- The paper identifies logit-attention divergence, showing that output logits are dominated by structural positional priors while internal attention remains semantically precise.
- It introduces a training-free, attention-guided calibration framework that uses counterfactual bias estimation and Bayesian-inspired correction to restore permutation invariance.
- Experimental results reveal significant accuracy gains (e.g., from 67.52% to 98.66%) in multi-image retrieval tasks, demonstrating the method's robustness and efficiency.
Logit-Attention Divergence and Attention-Guided Calibration for Position Bias in Multi-Image Retrieval
Motivation: Position Bias in MLLMs
Multimodal LLMs (MLLMs) have demonstrated notable performance in tasks requiring cross-modal reasoning with multi-image contexts, such as retrieval and visual understanding. However, these models are subject to severe position bias, where prediction outcomes are dominated by input order instead of visual-semantic alignment. Empirical analyses reveal irrational preferences for specific candidate positions; for instance, in 8-candidate retrieval conditions, models exhibit disproportionate selection rates for certain positions (e.g., 48.96% at Position 7, 0.00% at Position 4), independent of semantic content (Figure 1).
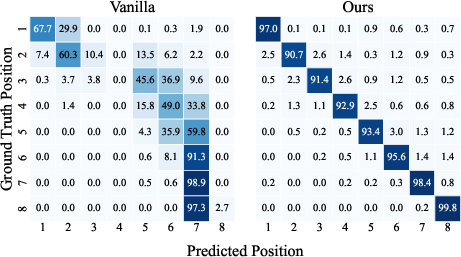
Figure 1: The Vanilla model (Left) demonstrates strong vertical stripe patterns indicative of position bias, whereas attention-guided calibration (Right) restores the expected diagonal pattern thus correctly aligning predictions with ground truth.
This position bias can severely distort evaluation, inflating or collapsing accuracy scores depending on the alignment between ground truth and favored positions, and stems from the autoregressive architecture and positional encoding strategies borrowed from text LLMs. Existing calibration methods, such as logit reweighting via global priors (PriDe), prompt-based interventions, and ensemble-style self-consistency, have limited effect, failing to account for visually-conditioned and instance-dependent bias manifestations.
Logit-Attention Divergence: Diagnostic Insight
A key contribution is the identification of the Logit-Attention Divergence phenomenon. It is observed that although output logits are dominated by structural positional priors, the model's internal attention mechanisms remain semantically precise, focusing accurately on the relevant image regions associated with the textual query. This can be quantified by examining position-conditioned logit profiles across multiple ground truth (GT) positions: while logits display strong structural regularities and homogenization within GT categories (Figure 2), the final prediction remains insensitive to permutations and thus fails to reflect true semantic alignment.
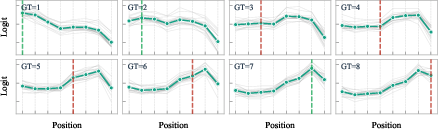
Figure 2: Logit distributions conditioned on GT position reveal tight clustering and structural regularities, but not discriminability necessary for true retrieval.
Analysis of internal attention scores confirms that attention weights peak reliably at the correct GT position, while final logits do not correspondingly reflect this information (Figure 3). The divergence indicates a decoupling between perceptual localization (attention) and autoregressive output generation (logits), with the latter corrupted by unconditional priors.
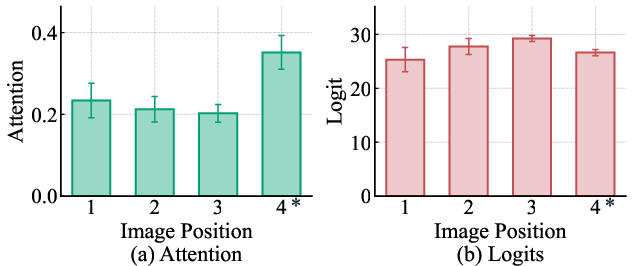
Figure 3: Despite the model attending to the correct GT (4), output logits spuriously peak at an off-target position due to position bias.
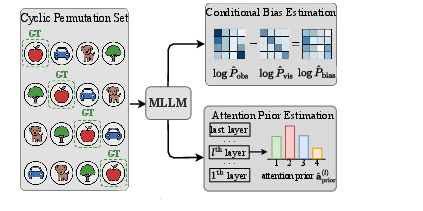
Methodology: Attention-Guided Debiasing
Building on the Logit-Attention Divergence observation, the proposed methodology introduces a training-free, attention-guided calibration framework. It leverages a minimal calibration set (as few as 5 samples) and exploits instance-level intrinsic attention signals to estimate and correct position biases at inference time.
