- The paper introduces a novel reinforcement learning framework that decouples visual and reasoning confidence to improve calibration in LVLMs.
- It leverages metrics like KL divergence and entropy for intrinsic visual certainty, significantly reducing Expected Calibration Error and hallucinations.
- Empirical evaluations across 13 benchmarks demonstrate enhanced accuracy, robust uncertainty localization, and improved safety in high-stakes applications.
VL-Calibration: Decoupled Confidence Calibration for Large Vision-LLM Reasoning
Introduction and Motivation
Large Vision-LLMs (LVLMs) have demonstrated strong performance in multi-modal reasoning, yet remain susceptible to overconfidence, notably manifesting as hallucinations—incorrect but high-certainty predictions. This overconfidence impedes reliability and safety in high-stakes applications. The prevalent confidence calibration strategies inherited from language-only models focus on modeling a single holistic confidence score, which is insufficient for LVLMs, as errors may arise from either failed visual perception or subsequent reasoning. Such conflation obfuscates which error source is responsible and hinders effective calibration.
VL-Calibration proposes a reinforcement learning framework for confidence calibration that actively decouples confidence estimation into visual and reasoning components, accompanied by targeted training strategies and intrinsic visual certainty estimation mechanisms. This modular confidence supervision enables improved uncertainty localization and more robust calibration for multimodal reasoning systems.
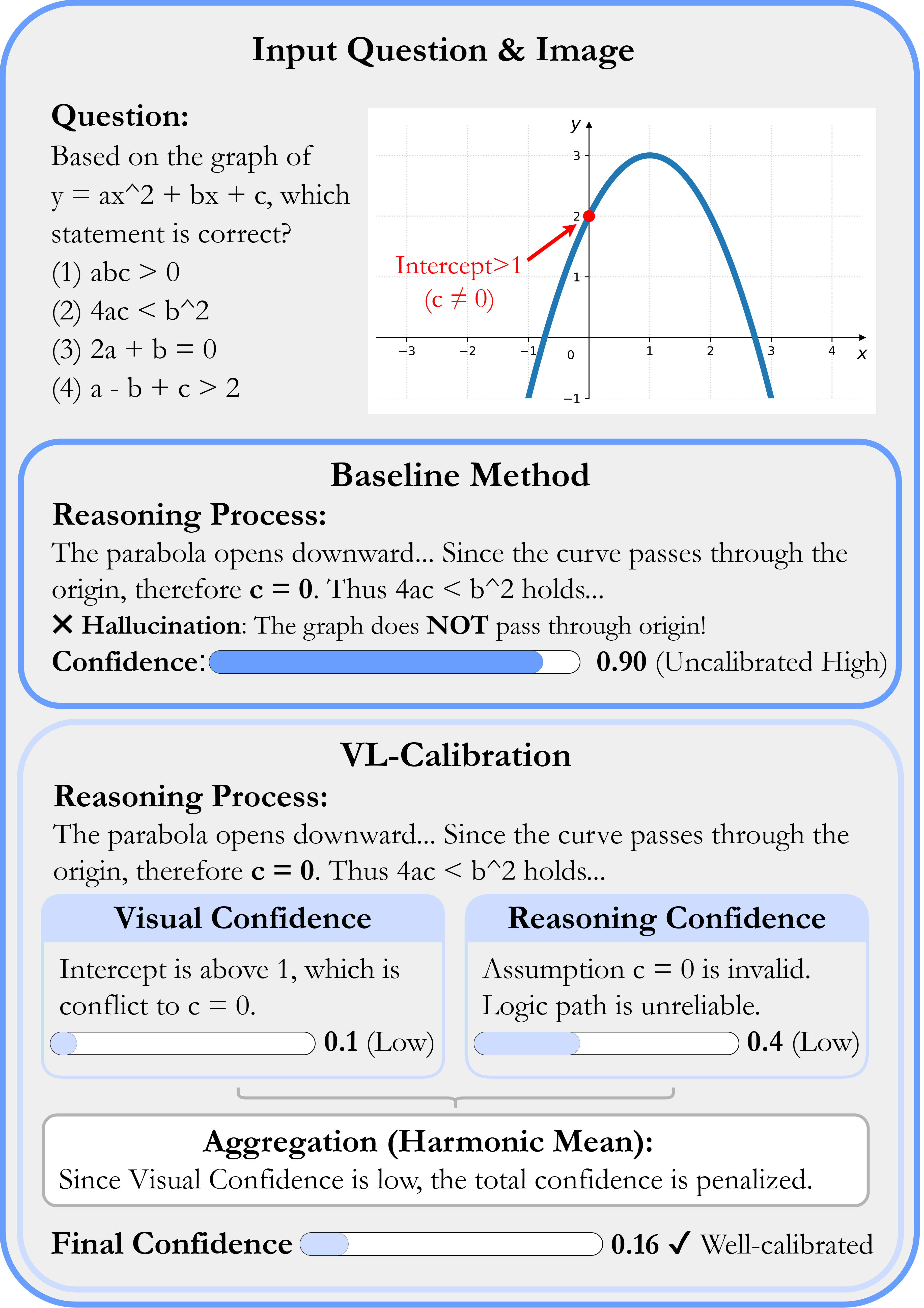
Figure 1: The method contrasts holistic (single) confidence calibration (upper) with decoupled visual and reasoning confidence (lower), showing improved identification of uncertainty sources and calibration.
