- The paper introduces BICR, a framework that uses contrastive ranking between real and null images to distinguish visually grounded from ungrounded outputs.
- It demonstrates state-of-the-art calibration (ECE=7.09%, BS=18.41%) and discrimination (AUCPR=87.47%, AUROC=78.63%) across diverse evaluation tasks.
- BICR achieves these gains using 4–18× fewer parameters and pre-generation confidence estimation, ensuring zero inference-time overhead.
Blind-Image Contrastive Ranking for LVLM Confidence Estimation: A Technical Examination
Introduction and Motivation
Large Vision-LLMs (LVLMs) exhibit a persistent vulnerability: visual ungroundedness, where model predictions are driven almost entirely by linguistic priors rather than by actual image content. This failure mode is not trivially detectable—the model's output may be confident, fluent, and even correct, yet the image is causally irrelevant to the answer. Conventional confidence estimation methods provide no mechanism to distinguish between grounded and ungrounded outputs, leading to systematically inflated confidence on visually ungrounded predictions and undermining the reliability of LVLMs, particularly in high-stakes multimodal domains.
This work systematically interrogates these limitations by introducing Blind-Image Contrastive Ranking (BICR): a model-agnostic, white-box confidence estimation framework that explicitly enforces attention to visual grounding as a reliability signal. BICR targets the regime where current estimates fail—simultaneously attaining strong confidence calibration (alignment between confidence and correctness frequencies) and discrimination (separation between correct and incorrect predictions), across multiple LVLM families and a diverse suite of evaluation tasks.
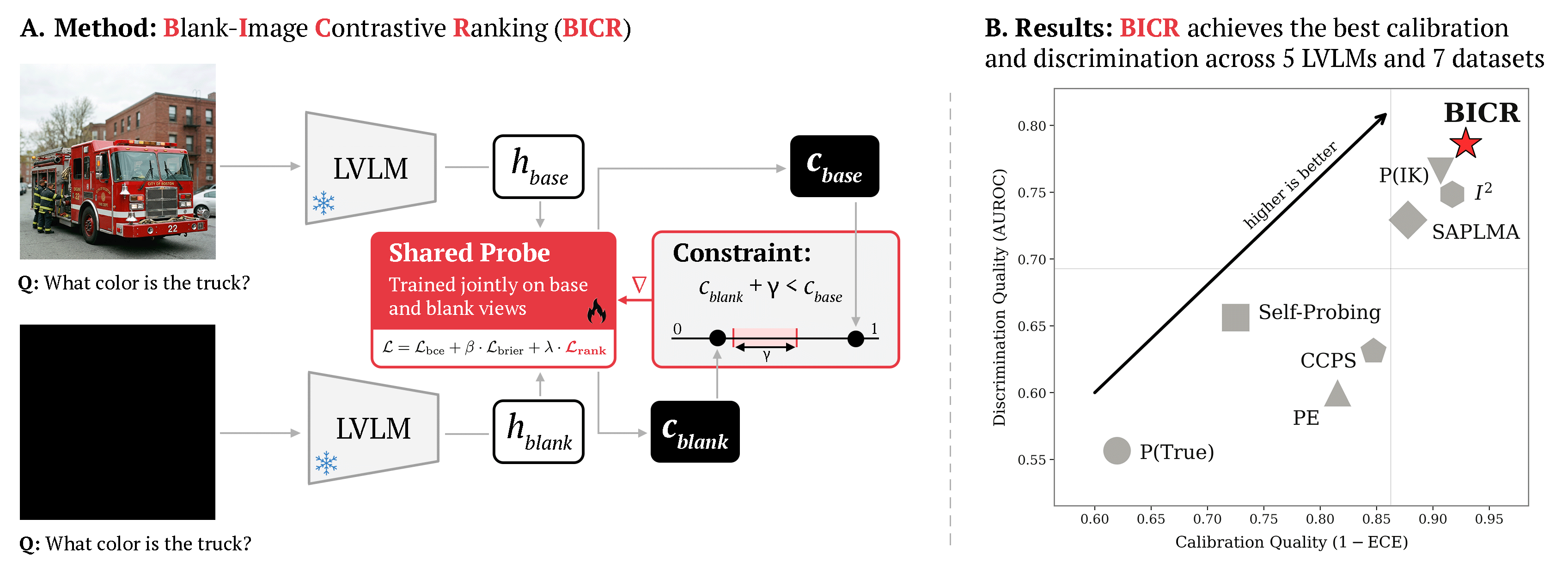
Figure 1: Overview of the BICR framework, with training-time contrastive mechanism and headline joint calibration/discrimination results across methods.
