TUNA: Taming Unified Visual Representations for Native Unified Multimodal Models
Abstract: Unified multimodal models (UMMs) aim to jointly perform multimodal understanding and generation within a single framework. We present TUNA, a native UMM that builds a unified continuous visual representation by cascading a VAE encoder with a representation encoder. This unified representation space allows end-to-end processing of images and videos for both understanding and generation tasks. Compared to prior UMMs with decoupled representations, TUNA's unified visual space avoids representation format mismatches introduced by separate encoders, outperforming decoupled alternatives in both understanding and generation. Moreover, we observe that stronger pretrained representation encoders consistently yield better performance across all multimodal tasks, highlighting the importance of the representation encoder. Finally, in this unified setting, jointly training on both understanding and generation data allows the two tasks to benefit from each other rather than interfere. Our extensive experiments on multimodal understanding and generation benchmarks show that TUNA achieves state-of-the-art results in image and video understanding, image and video generation, and image editing, demonstrating the effectiveness and scalability of its unified representation design.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces Tuna, a single AI model that can both understand and create pictures and videos. Instead of using separate parts for “understanding” and “making” visuals, Tuna uses one shared way to represent images and videos inside the model. This “one shared language” for visuals helps the model work smarter, faster, and better across many tasks.
The main questions the paper asks
- Can one model, using one shared visual representation, do many things well: answer questions about images, describe videos, create images from text, edit images, and make videos?
- Is a unified visual representation better than using different representations for understanding and generation?
- Does giving the model a stronger “vision brain” (a better pretrained visual encoder) make everything better?
- If we train understanding and generation together, do they help each other instead of getting in the way?
How Tuna works (with everyday analogies)
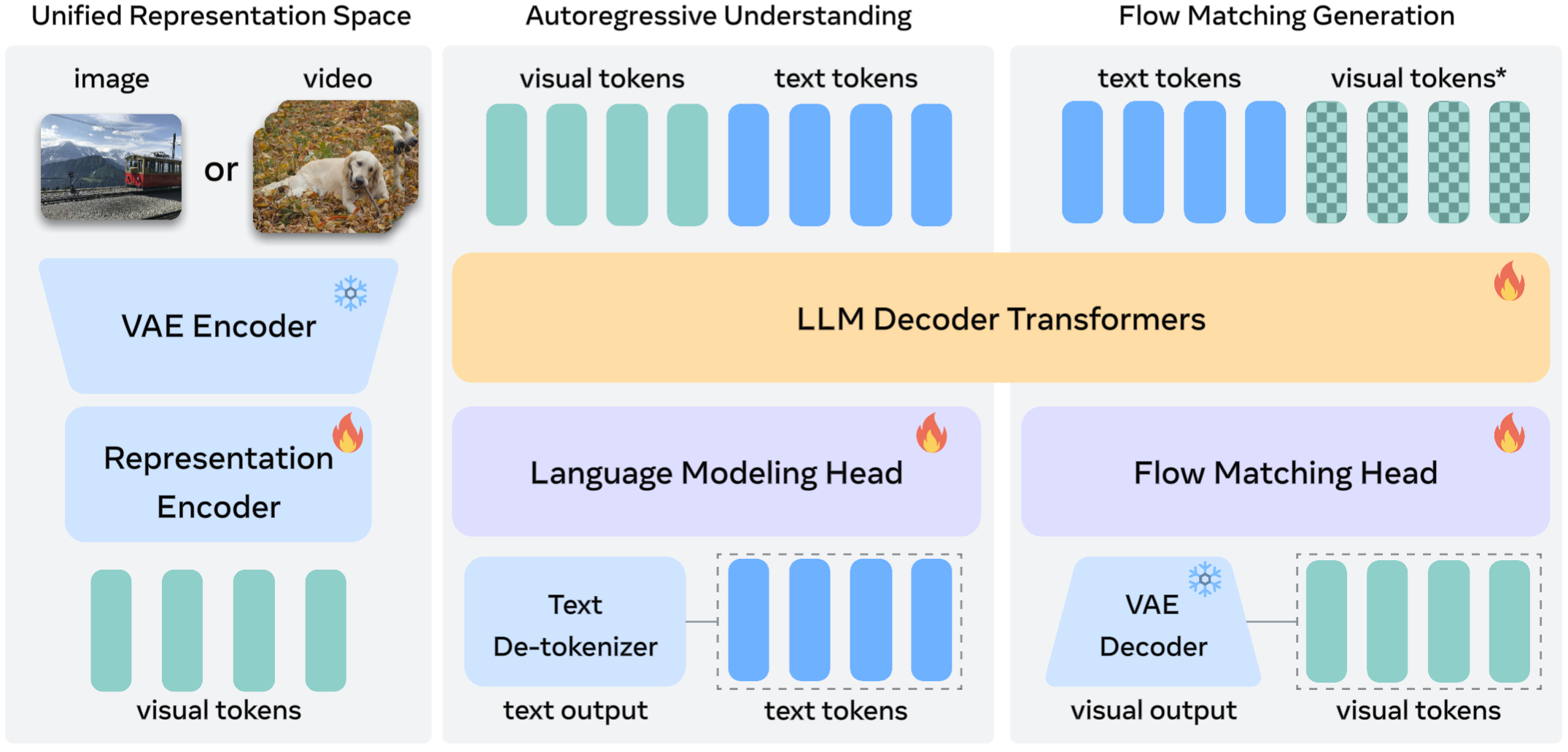
Think of Tuna as a team with three key members:
- A visual compressor (VAE encoder): Like shrinking a large photo into a small, detailed code so it’s easier to work with but still keeps important details.
- A meaning finder (representation encoder): Like a teacher that looks at the compressed code and pulls out the important “what’s in this picture?” clues (objects, colors, positions, text in images).
- A language-and-creation brain (LLM decoder + generator head): Like a smart writer that can read instructions, reason about visuals, answer questions, and also draw images or videos based on what it learned.