Decoupled Confidence Modeling and Framework
VL-Calibration structures inference into two explicit reasoning phases: visual perception and logical reasoning. The model generates a visual rationale with a corresponding visual confidence score, followed by a reasoning chain with a separate reasoning confidence score. A final holistic confidence for the answer is derived via the harmonic mean of these decoupled confidences, emphasizing conservative aggregation.
Figure 2: The VL-Calibration framework comprises decoupled confidence inference, intrinsic visual certainty estimation, and GRPO-based reinforcement learning with advantage reweighting.
Supervision of visual confidence is problematic due to the absence of explicit perception ground truths. VL-Calibration instead leverages a pseudo-supervision signal based on two metrics: (1) visual grounding, quantified by KL divergence between model outputs with original versus perturbed images, and (2) internal certainty, measured using the entropy of output token probabilities for visual descriptions. The visual certainty reward is computed as the log-ratio of these metrics and normalized to [0,1].
Token-level advantage reweighting further enables fine-grained penalization during RL training: tokens with low visual certainty are more severely penalized when predictions are incorrect, directly targeting hallucination suppression.
Main Results and Empirical Validation
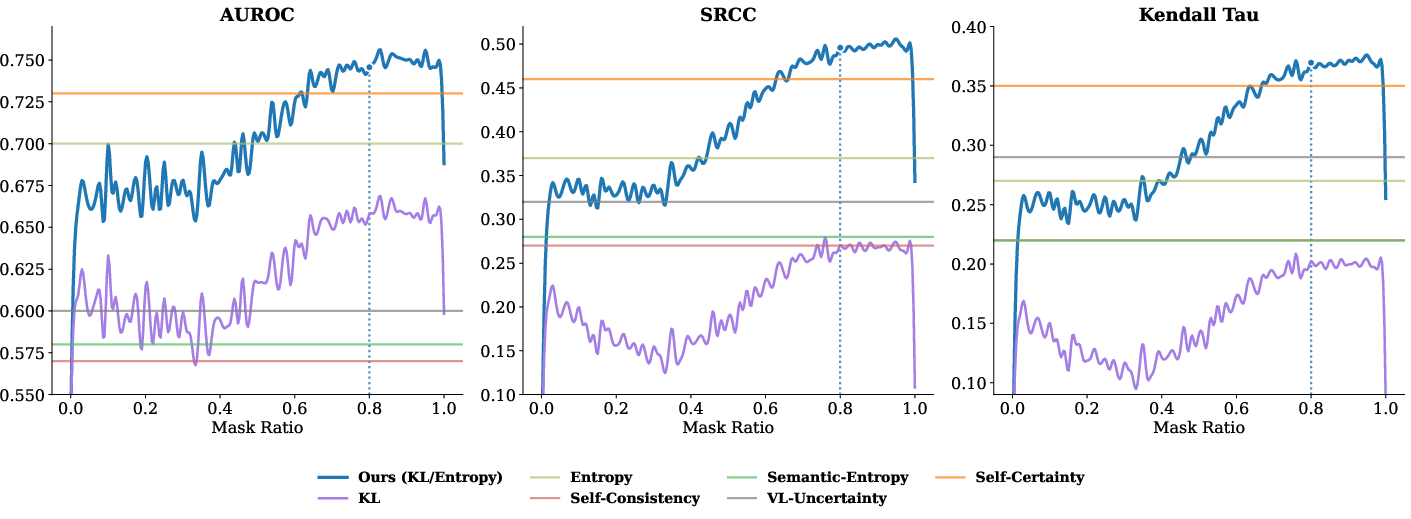
VL-Calibration demonstrates robust improvements in both calibration and accuracy across 13 evaluation benchmarks, spanning mathematical, geometric, logical, and multi-disciplinary reasoning, and generalizes effectively across scales (4B, 8B, and 30B models, Qwen and InternVL architectures).
