- The paper introduces DaID, a training-free framework that leverages internal attention signals to mitigate hallucination in MLLMs.
- It dynamically selects a 'Spotlight' layer for enhanced visual grounding and a 'Shadow' layer to counteract linguistic inertia.
- Empirical evaluations across various benchmarks demonstrate significant accuracy improvements and reduced hallucination with minimal inference overhead.
Attention-Guided Dual-Anchor Introspective Decoding for Mitigating MLLM Hallucination
Introduction and Problem Context
Multimodal LLMs (MLLMs), which integrate visual encoders with LLMs, have achieved strong results on tasks requiring joint visual-linguistic reasoning. However, these models continue to exhibit a significant rate of hallucination—generating text inconsistent with the visual input. Addressing this cross-modal fidelity breakdown is a critical requirement for deploying MLLMs in domains such as medicine and finance, where factual grounding is essential.
Conventional hallucination mitigation approaches based on Contrastive Decoding (CD) rely on external perturbations to synthesize negative samples, typically requiring additional forward passes and introducing random noise that can shift model semantics, as demonstrated by erroneous outputs in Visual Contrastive Decoding (VCD).
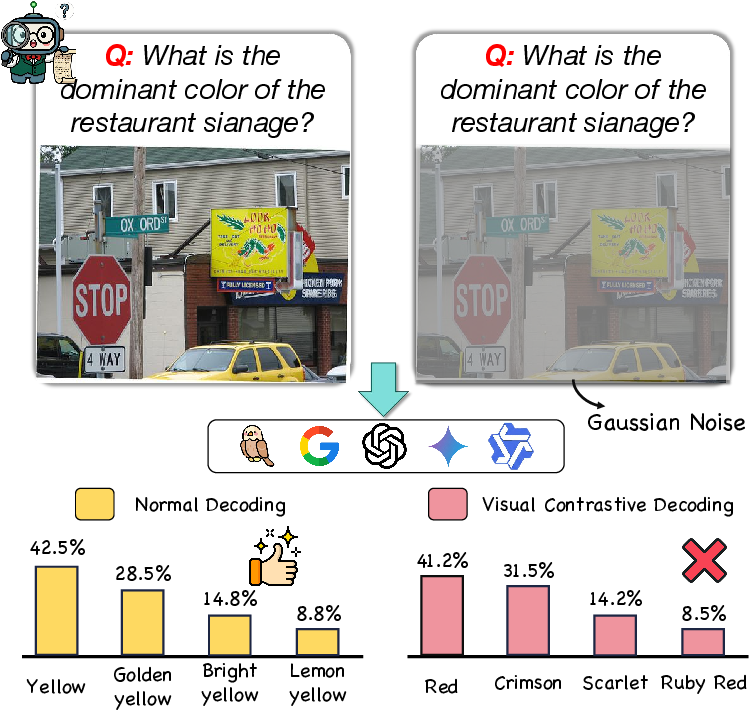
Figure 1: A failure case of Visual Contrastive Decoding (VCD) caused by external perturbations.
To address these deficits, "Spotlight and Shadow: Attention-Guided Dual-Anchor Introspective Decoding for MLLM Hallucination Mitigation" (2604.10071) proposes Dual-Anchor Introspective Decoding (DaID), an adaptive, training-free, contrastive decoding framework that leverages internal model states for contrastive calibration—eschewing external intervention. DaID dynamically identifies a “Spotlight” layer, maximizing visual signal, and a “Shadow” layer, isolating textual inertia, to adaptively modulate token generation, guided by attention distributions.
Internal Layer Dynamics and Motivation
Layer-wise analyses reveal that shallow layers in MLLMs display high hallucination rates due to the dominance of linguistic priors and lack of alignment between the visual encoder and the LLM’s latent space, leading to semantic agnosia. Intermediate layers achieve superior visual object recognition, which subsequently declines in deeper layers due to increasing linguistic inertia.
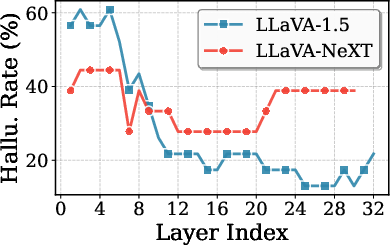
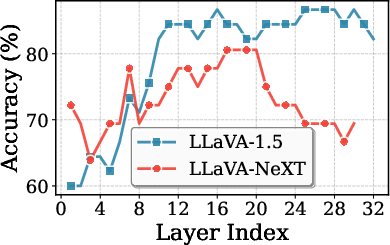
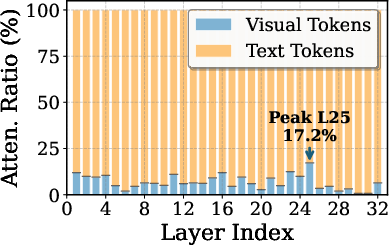
Figure 2: Hallucination Rate across MLLM layers, illustrating the high error in shallow layers and non-monotonic evolution in visual fidelity.
