- The paper proposes a novel theoretical framework where Muon dynamics are formulated as a spectral Wasserstein flow, connecting optimal transport with neural network parameter updates.
- It rigorously derives gradient flows for spectral normalization by employing Schatten norm metrics that interpolate between classical and Muon-like behaviors.
- The work supports its theoretical claims with numerical experiments, demonstrating how different matrix norms influence convergence, stability, and global coordination in training.
Muon Dynamics as a Spectral Wasserstein Flow
Introduction and Context
This paper establishes a theoretical and algorithmic foundation for spectrally normalized optimization dynamics, focusing on a continuum limit interpretation of Muon-like parameter updates in modern neural network training. The analysis is grounded in a generalized notion of optimal transport, the Spectral Wasserstein geometry, parameterized by matrix norms—primarily the Schatten p-norms—on positive semidefinite (PSD) matrices. This framework connects classical Wasserstein geometry, Muon optimization, and their interpolants, extending both static and dynamic optimal transport to operate over transport costs defined by matrix norms of displacement covariances.
Spectral normalization has become integral to stabilizing deep learning, particularly in architectures where parameter matrices denote collections of neurons or weight blocks. This paper makes explicit how spectral normalization, notably Muon, can be formulated as an exact gradient flow in the space of probability measures endowed with these Spectral Wasserstein distances.
Spectral Wasserstein Geometry
The core of the construction is a one-parameter family of optimal transport metrics, denoted Wγ, where γ is a matrix norm on S+d. The principal choices are the Schatten p-norms, smoothly interpolating between:
- Trace norm (p=1): Recovers the classic quadratic Wasserstein geometry (W2).
- Frobenius norm (p=2): Provides an intermediate geometry.
- Operator norm (p=∞): Recovers the Muon geometry, aligned with recent spectral normalization-based optimizers.
In the static setting, the cost between probability measures μ and Wγ0 is the minimal value, over all couplings Wγ1, of Wγ2 applied to the displacement covariance Wγ3. The spectral Wasserstein cost robustifies the classical transport problem by penalizing global transport interactions via matrix norms rather than summing independent scalar costs.
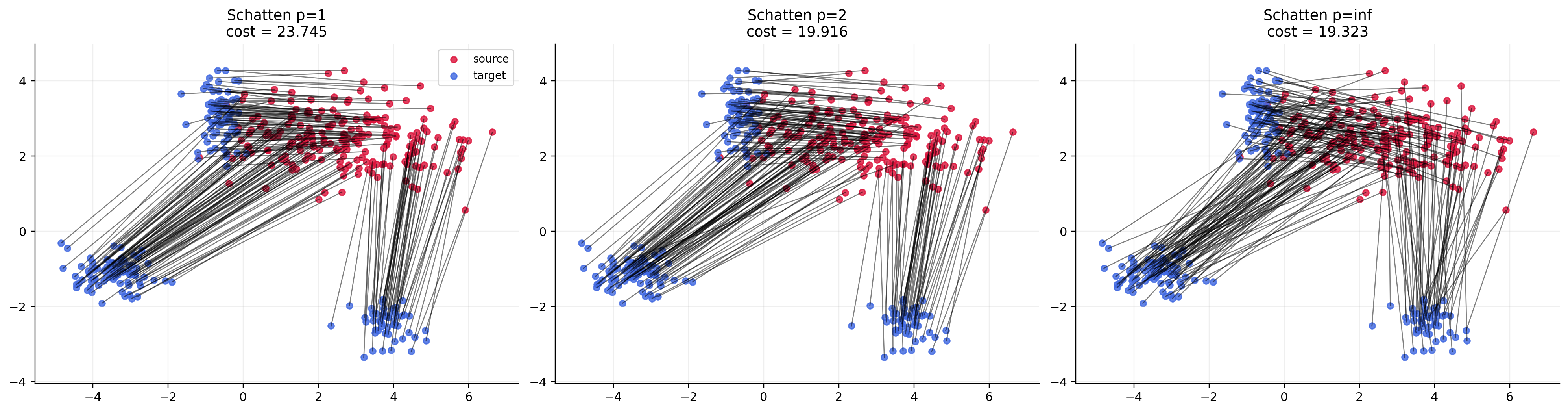
Figure 1: Static spectral couplings for Schatten Wγ4; red points: source, blue: target, black: assignment segments.
The Kantorovich and Monge formulations are distinguished, with the static spectral cost generally being strictly less than the Monge-restricted version for nontrivial norms. Theoretical results ensure that for all Schatten norms the cost defines a genuine metric, equivalent in topology to Wasserstein, and explicitly interpolate between classical and Muon-like behaviors.
The paper proves (via the Benamou–Brenier framework) that, provided the matrix norm Wγ5 is monotone, the static and dynamic Spectral Wasserstein costs coincide. The dynamic formulation interprets the transport as a curve of measures solving a continuity equation, where at each instant the cost is given by the action Wγ6. This leads directly to the existence of constant-speed geodesics in the space of measures, given by displacement interpolation under the optimal coupling.
Another key result is a robust comparison: for Schatten-Wγ7 norms, the cost sits between explicit multiples (depending on Wγ8 and Wγ9) of the classical Wasserstein distance.
Gaussian Marginals and Bures-Type Covariance Metrics
In the Gaussian setting, the infinite-dimensional optimal transport problem reduces to constrained optimization over block covariances, generalizing the Bures metric. For commuting covariances, the spectral distance admits a closed form, with the Schatten-γ0 geometry yielding explicit dependence on the difference of square roots of eigenvalues.
This positions the Spectral Wasserstein distances as natural generalizations of the Bures–Wasserstein metric to broader classes of matrix norms and supports their use in analyzing neural network representations and dynamics, where Gaussians serve as analytical proxies.
