Muon is Not That Special: Random or Inverted Spectra Work Just as Well
Abstract: The recent empirical success of the Muon optimizer has renewed interest in non-Euclidean optimization, typically justified by similarities with second-order methods, and linear minimization oracle (LMO) theory. In this paper, we challenge this geometric narrative through three contributions, demonstrating that precise geometric structure is not the key factor affecting optimization performance. First, we introduce Freon, a family of optimizers based on Schatten (quasi-)norms, powered by a novel, provably optimal QDWH-based iterative approximation. Freon naturally interpolates between SGD and Muon, while smoothly extrapolating into the quasi-norm regime. Empirically, the best-performing Schatten parameters for GPT-2 lie strictly within the quasi-norm regime, and thus cannot be represented by any unitarily invariant LMO. Second, noting that Freon performs well across a wide range of exponents, we introduce Kaon, an absurd optimizer that replaces singular values with random noise. Despite lacking any coherent geometric structure, Kaon matches Muon's performance and retains classical convergence guarantees, proving that strict adherence to a precise geometry is practically irrelevant. Third, having shown that geometry is not the primary driver of performance, we demonstrate it is instead controlled by two local quantities: alignment and descent potential. Ultimately, each optimizer must tune its step size around these two quantities. While their dynamics are difficult to predict a-priori, evaluating them within a stochastic random feature model yields a precise insight: Muon succeeds not by tracking an ideal global geometry, but by guaranteeing step-size optimality.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
In one sentence
The paper shows that a popular “fancy-geometry” optimizer for training neural networks (called Muon) isn’t special because of its precise math shape; what really matters is picking steps that are the right size and gently flattening the most extreme parts of the gradient—and you can even do this with random tweaks and still get similar results.
What is this paper about?
The authors study how we update a neural network’s weights during training. Many recent methods change the gradient (the direction we move) using matrix math on its “spectrum” (think: turning the volume up or down on different directions). A common belief is that Muon works because it follows a perfect, carefully designed geometry. This paper argues that’s not the main reason it works.
What questions did the authors ask?
- Do we need a very specific geometric rule (like Muon’s) to get good performance?
- If not, what really controls how fast and how well training improves?
- Can simpler or even random rules do just as well?
- How should we think about step size (learning rate) when using these methods?
How did they study it?
They built and tested three families of optimizers, and also analyzed why they work.
Three optimizer families
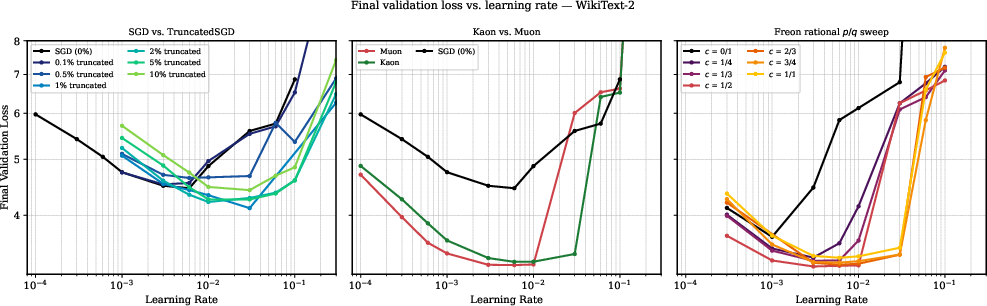
- Freon: A family with a single “knob” c that reshapes the gradient spectrum. It smoothly moves between:
- c = 0: plain SGD (no reshaping),
- c = 1/2: Muon-like behavior,
- c close to 1: very strong flattening that inverts more of the spectrum.
- The math behind Freon uses safe, efficient tricks to compute weird matrix powers reliably (think of it like a clever calculator that avoids rounding errors).
- Kaon: A deliberately “absurd” idea that replaces the gradient’s spectrum with random numbers. It keeps the directions but randomizes the strengths. Surprisingly, it still trains models well.
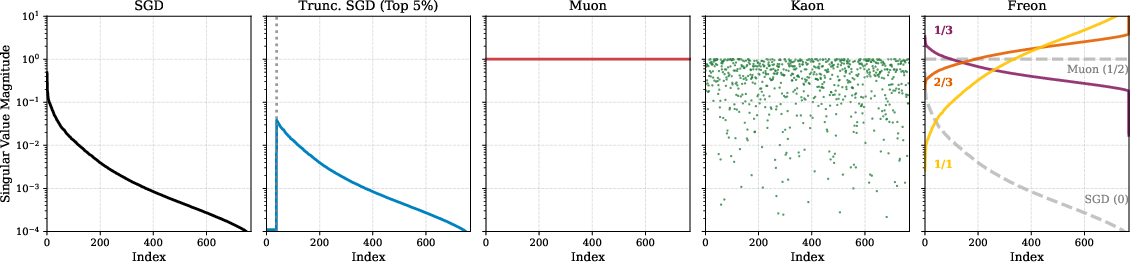
- TruncatedSGD: A simple version of SGD that just zeroes out the largest few singular values (the loudest directions), to test whether just removing extremes helps.
Measuring what really matters
They propose two simple ideas to explain progress in training:
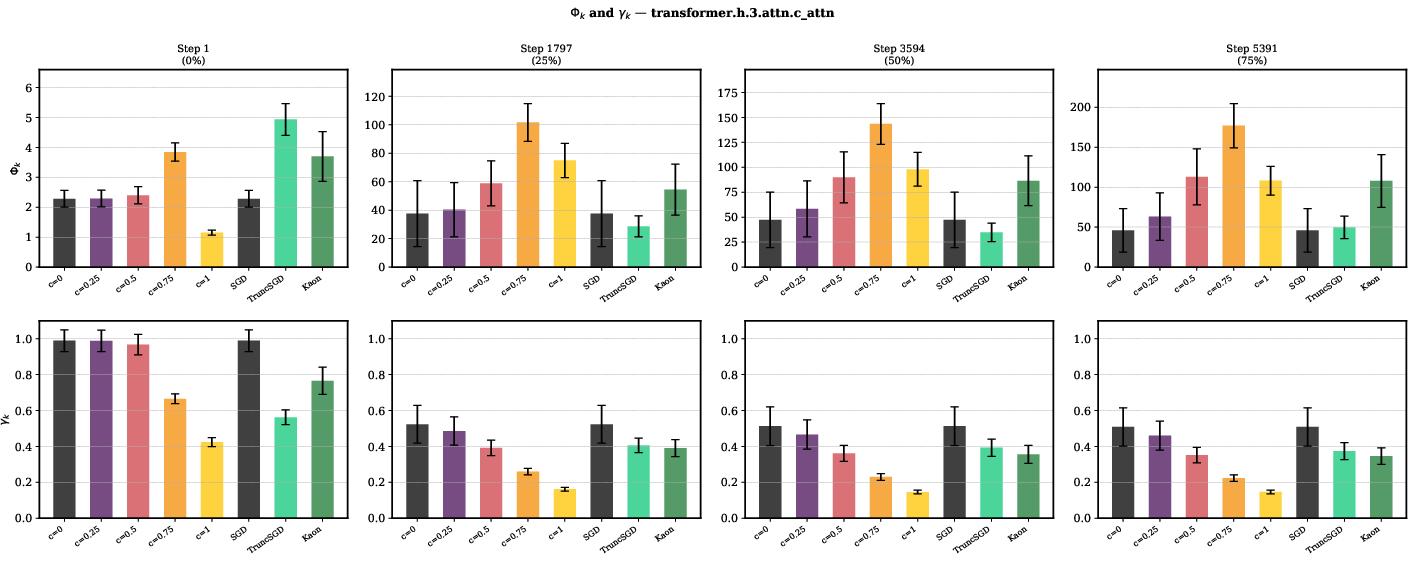
- Alignment (γ): How well your chosen update direction lines up with the true direction that lowers the loss.
