- The paper introduces two novel metrics, Attention Dispersion Score and Cross-modal Grounding Consistency, for token-level detection of LVLM hallucinations.
- It utilizes patch-level analysis to capture localized attention patterns, achieving up to 90% F1 and AUC on benchmark datasets.
- The study demonstrates that integrating local grounding features enhances explainability and robustness in multimodal systems.
Fine-Grained Token Grounding for Robust Detection of LVLM Hallucinations
Introduction
The paper "Beyond the Global Scores: Fine-Grained Token Grounding as a Robust Detector of LVLM Hallucinations" (2604.04863) systematically investigates the limitations of current hallucination detection techniques in Large Vision-LLMs (LVLMs). Traditional detection methods operate primarily at a global image level, aggregating signals that may inadvertently mask the nuanced structural patterns underlying visual hallucinations. This work identifies that token-level analysis—examining how individual output tokens relate to specific image regions—provides substantially more discriminative features. The authors introduce two novel metrics for this purpose: the Attention Dispersion Score (ADS) and Cross-modal Grounding Consistency (CGC), and use these to construct a robust, explainable, and lightweight detector for hallucinated outputs.
Limitations of Global Hallucination Detectors
Current state-of-the-art approaches, such as SVAR, focus on global attention aggregation, quantifying the sum-total relationship between a candidate token and the full input image. The authors highlight that hallucinated tokens, despite lacking correspondence to any actual object, can exhibit non-trivial but scattered relevance across myriad patches. When these weak signals are globally aggregated, the hallucinated token can be misclassified as grounded, thus creating false negatives undetected by global detectors.
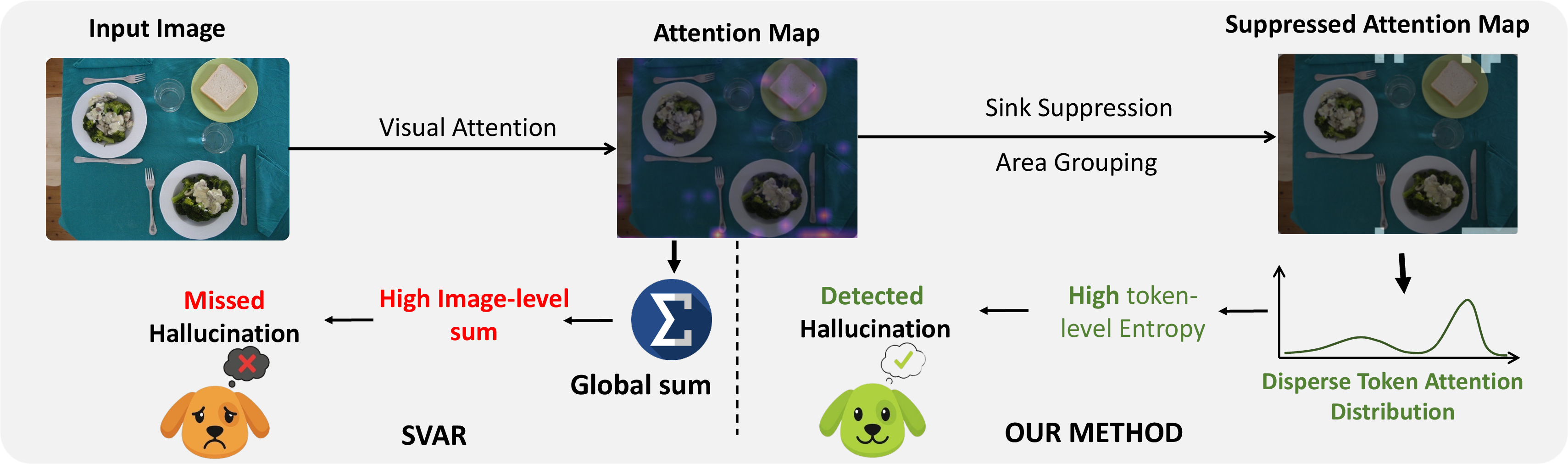
Figure 1: The pitfalls of global statistics—scattered, noisy attention accumulates to a deceptively high global relevance, confusing standard detectors, while the proposed patch-level method distinguishes local focus from dispersion.
Patch-Level, Token-wise Structural Analysis
To address these shortcomings, the authors propose a framework centered around patch-level interactions between textual tokens and image patches, systematically analyzing token grounding via two metrics:
- Attention Dispersion Score (ADS): Quantifies spatial compactness of token-level attention, with focused attention indicating grounding and dispersed patterns indicative of hallucination.
- Cross-modal Grounding Consistency (CGC): Measures the local semantic alignment between each token embedding and image region embeddings, isolating true token-grounded relationships.