The approach is summarized as follows:
Crucially, this pipeline requires only a single forward pass at inference and negligible computational and memory overhead compared to naive permutation-averaging baselines.
Experimental Analysis and Numerical Results
Extensive experiments on MS-COCO-based multi-image retrieval tasks, with both random and adversarial (hard negative) candidate pool construction, demonstrate the effectiveness of the proposed method:
- Permutation Invariance: The calibrated model achieves near-complete restoration of permutation invariance, as evidenced by robust confusion matrices which recover the ideal diagonal structure (Figure 1), and dramatic reductions in recall standard deviation across positions.
- Accuracy Gains: On LLaVA-OneVision-8B (N=4, random setting), accuracy increases from 67.52% (Vanilla) to 98.66% (Ours). For adversarial settings, performance rises from 49.56% to 71.06%, representing improvements exceeding 40 percentage points.
- Context Scaling: The approach exhibits graceful degradation as the candidate pool grows from N=2 to N=12, vastly outperforming logit-only baselines, which degrade rapidly with increasing context size (Figure 5).
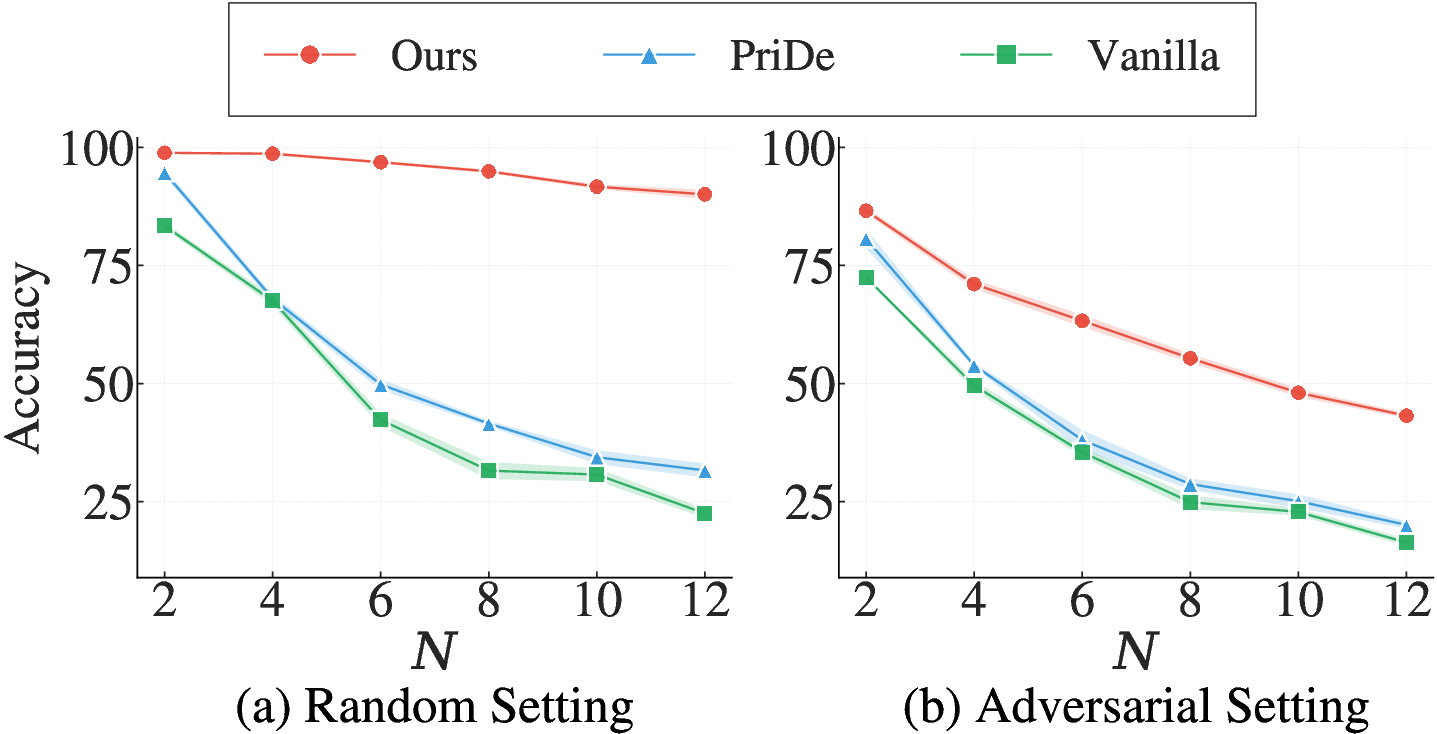
Figure 5: Accuracy as a function of candidate pool size, showing that attention-guided calibration maintains robustness as context increases.