- Descent potential (Φ): Given your direction, how much downhill progress you can get per step if you size the step well.
They show your actual improvement per step depends on these two things and on choosing a good step size. In words:
- Progress is larger if your direction is decently aligned and has high descent potential, and if your step size matches the local “steepness.”
Experiments and theory
- They tested on LLMs like GPT-2 (NanoGPT scale) and compared validation losses across optimizers.
- They also used a simpler math model (a random-feature model) to isolate what causes good step sizes and progress.
What did they find, and why is it important?
- Many shapes work, not just Muon’s:
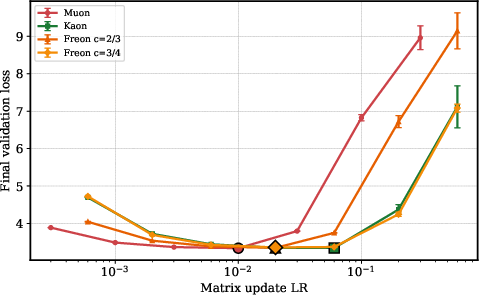
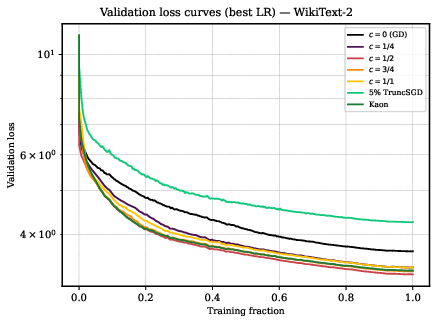
- Freon performs well across a wide range of c values, as long as you reduce very large singular values. The best c values for GPT-2 often sit in a region that classic “geometry theory” doesn’t even cover, weakening the idea that a precise geometry is key.
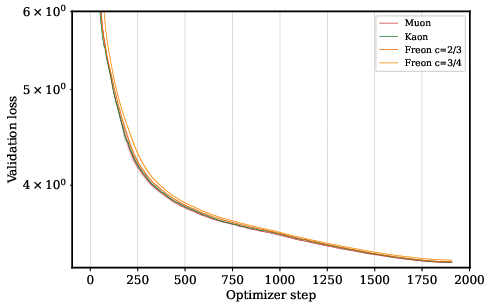
- Kaon, which randomizes the spectrum, performs about as well as Muon. This is a big surprise if you think a carefully crafted geometry is necessary.
- Suppressing extremes helps, but isn’t enough:
- Simply clipping the biggest singular values (TruncatedSGD) beats plain SGD but still doesn’t match Muon/Freon/Kaon. So, it’s not only about clipping; you also need the right overall scaling and step sizes.
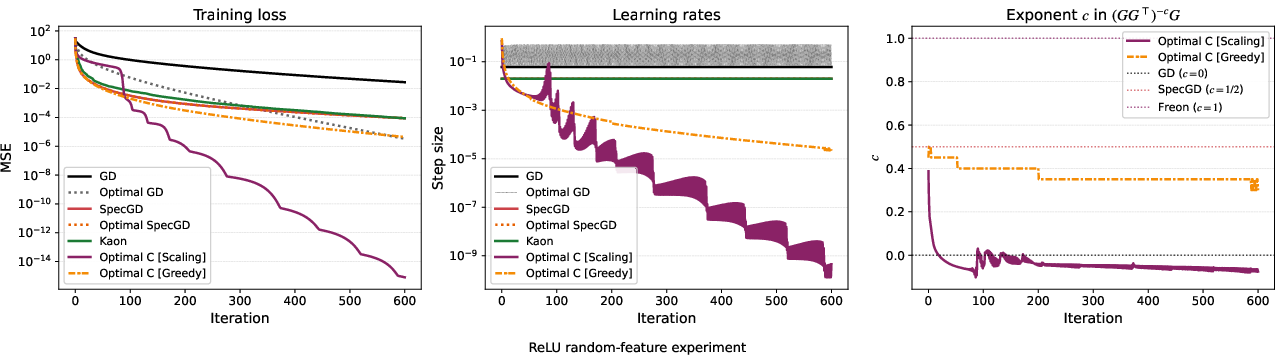
- Step-size stability is the hidden hero:
- In their simpler math model, the direction used by spectral methods (like Muon/Freon) naturally leads to a nearly constant best step size across training. That makes tuning much easier and keeps training stable.
- By contrast, plain SGD could, in theory, take bigger winning steps sometimes, but its truly best step size would jump around wildly—too hard to use in practice.
- Two quantities explain the whole story:
- Different optimizers trade some alignment (γ) for higher descent potential (Φ). You might purposely choose a direction that’s less aligned with the raw gradient if it gives you much more downhill progress—provided your step size matches that direction’s local steepness.
- The “best geometry” changes batch by batch:
- In real training on GPT-2, the locally best setting (the best c) bounces around from batch to batch. There isn’t one perfect geometric shape to lock onto globally. This again points to step-size control and broad spectrum shaping, not to strict geometry.
What does this mean going forward?
- Don’t over-worship geometry: You don’t need to perfectly match a fancy mathematical shape to get great training performance. Random or inverted spectra can work just as well as precise designs.
- Focus on practical levers:
- Keep extreme gradient directions in check.
- Choose update rules that make the best step size stable and easy to set.
- Think in terms of alignment (γ), descent potential (Φ), and step size, rather than an idealized global geometry.
- Simpler and more robust optimizers are possible:
- Since even randomized spectrum shaping can work, there’s room to design optimizers that are easier to implement, scale well, and are less sensitive to tricky hyperparameters.