Quantitative Results:
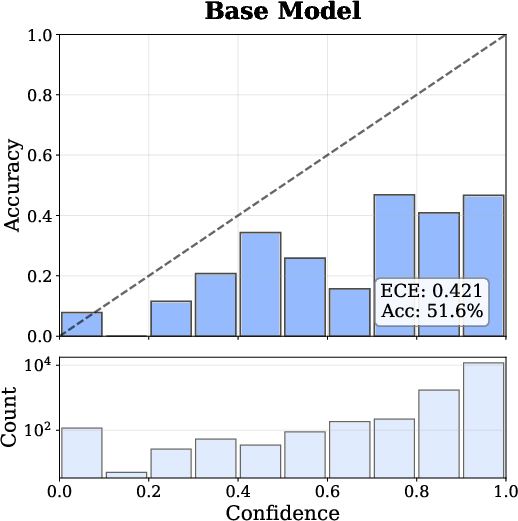
- Expected Calibration Error (ECE) reduced from 0.421 (baseline) to 0.098 (VL-Calibration, Qwen3-VL-4B).
- Accuracy improved by 2.3–3.0% over strongest baselines (e.g., RLCR), especially on benchmarks requiring acute visual reasoning such as DynaMath, MathVerse, and MMMU-Pro.
- Gains are consistent for both accuracy (ACC), ECE, and AUROC across OOD (out-of-distribution) tasks and different model architectures.
Ablations confirm:
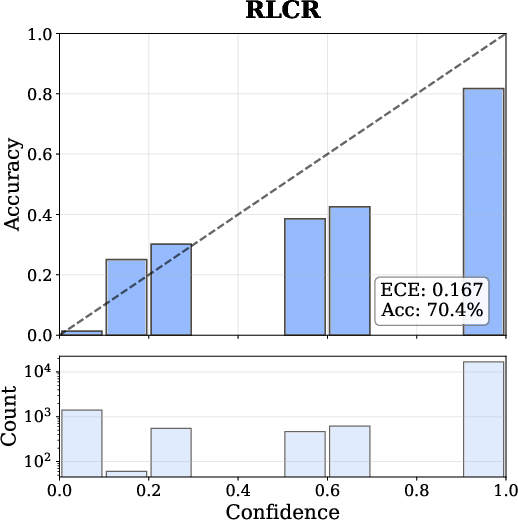
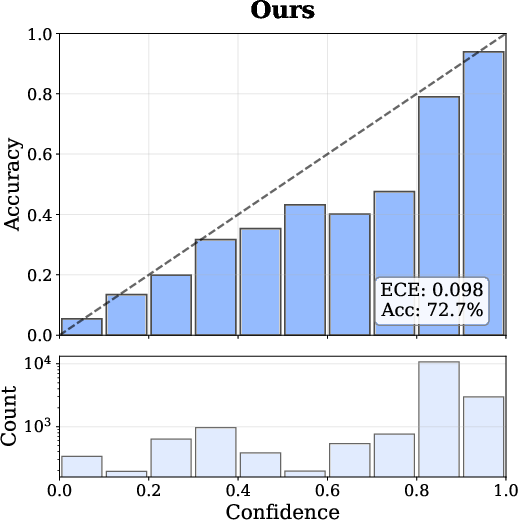