Here’s the big idea: Tuna “cascades” the compressor into the meaning finder. That means it first turns an image/video into a compact code (continuous VAE latents), then feeds that into a visual encoder that extracts high-level meaning. This creates a single, unified kind of visual token the model uses for everything.
Why unify? Imagine trying to combine two maps of the same city that use different scales and symbols—confusing! Many past models used separate visual “formats” for understanding and generation, which don’t match well (different sizes, time steps, and channels). Tuna uses one standard format so every part of the model speaks the same visual language.
How it generates text vs. images/videos:
- Text generation (answers, descriptions): It writes one word at a time (autoregressive), like normal chatbots.
- Image/video generation: It uses a method called flow matching (similar to diffusion). Think of starting from noise and steadily “un-blurring” it into a clear picture that follows the instructions.
Training, step by step
Tuna learns in three stages:
- Stage 1: Pretrain the visual part and the generator head
- Tasks: caption images (to learn meaning) and make images from text (to learn drawing).
- Goal: Build a strong unified visual representation and a good starting point for image creation.
- Stage 2: Train the whole model together
- Keep doing captioning and text-to-image.
- Add instruction-following with images, image editing, and video captioning.
- Goal: Teach the model to follow complex instructions and handle videos.
- Stage 3: Supervised fine-tuning (polish)
- Use high-quality datasets for image/video instructions, editing, and generation.
- Smaller learning rate to refine skills.
Why this helps: Understanding tasks (like “what’s in this image?”) teach the model better visual concepts, which improves generation. Generation tasks (like “draw a red car on a beach”) force the model to handle precise details, which also improves understanding. Sharing one representation lets these skills boost each other.
What the researchers found (and why it matters)
- Unified beats split: Tuna’s single shared visual representation outperforms models that use separate representations for understanding and generation. It avoids format mismatches and is more efficient.
- Better visual encoders help everything: When Tuna uses a stronger pretrained representation encoder, it improves across all tasks—understanding, generation, and editing. Think of it as giving the model a sharper pair of glasses.
- Mutual benefit: Training understanding and generation together helps both, rather than causing interference—because they share one visual “language.”
- Strong results across the board:
- Image and video understanding: State-of-the-art or best-in-class on many benchmarks (for example, MMStar ~61.2% with the 7B model).
- Image generation: Top scores on GenEval (around 0.90 for the 7B model), DPG-Bench, and strong text rendering in OneIG-Bench.
- Image editing: Competitive high-quality edits guided by instructions.
