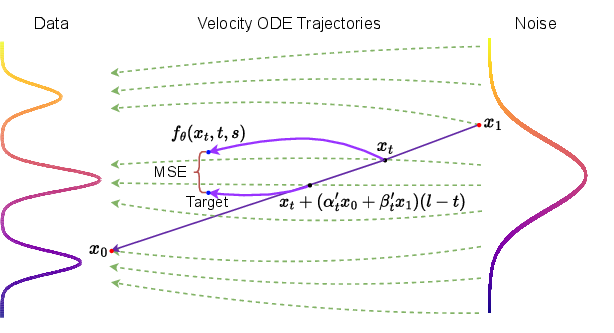
- It learns a “solution function,” a kind of smart teleportation tool: give it where you are now (noisy image at time t), and it tells you where you would be at another time s (a less noisy image), in one jump.
- If you give it a noise sample at time 1 and ask for time 0, it outputs the final image in a single step.
To train this teleportation tool, SoFlow uses two simple rules:
- Flow Matching loss (move at the right speed)
- This teaches the model what the correct “speed and direction” should be at each point.
- In plain terms, it aligns the model’s idea of how images change over time with the true motion from noise to clean images.
- Bonus: This lets the model use Classifier-Free Guidance (CFG) during training, which improves image quality (especially for class-conditional generation like ImageNet).
- Solution Consistency loss (be consistent when you nudge time)
- This teaches the model to stay coherent if you shift the time a little. If a tiny move forward in time should change the image a tiny bit, the model’s outputs should reflect that.
- Importantly, SoFlow designs this consistency rule so it does NOT need the heavy Jacobian–vector product that slows other methods. That makes training faster and more memory-friendly.
Together, these two rules help the model learn a reliable one-step “map” from noise to image, without expensive math or unstable training.
A quick note on Classifier-Free Guidance (CFG)
- CFG boosts quality by mixing two predictions: one that knows the class label (e.g., “golden retriever”) and one that doesn’t.
- Many one-step-from-scratch models can’t easily use CFG. SoFlow builds CFG into training, so you still get one-step generation at test time, but with better detail and relevance to the class.
What did they test, and what did they find?
They trained SoFlow from scratch on ImageNet 256×256 using the same model backbone (Diffusion Transformer, DiT) and the same number of training epochs as a strong recent baseline called MeanFlow.
Key results:
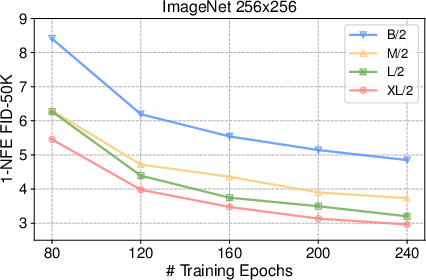
- One-step image quality (lower is better for FID-50K):
- DiT-B/2: SoFlow 4.85 vs MeanFlow 6.17
- DiT-M/2: SoFlow 3.73 vs MeanFlow 5.01
- DiT-L/2: SoFlow 3.20 vs MeanFlow 3.84
- DiT-XL/2: SoFlow 2.96 vs MeanFlow 3.43
- Two-step (still very fast) also improves further (e.g., SoFlow XL/2: 2.66 FID).
- Training is more efficient because SoFlow avoids the expensive JVP operation used in some other methods. That means lower memory use and faster training in practice.
- On CIFAR-10 (32×32 pixels), SoFlow’s one-step results are competitive with other fast methods.
Why this matters:
- You get fast, one-step sampling without giving up much quality.
- Training is simpler and more efficient, making it easier to scale.
- Built-in support for CFG improves class-conditional image quality.
Why is this important?
- Speed: One-step generation makes image creation much faster, which is valuable for real-time applications.
- Simplicity: Skipping complex, slow operations (like JVP) makes training less resource-intensive.
- Quality: Matching or beating strong baselines in one step is hard—SoFlow does it while supporting CFG.