Key takeaways
- Muon’s success is less about perfect geometry and more about stable, near-optimal step sizes and reducing extreme gradient directions.
- A wide range of spectrum-shaping methods, including random ones, can perform similarly well.
- The most useful mental model is: progress = alignment × descent potential × good step size.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved by the paper; each item is phrased to enable actionable follow-up work.
- Adaptive control of the Schatten exponent: How to select
conline (per layer and over time) in a stable, low-variance way given that the empirically optimalcfluctuates across batches and often lies in the quasi-norm regime (c\>1/2)? Develop robust estimators or controllers forcthat improve loss and stability without exhaustive grid searches. - Practical estimation of the two key quantities: How can
γ_k(batch gradient alignment) andΦ_k(directional descent potential) be estimated cheaply and reliably during training to drive step-size andcadaptation, given that exact Hessian-dependent terms (e.g.,λ_k) are not directly observable? - Step-size adaptation grounded in
γ_k/Φ_k: The paper argues Muon’s success stems from step-size optimality; design and evaluate step-size controllers that directly targetα_k ≈ γ_k/λ_k(or proxies) in large-scale, nonconvex settings without line search. - Beyond RF models: The random-feature (RF) analysis provides qualitative insight but fails to capture GPT-2 layer behavior (e.g., preference for
c≈1); develop richer surrogate models that better reflect transformer curvature/noise to predictγ_k,Φ_k, and optimalcin practice. - Theory for the quasi-norm regime: Provide rigorous convergence/stability guarantees and descent-rate characterizations for preconditioned spectral descent with
c ≥ 1/2(non-norm/quasi-norm regime), and delineate conditions under whichc\>1/2is provably beneficial. - Nonconvex and stochastic settings: Extend the convergence analyses (including the Kaon result) to nonconvex objectives with stochastic gradients, momentum, and weight decay, and characterize conditions ensuring monotonic decrease or bounded oscillations.
- Robust proxies for curvature: Develop tractable, online surrogates for
λ_k = ⟨D_k, ∇²f(Z_k)[D_k]⟩(e.g., directional Gauss–Newton or low-rank Hessian sketches) that can be used for step-size tuning in deep networks without prohibitive cost. - Distributional choices in Kaon: Is Kaon’s performance sensitive to the chosen random singular-value distribution (e.g., uniform vs. heavy-tailed vs. Beta/Dirichlet)? Systematically map the impact of different noise distributions on
γ_k,Φ_k, generalization, and stability. - Structure-aware randomization: Explore “structured Kaon” variants that randomize spectra while preserving ordering, partial groupings, or low-rank structure to test minimal constraints needed for Muon-level performance.
- Generalization and implicit bias: Quantify how spectral reshaping (deterministic vs. randomized) affects margin, flatness/sharpness, calibration, and in-context learning properties; determine whether geometry-agnostic methods induce different implicit biases than Muon.
- Breadth of empirical validation: Validate Freon/Kaon across architectures (e.g., larger LLMs, CNNs, diffusion models), tasks (vision, code, RL, speech), scales, batch sizes, and data regimes (pretraining vs. finetuning) to test the claimed geometry irrelevance.
- Interaction with optimization staples: Assess compatibility and interactions with momentum (e.g., heavy-ball, Adam-type), decoupled weight decay, learning-rate schedules/warmup, gradient clipping, and mixed precision; identify best-practice combinations.
- Wall-clock and energy cost: Quantify throughput, latency, memory traffic, and energy for Freon’s QDWH-based iterations (block-QR, rational maps) vs. Muon/AdamW/Shampoo on GPUs/TPUs; provide kernels and profiling to guide deployment decisions.
- Mixed-precision robustness: Determine the numerical stability and accuracy of the QDWH rational approximations and Kaon’s chaotic recurrences under bfloat16/FP8; assess error accumulation and failure modes.
- Handling rank-deficient and ill-conditioned gradients: Many layer gradients are low rank (batch-size-limited); characterize how Freon’s
(GGᵀ)^{-c}behaves with pseudoinverses, near-zero singular values, and how to set/estimate the lower boundℓrequired by the rational approximation. - Scaling and symmetry results in modern stacks: Extend the Freon
c=1equivariance claim beyond scaling/orthogonal symmetries to transformers with LayerNorm/RMSNorm, residuals, attention scaling, and parameter sharing; verify invariance in practice. - TruncatedSGD practicality: Design efficient, SVD-free methods to clip only the top singular values (e.g., randomized subspace iterations, Nyström sketches) and compare to Freon/Muon in stability, cost, and accuracy.
- Diagnosing and mitigating failure modes: Identify scenarios where suppressing large singular values is harmful (e.g., intrinsically low-rank tasks or small-batch finetuning) and develop detection criteria and fallback strategies.
- Order vs. magnitude: Prior work suggests preserving singular-value ordering may suffice; explicitly test “order-preserving but magnitude-random” updates, isolating the value of order vs. precise spectra.
- Batch-to-dataset geometry mismatch: The optimal
cvaries across batches; can multi-batch or EMA-based estimators stabilizec/step-size decisions so they reflect dataset-level rather than batch-level geometry? - Alternative norm scalings: The proposed “mean Schatten” scaling aims to decouple step size from rank; systematically compare alternative scalings (e.g., trace- or determinant-based, layer-size adaptive) for stability and dimension-independence.
- Edge-of-stability dynamics: Analyze whether and how Freon/Kaon shift the edge-of-stability boundary relative to SGD/AdamW, and whether spectral reshaping can safely operate at larger effective step sizes without divergence.
- Distributed and reproducibility issues: Kaon’s chaotic generator raises determinism questions under data/model parallelism; specify seeding, synchronization, and numerical-consistency protocols to ensure reproducible training.
- Curvature sign and saddle regions: The local descent formula uses a quadratic term that can be negative near saddles; characterize how spectral updates interact with negative curvature and whether they escape saddles more/less effectively than baselines.
- Layerwise coupling: Current analysis is largely per-layer; study interactions across layers (e.g., conflicting
c/step-size choices) and develop coordinators that allocate per-layer budgets based on global progress signals. - Heavy-tailed noise regimes: Given claims around heavy tails, measure how Freon/Kaon behave under varying gradient-noise tail indices and covariance structures, and whether specific
cor randomization strategies are preferable. - Implementation details for practitioners: Provide open-source, GPU-friendly implementations (e.g., fused kernels for rational iterations), memory/computation guidelines, and calibration recipes to reduce the barrier to adoption.
- Benchmarks with equal tuning budgets: Re-evaluate gains against rigorously tuned baselines (AdamW/Shampoo/Adafactor) with matched hyperparameter searches, to quantify improvements attributable to spectra vs. tuning advantages.
