- The paper introduces CapCal, a method that mechanically removes positional bias in listwise rerankers through content-agnostic probability calibration.
- It quantifies structural priors using empty-passage probing and applies entropy-adaptive contrastive decoding for dynamic score correction.
- Experimental results show significant NDCG gains and efficiency improvements over permutation-based and retraining methods across diverse benchmarks.
Content-Agnostic Calibration for De-biasing Listwise Rerankers: An In-depth Analysis of CapCal
Introduction
Generative listwise rerankers, driven by LLMs, have demonstrated strong effectiveness by incorporating global context in passage ranking, surpassing pointwise and pairwise rerankers. Yet, such models are systematically afflicted by severe position bias, notably the violation of permutation invariance, manifesting as preference for specific positional indices independent of the relevance signal ("Lost in the Middle" effect). Traditional mitigation avenues—such as inference-time aggregation via permutation or model retraining with order-invariant objectives—are either computationally prohibitive or lack robust generalization, especially for compact models. The "Learning from Emptiness" paper (2604.10150) proposes CapCal: a training-free, plug-and-play calibration framework to mechanically remove position bias using content-agnostic probability correction, offering efficiency without the drawbacks of prior methods.
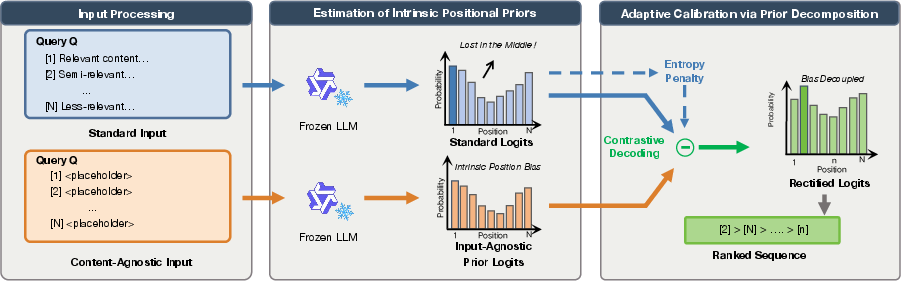
Figure 1: A schematic illustration of CapCal, where an empty-passage query is leveraged to capture the input-agnostic prior and a contrastive decoding step is used to correct standard inference logits, leading to de-biased ranking.
Background and Motivation
The core challenge in listwise reranking with LLMs arises from intrinsic architectural asymmetries—transformer layers, attention masks, and instruction layouts underpin a non-uniform prior over candidate passage positions. As established in [lost_in_the_middle], such models consistently overvalue items at list boundaries, which significantly corrupts actual retrieval performance. Prior countermeasures either:
- Rely on inference-time ensemble approaches: These aggregate model predictions across multiple permutations (e.g., Permutation Self-Consistency [psc], Mixture-of-Intervention [moi]), at the cost of 10–100x computational overhead.
- Mandate retraining with augmented data or architectural supervision: This route, typified by strategies such as RankZephyr [pradeep2023rankzephyr], ListT5 [listt5], or SCaLR [scalr], lacks flexibility and frequently fails to suppress learned priors in small/medium model settings.
- Target parametric or attention-structure normalization: Such as FitM [fitm], which acts on internal attention maps rather than surface-level output probabilities, resulting in insufficient mitigation for generation-dominated outputs.
CapCal circumvents these limitations by directly estimating the structural prior through content-free probing and analytically subtracting it from inference outputs, independent of both backbone architecture and training data lineage.
CapCal: Methodological Framework
The CapCal pipeline consists of two primary stages: (1) estimation of input-agnostic structural priors, and (2) adaptive contrastive calibration to correct standard model logits.
1. Intrinsic Prior Quantification via Empty-Passage Probing
CapCal constructs a content-free prompt—mirroring the standard reranking prompt structure but replacing passage content with vacuous entries. The model's probability mass distribution over candidate indices, as induced by this "empty" prompt, forms a direct quantification of its permutation-sensitive bias. These priors are stable and largely insensitive to placeholder content or identifier semantics, confirmed through ablation on placeholder variants and different identifier tokens (see robustness results in the appendix).
