- The paper introduces a training-free Multi-View Reformulation (MVR) framework that uses LLM-driven strategies to combat expression drift in text-to-image retrieval.
- It employs key feature consistent and diversity-aware reformulation techniques, aggregating outputs with mean pooling and scaling factors to enhance semantic alignment.
- Experimental results across benchmarks demonstrate state-of-the-art gains in Rank-1 accuracy and mAP, validating the effectiveness of semantic compensation.
Robust Text-to-Image Person Retrieval via Multi-View Reformulation for Semantic Compensation
Introduction
Text-to-image person retrieval remains a pivotal and challenging problem in multimodal AI due to the inherent semantic variability of natural language and the ambiguity of visual semantics. This work introduces a training-free Multi-View Reformulation (MVR) framework that leverages LLM-driven strategies to compensate for expression drift and reinforce cross-modal alignment without modifying underlying model weights. By attacking the brittleness arising from semantic shift and distributional discrepancies among paraphrased descriptions, the framework systematically composes semantically robust, invariant representations and achieves state-of-the-art results across standard benchmarks.
Expression Drift and Motivation
Expression drift is identified as the phenomenon where semantically equivalent textual queries yield divergent feature embeddings due to syntactic and lexical variance, which disrupts cross-modal alignment. The paper presents empirical evidence showing the variability in feature representations caused by paraphrastic reformulation.
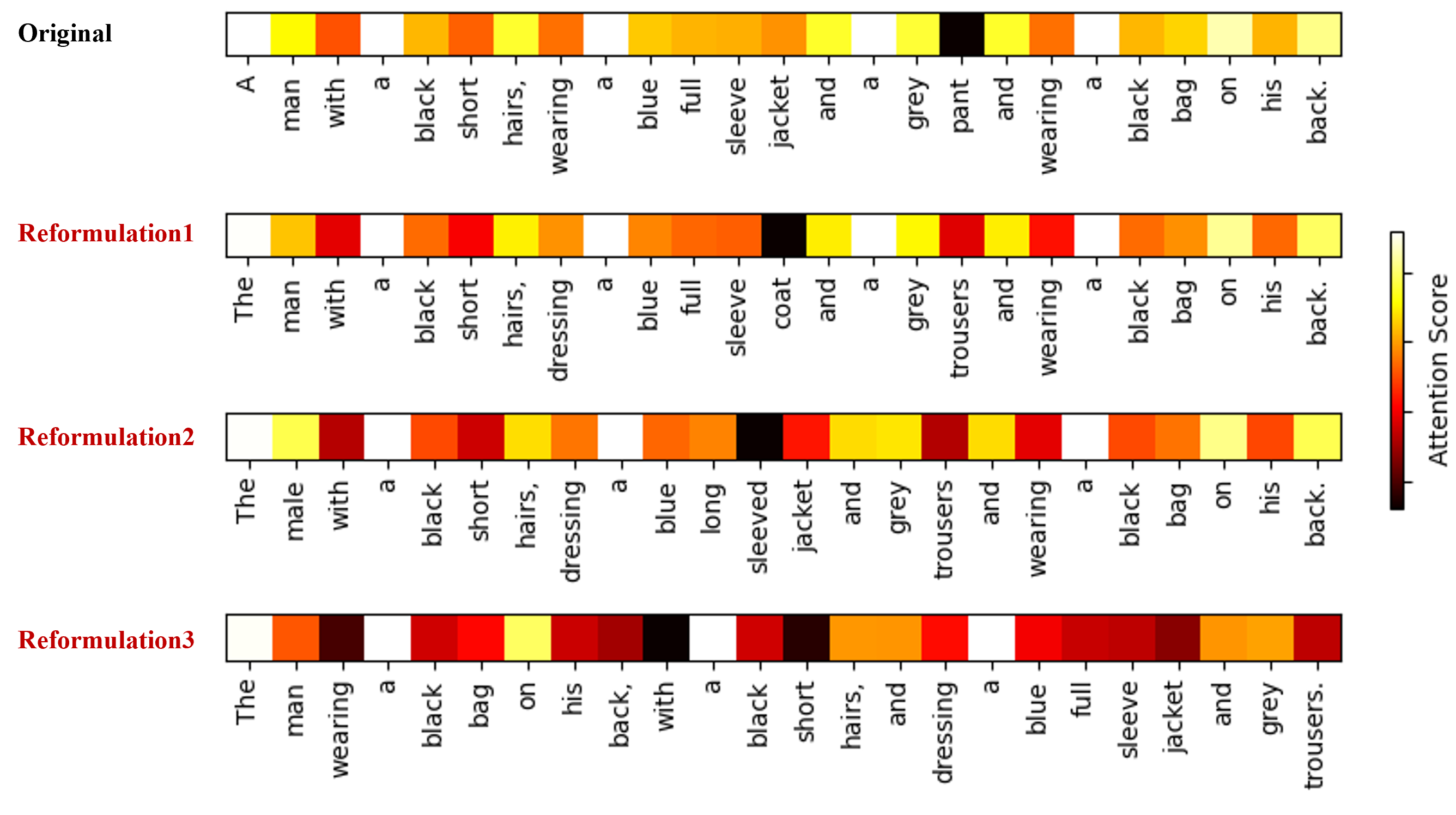
Figure 1: Cosine similarity visualization between word vectors and sentences with the same meaning but different words/orders, exposing that distributional focus varies by phrasing.