- Safety and failure detection: Develop simple online diagnostics (e.g., monitoring
γ_k,Φ_k, and effective step size) to flag instability, misalignment, or wasted descent potential, and trigger corrective actions (e.g.,c/LR adjustments).
Practical Applications
Overview
This paper introduces two optimizer families—Freon (a continuum of Schatten quasi‑norm–inspired updates computed via an optimal QDWH-based rational iteration) and Kaon (a deliberately “absurd” optimizer that randomizes singular values)—and shows they can match Muon’s performance without adhering to a precise geometric target. It further identifies two local, mechanistic quantities—batch gradient alignment (γ) and directional descent potential (Φ)—as the true drivers of performance, with step-size tuning being critical. Below are practical applications and workflows that stem from these findings.
Immediate Applications
- Drop‑in spectral optimizers for deep learning training
- What: Deploy Freon (e.g., c≈0.6–0.8) or Kaon as alternatives to Muon/AdamW in training LLMs, vision models, and multimodal models; use Freon as a spectrum‑shaping preconditioner that interpolates between SGD and Muon; use Kaon to avoid expensive geometric computations while retaining performance.
- Sectors: Software/AI, Cloud ML, Enterprise ML, Education (research labs).
- Tools/workflows/products: PyTorch/TF/JAX optimizer plugins; training scripts for fine‑tuning and pretraining; Hugging Face/Lightning integrations.
- Assumptions/dependencies: Efficient GPU kernels for the QDWH rational iteration (block‑QR, batched QR) or fast Kaon implementation; bfloat16/FP8 numerical stability; observed gains validated primarily on GPT‑2/NanoGPT/WikiText—further task benchmarking recommended; careful learning‑rate tuning.
- Training‑stability gains at challenging batch sizes
- What: Use Freon/Kaon to suppress unstable leading singular directions, improving stability for very small or very large batches where AdamW/SGD can be brittle.
- Sectors: Healthcare (small datasets), Robotics (on‑device/edge training), Education (low‑resource labs).
- Tools/workflows/products: “Spectral suppression” optimizer settings in MLOps pipelines; batch‑size–aware optimizer presets.
- Assumptions/dependencies: Benefits depend on data/model regime; top‑singular‑value suppression helps but is not sufficient alone—tune step sizes accordingly.
- Learning‑rate policies centered on step‑size optimality
- What: Shift LR tuning focus from “exact geometry” to achieving near‑optimal α via proxies for γ and local curvature; adopt conservative, stable LR schedules that leverage spectral methods’ more stable effective step sizes.
- Sectors: Software/AI, MLOps.
- Tools/workflows/products: LR schedulers that target α*≈γ/λ using proxies (e.g., backtracking line‑search, secant estimates from recent loss decreases, GGN‑based approximations); automated LR sweeps aligned with Φ amplification.
- Assumptions/dependencies: λ (directional curvature) cannot be computed exactly during training—requires proxies; global convergence still depends on standard smoothness conditions.
- Training dashboards that log γ and Φ as optimization health signals
- What: Monitor γ (alignment) and Φ (descent potential) per layer or per block to diagnose when to trade alignment for descent potential (higher c) or vice versa.
- Sectors: MLOps, Education/Academia.
- Tools/workflows/products: Logging hooks; dashboards that expose γ, Φ, effective step sizes, and per‑directional loss decrease proxies; alarms for mis‑tuned LR or c.
- Assumptions/dependencies: Approximate γ and Φ with stochastic gradient statistics and GGN/Hutchinson traces; overhead must be controlled.
- Low‑overhead fine‑tuning on consumer GPUs
- What: Use Kaon (random spectral reshaping) to approximate Muon‑level performance without full spectrum whitening; beneficial for LoRA/adapter fine‑tuning with tight memory/compute budgets.
- Sectors: Open‑source community, Startups, Education.
- Tools/workflows/products: Lightweight Kaon optimizer wheels or Triton kernels; recipes for consumer GPUs (e.g., 3090/4090, A10).
- Assumptions/dependencies: Validate variance and stability on target tasks; ensure reproducibility with seeded pseudo‑random maps.
- Robustness and regularization via random spectral reshaping
- What: Treat Kaon’s randomized singular values as a regularization/robustness tool to reduce over‑reliance on batch‑specific curvature geometry.
- Sectors: Security/Robust ML, General ML.
- Tools/workflows/products: “Spectral randomization” toggles in training configs; ablation suites to quantify generalization shifts.
- Assumptions/dependencies: Must be balanced against potential training noise; evaluate on OOD benchmarks.
- HPC linear‑algebra kernels for fractional matrix actions
- What: Adopt QDWH‑based rational approximations to compute (GGT)−c G robustly (doubly‑exponential convergence) in ML frameworks; also immediately useful for polar decompositions/SVD pipelines.
- Sectors: HPC, Software/AI Infrastructure.
- Tools/workflows/products: cuBLAS/cuSOLVER‑adjacent kernels; batched QR/Cholesky; vendor libraries or Triton extensions.
- Assumptions/dependencies: High‑quality block‑QR implementations; memory bandwidth; careful handling in mixed precision.
- Curriculum and benchmarking updates in academia
- What: Update teaching materials and baselines to include Freon/Kaon and γ–Φ analysis; add “non‑geometry–centric” optimizers to optimizer benchmarks.
- Sectors: Education/Academia.
- Tools/workflows/products: Course labs; reproducible benchmark suites (LLM pretraining/fine‑tuning); open‑source repos.
- Assumptions/dependencies: Community adoption; standardized evaluation harnesses.
Long‑Term Applications
- Auto‑optimizer controllers that co‑tune c and LR using γ–Φ feedback
- What: Closed‑loop controllers that adjust Freon’s exponent c and LR online to maximize Φ while maintaining acceptable γ; schedule c toward mid‑spectrum emphasis (e.g., 0.6–0.8) when gradients become misaligned.
- Sectors: Cloud ML, AutoML platforms.
- Tools/workflows/products: RL/black‑box controllers; Bayesian optimization over c and LR with γ–Φ features; “Alignment–Potential” control planes in MLOps.
- Assumptions/dependencies: Reliable online proxies for γ, Φ; overhead constraints; guardrails against instability.
- Hardware co‑design for spectral updates and QDWH
- What: Accelerator support (ISA or tensor‑core primitives) for QR/block‑QR, rational minimax steps, and matrix sign/polar functions; fused kernels for (GGT)−c G.
- Sectors: Semiconductors, Cloud Providers.
- Tools/workflows/products: Next‑gen GPUs/NPUs with fast QR and rational‑function pipelines; library support for batched fractional matrix actions.
- Assumptions/dependencies: Sufficient demand from ML workloads; compiler/runtime integration; numerical stability in low precision.