These wins show the unified design scales well and works on both small and larger model sizes (1.5B and 7B parameters).
Why this research is important
- One model for many tasks: Tuna moves us toward AI that can seamlessly switch between understanding and creating, across images and videos, without glueing together separate systems.
- Simpler and more efficient: A single visual format reduces complexity and cost, making training and use more practical.
- Better foundations for future AI: The idea of building on continuous, unified visual representations—plus combining text writing with diffusion-style image/video creation—could become a standard blueprint for future multimodal AI.
- Real-world impact: From smarter visual assistants and better creative tools to more reliable robotics and education apps, unified multimodal models can understand context and create precise visuals in response to instructions.
In short, Tuna shows that “one shared visual language” inside a model isn’t just cleaner—it’s also stronger, leading to better understanding, generation, and editing all in the same system.
Knowledge Gaps
Below is a single, consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Quantitative efficiency analysis is missing: the paper claims unified representations simplify training and improve efficiency versus decoupled/multi-encoder MoE designs, but provides no measurements of training/inference latency, memory footprint, or throughput under matched settings.
- Video capabilities are under-evaluated and partially unsupported: the 7B model is trained “without video data” due to compute cost, and there are no quantitative video understanding/generation results or long-horizon benchmarks validating the windowed attention strategy.
- Temporal modeling limitations are unaddressed: processing video by reshaping frames into the batch dimension means each 4-frame window is handled independently; it is unclear how the model captures long-range temporal dependencies, cross-window coherence, motion consistency, or scene-level continuity.
- High-resolution generation is not studied: training is at 512×512 with “similar token counts” for other aspect ratios; no experiments assess fidelity, realism, or stability beyond 512 resolution or the cost/quality trade-offs of scaling resolution.
- Sensitivity to the VAE choice and compression factors is unexplored: the approach is tied to Wan 2.2’s 16× spatial and 4× temporal downsampling; there is no analysis of how different VAEs (e.g., compression ratios, KL regularization strengths) affect understanding and generation.
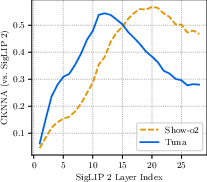
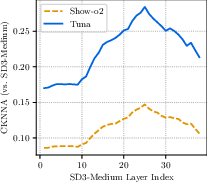
- Dependence on SigLIP 2 as the representation encoder is not probed: the paper asserts stronger representation encoders help, but offers no systematic comparison across encoders (e.g., DINOv2, MAR, CLIP variants) or whether joint training on latents destabilizes or improves different architectures.
- Patch-embedding modification is ad hoc and unablated: replacing the 16×16 patch embedding with a randomly initialized 1×1 layer to match VAE latents is plausible, but there are no ablations comparing alternatives (kernel sizes, learned up/downsampling, cross-attention bridges) or quantifying the impact.
- Noise-timestep conditioning design is not analyzed: a single prepended timestep token and uniform sampling of t are used; there is no study on alternative schedules, multi-token conditioning, or the effect of training the representation encoder on a mixture of clean/noised latents for understanding.
- Parameter sharing between LLM decoder and flow-matching head is ambiguous: the flow head “shares the LLM decoder architecture” but is “randomly initialized”; it is unclear whether weights are shared or separate, and how different sharing strategies affect interference, capacity, and synergy.
- Task interference versus synergy is not causally validated: while the paper claims understanding and generation mutually benefit in a unified space, it lacks controlled experiments that isolate mixing ratios, curriculum schedules, and gradient interference (e.g., task-specific adapters, PCGrad) and quantify gains/losses.
- Training data transparency is limited: datasets for captioning, instruction following, editing, and video are not described in detail (size, domains, licenses, quality control), making it hard to assess data leakage, benchmark contamination, or generalization beyond known distributions.
- Robustness and safety are unexamined: no analyses of out-of-distribution robustness, adversarial inputs, compositional consistency under perturbations, bias/fairness in generations/answers, safety guardrails, or content control are provided.
- Editing evaluation is incomplete: the paper claims strong image editing but presents no quantitative editing benchmarks (e.g., instruction fidelity, identity preservation, consistency metrics), user studies, or ablations across edit types and difficulty.