Classical approaches relying on static sentence embeddings are thus intrinsically ill-suited for scenarios with high expression diversity, and may under-attend or misalign critical attributes (e.g., color, clothing, pose) across text and image modalities. This motivates a compensation mechanism that targets semantic invariance—ensuring that all valid paraphrases of a query anchor to consistent locations within the joint embedding space.
Methodology
The framework deploys two collaborative LLM interaction strategies for generating multi-view reformulations:
- Key Feature Consistent Reformulation extracts visually salient tokens using a CLIP-based attention mechanism, preserving essential attributes (e.g., gender, clothing, color) in each paraphrase to minimize critical semantic degradation.
- Diversity-Aware Reformulation instructs the LLM to generate a spectrum of natural, plausible variants by modulating response diversity (temperature), promoting robust representation via enriched linguistic variance constrained to remain logically aligned with the original.
By aggregating feature embeddings from N reformulated queries through mean pooling and residual connections (with tunable scaling α), the approach accumulates semantic "echoes," mitigating the impact of lexical fluctuation. All text encoders and backbones are frozen, preserving full zero-shot generalizability.
Visual Semantic Compensation
Visual representations are compensated by projecting gallery images through a VLM into natural language descriptions, which are then reformulated using the same MVR process applied to text queries. This projects visual features into a more semantically enriched latent space by incorporating LLM-generated paraphrastic augmentations, with scaling factor β controlling their influence. The resulting hybrid feature is more resilient to both under-specification and high-level semantic ambiguity endemic to visual domains.
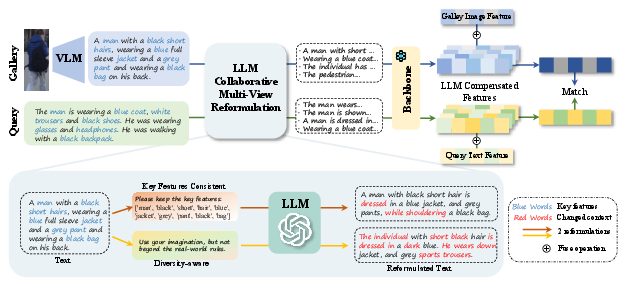
Figure 2: Overview of the MVR framework, highlighting training-free application and bi-branch (text/image) semantic compensation.
Experimental Results
Quantitative Analysis
The evaluation encompasses RSTPReid, CUHK-PEDES, and ICFG-PEDES, where the MVR approach is applied atop competitive retrieval baselines (e.g., IRRA, RDE, HAM). Across all datasets, it demonstrates consistent, significant increases in both Rank-1 accuracy and mAP, indicating enhanced cross-modal alignment and robustness:
- Example: On RSTPReid, integrating MVR yielded +2.9% R1 and +2.0% mAP gains over IRRA, and analogous improvements were demonstrated across all baselines.
- Performance gains are persistent across expression variance, noisy queries, and domain-shifted inputs, showing the effectiveness of multi-view compensation in mitigating semantic instability.