- Flexibility: Although designed for one-step, the model can also do a few steps if you want even better quality.
Takeaway and impact
SoFlow shows that you can train a model to “solve the whole path at once” from noise to image, instead of walking it step by step. This approach:
- Keeps generation very fast (one step),
- Improves training efficiency,
- Plays nicely with CFG to boost quality,
- And outperforms a strong recent baseline under fair, same-budget comparisons.
In the future, this could help build faster, high-quality image and video generators that are cheaper to train and easier to deploy—useful for creative tools, games, and on-device AI where speed matters.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Lack of theoretical guarantees that minimizing the proposed losses yields a solution function satisfying the PDE condition globally: no proof that the Flow Matching + solution consistency objectives imply converges to the unique ODE solution for all .
- No error bounds for the Taylor-based solution consistency loss: the approximation in the limit is used without a formal quantitative analysis of bias, variance, or convergence rate as a function of , network capacity, and data distribution.
- Missing analysis of the semigroup/flow property: the paper does not test or enforce that , a key property for valid flow maps and multi-step consistency.
- Global Lipschitz and smoothness assumptions on the true velocity field are not verified or enforced in practice; there is no discussion of how violations affect learned , stability, or generalization.
- The choice of parameterizations (Euler or trigonometric) is heuristic; the paper does not analyze which families guarantee stable training, better approximation accuracy, or stronger theoretical properties (e.g., semigroup consistency, conditioning).
- No principled method for selecting the loss weighting coefficient , smoothing , or adaptive weights and : sensitivity analyses beyond the reported ablations are missing, and guidelines for other datasets or modalities are not provided.
- The logit-normal time sampling (for and ) is adopted without theoretical justification; the effects of choices on convergence, bias towards certain time regimes, and performance across datasets are not studied.
- The schedule is chosen heuristically; there is no analysis of how dynamic schedules (e.g., adaptive per-batch/per-sample) impact optimization stability or final performance, nor whether can be learned.
- CFG training relies on mixing a high-variance stochastic velocity term with a low-variance model prediction using a constant ratio ; there is no variance/bias decomposition, no proof of unbiasedness, and no principled selection or scheduling of across time steps or training stages.
- Potential guidance-induced bias is not quantified: how CFG during training reshapes the learned unconditional flow and whether it causes over-conditioning or label leakage is not measured.
- No explicit comparison of training stability against JVP-based methods beyond qualitative statements; missing quantitative training-speed, memory, and wall-clock comparisons across architectures and scales in the main text.
- Reliance on SD-VAE latents (32×32×4) for ImageNet experiments is a confounder; the effect of the tokenizer choice, VAE quality, and latent resolution on SoFlow’s one-step performance is not disentangled.
- Pixel-space performance at high resolution (e.g., 256×256 without a VAE) is untested; the generality of SoFlow to end-to-end pixel generation remains unknown.
- Multi-step sampling behavior is underexplored: beyond 2-NFE, it is unclear whether performance improves monotonically, whether error accumulates, and how to best choose noise re-injection schedules compatible with .
- The method’s robustness to different noising schedules is only briefly ablated; a broader study (e.g., rectified flow schedules, learned schedules) and their impact on one-step fidelity is missing.
- Lack of analysis on architectural generality: the approach is shown with DiTs (ImageNet) and a U-Net (CIFAR-10), but behavior with other backbones (e.g., ConvNets, ViTs without DiT-specific heads) and larger/lower-capacity models is not characterized.
- Conditional generality is not tested beyond class labels; how SoFlow handles richer conditions (text prompts, segmentation maps, multimodal inputs) and whether the guided velocity formulation scales to complex conditioning is unknown.
- No evaluation of distributional fidelity beyond FID-50K: diversity, precision/recall, mode coverage, calibration, and semantic alignment under conditional generation are not reported.
- Fairness of cross-method comparisons is limited: differences in training budgets, tokenizers, and evaluation pipelines (e.g., CFG cost counted as “×2” NFE) could confound conclusions; standardized compute-normalized comparisons are missing.