- Text rendering and OCR performance are promising but not deeply analyzed: strong OneIG/OCRBench scores are reported, yet there is no breakdown by fonts, layouts, crowded scenes, non-Latin scripts, or low-light/low-res conditions.
- Position encoding choices are not ablated: the adoption of multimodal 3D-RoPE for interleaved sequences is plausible, but there is no comparison to alternatives (e.g., ALiBi, learned positional encodings, modality-specific RoPE variants) or their effects on cross-modal alignment.
- Scaling laws and capacity limits are unclear: results at 1.5B/7B are shown, but no systematic scaling analysis (data vs. parameters vs. tokens) quantifies how unified representations and joint objectives scale, or when diminishing returns/overfitting occur.
- Mixed-objective optimization details are not specified: the paper lacks concrete mixing ratios, sampling strategies, and loss balancing among captioning, generation, instruction following, and editing; without these, reproducibility and stability insights are limited.
- Generalization to additional modalities is open: the design targets images and videos; it remains unknown how the unified latent–representation cascade would extend to audio, 3D, or sensor streams, and whether similar benefits hold.
- Evaluation fairness across baselines is uncertain: several baselines use different data volumes, rewriters, or model sizes; matched-data/matched-size comparisons, or with/without LLM rewriters, are needed to isolate architectural contributions.
- Inference-time behavior under interleaved multimodal prompts is not characterized: while interleaved sequences are supported, latency, memory usage, and failure modes on long, complex, multi-turn interactions (with mixed visuals) are not reported.
- Practical deployment constraints are not discussed: the unified framework’s engineering footprint (VRAM requirements, batching strategies, KV-cache sizes for long sequences/videos, quantization effects) and its cloud/edge feasibility are not assessed.
- Theoretical understanding of why unified visual representations help is limited: beyond empirical gains, there is no formal analysis of representation alignment, information flow between VAE latents and semantic encoders, or conditions under which the unified space avoids format conflicts and improves transfer.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage Tuna’s unified visual representation, strong image/video understanding, high-fidelity generation, and editing capabilities.
- Sector: creative software and marketing — Use case: unified content creation assistant
- What: Generate and edit on-brand images and short videos from complex, interleaved text instructions (accurate text rendering, consistent colors, attributes, and layout).
- Potential products/workflows: “Tuna Studio” plugin for Adobe/Figma; batch creative variant generator; prompt-to-campaign tool with iterative editing.
- Assumptions/dependencies: Safety filters and brand compliance layers; GPU inference; rights management for training data; human-in-the-loop QC.
- Sector: e-commerce — Use case: product photography and catalog generation
- What: Text-conditional generation of product images with correct attributes (counting, color, position), plus text overlays (pricing, badges).
- Potential products/workflows: Listing generator; automated A/B ad creative; templated background swaps via text prompts.
- Assumptions/dependencies: Attribute verification; SKU metadata integration; approval workflows; explainability/traceability for compliance.
- Sector: enterprise document analytics — Use case: chart/diagram understanding and OCR
- What: Extract and reason over charts (ChartQA), diagrams (AI2D), and embedded text (OCRBench); summarize visuals into structured data.
- Potential products/workflows: “DocAI” pipeline for BI dashboards; PDF-to-knowledge graph; compliance document triage with visual Q&A.
- Assumptions/dependencies: Domain-specific fine-tuning; veracity checks; data governance; legal/privacy constraints.
- Sector: accessibility and media — Use case: image and video captioning for alt-text and subtitles
- What: Generate informative captions for images and short videos; improve discoverability and accessibility on social platforms.
- Potential products/workflows: “CaptionBot” API integrated with CMS; batch captioning for content libraries; newsroom assistants.
- Assumptions/dependencies: The 1.5B variant supports video; the 7B variant (as reported) was trained without video data; latency for near real-time; privacy.