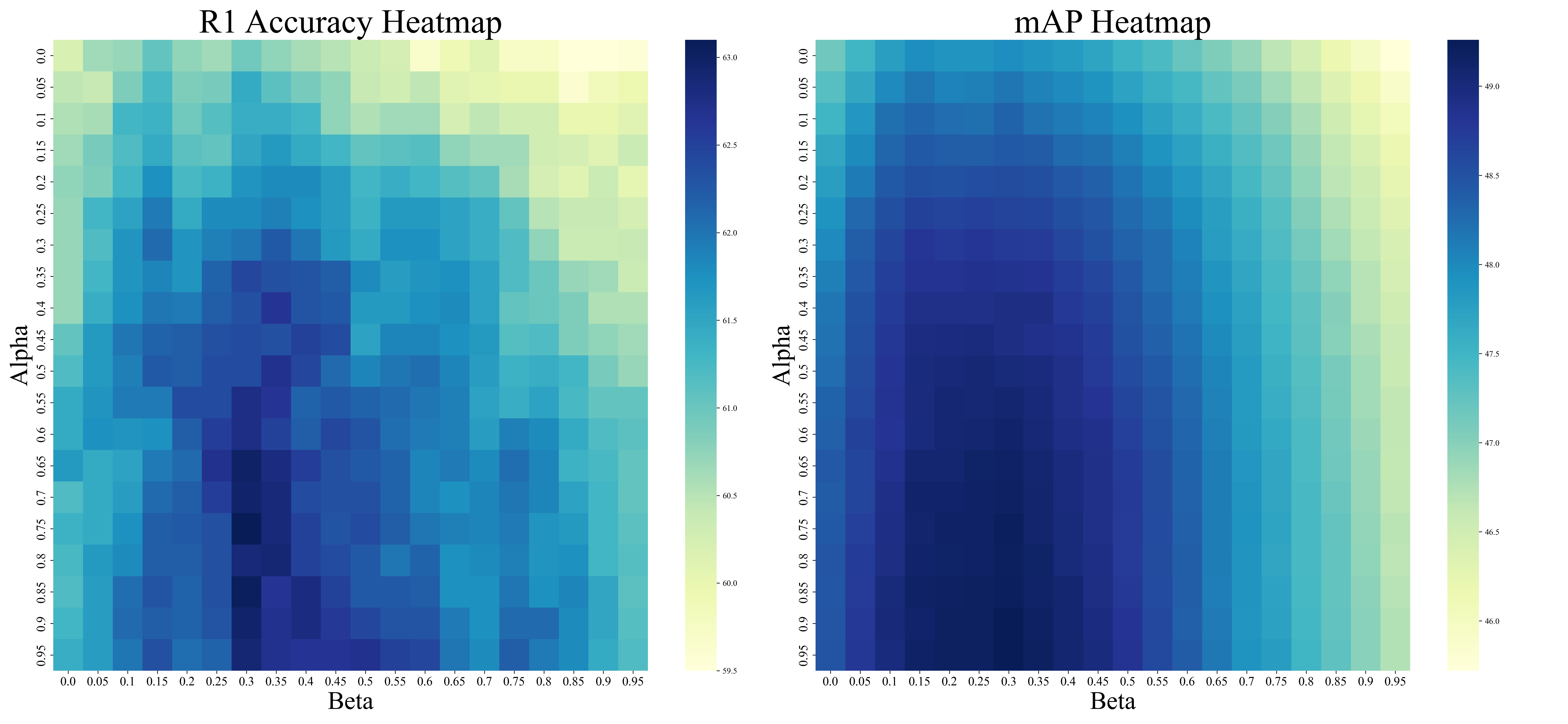
Figure 3: Heatmap visualization of Rank-1 and mAP under varied compensation parameters, illustrating optimal robustness near (α,β)=(0.75,0.3).