- Energy/cost‑aware training policies centered on step‑size stability
- What: Organizational policies and targets emphasizing optimizers with stable step sizes (e.g., Muon/Freon/Kaon variants) to reduce LR‑tuning cost and wall‑clock time.
- Sectors: Policy (corporate governance), Sustainability teams in AI orgs.
- Tools/workflows/products: Reporting frameworks that track energy‑per‑loss‑decrease and effective step sizes; procurement guidelines for ML services.
- Assumptions/dependencies: Clear measurement protocols; reproducible baselines across tasks.
- Privacy‑ and compliance‑oriented spectral randomization
- What: Explore whether random spectral reshaping (Kaon‑style) reduces leakage of curvature information or provides obfuscation complementary to DP‑SGD.
- Sectors: Healthcare, Finance, Regulated Industries.
- Tools/workflows/products: Compliance‑grade training modes with spectral randomization; audits of privacy‑utility trade‑offs.
- Assumptions/dependencies: Requires rigorous empirical/analytical evidence; potential utility/privacy trade‑offs.
- General scientific/engineering solvers using fractional preconditioning
- What: Use Freon’s rational approximation toolkit to apply fractional power preconditioners in PDE solvers, inverse problems, and convex optimization (e.g., fractional Laplacians, pseudo‑inverse–like updates).
- Sectors: Energy (grid/PDEs), Engineering/Simulation, Scientific Computing.
- Tools/workflows/products: Preconditioning modules in PETSc/Trilinos; rational minimax toolboxes.
- Assumptions/dependencies: Problem‑specific spectra; integration overhead; numerical stability in heterogeneous systems.
- Dynamic batching and throughput optimization via spectral control
- What: Exploit spectral suppression to maintain stability under changing batch sizes in production (dynamic batching), enabling better hardware utilization.
- Sectors: Cloud Inference/Training Services.
- Tools/workflows/products: Batch‑size–adaptive optimizers that adjust c; cluster schedulers that co‑optimize batch size and optimizer settings.
- Assumptions/dependencies: Real‑time measurement infrastructure; QoS constraints.
- Robust generalization under distribution shift
- What: Use mid‑spectrum–focused updates (c>1/2) or spectral randomization to avoid overfitting to spurious sharp directions; evaluate on OOD benchmarks.
- Sectors: Finance (time‑series models), Healthcare (shifted populations), Robotics (non‑stationary environments).
- Tools/workflows/products: “Shift‑robust” optimizer presets; evaluation harnesses for OOD.
- Assumptions/dependencies: Task‑specific validation; trade‑offs with convergence speed.
- New theory and benchmarks beyond LMO geometry
- What: Research programs and community benchmarks that evaluate optimizers through γ–Φ dynamics and step‑size stability rather than strict adherence to geometric LMOs.
- Sectors: Academia, Standards bodies/consortia.