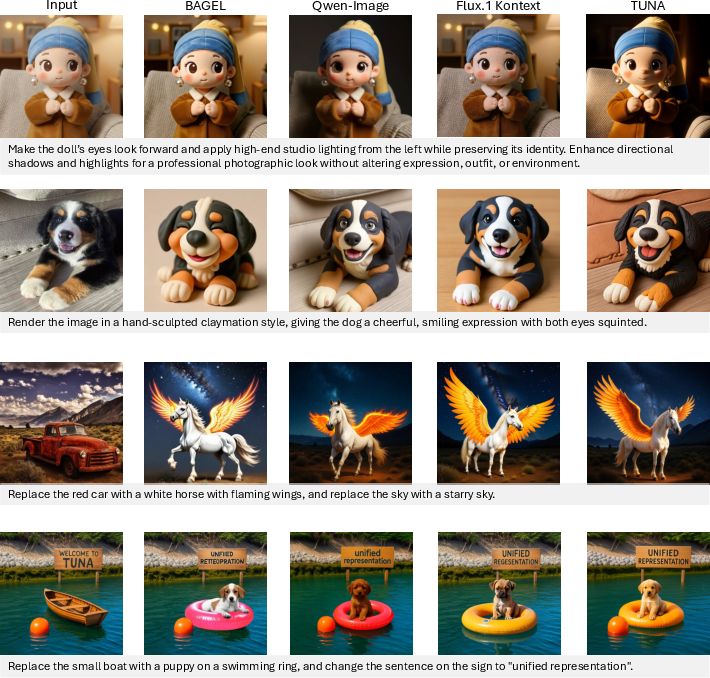
- Sector: photo apps and design tools — Use case: text-guided image editing and compositing
- What: Inpainting, background removal/replacement, object insertion/removal, style adjustments in one model.
- Potential products/workflows: “Tuna Edit API” for mobile and web; non-destructive edit layers; iterative edit chains guided by natural language.
- Assumptions/dependencies: UI integration; compute costs; content safety (avoid harmful edits); provenance tracking.
- Sector: content moderation and trust/safety — Use case: multimodal policy enforcement
- What: Detect and explain risky content in images/videos; generate compliant alternatives or redact sensitive elements via editing.
- Potential products/workflows: Moderation queue triage; automated redaction; “compliance rewriter” for ad creatives.
- Assumptions/dependencies: Fairness and bias auditing; appeals workflow; threshold tuning to manage false positives/negatives.
- Sector: search and knowledge management — Use case: multimodal search and retrieval
- What: Index unified visual tokens alongside text to enable cross-modal retrieval (find visuals by text and vice versa); improve RAG pipelines.
- Potential products/workflows: Enterprise multimodal search; “visual RAG” that fuses Tuna tokens with LLM context.
- Assumptions/dependencies: Efficient indexing of unified latents; relevance feedback; access controls.
- Sector: education — Use case: lesson material generation and diagram Q&A
- What: Produce accurate figures/diagrams from textual briefs; tutor-like Q&A over images/diagrams; generate exam items with visual reasoning.
- Potential products/workflows: Teacher assistant; curriculum builder; auto grading for visual questions.
- Assumptions/dependencies: Content accuracy and bias controls; alignment to curricula; safeguards for student privacy.
- Sector: robotics and autonomy (data ops) — Use case: synthetic data generation
- What: Generate domain-specific images/videos for perception model pretraining; iterate on scenarios with textual control (lighting, occlusions, object counts).
- Potential products/workflows: “Synthetic Dataset Factory” with prompt templates; scenario libraries for QA.
- Assumptions/dependencies: Domain gap minimization; labeling and validation; not real-time on edge hardware.
- Sector: software engineering — Use case: UI screenshot analysis and guidance
- What: Extract text, detect elements, and reason over UI layouts; generate user-facing step-by-step instructions or bug repro steps with annotated visuals.
- Potential products/workflows: QA assistant; support chatbot that accepts screenshots; onboarding content generator.
- Assumptions/dependencies: Robustness across diverse UI frameworks; privacy of user data.
- Sector: finance and compliance — Use case: report visualization parsing
- What: Extract data from charts/figures in regulatory filings; cross-check reported metrics; generate visual summaries for risk reviews.
- Potential products/workflows: Visual ETL in analytics stacks; “chart-to-table” converters; audit workbench.
- Assumptions/dependencies: High-precision extraction; human validation; secure deployment and lineage tracking.
- Sector: research and model training — Use case: more efficient UMM development
- What: Adopt Tuna’s unified representation cascade (VAE + strong representation encoder) to reduce decoupling overhead and improve cross-task synergy.
