- The paper introduces VeriMap, a framework that empirically maps when self-verification in medical VQA produces a 'verification mirage' due to generator-verifier coupling.
- It decomposes verifier performance into discrimination capability and agreement bias, exposing systematic over-acceptance in knowledge-intensive tasks.
- Mitigation efforts, including cross-verification and scaling, partially reduce errors but fail to fully eliminate safety risks in clinical reasoning.
Evaluating the Reliability Boundary of Self-Verification in Medical Visual Question Answering
Introduction and Motivation
Self-verification—the practice of re-invoking a VLM with identical parameters and a new context to assess its own answer—has emerged as a prevalent safety mechanism in medical VQA. Its appeal lies in its simplicity and lack of external requirements, making it a default post-processing step in many applied VLM pipelines for medicine. However, this paper establishes that the trustworthiness of self-verification is frequently overestimated, especially in high-stakes clinical scenarios. The key insight is that self-verification does not offer an independent error signal, since the verifier and generator inevitably share model capacity, training data, and limitations in both clinical knowledge and visual grounding.
The authors introduce VeriMap, a diagnostic framework to empirically map and quantify when self-verification serves as a reliable safety check versus when it produces a verification mirage—a regime of high apparent accuracy that actually disguises systematic over-acceptance and failure to detect generator errors. This framework provides a rigorous way to decompose and analyze verifier behavior across a spectrum of medical VQA task types and model configurations.
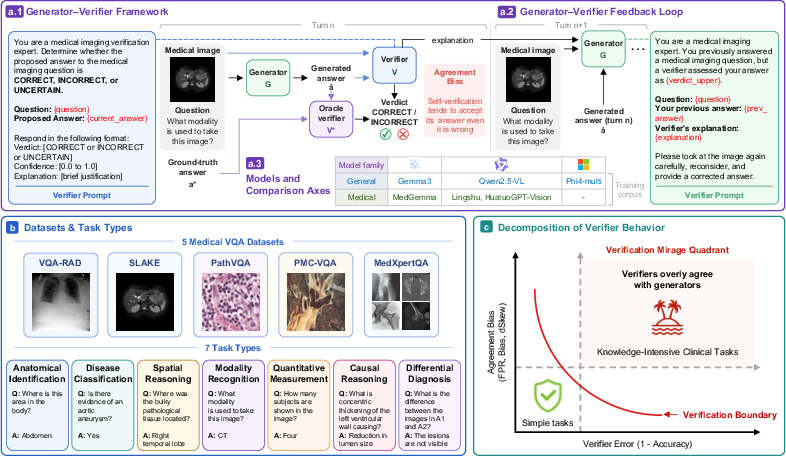
Figure 1: Overall study pipeline. The generator--verifier setup is evaluated for both single-turn and multi-turn verification across diverse medical VQA datasets, tasks, and model families. VeriMap decomposes verifier behavior into discrimination capability and agreement bias, exposing the verification mirage.
Methodology and VeriMap Framework
The VeriMap protocol comprises several innovations over prior work:
- Task-Type Decomposition: Medical VQA instances are stratified along a taxonomy from perceptual to knowledge-intensive clinical tasks (modality recognition, anatomical ID, spatial localization, disease classification, differential diagnosis, causal reasoning, quantitative measurement), allowing for fine-grained evaluation of verifier performance.
- Two-Axis Metric Decomposition: Rather than evaluating verifier reliability with a single scalar accuracy, VeriMap distinguishes discrimination capability (verifier's ability to distinguish correct/wrong answers) and agreement bias (tendency to endorse generator output regardless of correctness), using metrics such as FPR, Bias, and dSkew.
- Generator-Verifier Coupling Analysis: Generalized mixed-effects modeling quantifies how verifier errors and biases covary with generator performance, exposing systematic dependencies rather than treating generator and verifier as independent.
The study evaluates six open-weight VLMs (spanning both generalist and medical-specialist architectures) on five diverse medical VQA datasets, covering seven task types.
Empirical Findings: The Verification Mirage Regime
Occupancy of the Discrimination–Bias Plane
The vast majority of task–model pairs cluster in the verification mirage quadrant: high verifier error coupled with strong agreement bias. This is especially pronounced for knowledge-intensive tasks such as differential diagnosis, disease classification, and causal reasoning, where FPR often approaches 100% and verifier accuracy falls below 40%. The only exceptions, with verifier performance outside the mirage, are structured tasks like quantitative measurement, which admit more reliable checking.