- Tools/workflows/products: γ–Φ‑based benchmark suites; theory toolkits for stochastic alignment/potential analysis.
- Assumptions/dependencies: Community consensus; standardized metrics.
Key Cross‑Cutting Assumptions and Dependencies
- Numerical and systems support: Efficient, stable implementations of rational iterations (QDWH), block‑QR, and batched fractional matrix actions in mixed precision; distributed training compatibility and memory bandwidth considerations.
- Tuning and monitoring: Practical proxies for γ and λ (e.g., GGN approximations, secant/backtracking line search) are needed to exploit step‑size optimality; monitoring overhead must remain low.
- Generalization: While results are promising on GPT‑2/NanoGPT and WikiText‑2, broader validation (larger models, domains, modalities) is required before organization‑wide defaults.
- Reproducibility and variance: Kaon’s randomized spectra necessitate seeded deterministic PRNGs and variance controls; stability must be verified per workload.
- Integration costs: Migration to spectral optimizers requires MLOps changes (kernels, monitoring, schedules) and may entail nontrivial engineering effort.
Glossary
- Batch gradient alignment: The ratio between how well the chosen direction aligns with the true gradient versus the sampled/batch gradient. "batch gradient alignment ()"
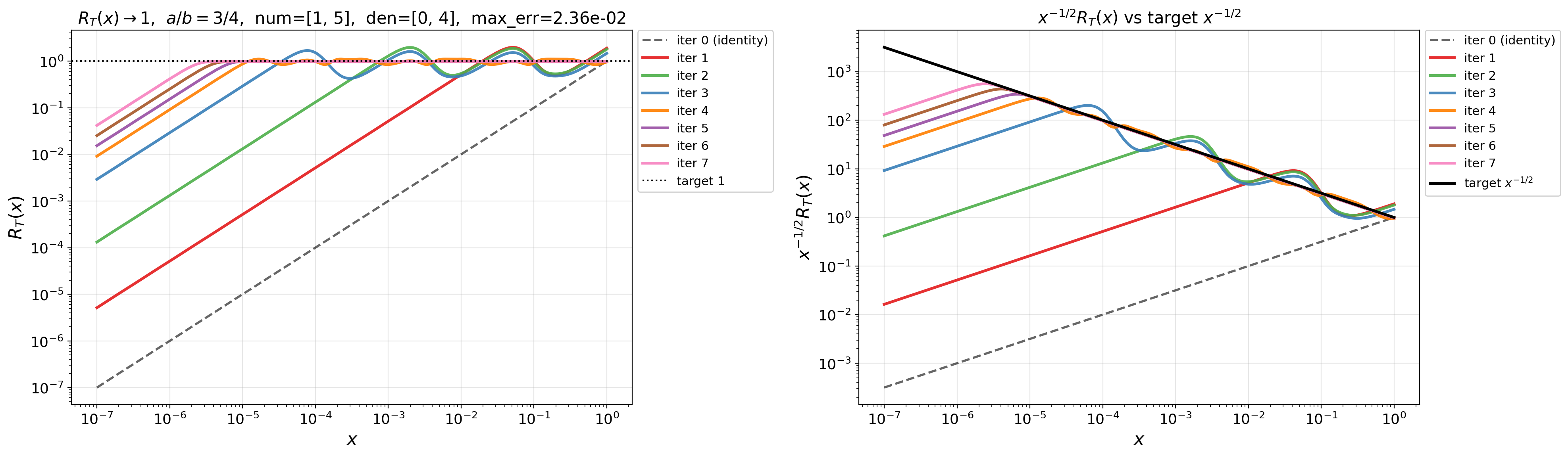
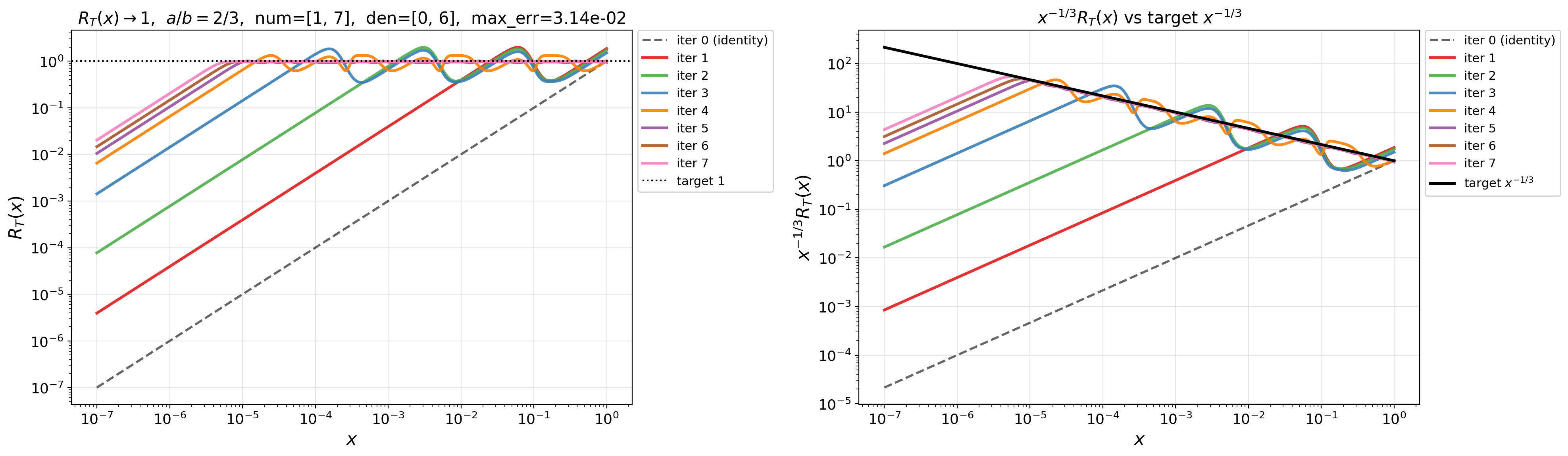
- block-QR: A numerical linear-algebra technique using QR factorizations on blocks to implement matrix mappings efficiently and stably. "utilizing block-QR for the rational map."
- Chaotic regime: A parameter range of a nonlinear recurrence where trajectories exhibit sensitive dependence on initial conditions and appear random. "Setting pushes the recurrence deep into the chaotic regime."
- Directional descent potential: A local scalar that measures how much decrease in loss an update direction can yield for a given step size. "directional descent potential ()."
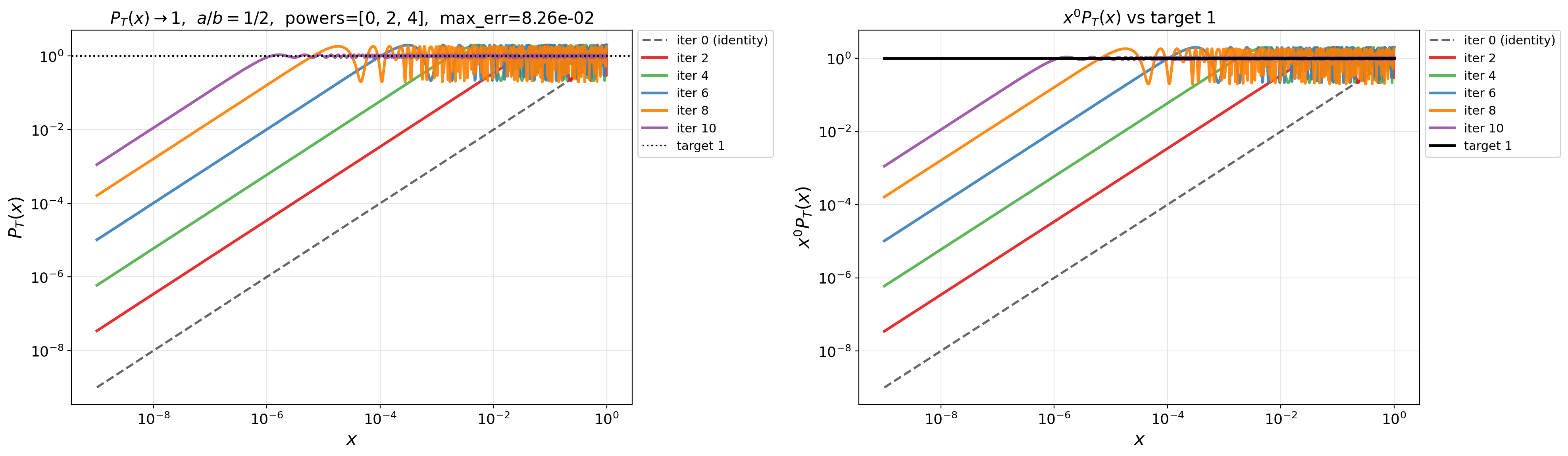
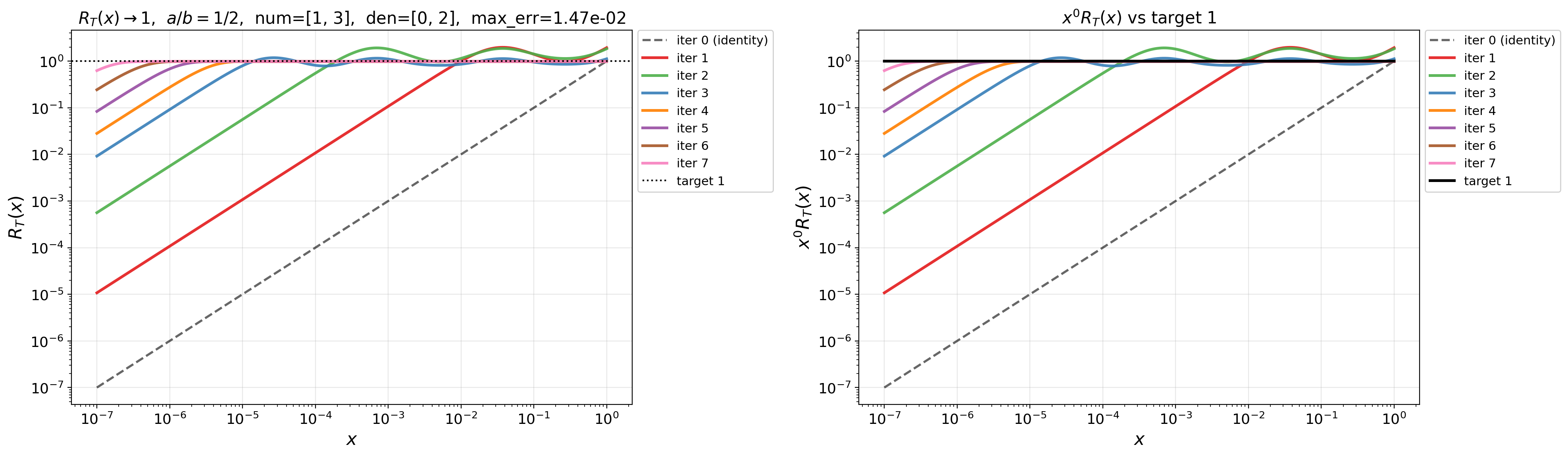
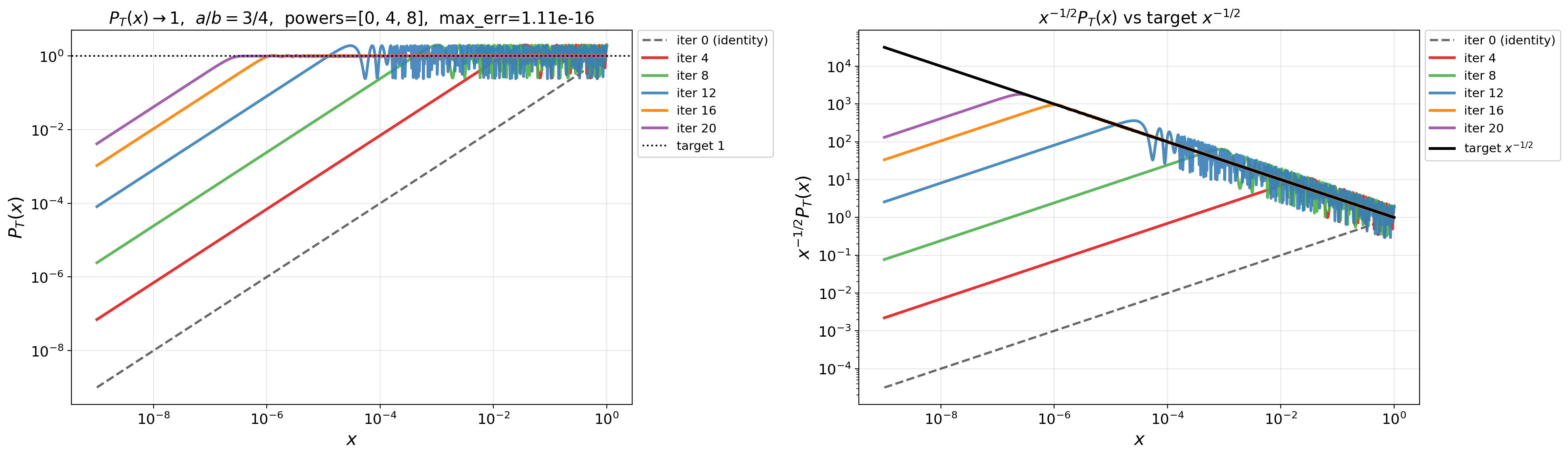
- Doubly exponential convergence rate: Convergence whose error decreases like an iterated exponential in the iteration count, much faster than geometric rates. "doubly exponential convergence rate"
- Dual exponent: The exponent paired with a Schatten -norm via $1/p+1/q=1$, which parameterizes the corresponding steepest-descent direction. "parametrized by the dual exponent "
- Dual norm: For a given norm, the dual norm is defined via a supremum over inner products and quantifies the size of linear functionals. "and the corresponding dual norm"
- Dual-normalized gradient: The gradient scaled by its dual norm to standardize update magnitudes across norms. "the dual-normalized gradient as "
- Equivariance: A property where updates commute with certain symmetry transformations, preserving trajectories up to those transformations. "Equivariance of Freon"
