- The paper introduces a training-free framework that leverages a Similarity Response Quality Scoring Module to distinguish true from hallucinated segmentations.
- It combines quantitative metrics with a GPT-4o based qualitative assessment to achieve over 85% accuracy in verifying query validity.
- The approach improves clinical safety and model generalizability by integrating verification without requiring extra retraining.
MedVeriSeg: A Training-Free Verification Framework for MLLM-Based Medical Segmentation
Introduction
The proliferation of Multimodal LLMs (MLLMs) such as LISA, LLaVA-Med, and their derivatives has significantly advanced text-prompted medical image segmentation. These systems achieve high segmentation accuracy and enhanced interactivity by leveraging large-scale medical data, sophisticated model architectures, and reasoning capabilities. However, a critical practical limitation persists: LISA-like pipelines uniformly generate segmentation masks, even when the queried entity is not present in the image, frequently resulting in "hallucinated" segmentations. This undermines both clinical reliability and educational utility, as such erroneous outputs can misguide students or practitioners and lead to inappropriate downstream decisions.
The "MedVeriSeg: Teaching MLLM-Based Medical Segmentation Models to Verify Query Validity Without Extra Training" (2604.10242) paper proposes a rigorous training-free verification mechanism. MedVeriSeg enables existing LISA-like frameworks to automatically verify whether a queried anatomical or pathological entity is present in the input prior to mask generation, refusing hallucinated segmentation requests and providing reasoned feedback.
Observations and Framework Overview
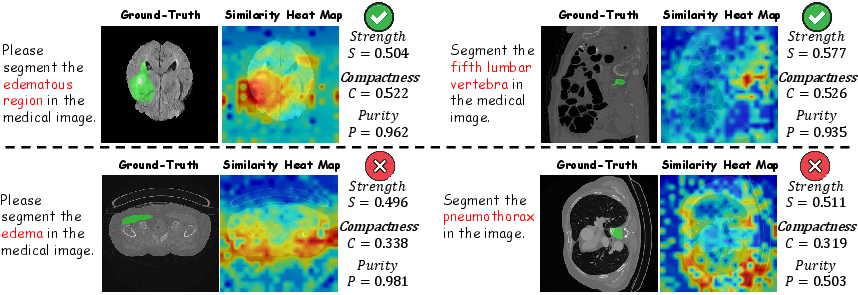
The hypothesis underlying MedVeriSeg is that genuine and hallucinated segmentations induce distinct activation patterns in the similarity heatmaps produced by the MLLM backbones. Specifically, the similarity map between the [SEG] token's hidden state and the final visual embeddings exhibits spatially compact and high-intensity activations over the queried entity for real targets. When the target is absent, activations are diffuse, weak, or erratic.
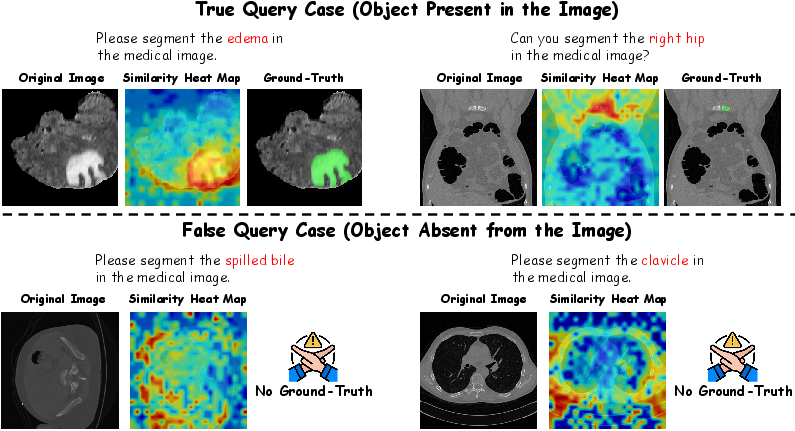
Figure 1: Distribution patterns of similarity heat maps under true-query and false-query cases; real targets exhibit compact high responses, while false queries yield scattered activations.
Based on this observation, MedVeriSeg is designed as a wrapper atop any LISA-like pipeline, augmenting it with a verification head that performs both quantitative and qualitative analysis of the similarity heatmap prior to mask generation.
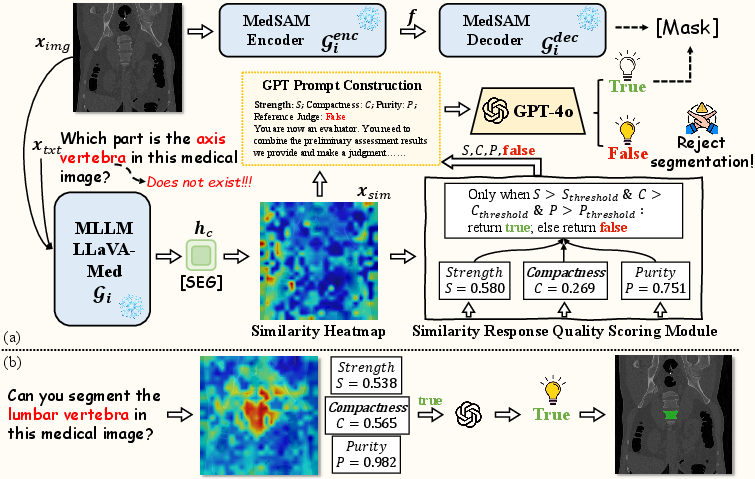
Figure 2: Overview of the MedVeriSeg framework, delineating the inference pipelines for both false-query and true-query cases.