This framework inspects token attention patterns and token-to-patch feature alignment throughout the model’s layers.
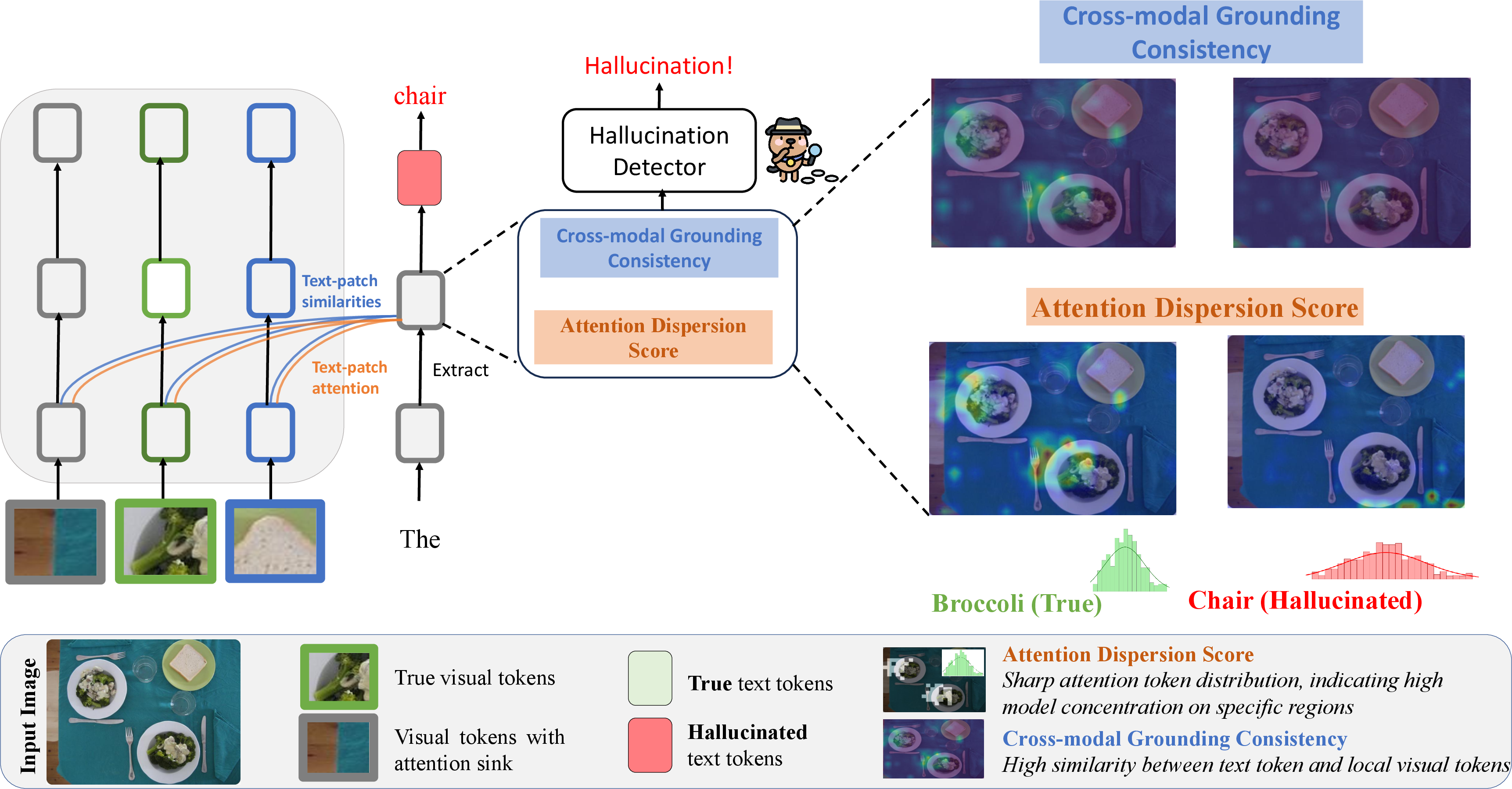
Figure 2: Overview of the token-level detection framework, featuring ADS (diffuse vs. concentrated cross-attention) and CGC (semantic similarity of tokens and patch regions) as dual detection signals.
The Attention Dispersion Score (ADS)
ADS is designed to capture how sharply a token’s attention is localized in the image. The introduced method retains the highest-activation patches in the cross-modal attention map, groups these into blobs (connected components), and suppresses spurious local maxima (attention sinks). Spatial entropy over the residual background then measures dispersion—the higher the entropy, the more diffused and less reliable the grounding.