- Generalization across datasets and modalities (e.g., audio, video, 3D) is unvalidated; the feasibility of bi-time conditioning and solution-consistency training in these settings is unexplored.
- Absence of robustness studies: sensitivity to optimizer choices, batch size, label-drop probability, and data corruption/out-of-distribution inputs is not assessed.
- No discussion of failure modes: whether solution-consistency training can collapse to trivial mappings, suffer from teacher drift due to stop-gradient targets, or produce artifacts at specific time regimes is not documented.
- The method depends on to avoid JVP-like terms; the design constraints this imposes on admissible parameterizations and their expressivity are not analyzed.
- Missing theoretical or empirical guarantees of invertibility or measure-preserving properties of along the flow; implications for density modeling, likelihood estimation, or exact transport are unclear.
- Limited exploration of guidance strategies: alternatives to CFG (e.g., log-prob gradient guidance, classifier-based guidance, autoguidance) and their compatibility with solution flows are not studied.
- Unspecified hyperparameters in the main text (e.g., exact for time distributions, final for the best models) hinder reproducibility; a comprehensive recipe is deferred to the appendix/code.
These gaps point to both theoretical and empirical directions: proving consistency of the training objectives, designing variance-controlled guidance estimators, enforcing semigroup properties, broadening evaluations to richer conditions and modalities, and standardizing comparisons under matched compute and tokenization settings.
Practical Applications
Immediate Applications
The following applications can be deployed with current techniques and infrastructure, leveraging SoFlow’s one-step generative modeling, training-time CFG, JVP-free objectives, and drop-in compatibility with DiT architectures and VAEs.
- Low-latency image generation services for creatives and e-commerce (Industry: software, media, advertising, retail)
- What: Replace multi-step diffusion backends with 1-NFE SoFlow for class-conditional image generation (e.g., product mockups, ad creatives, category-specific imagery).
- Tools/products/workflows: A microservice that wraps SoFlow+SD-VAE as a single forward-pass generator with optional 2-NFE “refine” mode; batch A/B testing at scale due to higher throughput.
- Assumptions/dependencies: Requires domain-specific fine-tuning; class labels or other conditions available; VAE encode/decode latency still present; ImageNet-256 class-conditional quality is representative of the target domain.
- On-device or edge deployment for real-time content creation (Industry: mobile, AR/VR, embedded)
- What: Single-pass generation enables real-time filters, stickers, and stylized assets on mobile/AR headsets.
- Tools/products/workflows: Quantized DiT-B/2 or smaller SoFlow variants; fused VAE decode; incremental “edit cycles” using optional few-step recursion.
- Assumptions/dependencies: Model size and memory budgets must fit the device; hardware acceleration for transformer blocks and VAE is desirable; potential quality trade-offs vs large cloud models.
- Cost and energy reduction for GenAI APIs (Industry: cloud, platform providers)
- What: Cut inference NFEs from hundreds to one, reducing GPU-hours and energy usage per image.
- Tools/products/workflows: Integrate SoFlow into serving stacks; new SLAs for sub-50 ms render budgets; carbon reporting dashboards reflecting reduced NFE.
- Assumptions/dependencies: Throughput constrained by VAE and DiT forward pass; quality targets must be met for specific use cases.
- Faster, simpler training pipelines in standard DL frameworks (Academia and Industry: ML research, applied ML)
- What: JVP-free solution consistency loss and Flow Matching loss remove a common training bottleneck and complexity in PyTorch.
- Tools/products/workflows: Open-source training recipes; minimal changes for teams already using DiT; reproducible baselines for one-step models.
- Assumptions/dependencies: Access to GPUs and standard tooling; hyperparameters (λ, p, schedules, velocity mixing m) tuned for target data.