- Generalized Gauss-Newton (GGN) approximation: A curvature approximation replacing the Hessian with a positive semidefinite surrogate derived from first-order derivatives through the model outputs. "Generalized Gauss-Newton (GGN) approximation"
- Generalized third-order logistic recurrence: A chaotic iterative map used here for pseudo-random singular-value reshaping, extending the classical logistic map. "generalized third-order logistic recurrence "
- Geometric preconditioning: Structuring updates to follow a prescribed geometry (norm/metric), often to improve conditioning and convergence. "strict geometric preconditioning"
- Hölder's inequality: A fundamental inequality relating norms that underpins duality between Schatten - and -norms. "By H\"older's inequality"
- Isotropic curvature model: A simplified theoretical model assuming curvature is directionally uniform to analyze optimizer behavior. "an isotropic curvature model"
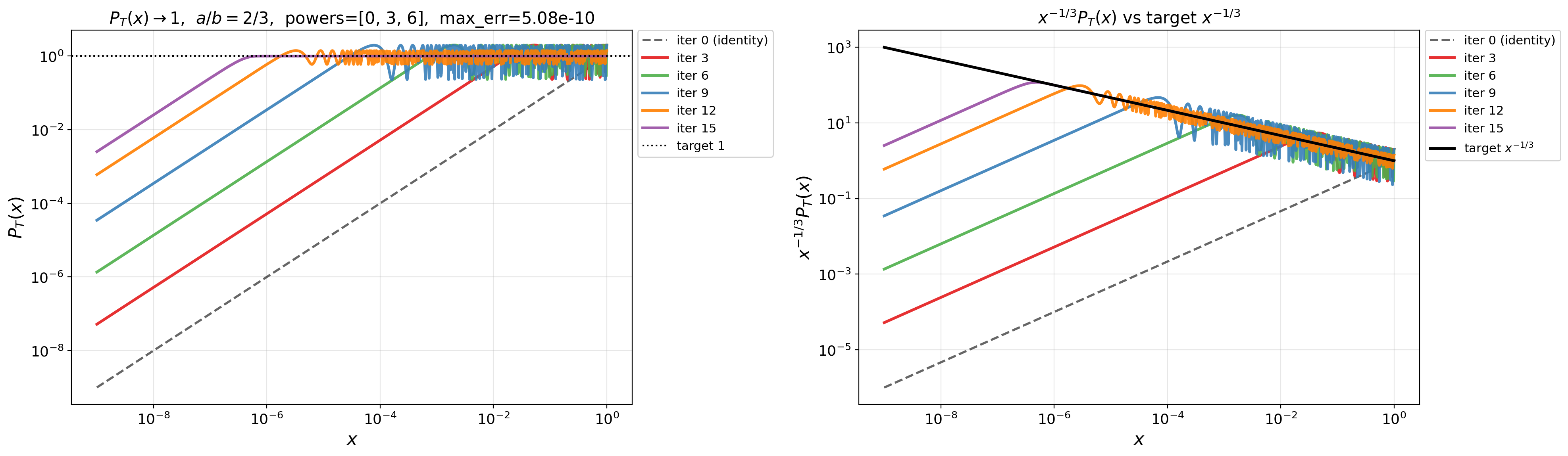
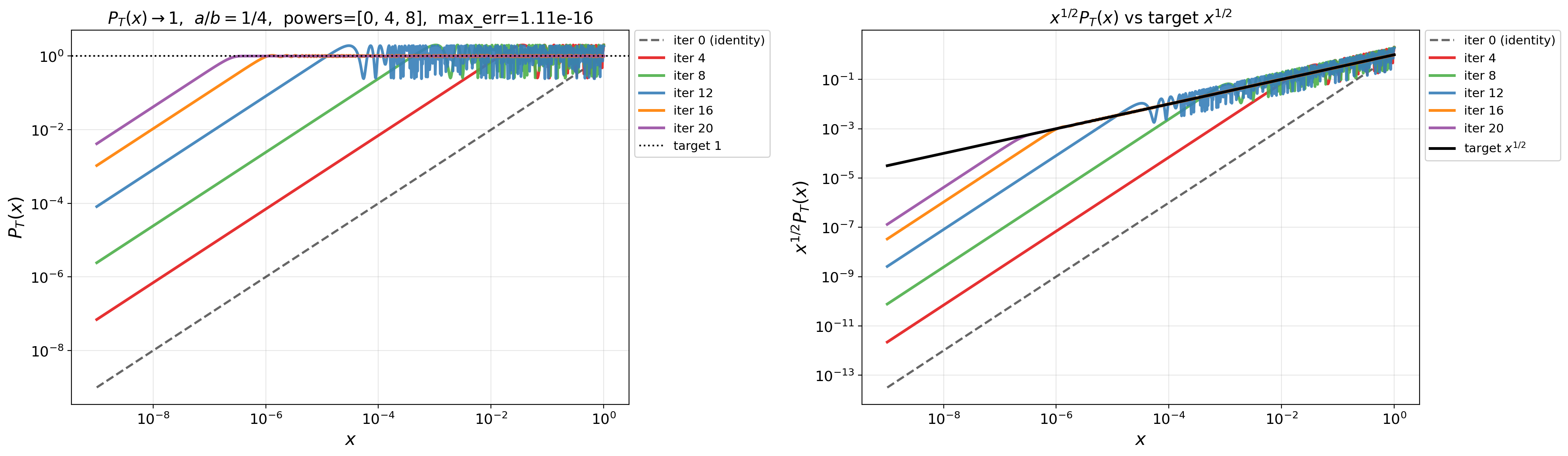
- Kaon: An “absurd” optimizer introduced in the paper that replaces gradient singular values with random noise yet performs competitively. "we introduce Kaon, an absurd optimizer"
- Linear Minimization Oracle (LMO): A subroutine that returns the steepest-descent direction under a given norm by maximizing an inner product over the unit ball. "Linear Minimization Oracles (LMOs)"
- LMO framework: The analytic approach that explains optimizers via steepest descent relative to a chosen (often non-Euclidean) norm and its oracle. "Limitations of the LMO Framework"
- Lipschitz continuous gradients: A smoothness condition where the gradient does not change faster than linearly with respect to a norm. "Lipschitz continuous gradients"
- Mean Schatten norm: A rescaled Schatten norm that normalizes by rank to stabilize step sizes across different values. "mean Schatten norm"
- Moore-Penrose pseudo-inverse: The generalized inverse of a matrix used to handle non-square or rank-deficient cases. "Moore-Penrose pseudo-inverse."
- Muon: A spectral optimizer that whitens gradient spectra (equalizes singular values) to target a specific geometry. "Muon maps all singular values uniformly to $1.0$."
- Newton--Schulz iterations: An iterative polynomial method for matrix functions such as inverse square roots, used in Muon-style updates. "Newton--Schulz iterations"
- Non-Euclidean optimization: Optimization performed with respect to non-Euclidean geometries (norms/metrics) rather than the standard Euclidean norm. "non-Euclidean optimization"
- Polar Express theory: A line of work analyzing and implementing polar-decomposition-based matrix iterations for optimization. "extending the polar express theory of \citet{amsel2025polarexpressoptimalmatrix}."
- Polar map: The mapping that returns the unitary (polar) factor of a matrix, often approximated via stable iterations. "approximate the polar map."