Methodology
BICR operates via contrastive probing at the level of LVLM hidden states. For each training instance, the method extracts the hidden state at the final prompt token under two conditions: (1) using the actual image, and (2) substituting the image with a solid black "null" image, keeping the question constant. A lightweight probe (multi-layer perceptron) is trained on the real-image hidden state using three loss terms: a balanced BCE for correctness supervision, a Brier score penalty to directly regularize calibration, and—critically—a ranking loss that enforces a margin γ such that for every correct sample, the probe’s confidence on the real image must exceed that on the blacked-out image.
At test time, only the real-image pass is used; the blank view is a training-time device, incurring zero inference overhead.
Evaluation: Benchmark, Tasks, and Metrics
A new comprehensive benchmark "VLCB" is constructed, aggregating seven open-source VQA-style datasets spanning compositional reasoning (GQA), object hallucination (POPE), medical imaging (GMAI-MMBench), financial document comprehension (MME-Finance), and college-level multi-choice exams (MMMU-Pro), along with open-ended visual dialogue (LLaVA-in-the-Wild). Five prominent open-weight LVLMs (Qwen3-VL-8B, LLaVA-NeXT-13B, InternVL3.5-14B, Gemma-3-27B, DeepSeek-VL2) are systematically evaluated, with correctness labels assigned uniformly via an LLM judge.
Calibration is measured by Expected Calibration Error (ECE) and Brier Score (BS), while discrimination is assessed by area under the precision-recall (AUCPR) and ROC (AUROC) curves. Seven state-of-the-art confidence estimation baselines spanning prompt-based, internal-probing, and representation-stability paradigms provide strong points of comparison.
Results
BICR achieves state-of-the-art calibration and discrimination jointly, with significant improvements on both axes relative to all baselines:
- Cross-LVLM averages: ECE = 7.09%, BS = 18.41%, AUCPR = 87.47%, AUROC = 78.63% (superior or tied best on all metrics).
- Gains are robust to both pooled and per-dataset equal-weight aggregation; ablation confirms the ranking loss is essential for discrimination (−3.3 AUROC points if removed), with the Brier term conferring calibration benefits.
- All improvements in discrimination are statistically significant compared to trained probing baselines, and calibration advantages are significant for all but one (InternalInspector) under pooled aggregation.
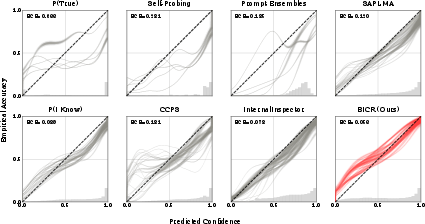
Figure 2: Cross-LVLM reliability diagrams across all eight methods; BICR achieves both lowest ECE and balanced distribution of confidence mass.
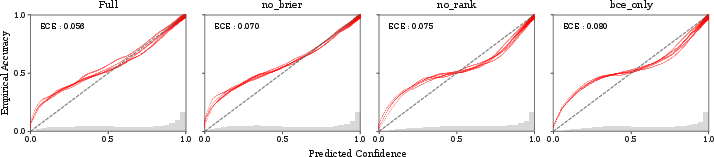
Figure 3: Loss ablation per-seed reliability diagrams; the rank loss is critical for curve alignment and confidence mass spread.
Per-dataset breakdown shows BICR’s advantage is amplified on visually grounded, high-difficulty tasks (e.g. medical imaging, MMMU-Pro), with the method’s calibration and discrimination improvements concentrating where ungroundedness is most likely and most impactful. On simpler binary detection (POPE, GQA), several baselines are competitive but lack generalization across more demanding domains.
Additional analysis shows BICR’s improvements are achieved with 4–18× fewer parameters than the strongest competing probe (InternalInspector), reinforcing that the gains derive from improved training objectives—not from increased probe capacity.
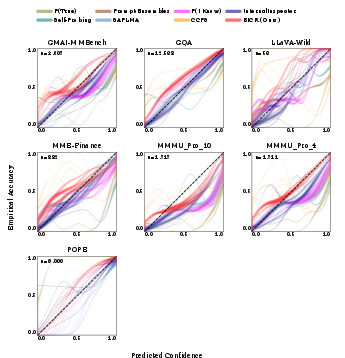
Figure 4: Per-dataset reliability diagrams for Qwen/Qwen3-VL-8B-Instruct; BICR consistently achieves best calibration especially on harder datasets.
Theoretical and Practical Implications
Causal signal for visual grounding
BICR demonstrates that representational contrasts induced by image nullification are inherently informative: the difference in hidden states between real and blacked-out images is a reliable predictor of answer correctness, resolving the prior ambiguity in what information internal probes actually leverage. Pure BCE-trained probes collapse when faced with visually ungrounded predictions; only contrastive exposure during training enables explicit differentiation.