- Stable guided conditional training with reduced variance (Academia/Industry: all sectors using guided generation)
- What: Use training-time CFG and velocity mixing to stabilize guided learning (e.g., using class labels, tags, or simple categorical conditions).
- Tools/products/workflows: Training configs that mix model-predicted guided velocity with stochastic targets; improved convergence for guided one-step models.
- Assumptions/dependencies: Conditions must be available and relevant; mixing ratio m and guidance strength w require tuning to manage variance-performance trade-offs.
- High-throughput data augmentation (Industry/Academia: vision, perception, synthetic data)
- What: Generate large volumes of class-conditional images quickly for model pretraining or long-tail class balancing.
- Tools/products/workflows: Synthetic augmentation pipelines that rely on 1-NFE sampling to control cost.
- Assumptions/dependencies: Synthetic-real domain gap must be validated; licensing/compliance of training data; downstream task performance needs empirical checks.
- Interactive design and rapid iteration loops (Industry: design tools, UX, gaming)
- What: Instant concept iteration in UIs where latency breaks flow (e.g., “generate variant” buttons, storyboard thumbnails).
- Tools/products/workflows: UX components invoking one-step sampling; optional 2-step refinement; non-destructive editing via “re-noise + re-apply” workflow.
- Assumptions/dependencies: Designers accept 256×256 or use super-resolution; content safety/misuse controls integrated.
- Teaching and research baselines for few-step models (Academia: ML curricula, experimentation)
- What: A clean formulation of solution flow learning and a competitive one-step baseline for comparative studies.
- Tools/products/workflows: Course modules and labs on flow/diffusion unification, ODE solution maps, and training-time guidance.
- Assumptions/dependencies: Familiarity with DiT, VAEs, Flow Matching; availability of compute for small-scale experiments (e.g., CIFAR-10).
- Sustainability and policy reporting (Policy and Industry: ESG, procurement)
- What: Demonstrate reduced carbon intensity per generated artifact by moving from multi-step to one-step pipelines.
- Tools/products/workflows: Vendor claims backed by NFE and energy telemetry; procurement criteria that score models by energy per output.
- Assumptions/dependencies: Transparent metering of energy; comparable quality metrics across models; organizational willingness to adopt new KPIs.
Long-Term Applications
These applications require further research, scaling, adaptation to new modalities, or integration with broader systems.
- High-fidelity text-to-image at large scale with one-step sampling (Industry: creative suites, search, ads)
- What: Extend SoFlow to text conditioning at SDXL/DiT-XL resolutions with comparable fidelity to multi-step models.
- Tools/products/workflows: Multimodal conditioning stacks (text encoders), large-scale curriculum training, improved VAEs or latent tokenizers.
- Assumptions/dependencies: Training data scale/licensing; quality and controllability parity with multi-step SOTA; safety filters and watermarking.
- Few-step or one-step video generation (Industry: media, entertainment, marketing)
- What: Apply solution-function learning to spatiotemporal latent flows for rapid video synthesis.
- Tools/products/workflows: 3D or factorized DiT variants over space-time; motion-aware VAEs; temporal guidance during training.
- Assumptions/dependencies: Stability and temporal coherence at high resolutions; significant compute for training; robust evaluation beyond FID.
- 3D and multimodal generative content (Industry: gaming, CAD, digital twins)
- What: One-step generation of 3D assets or cross-modal assets (image+depth, image+audio).
- Tools/products/workflows: Latent representations for 3D (e.g., NeRF/mesh latents), paired-modality flows, conditional guidance for geometry/texture constraints.
- Assumptions/dependencies: Suitable tokenizers/VAEs for 3D; domain datasets and quality metrics; integration with authoring tools.
- Real-time world models and planning priors in robotics (Industry: robotics, autonomy)
- What: Use solution flow maps for rapid state-sampling or scene imagination to support MPC or sim-to-real loops.
- Tools/products/workflows: Conditional flows tied to proprioception/sensor data; tight latency budgets for embedded hardware.