- Sample Efficiency: With only 5 calibration samples, bias estimation and correction are nearly optimal. Performance saturates quickly with calibration set size, implying strong sample efficiency (Figure 6, left).
- Attention Sharpening: Modulation of attention posterior entropy via softmax temperature is critical; accuracy peaks with moderate sharpening and remains stable thereafter (Figure 6, right).
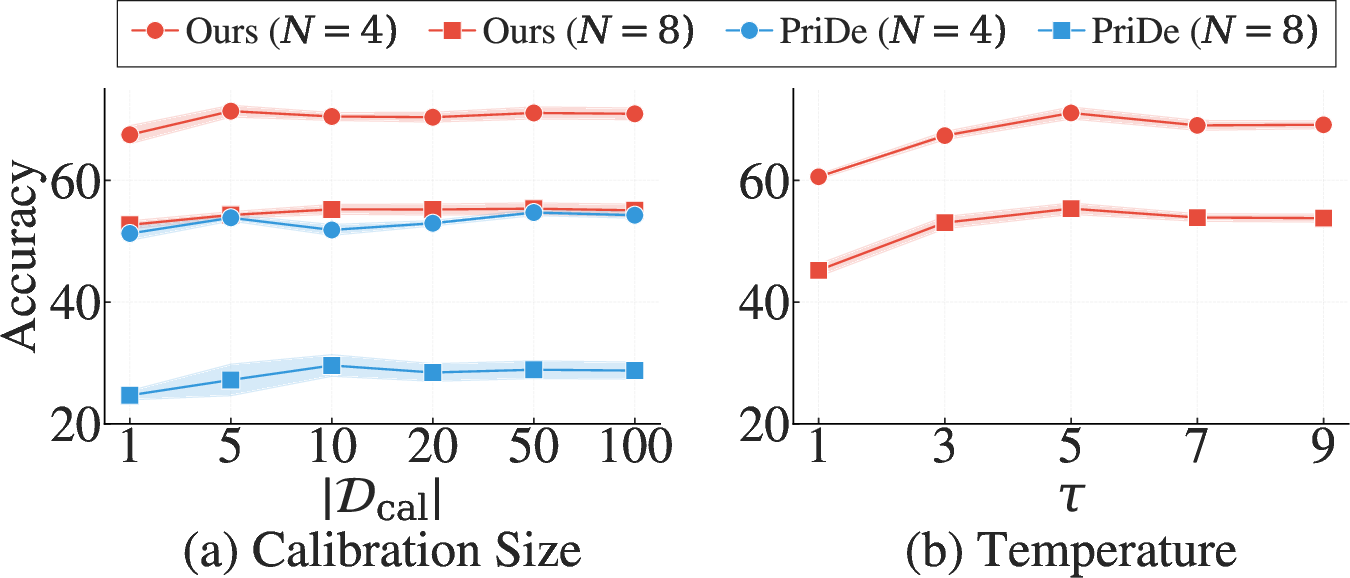
Figure 6: (a) Calibration set size and (b) temperature sharpening ablations reveal high efficiency and robustness of the method.
- Generalization: Calibration priors derived from one dataset or difficulty setting generalize well to others, demonstrating structural invariance of the captured position bias.
Theoretical and Practical Implications
The identification of Logit-Attention Divergence has substantial implications:
- Theoretical: The results suggest that structural biases—rooted in the sequence-generation design of MLLMs—can override otherwise accurate internal perceptual signals. This decoupling highlights the need to explicitly bridge attention mechanisms and output token distributions, especially in non-sequential, permutation-invariant scenarios. The phenomenon likely extends to other autoregressive architectures and cross-modal tasks.
- Practical: The attention-guided calibration method enables robust and reliable multi-image retrieval and visual QA in real-world settings where candidate ordering cannot be guaranteed, using just a handful of calibration samples and without additional training.
- Evaluation: Benchmark results that use autoregressive decoding logits for evaluation may systematically underestimate underlying model capabilities, as true visual grounding is not faithfully expressed at the logit level.
- Future Work: Extension to generative settings, integration with open-set tasks, and further exploration of the faithfulness and reliability of internal attention under high semantic ambiguity are promising avenues. The requirement for white-box access to attention maps restricts applicability to open-source or modifiable APIs, highlighting the need for architectural transparency in downstream deployment.
Conclusion
This work provides a rigorous diagnosis of position bias in MLLMs and introduces a practical, data- and computation-efficient method for its correction. By exploiting internal attention signals and counterfactual calibration, the approach restores permutation invariance and semantic faithfulness in multi-image retrieval, setting a new standard for robust cross-modal inference. The insights into logit-attention divergence open new directions for both analysis and architecture design in multimodal sequence modeling.