This suggests a seeing-then-forgetting phenomenon: intermediate layers maximize visual perception, while deeper layers focus on text fluency at the expense of visual grounding. Crucially, the visual attention allocation is maximized at intermediate layers, coincident with optimal recognition, and is minimal in shallow layers. Therefore, internal layer diversity offers a rich intrinsic signal for introspective, contrastive decoding.
DaID: Methodology
The DaID method formulates hallucination mitigation as a contrastive calibration problem over internal model representations, employing token-level dynamic anchor selection.
Attention-Guided Anchoring. DaID computes a Visual Attention Score (VAS) at each layer for every generation step, averaging attention weights over all heads to visual tokens. The “Spotlight” anchor is the layer with the highest VAS (peak visual grounding), while the “Shadow” anchor precedes the Spotlight layer and exhibits the lowest VAS (dominant language prior). This design ensures that negative reference points are visually agnostic, while positive anchors reinforce authentic perceptual signals.
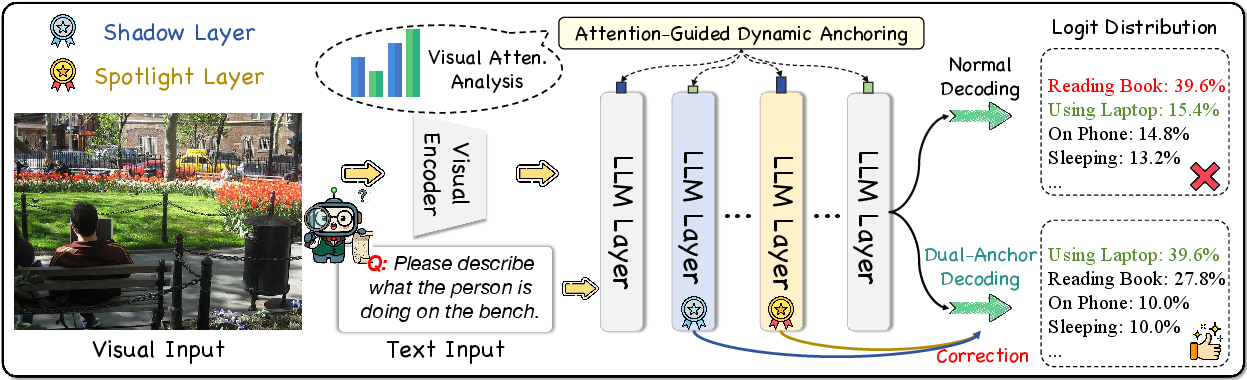
Figure 3: Framework of DaID. DaID dynamically identifies dual-anchor layers guided by the visual attention and calibrates the final output by leveraging both the Spotlight and Shadow anchors to ensure visual grounding.
Dual-Anchor Contrastive Decoding. The token distribution at each timestep is adjusted as follows: the final layer logits are modulated by an additive term emphasizing the Spotlight anchor and a subtractive term penalizing the Shadow anchor, each scaled by hyperparameters α and β, respectively. An adaptive plausibility constraint restricts adjustment to tokens within a high-confidence candidate set based on the final layer’s output, preserving syntactic coherence.
Efficiency: Unlike external perturbation-based CD, DaID performs all computations within a single forward pass, requiring only incremental computation to project anchor states to the vocabulary space.
Empirical Results
DaID is evaluated across a comprehensive suite of benchmarks—POPE, CHAIR, MME, GQA, VQA v2, MMB, SeedI, and VizWiz—using five MLLMs (LLaVA-1.5, LLaVA-NeXT, Qwen2-VL, MiniGPT-4, InstructBLIP) at the 7B scale.
Strong numerical results:
- POPE: On LLaVA-1.5, DaID achieves 85.08% accuracy and 85.92% F1 (outperforming all baselines by up to 3.72%).
- CHAIR: Achieves the lowest hallucination rates (CHAIRS: 35.9%, CHAIRI: 11.3%).
- Generalization: Performance gains persist across alternative architectures; e.g., on InstructBLIP, DaID reduces CHAIRS by 3.6% and improves POPE F1 by 1.9%.
- Reasoning preservation: DaID does not degrade, and often enhances, general vision-language task accuracy, e.g., +2.1% on SeedI at 7B scale.