- Assumptions/dependencies: Training on robot/task-specific distributions; safety guarantees; bridging perception-to-action.
- Scientific simulation surrogates via learned solution maps (Academia/Industry: energy, climate, materials)
- What: Learn solution functions for velocity fields arising from physical dynamics, providing fast surrogate solvers for ODE/PDE time-stepping.
- Tools/products/workflows: Domain-specific training using simulator trajectories; error-bounded surrogates for acceleration of parameter sweeps.
- Assumptions/dependencies: Strict physical constraints and stability; generalization across regimes; verification and uncertainty quantification.
- Risk and scenario generation in finance (Industry: finance, insurance)
- What: Rapid sampling of market states or stress scenarios using flow-based distribution transport, enabling more Monte Carlo paths per time budget.
- Tools/products/workflows: SoFlow-style samplers trained on factor models; conditional guidance on macro variables.
- Assumptions/dependencies: Regulatory and model risk governance; alignment with financial time-series dynamics (non-stationarity, tail behavior).
- Privacy-preserving, on-device medical image synthesis (Industry: healthcare)
- What: Generate or augment medical images on local devices for training/education without exporting sensitive data.
- Tools/products/workflows: Hospital-specific fine-tuning; governance overlays; differential privacy or auditing.
- Assumptions/dependencies: Regulatory approvals; rigorous clinical validation; domain shift and bias controls.
- Federated and personalized generative models at the edge (Industry: mobile, consumer apps)
- What: Lightweight fine-tuning of SoFlow on user devices for personalized styles with minimal rounds and energy.
- Tools/products/workflows: Federated optimization; secure aggregation; local safety filters.
- Assumptions/dependencies: Efficient adapters/LoRA for DiT; privacy safeguards; acceptable on-device compute.
- Hardware-software co-design for one-pass generative inference (Industry: semiconductors, systems)
- What: Accelerators optimized for single forward-pass generation plus VAE decode, exploiting predictable memory access patterns.
- Tools/products/workflows: Kernel fusion for DiT blocks; specialized VAE decoders; SoFlow-aware compilers.
- Assumptions/dependencies: Sufficient adoption to justify silicon investment; stable architectures and operator sets.
- Content safety and provenance tailored to one-step models (Policy/Industry: platforms, regulators)
- What: Watermarking and safety classifiers integrated tightly into a one-step pipeline, with minimal overhead.
- Tools/products/workflows: Embedded watermark during the single pass; post-generation safety checks; audit logs linking energy and content metrics.
- Assumptions/dependencies: Robust watermark resilience; standards for provenance; industry cooperation.
Notes on Feasibility and Dependencies Across Applications
- Model scope: Demonstrated on ImageNet 256×256 (class-conditional) and CIFAR-10 (unconditional). Extension to text-to-image, higher resolutions, and other modalities will need further research and scaling.
- Quality–latency trade-offs: One-step generation drastically cuts latency and cost; for some use cases, optional 2–4 NFE can improve quality while remaining fast.
- Architectural and data dependencies: SoFlow is shown with DiT backbones and SD-VAE latents; results depend on tokenizer quality, data scale, and condition availability.
- Training stability: Performance hinges on hyperparameters (λ, p, guidance strength w, velocity mix m, sampling schedules). Re-tuning is expected per domain.
- Safety and compliance: As generation becomes cheaper and faster, safety controls, watermarking, and policy alignment should be integrated early.
Glossary
- Classifier-Free Guidance (CFG): A technique that improves conditional generation by combining conditional and unconditional predictions, controlled by a guidance strength. "Classifier-Free Guidance (CFG) is a standard technique in diffusion models for enhancing conditional generation."