- Potential products/workflows: Training recipes; ablation tooling; unified data pipelines for captioning + T2I + editing.
- Assumptions/dependencies: Access to pretrained encoders (e.g., SigLIP 2, Wan VAE); mixed-modality corpora; large-scale compute.
Long-Term Applications
These opportunities require further research, scaling, video training, or engineering to meet performance, safety, or real-time constraints.
- Sector: consumer AI and productivity — Use case: native multimodal assistants that both “see” and “imagine”
- What: A single agent that reads documents, watches short videos, reasons, and generates tailored visuals or edits in-context.
- Potential products/workflows: “Unified Copilot” for knowledge workers; meeting assistant that creates diagrams from discussion; scenario simulators.
- Assumptions/dependencies: Stronger long-context handling; robust factuality; richer tool-use orchestration; guardrails.
- Sector: advertising, entertainment, and education — Use case: high-fidelity video generation and editing
- What: Long-form video synthesis, shot planning, stylistic continuity, and text-accurate overlays; classroom lesson videos generated from scripts.
- Potential products/workflows: Studio-grade prompt-to-video; auto-cut platforms; visual lesson builders.
- Assumptions/dependencies: Large-scale video training (7B variant currently without video); rendering pipelines; rights management; compute scaling.
- Sector: AR/VR and accessibility — Use case: real-time visual understanding and augmentation
- What: On-device assistance that recognizes scenes and overlays generated guidance or translations; “prosthetic vision” aides.
- Potential products/workflows: Smart glasses; live diagram explanations; AR captioning.
- Assumptions/dependencies: Edge compression/quantization; low-latency 3D VAE inference; privacy and safety.
- Sector: robotics/autonomy — Use case: perception-planning via unified “see-and-generate” models
- What: Use generation to simulate candidate futures; robust multimodal understanding for manipulation and navigation.
- Potential products/workflows: Simulation-in-the-loop training; hybrid vision/planning stacks.
- Assumptions/dependencies: Controlled hallucination; causal reasoning; safety certification; real-time constraints.
- Sector: scientific communication — Use case: data-to-figure synthesis with verifiable accuracy
- What: From structured data and textual findings to precise plots, diagrams, and visual abstracts; figure regeneration/reproducibility.
- Potential products/workflows: “Figure-as-code” assistants; paper-to-figure converters; lab notebooks with automatic visuals.
- Assumptions/dependencies: Grounded generation (links to data provenance); domain-specific validation; journal policies.
- Sector: digital twins and industrial ops — Use case: synthetic visual simulations of processes and failures
- What: Stress-test pipelines with generated images/videos of edge cases (rare defects, occlusions, lighting).
- Potential products/workflows: Scenario generators for inspection systems; continuous QA in manufacturing.
- Assumptions/dependencies: Accurate domain modeling; safety and reliability thresholds; integration with IoT telemetry.
- Sector: mobile/edge deployment — Use case: compact UMMs with unified latents
- What: Smaller models that retain Tuna’s unified representation to enable multimodal features on devices.
- Potential products/workflows: On-device editors; camera assistants; offline document analyzers.
- Assumptions/dependencies: Distillation and quantization for the LLM decoder and flow head; memory-efficient VAE; hardware acceleration.
- Sector: policy and governance — Use case: standards for provenance, watermarking, and multimodal auditing
- What: Establish benchmarks and protocols (GenEval-like) for visual correctness; C2PA-style provenance for generated edits/videos.
- Potential products/workflows: Auditing dashboards; “compliance scorecards” for multimodal systems; content credentials baked into generation.
- Assumptions/dependencies: Industry consensus; robust watermarking resilient to edits; regulatory alignment.
- Sector: finance and risk — Use case: automated visual compliance and scenario generation
- What: Detect misleading charts, simulate alternative visualizations to test risk narratives, and propose corrections.
- Potential products/workflows: “Visual compliance auditor”; explainable chart validators; scenario generation for stress testing.
- Assumptions/dependencies: High-precision reasoning; audit trails; domain expertise in-the-loop.
- Sector: sustainability in AI infrastructure — Use case: energy-aware training/inference via unified representations
- What: Reduce redundancy from decoupled models; shared visual representation lowers training/inference costs for multimodal fleets.