Gradient Flows and Particle Dynamics
The central implication for optimization is that normalized spectral flows—most notably the Muon dynamic—emerge as metric gradient flows in the measure space endowed with γ1. The gradient flow is given via a duality map for the cost structure, yielding explicit, norm-dependent update rules. For the operator norm, this recovers the Muon update as an exact limit.
The particle (finite-γ2) analog is a matrix-normalized flow, with explicit selectors for each Schatten norm based on matrix singular value decomposition (SVD). The update rules interpolate between vanilla gradient descent (γ3), Frobenius-intermediate flows (γ4), and the Muon dynamic (γ5).
For Gaussian-invariant objectives and affine functionals, the framework ensures closed-form ODEs for means and covariances, allowing tractable analysis of learning dynamics under spectral normalization.
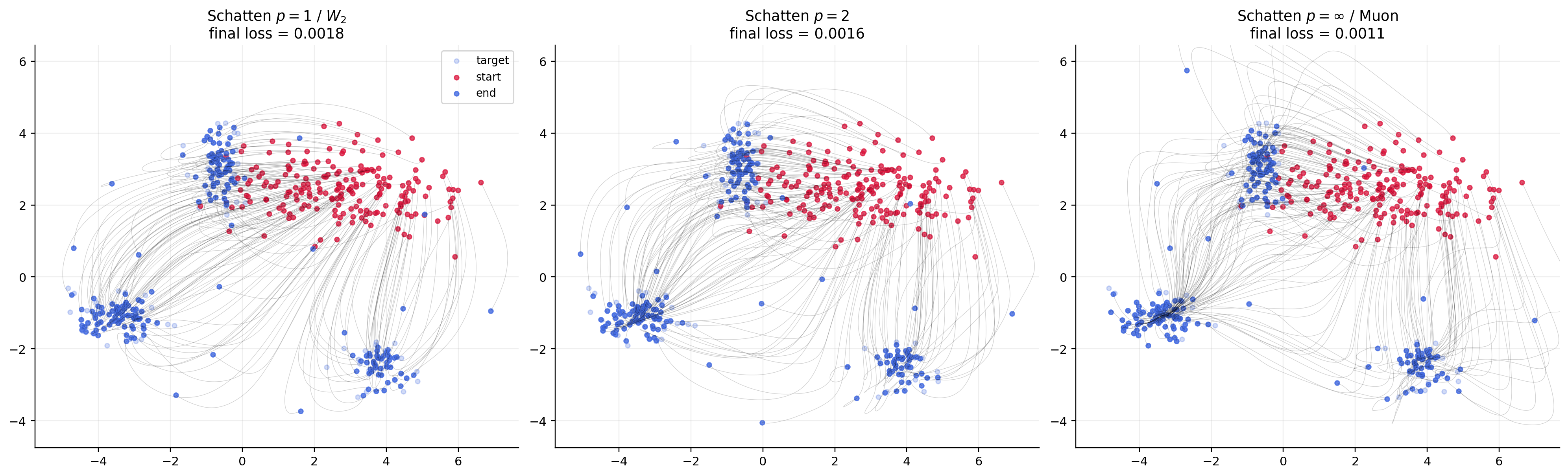
Figure 2: Particle trajectories for MMD flows; operator-norm (Muon) induces globally coordinated motion, Frobenius is intermediate, trace-norm yields local flows.
Implications for Neural Network Training
By formally connecting spectral normalization (and Muon) to rigorous optimal transport gradient flows, the paper provides a theoretical lens for understanding and comparing modern normalization-based optimizers. The results can explain empirical differences in convergence and generalization observed in deep networks, as the geometry of the transport cost dictates the collective behavior of parameter updates.
Furthermore, the reduction of positively γ6-homogeneous models to spherical, unbalanced transport problems establishes a pathway for analyzing wider two-layer MLPs and potential functional extensions to nontrivial parameterizations.
Numerical Experiments
The paper presents comparative evaluations of static couplings and spectral-gradient flows for MMD loss with Schatten γ7. The experiments illustrate the nature of the couplings and the induced dynamics, with Muon (operator norm) exhibiting the most globally coordinated updates, while trace-norm flows are highly local, and Frobenius norm provides an interpolation.
Theoretical and Practical Implications
Theoretically, the generalization of Wasserstein geometry enables sharper characterization of measure-valued optimization dynamics, geodesic convexity, and flows over empirical and infinite-width neural representations. The formal identification of these dynamics with explicit normalized update rules grounds the use of spectral normalization in deep learning and opens the space for principled analysis of their stability, generalization, and convergence.
Practically, the results can inform the design of new optimizers in large-scale training, where blockwise or layerwise normalization is standard. The tools developed also suggest new regularization frameworks, robustness analyses (by maximizing and minimizing over cost structures), and potential metrics for generative modeling or representation learning that account for global, coordinated transport between distributions.
Future Directions
Open problems highlighted include finer characterizations of optimal couplings beyond the conditional Brenier regime, global convergence analysis for neural network training outside the classical Wasserstein setting, and robustification of the framework to block-separable or more structured matrix norms relevant in full-stack architectures.
The paper's unbalanced transport reduction for homogeneous models invites further exploration into generalized spherical transport geometries and their connections to Wasserstein–Fisher–Rao and beyond.
Conclusion
This work provides a rigorous, measure-theoretic interpretation of matrix-normalized gradient dynamics in large-scale learning, bridging modern optimization algorithms (notably Muon) and advanced transport-theoretic tools. By analytically and algorithmically interpolating between classical, local, and globally coordinated update schemes, it equips researchers with a formal apparatus for designing, understanding, and extending normalized optimization in neural architectures (2604.04891).