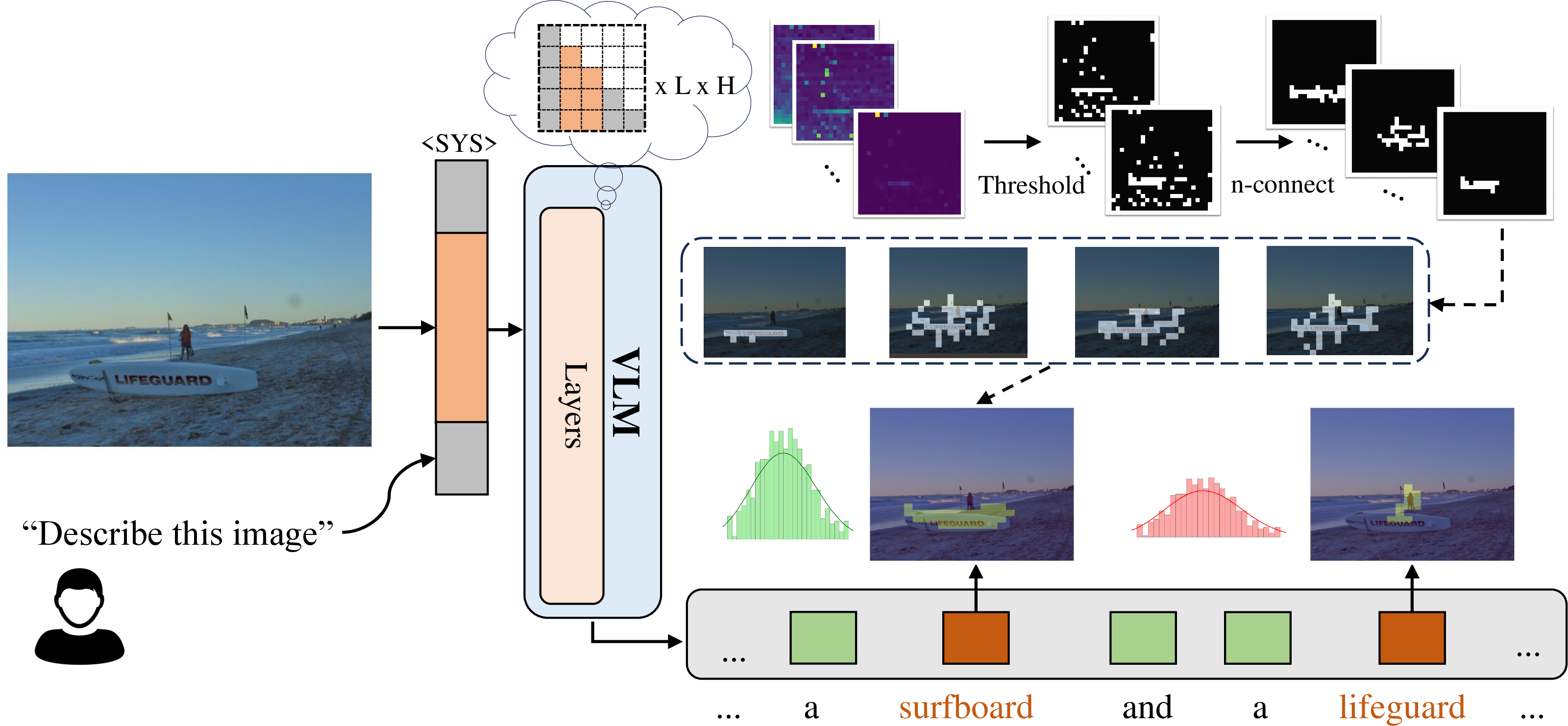
Figure 3: Illustration of ADS computation: after extracting text-to-patch attention, only salient regions are kept, attention sinks suppressed, and entropy quantified for assessment.
Empirical analysis over models such as LLaVA-1.5-7B reveals that genuine tokens display concentrated attention—corresponding to actual object locations—while hallucinated tokens spread attention diffusely.

Figure 4: Visual comparison of cross-modal attention maps for true vs. hallucinated tokens—focused versus scattered across transformer layers.
Layer-wise entropy plots further show that lower and mid-level layers offer the sharpest separation.

Figure 5: Layer-wise attention entropy for true vs. hallucinated tokens, demonstrating strong class separation, particularly in early/mid transformer layers.
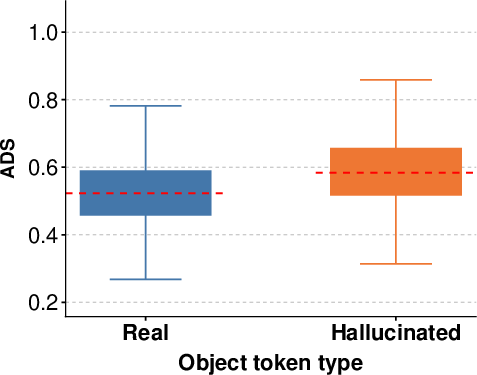
Figure 6: Distribution of attention dispersion scores in the intermediate layers of LLaVA-1.5-7B, indicating a clear margin between true and hallucinated tokens.
