- The paper demonstrates that iterative self-reflective reasoning yields mixed accuracy improvements in medical QA across diverse datasets.
- It benchmarks standard chain-of-thought prompting against self-reflective approaches using GPT-4 variants on MedQA, HeadQA, and PubMedQA datasets.
- Findings indicate that additional self-reflection steps do not consistently correct errors, challenging reliance on internal iteration in safety-critical settings.
Self-Reflective Reasoning in Medical Multiple-Choice Question Answering: An Empirical Study
Introduction
This study systematically investigates the practical value of self-reflective reasoning in LLMs applied to medical multiple-choice question answering (QA). Instead of proposing a novel method, the work benchmarks the impact of iterative self-reflective prompting—where an LLM reviews and possibly corrects its own chain-of-thought (CoT) reasoning—against standard CoT prompting across MedQA (USMLE), HeadQA, and PubMedQA. The motivation is to empirically establish whether self-reflection consistently leads to improved reliability, or whether it introduces further error modes, given the safety-critical nature of medical QA.
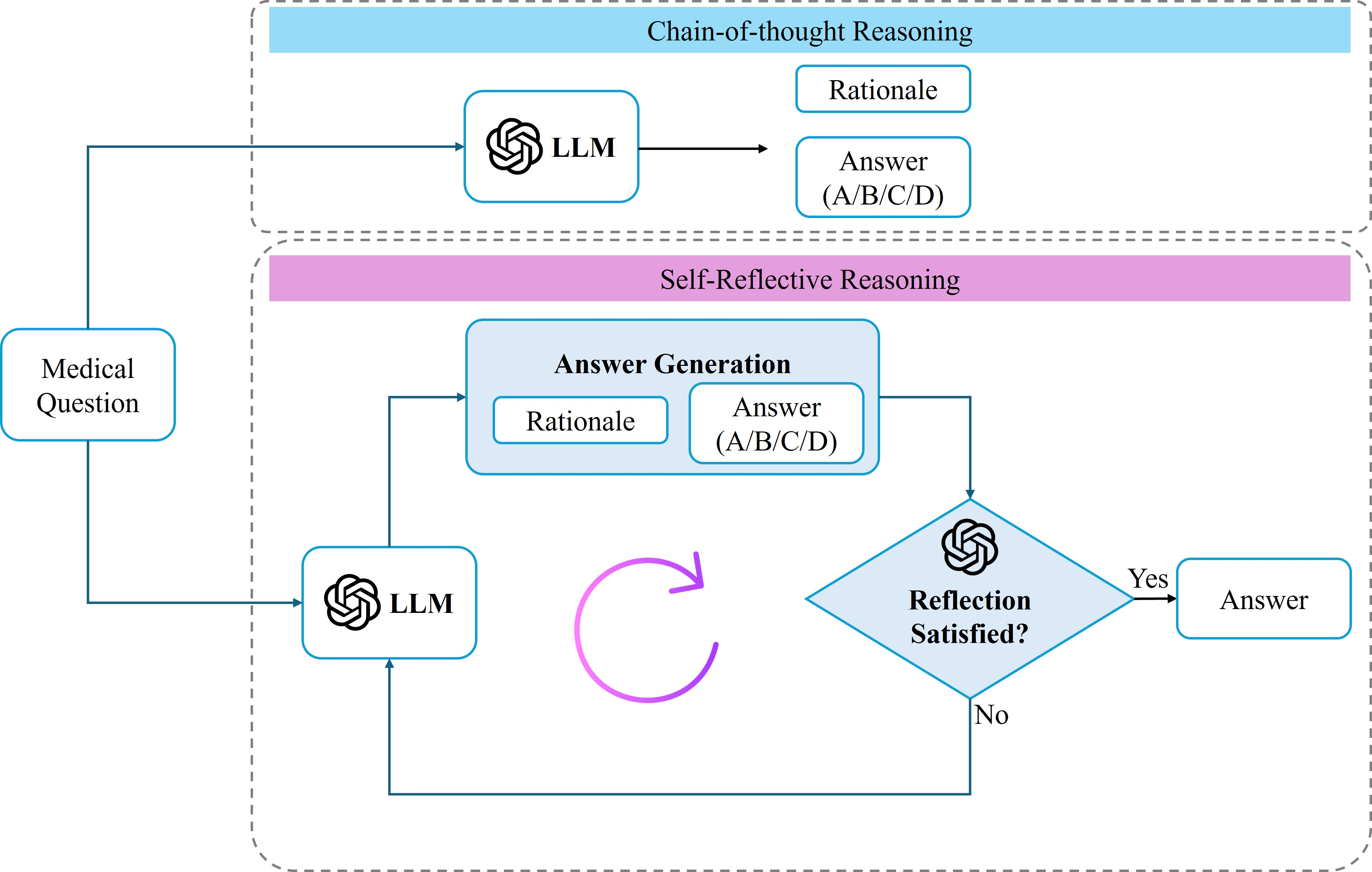
Figure 1: Overview of the experimental framework contrasting standard CoT prompting (top) with iterative self-reflective reasoning (bottom) for medical multiple-choice QA.