Figure 4: Reliability diagrams exhibit drastic calibration improvement—the model's predicted confidence nearly matches empirical accuracy.
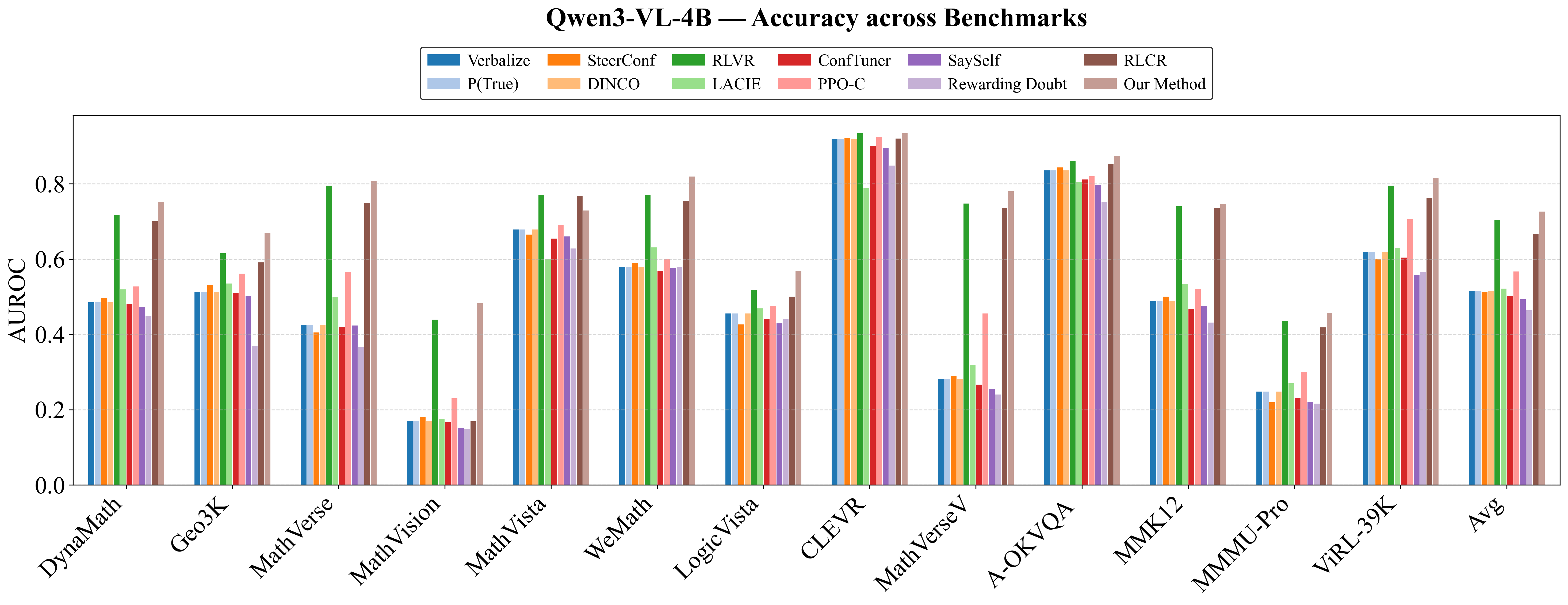
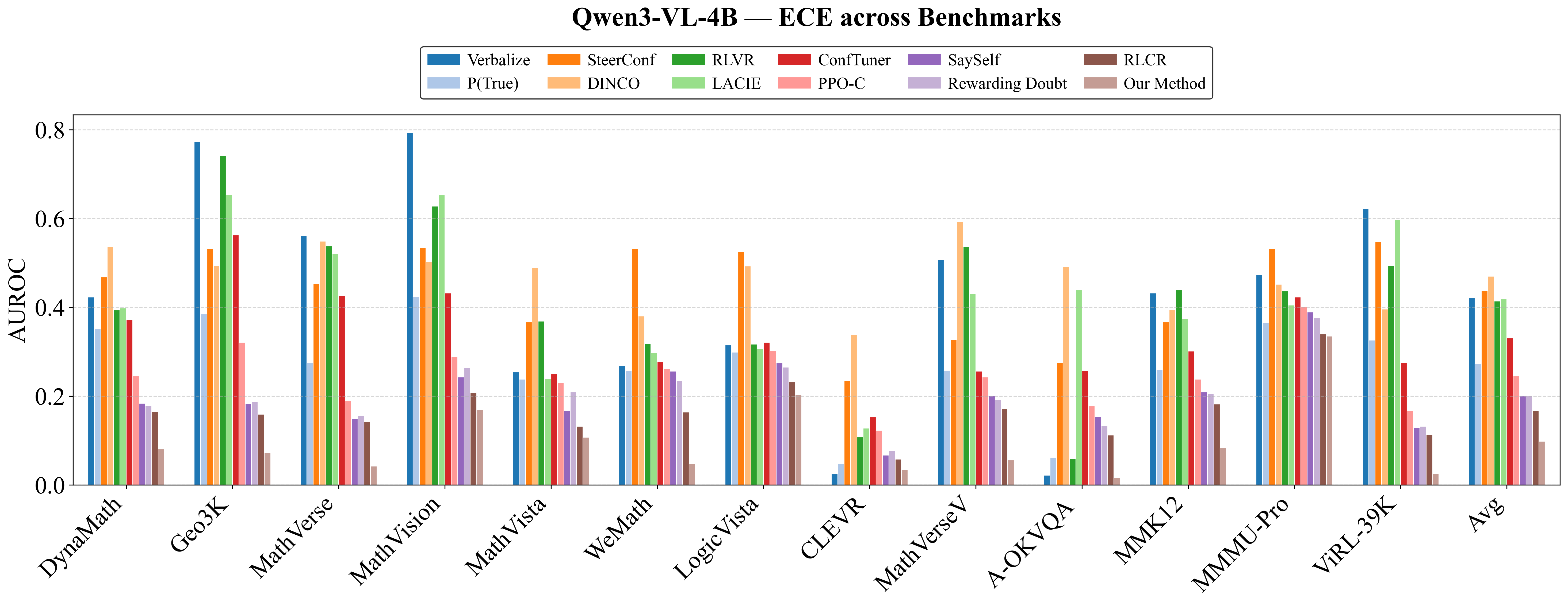
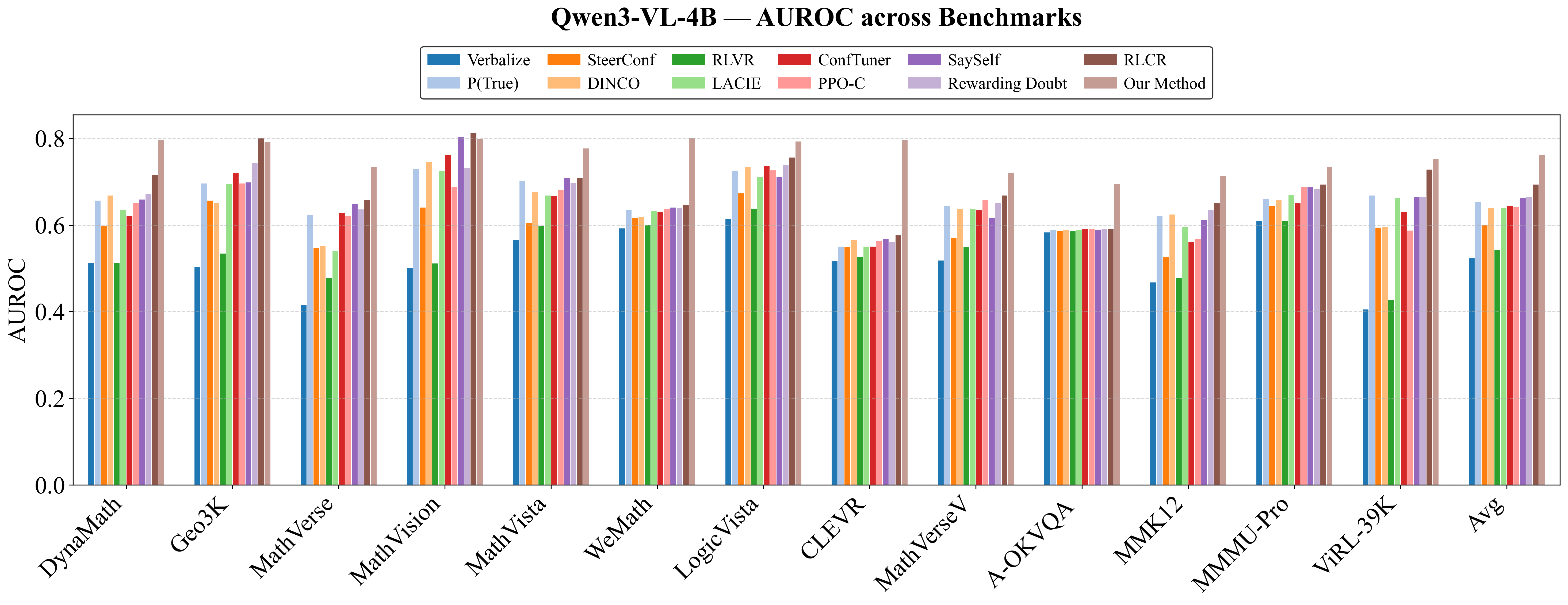
Figure 5: VL-Calibration achieves uniformly superior accuracy, ECE, and AUROC compared to baselines over multiple benchmarks (Qwen3-VL-4B).
Mechanistic Analysis
Decoupled calibration integrates fine-grained uncertainty quantification:
- Visual confidence is tightly associated with visual correctness—decoupled scores decrease for visually incorrect responses, sharply distinguishing error sources.