- Preconditioned Spectral Descent: Updates that reshape the gradient in its singular-vector basis by a prescribed function of singular values. "Preconditioned Spectral Descent"
- Proportional asymptotic limit: A high-dimensional regime where dimensions and batch size grow proportionally, enabling random-matrix asymptotics. "proportional asymptotic limit "
- Pseudoinverse-like endpoint: The extreme case of the Freon family () that resembles applying a pseudoinverse to the gradient. "the pseudoinverse-like endpoint ()"
- QDWH method: The QR-based Dynamically Weighted Halley iteration, a stable rational scheme for computing the polar decomposition/sign function. "QR-based Dynamically Weighted Halley (QDWH) method"
- Quasi-norm regime: The region for Schatten “norms” where the triangle inequality fails, breaking standard norm-based theory. "quasi-norm regime"
- Random feature model: A simplified model where features are randomly generated to analyze learning dynamics theoretically. "within a stochastic random feature model"
- Random matrix theory: The study of spectral properties of random matrices, used here to analyze asymptotic behavior of learning quantities. "Using standard random matrix theory"
- Random Spectral Descent: A class of updates that randomize the singular values of the gradient direction, analyzed for convergence. "Convergence of Random Spectral Descent"
- Remez algorithm: An iterative method for computing near-minimax (best) rational or polynomial approximations. "we use the Remez algorithm"
- Schatten p-norms: Matrix norms defined as equal to the norm of the singular values; generalize trace, Frobenius, and spectral norms. "Schatten -norms"
- Singular value decomposition: Factorization of a matrix into orthonormal singular vectors and nonnegative singular values. "singular value decomposition "
- Spectral ball: The unit ball in spectral (operator) norm, used to anchor step-size scaling across norms. "the spectral ball"
- Spectral descent: Optimization that updates parameters using directions derived from spectral (singular-value-based) transformations of the gradient. "spectral descent"
- Spectrum whitening: Mapping singular values to become equal, removing directional scaling differences in the gradient. "complete spectrum whitening"
- Unitarily invariant LMO: An LMO associated with a norm that is invariant under unitary transformations of the matrix. "unitarily invariant LMO"
- Unitarily invariant matrix norm: A norm that depends only on a matrix’s singular values and is unchanged by unitary rotations. "a unitarily invariant matrix norm"
- Zolotarev's best rational approximants: Optimal rational functions for approximating the sign function on intervals, enabling exceptionally fast matrix iterations. "Zolotarev's best rational approximants to the sign function"
Collections
Sign up for free to add this paper to one or more collections.