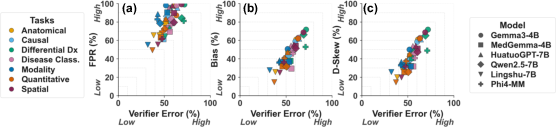
Figure 2: Verification boundary in the discrimination-bias plane; most task–model instances occupy the mirage quadrant (high error, high bias), particularly for knowledge-intensive tasks.
A joint rise in verifier error and agreement bias is observed, suggesting that as generator performance degrades, the verifier not only becomes less accurate but also more likely to falsely accept incorrect answers rather than issuing rejections.
Strong Generator-Verifier Error Coupling
Mixed-effects modeling demonstrates that verifier errors are strongly coupled to generator errors, with generator mistakes leading to up to 57-fold increases in the odds of verifier failure. This coupling intensifies for models with weaker underlying capacities and for more knowledge-intensive tasks. Importantly, this negates the assumption that self-verification supplies an independent audit signal.
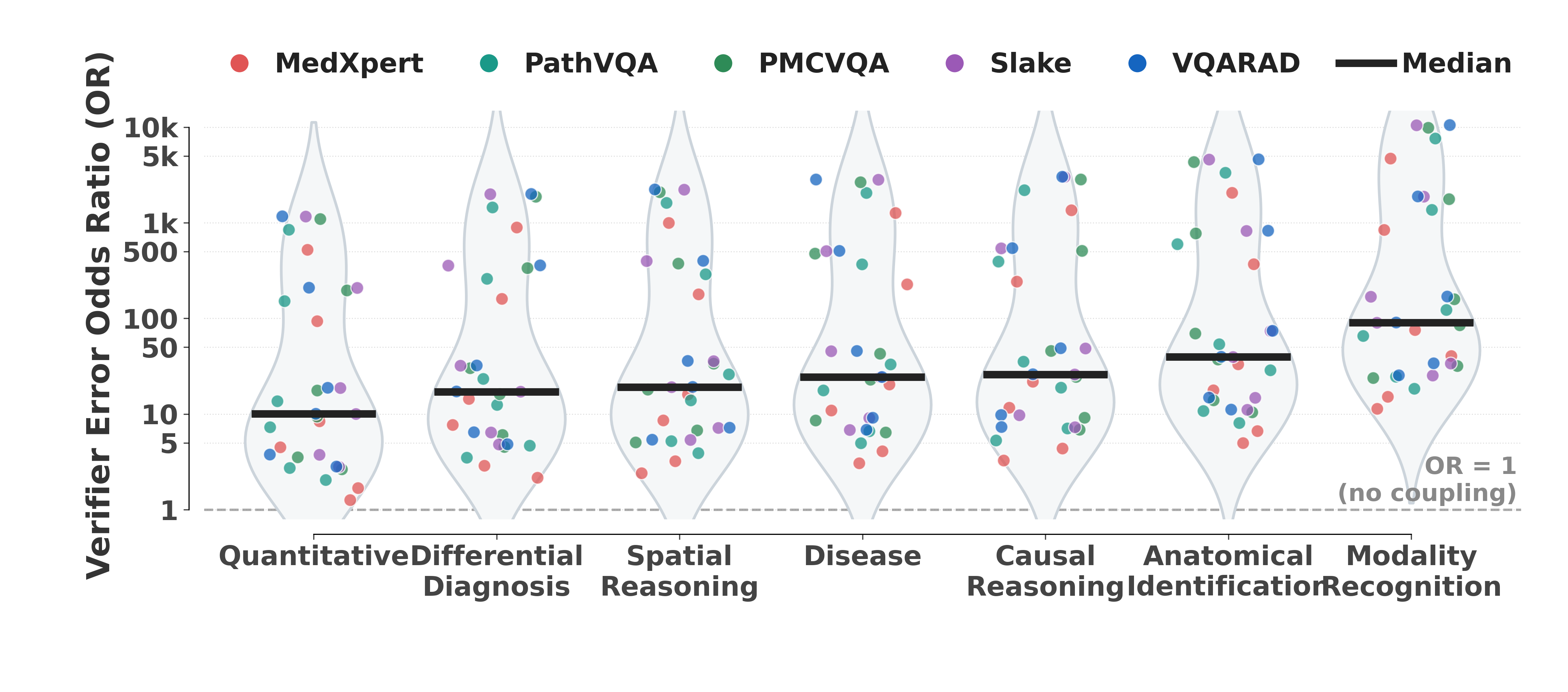
Figure 3: Generator-verifier error coupling by task—odds ratios >1 indicate that verifier errors are significantly more probable when the generator is wrong.