- On visually unanswerable samples (e.g., image removed), VL-Calibration lowers its confidence significantly (Figure 6), while baselines remain overconfident, substantiating improved visual uncertainty estimation.
- Visualization of the joint distribution of visual and reasoning confidence (Figure 7) reveals substantial off-diagonal mass, confirming that perception and reasoning uncertainties are effectively disentangled.
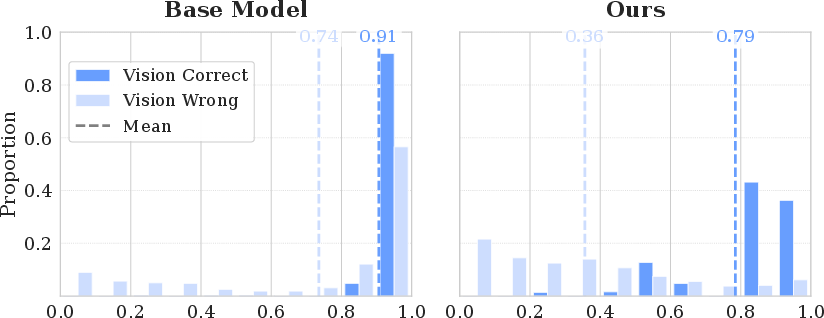
Figure 8: The visual confidence score distribution sharply distinguishes between visually correct and incorrect responses post-calibration.