- Potential products/workflows: Fleet planners; cost/performance dashboards; model consolidation initiatives.
- Assumptions/dependencies: Careful ablations to confirm efficiency gains; operational tooling for rollout; workload profiling.
Cross-cutting assumptions and dependencies
- Model components: Access to compatible pretrained encoders (e.g., 3D causal VAE, SigLIP 2), adherence to their licenses, and robust connectors (MLP, AdaLN-Zero).
- Data: Diverse, lawful, and bias-mitigated multimodal corpora; domain-specific fine-tuning for regulated sectors.
- Safety and reliability: Hallucination controls, factuality checks, and human-in-the-loop validations; provenance tracking and content credentials for generation/editing.
- Compute and latency: GPU/accelerator capacity for training/inference; engineering for low-latency video; window-based attention helps but may still require optimization.
- Integration: APIs and SDKs that fit existing design, analytics, and CMS pipelines; monitoring for performance drift and error modes.
Glossary
- ablation study: A systematic set of experiments where components are removed or varied to measure their impact on performance. "We further perform a comprehensive ablation study, demonstrating the superiority of our unified visual representation design over existing methods such as Show-o2 and other models employing decoupled representations."
- AdaLN-Zero: An adaptation of layer normalization with zero-initialized conditioning parameters, used to inject timestep or other conditioning into model layers. "adds timestep conditioning via AdaLN-Zero, following Show-o2~\citep{xie2025show} and DiT~\citep{peebles2023scalable}."
- AdamW: An optimizer that decouples weight decay from gradient updates, improving regularization compared to standard Adam. "optimize the representation encoder, projection layers, and diffusion head with AdamW~\citep{loshchilov2017decoupled} using a learning rate of ."
- autoregressive: A generation paradigm that produces outputs token-by-token by conditioning each prediction on previously generated tokens. "generates new text tokens and denoised images through autoregressive next-token prediction and flow matching."
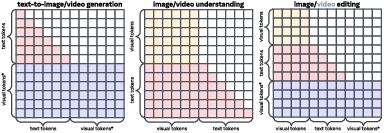
- bidirectional attention mask: An attention configuration allowing tokens to attend to all other tokens in both past and future positions. "we apply a causal attention mask on language tokens and a bidirectional attention mask on visual tokens within the LLM decoder layers"
- causal attention mask: An attention constraint that restricts each token to attend only to previous tokens, enforcing left-to-right generation. "we apply a causal attention mask on language tokens and a bidirectional attention mask on visual tokens within the LLM decoder layers"
- causal VAE: A variational autoencoder with causal (time-ordered) structure, often used for video latents to respect temporal dependencies. "we apply the 3D causal VAE encoder from Wan 2.2~\citep{Wan2.2}"
- CLIP: A vision-LLM that learns joint image-text embeddings via contrastive training, widely used as a semantic representation encoder. "rely on continuous semantic features (e.g, CLIP~\citep{radford2021learning} features)"
- contrastive learning: A training objective that pulls semantically similar pairs together and pushes dissimilar pairs apart in representation space. "Image captioning has also been shown to provide semantic richness comparable to contrastive learning~\citep{tschannen2023image}"
- DINOv2: A strong self-supervised vision transformer providing high-quality semantic features useful for alignment and generation. "REPA~\citep{yu2024representation} demonstrates that diffusion transformers benefit from aligning intermediate features with pretrained representation encoders like DINOv2~\citep{oquab2023dinov2}."
- einops notation: A concise tensor manipulation notation/library used to express complex reshaping and rearrangement operations. "In einops notation, the unified visual representation can be expressed as:"
- end-to-end: A training or processing approach where all system components are optimized jointly, without hand-engineered interfaces. "This unified representation space allows end-to-end processing of images and videos for both understanding and generation tasks."
- flow matching: A training method for generative models that learns a velocity field to transport noise to data, enabling diffusion-like generation. "The decoder performs autoregressive text generation for understanding tasks and flow-matching-based visual generation for generation tasks."
- flow matching head: A network head specialized to predict velocities for flow matching-based generation from multimodal tokens. "we feed the full token sequence to a randomly initialized flow matching head to predict the velocity for flow matching."