Ablation studies confirm the necessity of both the Spotlight (visual) and Shadow (textual) anchors—their removal substantially worsens grounding and increases hallucination metrics.
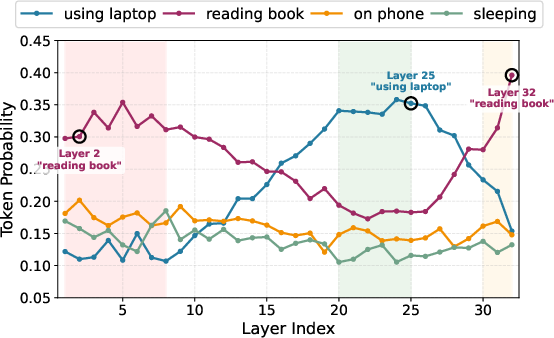
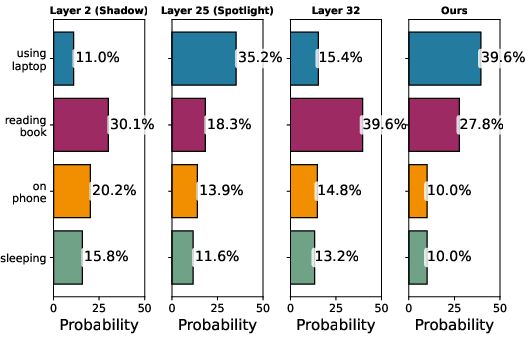
Figure 4: Token probability distribution across layers, demonstrating the suppression of correct tokens in final layers and correction via DaID.
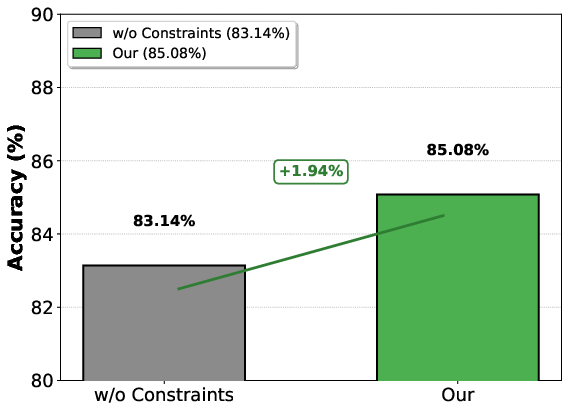
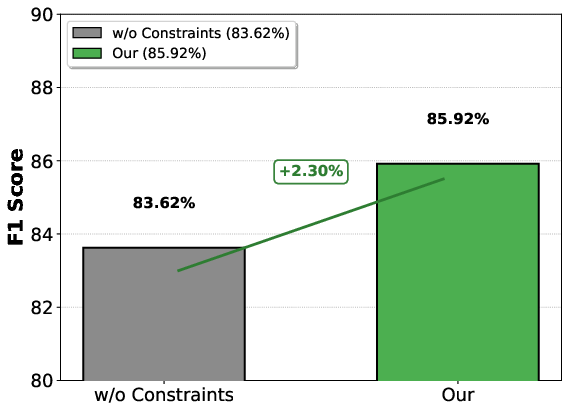
Figure 5: POPE-Acc, illustrating substantial improvement of DaID over unconstrained alternatives.
Analysis of Efficiency and Adaptivity
DaID’s efficiency is empirically validated: the overhead compared to standard decoding is modest (1.31–1.35x), and it is substantially faster than VCD (<1.4× vs >1.8× per-token latency). The necessity of the topological constraint (Lshadow<Lspotlight) for effective negative anchor selection is evidenced by a nearly +2% accuracy gain.
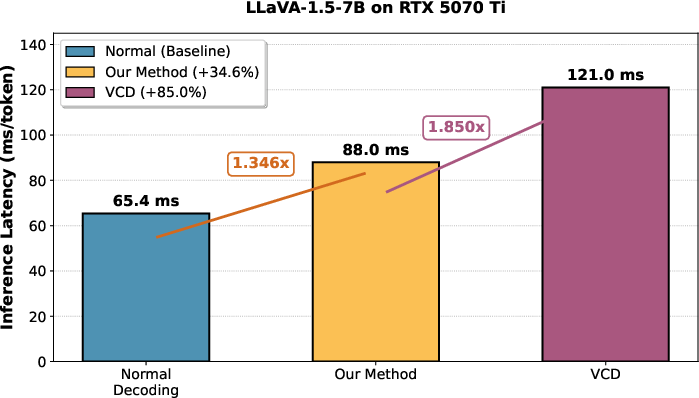
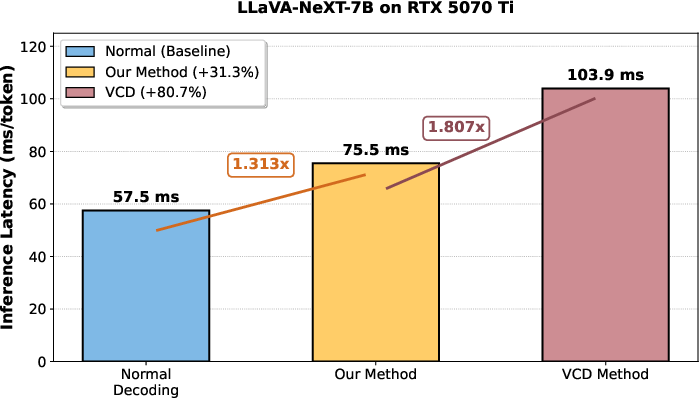
Figure 6: Inference Latency on LLaVA-1.5-7B, comparing DaID to VCD and baseline.