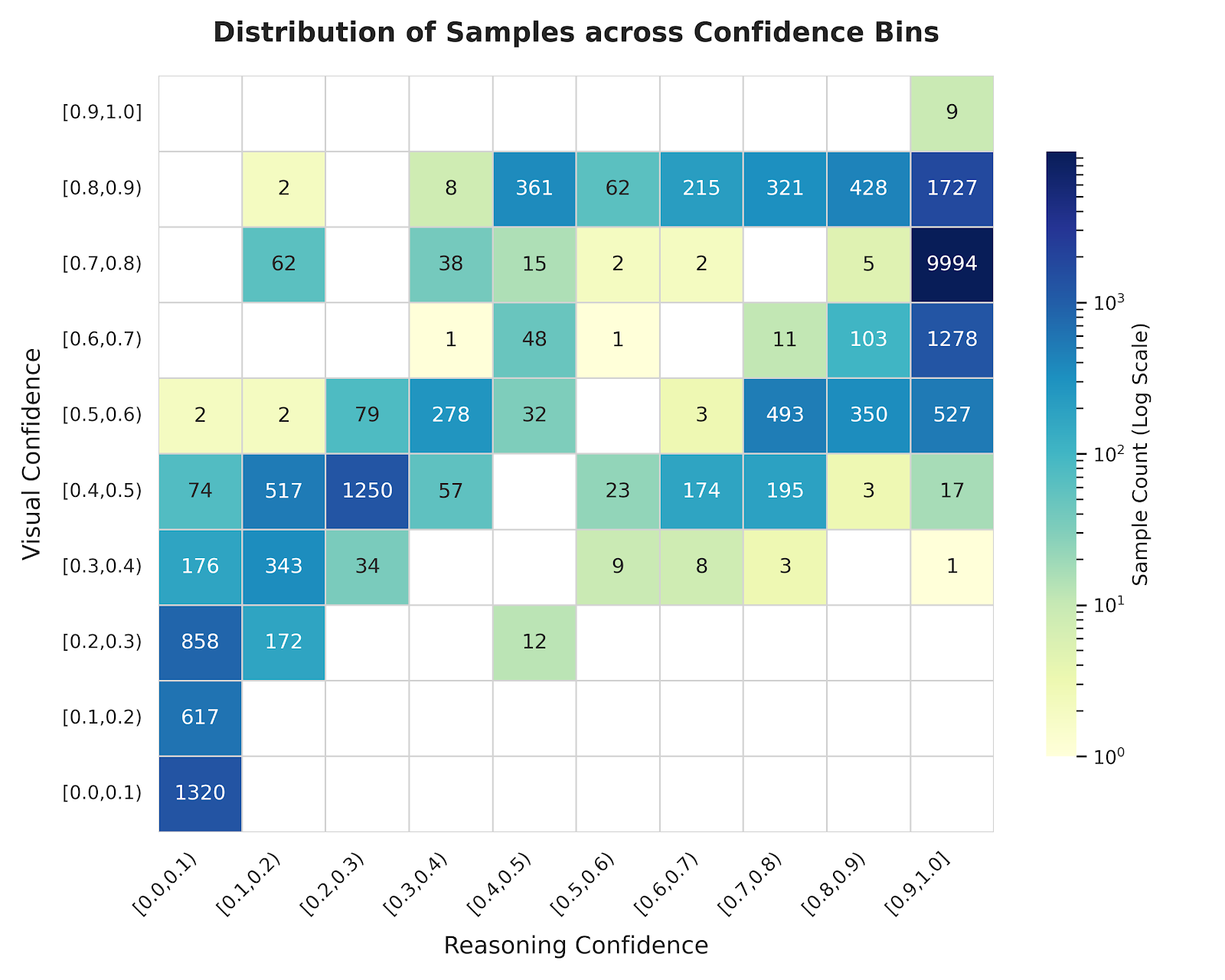
Figure 7: Heatmap reveals off-diagonal structure—visual and reasoning confidence values are decorrelated, confirming that they measure distinct epistemic uncertainties.