Experimental Protocol
The experimental approach is based on two primary prompting strategies:
- Chain-of-Thought Baseline: The model generates an explicit, step-by-step clinical rationale followed by a final multiple-choice answer.
- Self-Reflective Reasoning: Starting from the CoT answer, the LLM is prompted to act as a critical reviewer, iteratively detecting and revising errors in its own reasoning and final answer over up to 10 reflection steps.
The models used are OpenAI GPT-4o and GPT-4o-mini, treated as inference-only black boxes. Prompts are carefully designed to control for format, as exemplified for MedQA:

Figure 2: Prompt structure for MedQA, illustrating the sequential rationale/answer requirement and iterative self-reflection instruction.
Datasets were chosen for diversity in difficulty and domain: MedQA (professional medical exams), HeadQA (Spanish specialty exams), and PubMedQA (biomedical literature-based QA).
Results and Quantitative Analysis
Accuracy Comparison
Across all three benchmarks, self-reflective reasoning does not yield uniform improvements. On MedQA, modest gains are observed: GPT-4o achieves an increase from 87.80% (CoT) to 88.80% (self-reflective), and GPT-4o-mini improves from 74.80% to 76.00%. However, on HeadQA, accuracy for GPT-4o slightly decreases (91.39% to 90.57%), and is unchanged for GPT-4o-mini. Notably, on PubMedQA, self-reflection degrades performance for both models (GPT-4o: 70.80% to 69.00%, GPT-4o-mini: 71.60% to 69.60%). These outcomes starkly contradict widespread claims of self-reflective prompting as a performance panacea.
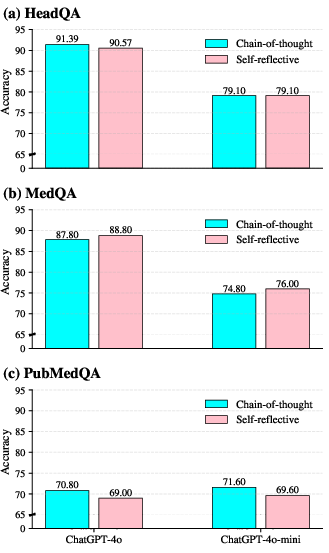
Figure 3: Comparative accuracy of CoT vs. self-reflective reasoning for various datasets and models.
Dynamics Across Reflection Steps
Performance as a function of cumulative reflection steps shows that increased iterative reasoning does not guarantee monotonic improvement. For all datasets, accuracy typically stabilizes or fluctuates after the first one or two steps, with extended reflection sometimes introducing instability, especially for the smaller model.
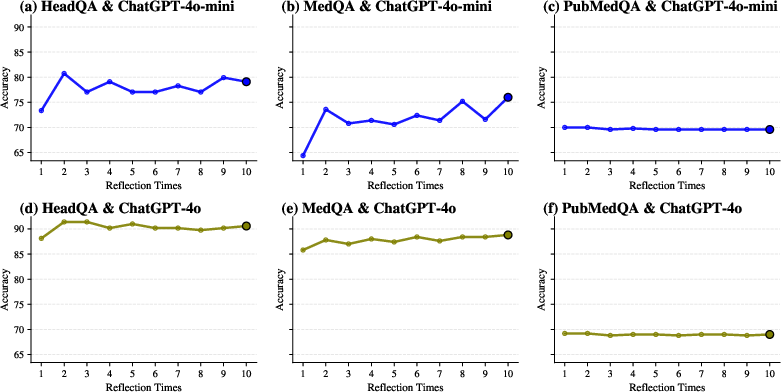
Figure 4: Evolution of accuracy with the number of self-reflection steps per dataset and model.