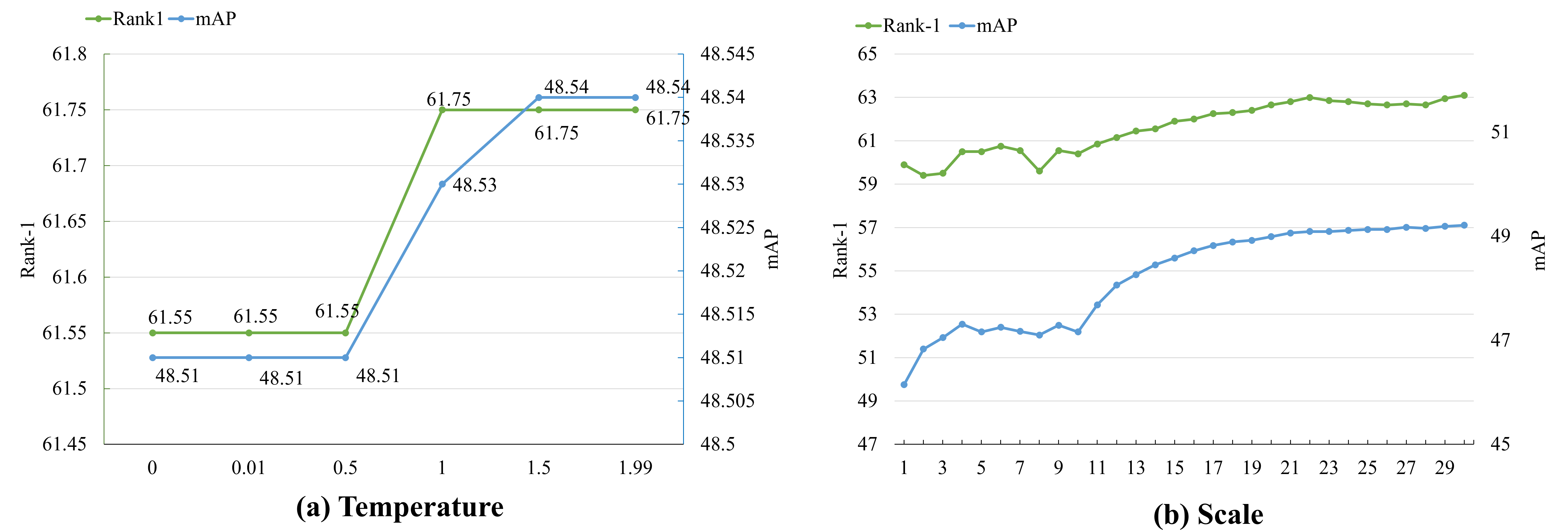
Figure 4: (a) Effect of temperature τ on reformulation diversity; (b) Impact of query compensation scale on RSTPReid performance.
Scalability and LLM Diversity
Experiments varying the number of reformulations and LLM sources (Grok, DeepSeek, GPT-4o-Mini, Qwen2.5-VL-32B, and combinations) reveal that increasing reformulation diversity consistently improves semantic coverage and alignment, with pronounced benefits when aggregating outputs from heterogeneous LLMs.
Qualitative Analysis
Visualizations substantiate that the proposed method outperforms baselines in retrieving the correct identities, particularly in challenging conditions (attributes occluded, ambiguous background), and the t-SNE plots confirm tighter alignment between textual and gallery features after compensation.

Figure 5: Top-10 retrieval results comparison between baseline and MVR; green boxes denote correct matches.