- KL-regularized: Refers to using Kullback–Leibler divergence as a regularizer in VAEs to structure latent distributions. "operating in a continuous (e.g, KL-regularized) VAE latent space"
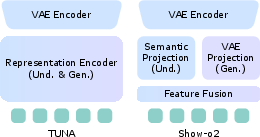
- late-fusion strategy: A feature-integration approach that combines outputs from separate encoders at a later stage rather than at the input or early layers. "Show-o2~\citep{xie2025show} attempts to mitigate this issue by fusing SigLIP~\citep{zhai2023sigmoid} and VAE~\citep{wan2025wan} features through a late-fusion strategy."
- latent diffusion models: Diffusion generative models that operate in a compressed latent space rather than pixel space for efficiency and fidelity. "latent diffusion models are generally favoured over pixel diffusion \citep{zheng2025diffusion}."
- LLM decoder: The decoder component of a LLM used to process and generate sequences, here extended to multimodal inputs. "feed the combined sequence into an LLM decoder (Qwen-2.5~\citep{bai2025qwen2}) for joint multimodal processing."
- MAR encoder: A masked autoregressive visual encoder used to produce discrete or structured representations for unified multimodal models. "Harmon~\citep{wu2025harmonizing} utilizes the MAR encoder~\citep{li2024autoregressive}."
- MLP connector: A small multilayer perceptron used to project encoder features into a unified token space compatible with the decoder. "Finally, we apply a two-layer MLP connector to obtain the unified visual representations ."
- MoE-style architectures: Mixture-of-experts designs that route inputs among specialized subnetworks, often increasing parameter count and cost. "often adopt MoE-style architectures to handle different visual encoders, introducing additional parameters that increase training and inference costs."
- multimodal 3D-RoPE: Three-dimensional rotary position embeddings adapted for sequences that interleave text and visual tokens. "we adopt multimodal 3D-RoPE~\citep{seawead2025seaweed, su2024roformer} over the concatenated text-visual sequence"
- native UMMs: Unified multimodal models pretrained jointly on both understanding and generation objectives in a single architecture. "We define native UMMs as models that are pretrained jointly on both understanding and generation objectives"
- patch embedding layer: The initial transformer layer that converts image patches into token embeddings at a specified patch size. "we replace SigLIP 2âs original 1616 patch embedding layer with a randomly initialized 11 patch embedding layer"
- RAE: A method that reconstructs images by encoding them with a frozen representation encoder into latent space, demonstrating semantic latents suffice. "Concurrent to our work, RAE~\citep{zheng2025diffusion} employs a frozen representation encoder to encode images into latent representations, showing that pretrained semantic features alone can reconstruct input images effectively."
- REPA: A representation alignment technique that improves diffusion transformers by aligning intermediate features to a pretrained encoder. "REPA~\citep{yu2024representation} demonstrates that diffusion transformers benefit from aligning intermediate features with pretrained representation encoders like DINOv2~\citep{oquab2023dinov2}."
- representation encoder: A vision encoder that extracts high-level semantic features from inputs or latents for understanding and generation. "stronger pretrained representation encoders consistently yield better performance across all multimodal tasks"
- SigLIP 2: A strong vision encoder trained with a sigmoid-based contrastive objective, used here to extract semantic features from VAE latents. "we use the SigLIP 2 vision encoder (patch size 16, pretrained resolution 512)"
- timestep token: A special token indicating the diffusion/generation timestep, prepended to visual tokens to condition the model. "we prepend a timestep token representing the sampled timestep to "
- VAE encoder: The encoder of a variational autoencoder that compresses images or videos into continuous latent representations. "Our model employs a VAE encoder and a representation encoder to construct unified visual representations."
- VQ-VAE: Vector-quantized variational autoencoder that produces discrete latent tokens for image/video representation and generation. "Chameleon~\citep{team2024chameleon} and Transfusion~\citep{zhou2024transfusion} use VQ-VAE~\citep{esser2021taming}"
- window-based attention: An attention scheme that processes tokens in local windows to reduce sequence length and computation, especially for video. "we apply a window-based attention mechanism by reshaping the frame dimension into the batch dimension in ."
Collections
Sign up for free to add this paper to one or more collections.