Decoupling calibration and discrimination
Contrary to previous belief that calibration/discrimination trade-offs are fundamental, BICR shows these axes can be aligned given the right training signal—the rank loss induces both sharper separation and more informative absolute probabilities.
Training-time cost, inference-time parity
By relegating the contrastive computation to the training phase, BICR introduces no additional inference cost compared to single-view probes. This reallocation is critical for real-world deployment, particularly in latency- or compute-sensitive applications.
Pre-generation confidence estimation
BICR operates at the pre-generation hidden state, enabling confidence estimation before any answer is produced, which is valuable for triage or escalation without wasteful generation passes.
Critical Analysis and Future Directions
While BICR sets a new standard for confidence estimation in open-weight LVLMs, certain limitations remain:
- Proprietary/closed-weight LVLMs: The method requires access to hidden representations, precluding direct application to API-limited models (e.g., GPT-4V). Extending contrastive principles to black-box settings is an important open problem.
- Operational semantics of grounding: The blank-image contrast is an operational proxy; it does not guarantee semantic grounding in all cases, and errors in downstream reasoning may be unaffected by this intervention.
- Distributional assumptions: The benchmark composition is heavily weighted to standard datasets (GQA/POPE); additional coverage (e.g., video, 3D, multilingual, or embodied modalities) would further validate generality.
- Robustness to null-image choice: Empirically, the solid-black null is optimal; however, validating the approach across other degenerate visual conditions and for different input modalities would tighten theoretical understanding.


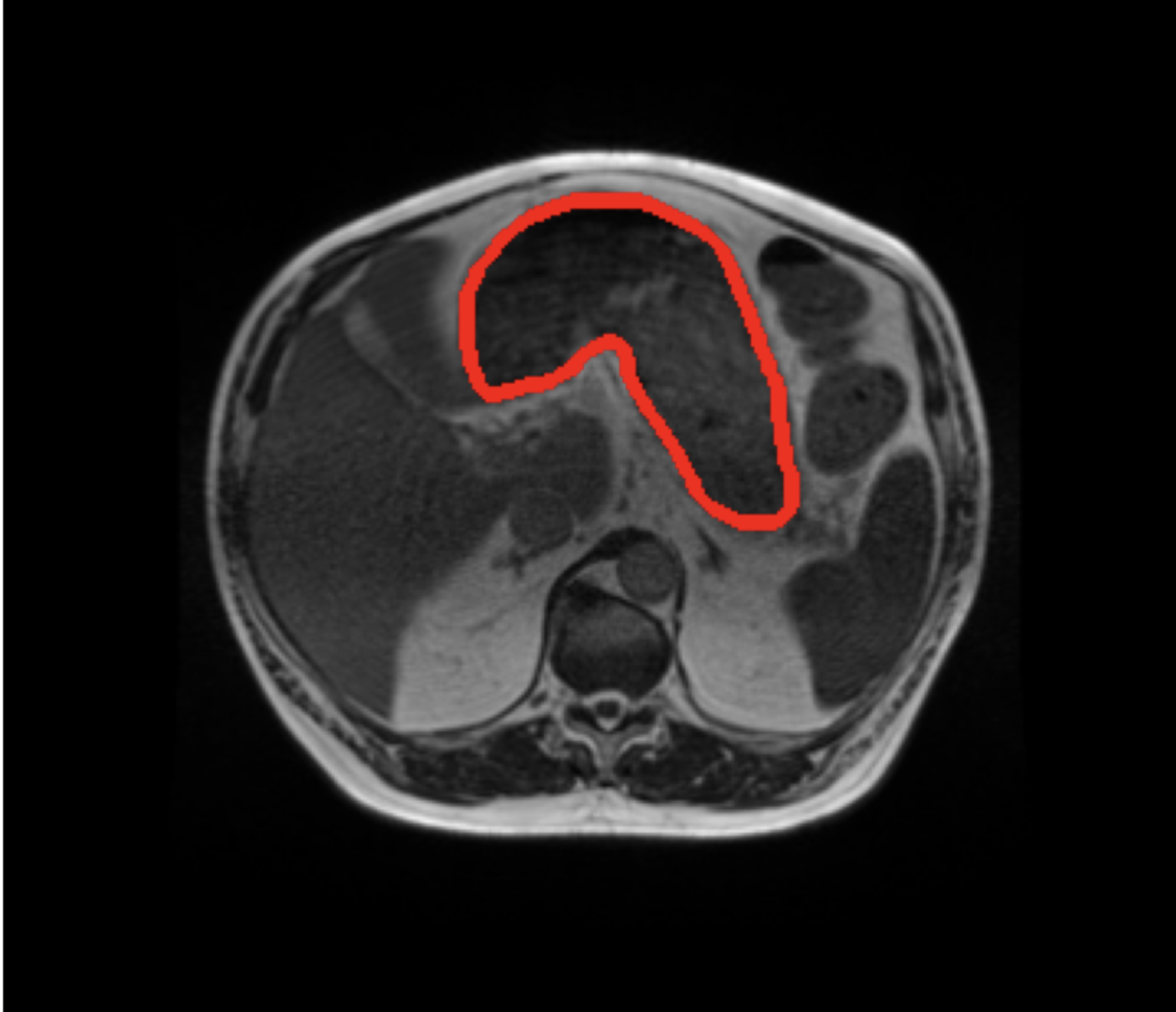
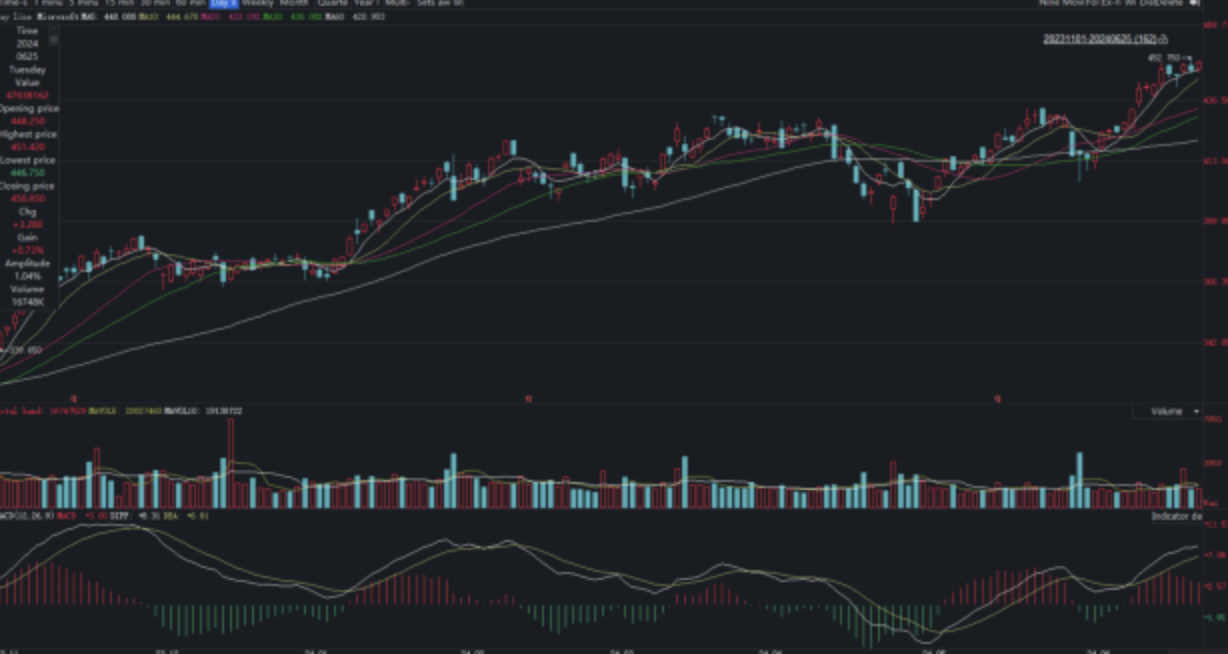


Figure 5: Sample images and question types from the seven datasets in VLCB, highlighting broad task diversity.
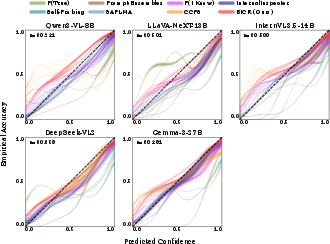
Figure 6: Pooled per-LVLM reliability diagrams; BICR maintains consistent calibration across all model families.
Conclusion
Blind-Image Contrastive Ranking offers a rigorous and scalable solution to the challenge of quantifying and calibrating confidence in LVLM outputs under the threat of visual ungroundedness. By synthesizing a training-time contrastive regime and leveraging lightweight probes, BICR accomplishes simultaneous state-of-the-art calibration and discrimination with minimal inference cost and superior parameter efficiency. The method’s release, alongside the VLCB benchmark, positions it as both a tool for scientific inquiry into LVLM behavior and a practical building block for trustworthy deployment in high-assurance domains. Future research should generalize the approach to closed models and more diverse multimodal scenarios, as well as sharpen the operational definitions and diagnostics for multimodal grounding.