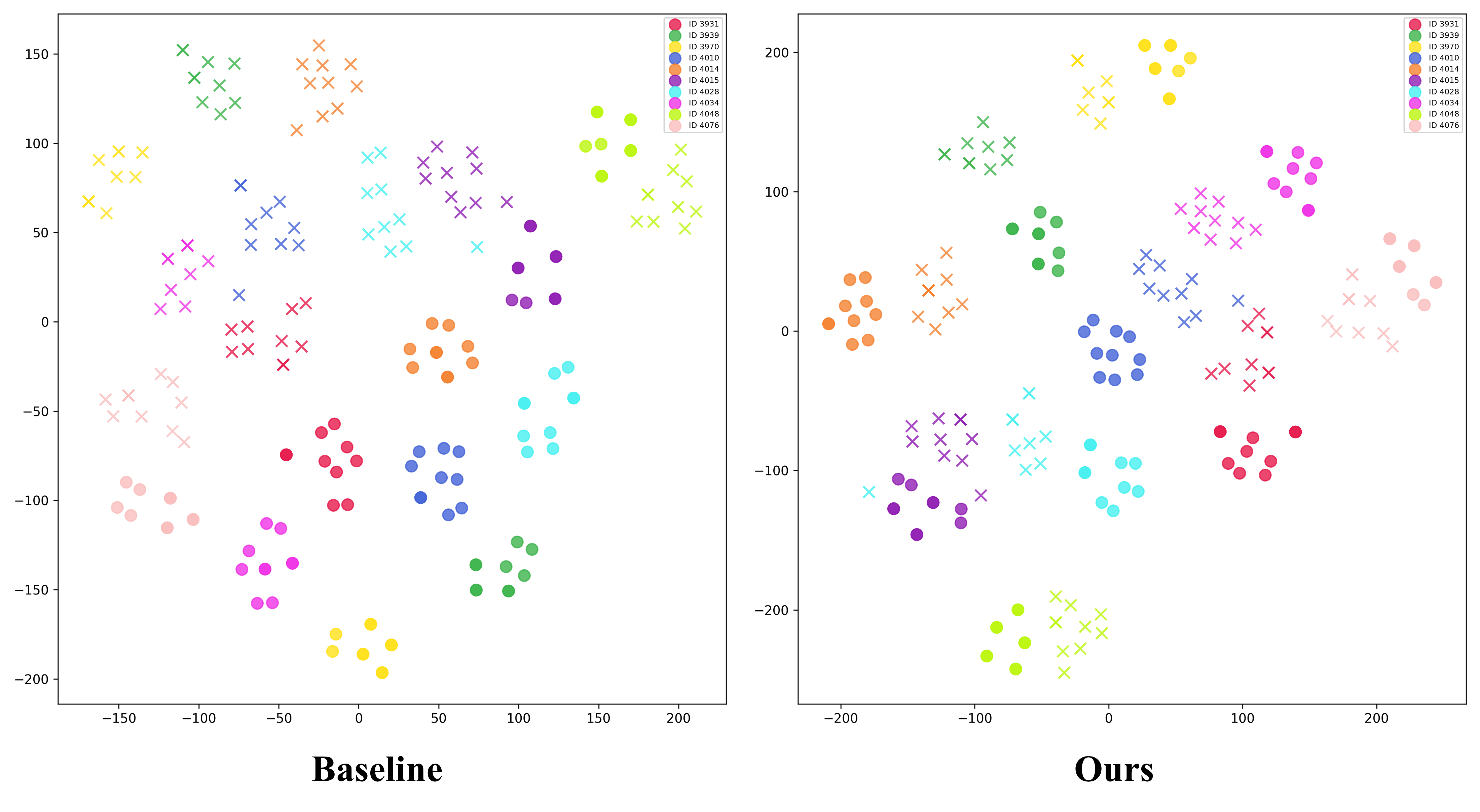
Figure 6: t-SNE plot illustrating improved clustering and alignment of query and gallery feature spaces through MVR.
Practical Considerations
Computational overhead is modest; the bulk of additional inference time is constrained to LLM-based captioning and reformulation, which can be parallelized, and does not impinge on real-time application constraints. Commercial cost for API usage remains tractable even for large-scale datasets.
Implications and Future Directions
This work demonstrates that multi-view, LLM-collaborative reformulation is a powerful, model-agnostic augmentation strategy for robust cross-modal retrieval—and is readily extendable to other multi-modal tasks requiring alignment under semantic shift (e.g., zero-shot VQA, multimodal search, fine-grained recognition). Further, integrating even richer linguistic augmenters and compositional strategies (multi-turn dialog, external knowledge) could extend robustness under more adversarial settings.
Further research could probe the theoretical limits of aggregation and investigate its interplay with contrastive learning, hard negative mining, and compositionality-aware architectures.
Conclusion
The MVR framework introduces a principled, training-free solution to the persistent problem of expression drift and visual semantic ambiguity in text-to-image person retrieval. Through systematic, LLM-driven multi-view reformulation and aggregation, the method achieves semantically invariant, robust representations, improves all key retrieval metrics, and maintains efficiency. This approach opens promising avenues for zero-shot robust alignment in more complex multi-modal tasks.