Dynamic, token-specific anchor selection is found to adapt fluidly to contextual demands. Even when the layer indices of Spotlight/Shadow fluctuate, their functional zones (shallow for Shadow, intermediate for Spotlight) remain stable, preserving the two-anchored contrastive principle.
Implications and Future Directions
The demonstrated efficacy, efficiency, and universality of DaID position it as a promising training-free approach for reliable MLLM deployment. Its core insight—that inherent internal representational diversity can be harnessed for contrastive calibration—suggests several implications and avenues for future exploration:
- Scalability: While DaID is validated on 7B models, its dynamic attention-guided mechanism is architecture-agnostic and is theoretically applicable to larger parameter regimes.
- Generality: The approach may be extended beyond image-text to other modalities (e.g., video, audio), though temporal attention dynamics pose new challenges.
- Internal Representation: DaID’s reliance on VAS provides a direct, interpretable, and low-overhead metric for internal state introspection, offering a blueprint for future decoding-time reliability corrections in large models.
Conclusion
DaID establishes a new paradigm for hallucination mitigation in MLLMs by introspectively leveraging layer-wise attention signals to select dual internal anchors for per-token contrastive decoding, with substantial improvements in factual consistency and reasoning fidelity while maintaining inference efficiency. The method’s adaptability, efficiency, and universality indicate its relevance for robust MLLM deployment and motivate its extension to other multimodal and large-scale regimes.
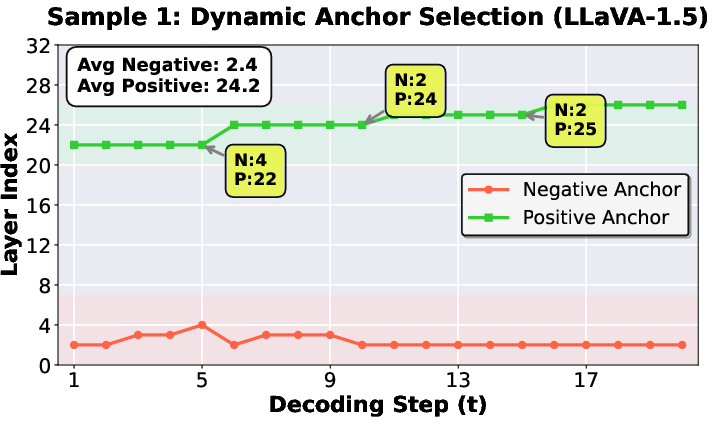
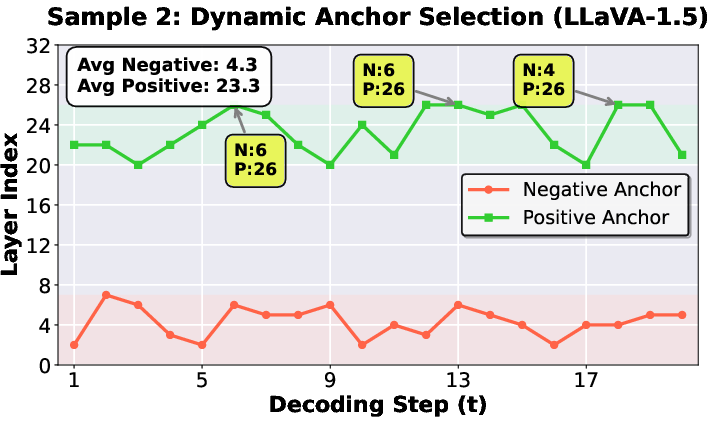
Figure 7: Sample 1 (Stable Progression)—visualization of dynamic anchor selection, illustrating the controlled adaptation inherent to DaID’s operation.