Cross-Modal Grounding Consistency (CGC)
CGC is computed as the maximum (or mean top-k) cosine similarity between each token’s embedding and image patch embeddings at each transformer layer. Grounded tokens feature sharp alignment peaks over the relevant patches, while hallucinated tokens typically lack any such peaks, yielding consistently low alignment.

Figure 7: Layer-wise CGC for true vs. hallucinated tokens, with strong separation observed in early/mid layers.
A qualitative inspection of patch-level similarity heatmaps illustrates this difference:

Figure 8: CGC heatmaps—true tokens align to localized structures, hallucinated tokens demonstrate low/no alignment over the image.
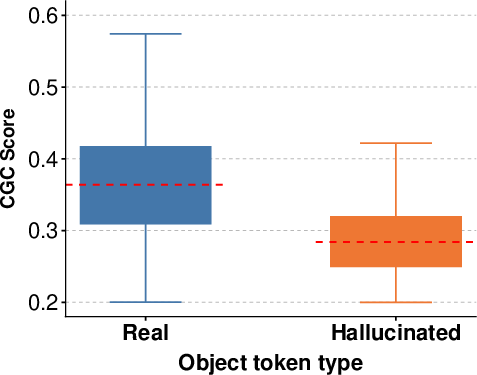
Figure 9: Distribution of top-5% patch similarities for true and hallucinated tokens.
Experimental results validate that classifiers using ADS and CGC as layerwise features consistently outperform prior art—including MetaToken, HalLoc, DHCP, and SVAR—on both MS COCO and POPE datasets. In extensive benchmarks, the combined ADS+CGC detector achieves up to 90% F1 and AUC on diverse LVLM backbones.
Key findings include:
- ADS as a signal: Per-model F1 scores up to 0.77 for attention entropy alone.
- CGC as a signal: CGC-based classifiers reach F1 scores up to 0.81.
- Combined approach: Integrating both yields additive improvements, especially for challenging, precision-critical tasks.
Ablation studies further show that mid-layer representations are most informative, a result that aligns with the model’s cross-modal fusion behavior; top layers are dominated by generative language priors, which attenuate cross-modal grounding.
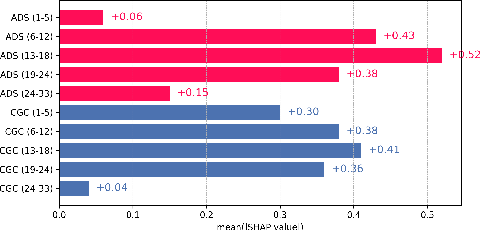
Figure 10: Mean SHAP values for ADS and CGC layerwise features, confirming the diagnostic value of mid-level representations.
Theoretical and Practical Implications
These findings provide robust evidence that attention-driven dispersion and token-patch semantic correspondences are key internal signals for hallucination detection in LVLMs. The results substantiate that many hallucinations stem from excessive reliance on language priors, not deficiencies in visual encoding. Practically, the proposed approach substantially enhances explainability, is compatible with patch-wise visualizations, and is lightweight—requiring no external pipelines or retraining. It also generalizes across backbones without model-specific tuning.
The proposed metrics’ effectiveness is further demonstrated through their combination with SVAR, yielding additional performance gains, strengthening the argument for integrating local-structure-sensitive features into future LVLM hallucination detection and mitigation systems.
Future Directions
This structural, token-level analysis framework could be extended in several directions:
- Dynamic calibration of detection thresholds across layers and model variants.
- Integration with generative training objectives for hallucination mitigation.
- Applicability to textual hallucination detection in pure LLMs via analogous attention and grounding statistics.
- Per-object/phrase attribution in complex, multi-object scenes and robust evaluation under adversarial scenarios.
Conclusion
This work establishes fine-grained patch-level analysis—specifically, token-level attention entropy (ADS) and local grounding consistency (CGC)—as essential, diagnostic, and robust signals for detecting hallucinations in LVLM outputs. The research demonstrates that holistic, whole-image metrics are insufficient for high-precision hallucination detection, especially in highly compositional scenes. By systematically characterizing true and hallucinated object tokens at a structural level, the framework sets a new state-of-the-art for hallucination detection, with clear theoretical underpinnings and practical benefits for model auditing and safety assurance in real-world multimodal systems.