2. Entropy-Adaptive Contrastive Score Correction
CapCal calibrates document generation probabilities by analytically subtracting the empirically measured structural prior at each decoding step. The calibrated score S(di) for document di is given by:
S(di)=P(di∣x)−αk[P(di∣xempty)−∣Ck∣1]
where αk is dynamically modulated according to the entropy of the model's predictive distribution, allowing stronger correction in flat (uncertain) output regimes and gentle correction when the model expresses semantic confidence.
Identification of the probability mass for passage identifiers is implemented at the token-sequence level to account for variable identifier tokenization. Decoding is further constrained to legal permutations over passages.
Experimental Validation and Results
CapCal undergoes comprehensive evaluation on ten benchmarks covering both general-domain (MS MARCO v1/2, TREC DL19-23) and diverse BEIR zero-shot tasks (TREC-COVID, NFCorpus, Climate-FEVER, FiQA, Arguana). Three Qwen model scales are analyzed: 0.6B, 7B/8B. CapCal's comparative baselines include the frozen base reranker, Permutation Self-Consistency (PSC), and models with permutation-augmented retraining.
Strong Numerical Findings:
- Absolute NDCG@10 gains of >10 points are observed for Qwen3-0.6B on high-bias cases (MS MARCO V2, Climate-FEVER) following CapCal calibration.
- Across all scales and domains, CapCal delivers consistent enhancements (avg. +4–6 NDCG points) over the base reranker.
- Against PSC, CapCal yields comparable or superior performance on 0.6B models—while requiring only a single additional forward pass rather than O(10), a robust effectiveness-efficiency advantage.
- Training-based de-biasing (e.g., RankZephyr) fails to fully eliminate positional bias in smaller models, whereas CapCal mitigates residual effects even post retraining.
Robustness and Analysis
- Stable under input order and retrieval quality perturbations: Whether document order is shuffled, a stronger retriever (bge-reranker-v2-m3) is used, or the base retrieval set is altered, CapCal’s correction remains statistically significant.
- Invariance to placeholder content/identifier format: Substituting numerals with alphabetic indices does not erode correction efficacy, establishing the structural and content-agnostic foundation of the measured prior.
- Contrast with permutation-based SFT and data augmentation: Empirical evidence suggests entrenched bias in smaller transformers is largely immune to permutation-augmented fine-tuning, necessitating explicit methodical subtraction as provided by CapCal.
Implications and Prospects
The introduction of CapCal marks a paradigm shift from data- or model-centric debiasing to direct calibration, reframing positional bias as a structural artifact subject to explicit measurement and removal rather than an implicit learning target. Practically, this enables:
- Plug-and-play de-biasing for existing LLM-based rerankers: CapCal integrates seamlessly with any model providing logit/probability interfaces.
- Significant latency reduction compared with permutation aggregation strategies, unlocking real-time deployment for rerankers in industrial-scale retrieval and recommendation settings.
- Effective deployment of compact rerankers: Substantial gains for low-resource LLMs (e.g., 0.6B models) democratize high-quality ranking beyond the largest foundation models.
On a theoretical level, this approach suggests that model biases—especially those orthogonal to semantic intent—are often structurally quantifiable and correctable post hoc. It further anticipates future architectural trends where content-agnostic calibration could be generalized to a broader spectrum of generation-based multi-candidate decision problems, including personalized agentic systems, sequence-level recommendation, retrieval-augmented reasoning, and evidence-grounded synthesis.
Limitations
CapCal does not eliminate all costs: it introduces minimal overhead via a secondary forward pass, and requires direct access to output token probabilities/logits (precluding use with fully opaque black-box APIs). However, its efficiency dominates any classical inference-time permutation approach.
Conclusion
CapCal demonstrates that mechanical, content-agnostic probability calibration—performed entirely at inference—can substantially reduce permutation-induced position bias in generative listwise rerankers. It enables single-pass efficiency, achieves strong gains even for compact models, and surpasses prior aggregation- and data-centric approaches in both scalability and robustness. These findings establish content-agnostic calibration as a key primitive for reliable, modular LLM-based ranking across diverse retrieval and recommendation tasks, with broad implications for the scalability and fairness of generative decision systems.