- Conditional marginal velocity field: The expected instantaneous transport velocity conditioned on data and a label/condition, used to define guided dynamics. "v(x_t,t\mid{c}) ... denotes the conditional marginal velocity field"
- Consistency Models (CMs): Generative models that map noisy inputs directly to clean outputs in one or few steps by enforcing consistency across timesteps. "Consistency Models (CMs) collapse noised inputs directly to clean data, enabling one- or few-step generation"
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion/flow-based generative modeling. "the same Diffusion Transformer (DiT) architecture"
- Euler parameterization: A linear-in-time parameterization of the solution map that enforces boundary conditions and simplifies gradients. "including the Euler parameterization and the trigonometric parameterization:"
- FID-50K: Fréchet Inception Distance computed on 50,000 generated samples; a standard image synthesis quality metric. "achieve better FID-50K scores than MeanFlow models"
- Flow Matching: A framework that learns a velocity field transporting a simple prior distribution to the data distribution. "Flow Matching offers a more direct alternative, modeling the velocity fields that transport a simple prior distribution to a complex data distribution."
- Flow Matching loss: A supervised objective that aligns a model’s predicted velocity with a target velocity derived from the noising process. "we propose a Flow Matching loss and a solution consistency loss to train our models."
- Guided marginal velocity field: The linear combination of conditional and unconditional velocity fields used for classifier-free guidance during training. "we first introduce the ground-truth guided marginal velocity field:"
- Initial value problem (IVP): An ODE problem specified by an equation and an initial state, solved here from t=1 to t=0 to generate samples. "solving the initial value problem (IVP) of the following velocity ordinary differential equation (ODE)"
- Jacobian-vector product (JVP): The product of a Jacobian matrix and a vector; often expensive to compute in deep learning frameworks. "does not require the calculation of the Jacobian-vector product (JVP)"
- Lipschitz continuous: A smoothness condition bounding how fast a function can change; ensures uniqueness and stability of ODE solutions. "globally Lipschitz continuous with respect to x_t"
- Logit-normal distribution: A distribution obtained by applying the sigmoid to a normal variable; used to sample timesteps. "sampling t from a logit-normal distribution."
- Marginal velocity field: The expected velocity at a state-time pair under the noising process, marginalizing latent variables. "the marginal velocity field associated with the noising process is defined as"
- MeanFlow: A recent few-step generative modeling approach that averages velocities over intervals. "achieve better FID-50K scores than MeanFlow models"
- Noising process: A forward process that blends data and noise via time-dependent coefficients to define trajectories. "A general noising process is defined as"
- Number of function evaluations (NFE): The count of forward model calls during sampling; lower NFE implies faster generation. "we report the number of function evaluations (NFE), with a particular focus on the single-step (1-NFE) scenario."
- Positional embeddings: Encodings of scalar or pairwise time inputs fed to a model to represent temporal positions. "feeding the positional embeddings of their difference, s−t."
- Solution consistency loss: A loss enforcing consistency of the learned solution map across nearby times using model predictions as targets. "and a solution consistency loss to train our models."
- Solution function: A learned bi-time map that takes a state at time t to the evolved state at time s under the velocity ODE. "we denote it as the solution function in this paper."
- Stop-gradient: An operation that prevents gradients from flowing through a target or branch during optimization. "θ- means applying the stop-gradient operation to the parameters"
- Stochastic interpolants: Stochastic trajectories that interpolate between data and prior, used to define transport and training targets. "Stochastic interpolants build upon these concepts by explicitly defining stochastic trajectories between the data and prior distributions"
- U-Net: A convolutional encoder–decoder architecture with skip connections, used here for pixel-space CIFAR-10 experiments. "we adopt the U-Net architecture"
- VAE: Variational Autoencoder; an encoder–decoder that maps images to and from a continuous latent space used for training and sampling. "operate within the latent space of a pre-trained VAE"
- Velocity mixing ratio: A scalar that blends high-variance stochastic velocity targets with lower-variance model-predicted guided velocities. "acts as a velocity mixing ratio."
- Velocity ODE: The ordinary differential equation whose right-hand side is the learned velocity field governing data transport. "the velocity ODE defined by Flow Matching"
Collections
Sign up for free to add this paper to one or more collections.