Reflection Depth and Model Decisiveness
A large majority of samples terminate reflection after 0–1 steps, especially with the larger GPT-4o model—over 85% of instances across datasets require no further revision. GPT-4o-mini is more prone to additional rounds of reflection, especially on more complex datasets like MedQA, but deep iterative revision (approaching 10 steps) remains rare. This suggests that LLMs are generally decisive in their initial reasoning or reluctant to overhaul their own decisions.
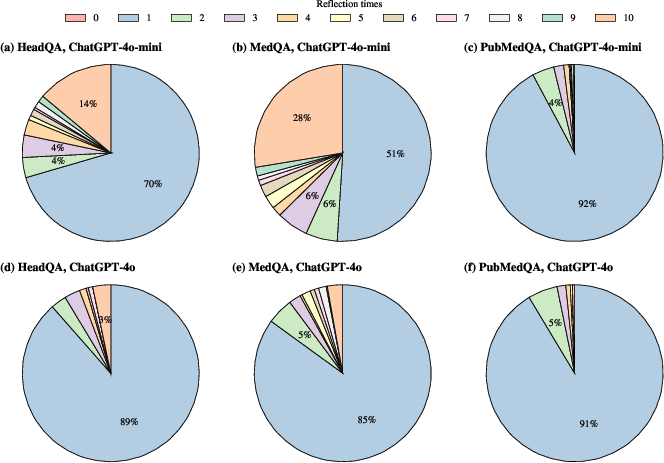
Figure 5: Distribution of the number of self-reflection steps required to reach satisfaction for each model and dataset.
The average number of reflection steps is consistently lower for GPT-4o versus GPT-4o-mini, with MedQA prompting the deepest reflection, indicative of its complexity.
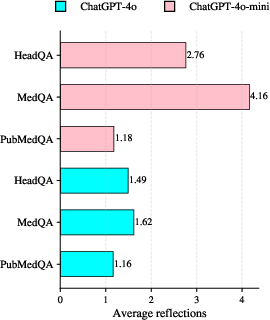
Figure 6: Mean self-reflection steps used across datasets and model scales.
Discussion
The empirical data demonstrate that self-reflective prompting does not operate as a universal error-correction mechanism in medical QA. Its efficacy is uncorrelated with increases in reasoning transparency and is highly contingent on both the underlying model and dataset. These findings directly challenge the assumption that internal iterative review reliably remediates LLM reasoning failures in high-stakes scenarios.
Several observations emerge:
- Dataset Sensitivity: Whereas MedQA's complex clinical reasoning occasionally benefits from reflection, datasets with highly structured questions (HeadQA) or evidence-centric tasks (PubMedQA) see negligible or negative effects, likely due to error origins in information retrieval or initial misinterpretation rather than logical oversight correctable by iteration.
- Confirmation Bias: Reflection often serves to rationalize prior outputs rather than correct them, akin to a confirmation bias loop, possibly increasing risk by making erroneous answers appear more justifiable.
- Model Scaling Effects: More capable models (GPT-4o) display higher initial reasoning robustness, engaging less in self-reflection and less prone to error oscillations. Smaller models are more variable but do not realize strong accuracy gains from increased iterative review.
These results highlight a practical gap between interpretability (reasoning trace visibility) and correctness; increased transparency does not equate to improved reliability.
Implications and Future Directions
Practically, reliance on iterative self-reflection for improved model trustworthiness in clinical applications is ill-advised. For medical and safety-critical domains, the incorporation of external evidence—through retrieval-augmentation, explicit verification, or uncertainty quantification—should be prioritized over solely relying on an LLM’s internal review. Future investigations should integrate self-reflective methods with such external mechanisms, intervene at granular reasoning steps, and extend analysis to open-ended clinical reasoning and real-world deployable systems.
Conclusion
This study provides a comprehensive, empirically grounded assessment of self-reflective reasoning in LLMs for medical QA. Iterative self-reflection does not consistently improve performance and is often dataset- and model-dependent; increasing the number of reflection steps does not guarantee error correction. These findings refute claims that self-reflective prompting is a standalone solution for improving the reliability or safety of medical LLMs. Instead, it should be leveraged as a tool for reasoning analysis, with robust error-mitigation requiring integration with external verification and grounding mechanisms.
(2604.00261)