Further, as generator error rates increase, agreement bias metrics (FPR, Bias, dSkew) also rise, implying that harder generation tasks induce verifiers to become more permissive rather than more conservative.
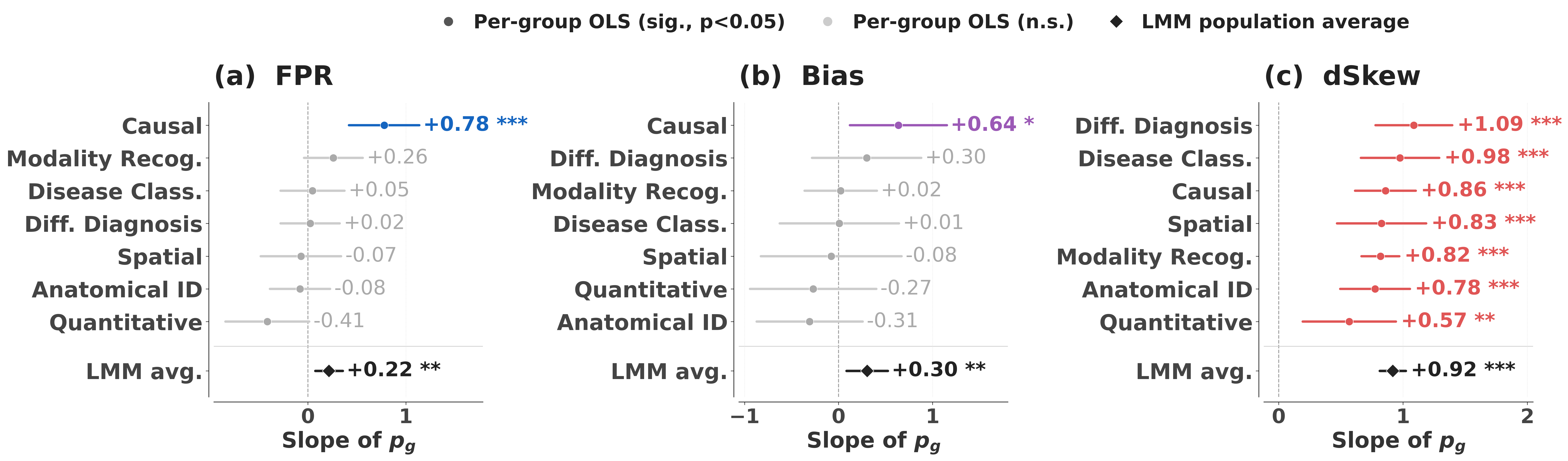
Figure 4: OLS slopes showing that agreement bias metrics increase with generator error rate, notably for clinical reasoning tasks.
Mechanism: The Lazy Verifier Effect
Visual grounding analysis reveals that verifiers attend to the image significantly less than generators, especially in cases where they mistakenly validate incorrect answers. This is quantified via image saliency fraction and mean gradient activation: across all task types, verifier saliency is systematically lower, and the gap is largest in tasks that most demand visual re-grounding.
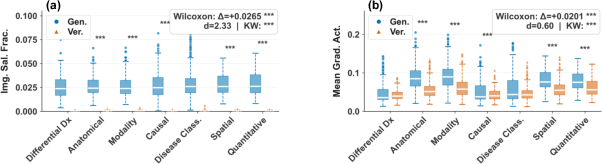
Figure 5: Verifier–generator visual grounding gap—verifiers exhibit significantly weaker image attention compared to generators across all tasks.
Qualitative evidence confirms that when generators produce erroneous outputs, the paired verifier rarely utilizes the visual evidence, frequently acting as a plausibility checker over the textual answer alone.
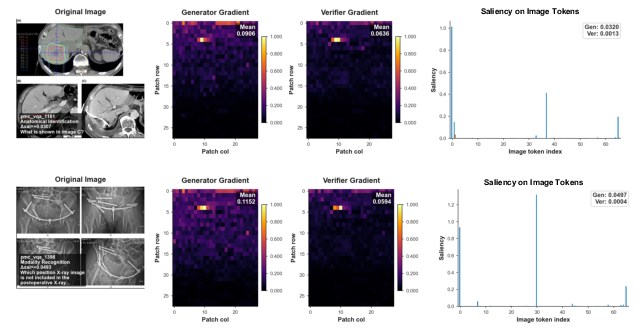
Figure 6: Qualitative demonstration of the lazy verifier: visual grounding is nearly absent in verifier gradient maps compared to generators, consistent with permissive, non-evidence-based decisions.