Similarity Response Quality Scoring Module
The core of MedVeriSeg's quantitative analysis is the Similarity Response Quality Scoring Module (SRQSM). This is a lightweight, non-parametric component that assesses the similarity map M∈RH×W through three orthogonal criteria:
- Response Strength (S): Quantifies whether the top-k activations on the map are significantly salient relative to the background.
- Spatial Compactness (C): Measures whether high-score activations are localized around a central region, as opposed to being widely scattered.
- Region Purity (P): Computes the ratio of "activation energy" concentrated in the largest connected component versus all active regions, penalizing fragmented or noisy responses.
Only if all three scores surpass empirically determined thresholds does the framework classify the query as targeting a truly present entity; otherwise, it is rejected as presumptively absent.
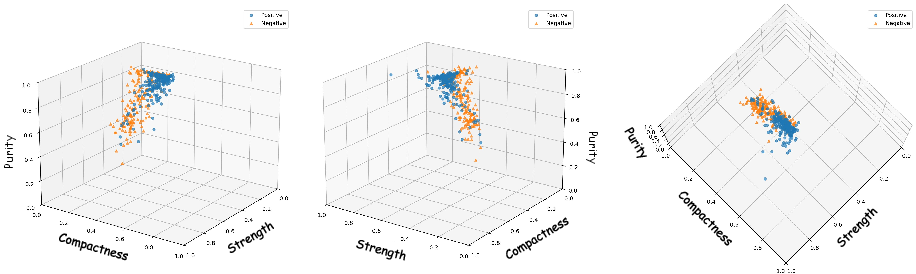
Figure 3: Three-dimensional distribution of positive and negative examples across the S, C, and P axes, showing their separability.
Qualitative Visual Assessment via GPT-4o
While the SRQSM provides robust, interpretable feature-based assessments, certain ambiguity cases (e.g., small and visually atypical lesions) may escape strict quantitative thresholds. To address this, MedVeriSeg incorporates a GPT-4o-based module, employing a system prompt that fuses the SRQSM outputs with a high-level qualitative interpretation of the similarity heatmap. If GPT-4o is uncertain, it defaults to the SRQSM; otherwise, it adjudicates based on macro-level cues and known heatmap distribution priors. This hybrid reasoning increases robustness in edge cases.
Experimental Results
Experiments use a carefully constructed benchmark derived from the SA-Med2D-20M dataset, comprising both authentic positive queries and synthetic negative queries (labels replaced with non-existent targets). Evaluation focuses solely on the existence determination task (not segmentation quality), using the Accuracy (Acc) metric for both positive (true) and negative (false) query identification.
Additionally, experiments on MedPLIB, an alternative open-source LISA-like model, confirm the generalization capability of MedVeriSeg (Acc 77.1 on positives vs. 80.4 on negatives for existence identification), supporting its cross-architecture applicability.
Theoretical and Practical Implications
MedVeriSeg's architecture- and training-free verification approach offers several substantive advantages:
- Practical Robustness: Integrating MedVeriSeg into clinical MLLM segmentation workflows decreases risk of misdiagnosis due to mask hallucination and saves computation by suppressing unnecessary decoder invocations.
- Domain Generalizability: The technique exploits model-internal feature dynamics rather than retraining, enabling rapid adaptation across both open- and closed-source LISA-like systems in research and deployment settings.
- Augmented Explainability: The selection of interpretable response criteria (intensity, compactness, and purity) and hybrid visual-language assessment enhances transparency, facilitating debugging and regulatory acceptance.
- No Retraining Required: Compared to negative sampling or retraining approaches, MedVeriSeg eliminates dataset reengineering and risk of overfitting, offering instant integration.
On a theoretical level, the method characterizes a critical failure mode in vision-language reasoning and demonstrates a general framework for exploiting intermediate feature space statistics for post hoc verification in MLLM applications. MedVeriSeg can be extended to adjacent domains (e.g., radiology, pathology, multi-round reasoning), potentially prompting further research into verification heads for text-guided structured prediction.
Future Directions
Anticipated research extensions include:
- Improved Negative Query Benchmarks: Larger and compositional datasets for hallucination/disambiguation would foster standardized evaluation.
- End-to-End Model Calibration: Integrating similarity-based verification as an auxiliary objective during MLLM training may further augment reliability.
- Generalization Beyond Medical Imaging: Applying the verification framework to text-to-image, open-vocabulary detection, and compositional reasoning tasks exploiting token-feature similarity metrics.
- Model-Agnostic Explainability: The explainable scoring paradigm can potentially inform model interpretability tooling in broader LLM-based systems.
Conclusion
MedVeriSeg presents an efficient, non-invasive solution to the hallucinated segmentation problem plaguing LISA-like medical MLLM pipelines. By systematically leveraging feature similarity distributions and a hybrid decision mechanism, it significantly reduces the prevalence of false-positive responses to absent target queries, thus enhancing both clinical reliability and computational efficiency. The framework is readily adaptable across architectures and LLMs, and lays groundwork for broader post hoc verification strategies in multimodal reasoning systems.
(2604.10242)