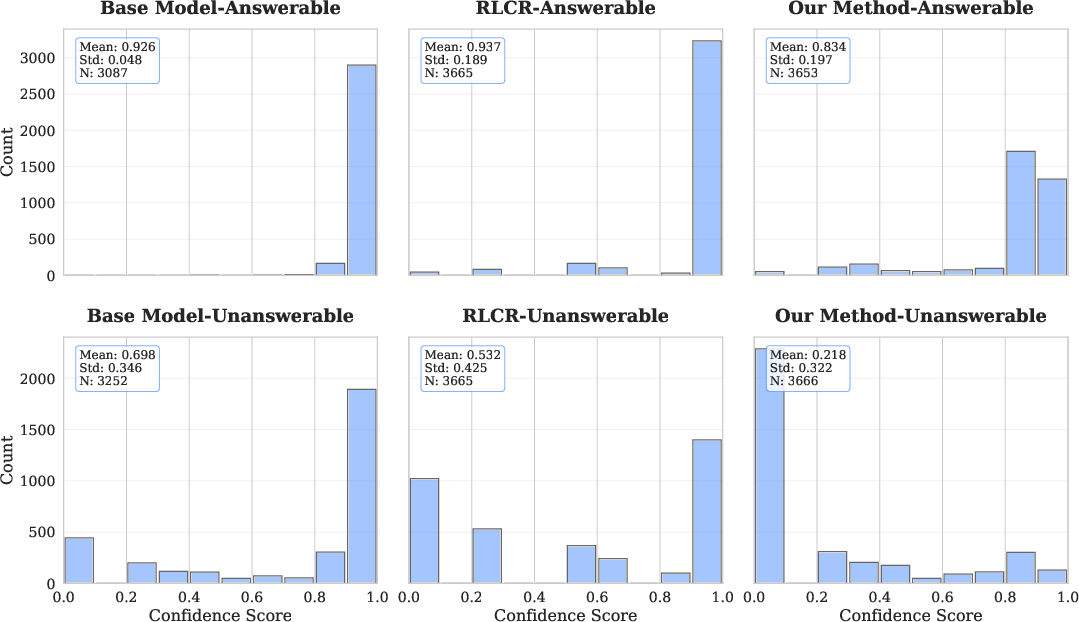
Figure 6: Confidence distributions on visually unanswerable and answerable samples show VL-Calibration uniquely shifts towards low confidence in unanswerable cases.
Training Stability and Optimization Insights
Combining KL and entropy in the visual certainty criterion is empirically critical for RL reward stability. Single-metric supervision (KL or entropy only) suffers from either explosion or collapse of entropy, as demonstrated by entropy curves during training (Figure 9), while combined estimation prevents instability.
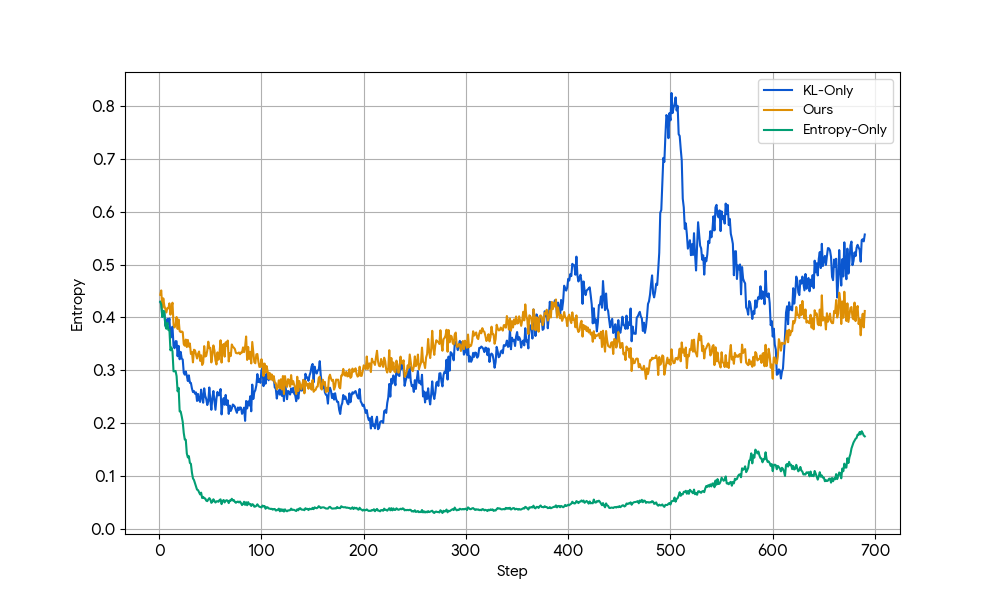
Figure 9: Training curves show entropy stability only when both KL and entropy metrics are used for visual certainty estimation.