Mitigation: Cross-Verification and Scaling
Routing the verification step to a model from a different family or with divergent pretraining (cross-verification) consistently reduces agreement bias and verifier error, especially in the hardest tasks. However, while gains are significant (particularly in reducing FPR by up to 20%), the verification mirage is diminished but not eliminated; reliable negative signal on knowledge-intensive tasks remains unattainable solely via cross-model checking.

Figure 7: Cross-verification consistently reduces verifier error and bias, especially in complex reasoning tasks, but the effect magnitude is limited.
Domain-expert or larger verifiers provide incremental FPR reductions, but for difficult clinical reasoning problems, false acceptance rates remain unacceptably high regardless of domain adaptation or scaling.
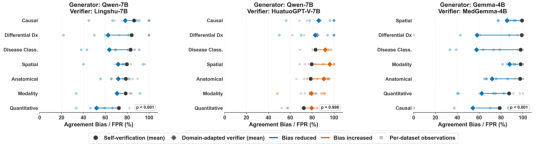
Figure 8: Domain-adapted verifiers reduce FPR, but every reasoning type retains substantial agreement bias, indicating incomplete mitigation.
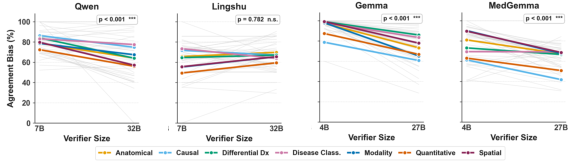
Figure 9: Scaling to larger verifiers within the same model family lowers false acceptance unevenly, with persistent high FPRs for knowledge-intensive tasks.
Negative Result: Multi-Turn Verification Amplifies Failure
Using self-verification in a multi-turn, feedback-driven setting (actor–verifier loops) causes errors to accumulate, rather than self-correct. Wrong answers are overwhelmingly "locked in" by false verifier validation upon repeated rounds, and cumulative agreement bias rises further with each loop iteration. Correction rates for initially wrong answers are negligible (often <4%), especially in tasks at the boundary of the verification mirage.

Figure 10: Multi-turn verifier–generator loops predominantly lock in wrong answers due to persisting false positive verification.
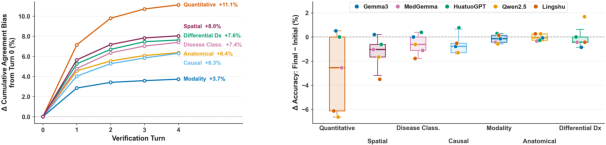
Figure 11: Cumulative agreement bias and generator underperformance increase proportionally in multi-turn feedback loops, reflecting system-level degradation.
Implications and Future Directions
These findings have substantial ramifications for the deployment of self-verification as a safety layer in medical VQA and, more broadly, for any settings where VLMs or LLMs are expected to self-audit in high-stakes environments.
- Conditional Utility: Self-verification offers utility only for tasks where generator and verifier capacities are decoupled (structured, perceptual, or low-complexity problems). For true clinical reasoning, it supplies false reassurance.
- Explicit Reliability Mapping Needed: Any deployment in clinical applications should explicitly report and act on both discrimination error and agreement bias across the full space of expected question types.
- Necessity of Independent Verification: Reliable safety checks require external or orthogonal verification sources—diverse model families, retrieval-based or knowledge-augmented approaches, or independent human-in-the-loop auditing.
- Research Directions: Improving verifier independence, enhancing visual grounding, and designing error detection strategies robust to generator-verifier coupling are critical directions. Diagnostic tools like VeriMap should be extended and standardized as audit modules in medical AI pipelines.
Conclusion
This paper elucidates the limits of self-verification in medical VQA, formally characterizing the regime where it yields a verification mirage rather than reliable error correction. Through comprehensive, task-stratified, and methodologically rigorous analysis, the authors demonstrate that self-verification is fundamentally unreliable for knowledge-intensive clinical tasks due to strong generator-verifier coupling and a pervasive lazy verifier effect. While cross-verification or scaling can partially alleviate agreement bias, no evaluated system achieves robust safety signaling for complex reasoning questions. Effective deployment of VLMs in clinical medicine must thus move beyond self-verification and invest in systematically mapping, auditing, and augmenting verification boundaries.
Reference: "Verification Mirage: Mapping the Reliability Boundary of Self-Verification in Medical VQA" (2605.10850)