- The paper presents a new method combining grounding of text responses in visual inputs with temperature scaling to align model confidence with true accuracy.
- It leverages cross-modal consistency and self-consistency to improve calibration for tasks such as medical and visual question answering.
- Experimental results demonstrate lower Expected Calibration Error and enhanced reliability diagrams, ensuring more trustworthy model outputs.
Calibrating Uncertainty Quantification of Multi-Modal LLMs using Grounding
Introduction
The paper discusses a new method for calibrating Uncertainty Quantification (UQ) in multi-modal LLMs, emphasizing the alignment of confidence with model accuracy. The approach involves grounding textual responses in visual inputs, thereby addressing typical pitfalls in existing UQ techniques that often misreport high confidence for consistently incorrect responses. Grounding is complemented with temperature scaling to adjust the confidence level of the grounding model accurately, thus improving overall calibration on various tasks such as medical question answering (Slake) and visual question answering (VQAv2).
Methodology
The proposed method integrates cross-modal consistency with self-consistency for improved confidence calibration. By linking textual responses to visual data, the framework provides a calibration basis grounded in real-world contexts, tackling the inherent uncertainty in grounding models. The process includes:
- Cross-Modal Consistency: Leveraging the relationship between text and image to assess the correctness of responses.
- Temperature Scaling: Applied as a post-processing calibration technique to adjust the grounding model's confidence, ensuring alignment with true accuracy probabilities.
The approach is designed to function across various multi-modal tasks, with thorough evaluations illustrating enhanced calibration as compared to existing techniques.
Experimental Results
The framework's efficacy is demonstrated across the Slake medical dataset and the VQA dataset, illustrating superior calibration through lower Expected Calibration Error (ECE). The reliability diagrams featured show substantial alignment improvements when grounding models are employed compared to baseline UQ techniques (Figure 1).
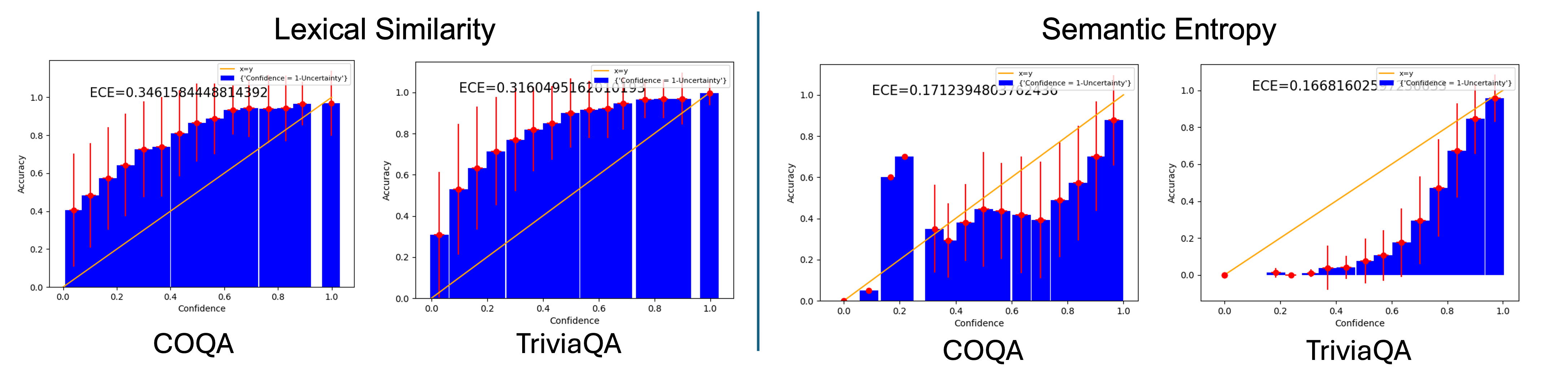
Figure 1: Reliability diagrams with the expected accuracy of Llama-2-13B on COQA and TriviaQA datasets plotted as a function of the model's confidence predicted by self-consistency-based UQ approaches: Lexical Similarity.
The experimental setup entails calibrating uncertainty using various grounding model types: segmentation-based, semantic-based, and foundation models, each contributing uniquely to the calibration accuracy.
Conclusion
This research provides a robust framework for calibrating UQ in multi-modal LLMs, significantly addressing the pitfalls of self-consistency approaches that fail to equate consistency with accuracy. Through grounding and temperature scaling, the work promises improved deployments of LLMs in critical fields such as healthcare, where model reliability is paramount. Future directions include extending these strategies to diverse modalities beyond image-text inputs, enhancing the versatility and application scope of multi-modal LLMs.