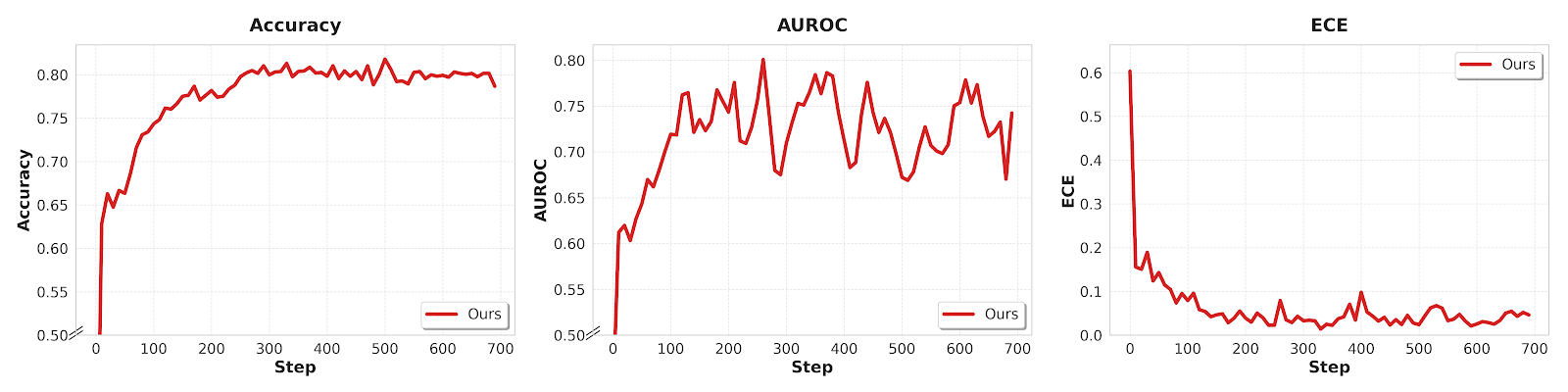
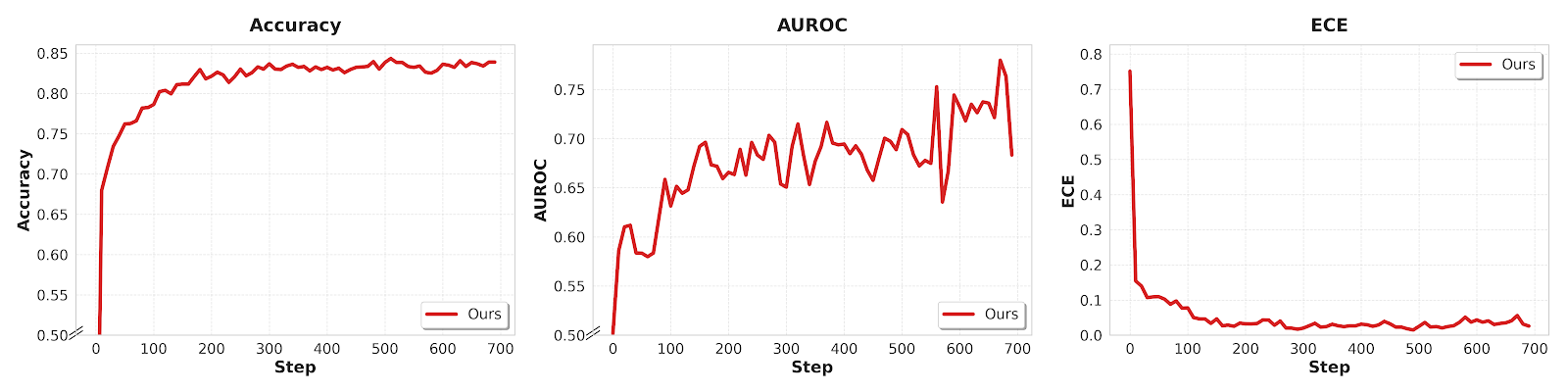
Figure 10: Training dynamics for Qwen3-VL-4B/8B reveal accelerated ECE reduction and accuracy/AUROC gains from visual certainty-based RL supervision.
Token-level advantage reweighting additionally localizes penalization to visually uncertain or hallucinated tokens, while ameliorating the impact on tokens for which the model expresses robust certainty. This dynamic, uncertainty-aware loss scaling is visualized in Figure 11, highlighting the model’s attention to both content and logical connectives.

Figure 11: Visualization of visually-uncertain tokens (darker red: higher uncertainty), confirming the efficacy of token-level reweighting for suppressing hallucination.
Practical and Theoretical Implications
The methodology has direct applicability to safety-critical LVLM deployments, providing actionable confidence diagnostics for both perception and reasoning. As the calibration is robust to distributional shift and scales to larger models, it has substantial theoretical impact, suggesting that decoupled confidence modeling is essential for accurate epistemic uncertainty quantification in multimodal settings.
Conservatively aggregating visual and reasoning scores prevents language priors from unjustifiably dominating holistic confidence, suppressing factually unsupported but confident generations. The framework is computationally competitive: visual grounding via image perturbation incurs moderate overhead, especially compared to sampling-based or external-judgment methods.
Future directions include scaling to larger model sizes, exploring additional perturbation types for visual grounding, and extending modular confidence calibration to other modalities or tasks with complex error hierarchies.
Conclusion
VL-Calibration introduces a framework for decoupled confidence calibration in LVLM reasoning, combining intrinsic visual certainty estimation and token-level advantage reweighting within an RL optimization protocol. Empirical evaluations demonstrate enhanced calibration and reasoning accuracy over strong baselines, robust generalization across tasks and architectures, and effective epistemic uncertainty localization. This paradigm sets the foundation for principled, fine-grained confidence modeling in LVLMs, essential for their reliable deployment in safety-sensitive domains.
[See (2604.09529) for details.]