- The paper presents a training-free, agentic system that utilizes anatomical indexing and source-verifiable knowledge for accurate crop disease diagnosis.
- It details a scalable pipeline that curates the largest multi-organ crop disease image dataset with structured symptom metadata and expert audits.
- Experimental results demonstrate significant accuracy gains, with up to a 16.2 percentage point improvement through effective knowledge integration and reference guidance.
SAGE: Scalable Agentic Grounded Evaluation for Crop Disease Diagnosis
Motivation and Contributions
Crop disease recognition presents unique challenges due to the scarcity and heterogeneity of labeled images, class imbalance, and the absence of structured, source-verifiable symptom knowledge. Classical deep learning architectures and vision-LLMs (VLMs) have demonstrated strong performance on narrow, controlled benchmarks, yet generalization across crop species, pathogens, and variable field conditions remains problematic. The lack of explainability and the inability to ground predictions in authoritative domain knowledge further limit practical adoption.
The "SAGE: Scalable Agentic Grounded Evaluation for Crop Disease Diagnosis" (2605.09768) addresses these gaps through a multi-pronged approach:
- Curation of the largest plant disease image–symptom dataset to date (839K images, 335 crops, 1,251 disease classes), integrating multi-organ coverage and source-grounded symptom metadata.
- Automated pipeline for constructing disease registries with per-claim provenance, linking structured symptom descriptions to verbatim web quotes with field-level expert audit.
- An agentic, training-free diagnostic system that operates via sequential visual reasoning, utilizing anatomical indexing and symptom knowledge to guide structured hypothesis narrowing and reference-based comparison with auditable reasoning traces.
The framework enables rapid extensibility to new crops and diseases, eschewing retraining, and delivers consistent accuracy improvements via knowledge base (KB) integration.
Dataset Construction and Knowledge Base
The SAGE dataset is assembled from diverse source categories, including:
- Standard benchmarks (PlantVillage, PlantDoc, LeafNet, PlantWild).
- Recent large-scale vision-language datasets.
- Expert-curated datasets for critical crops with multi-organ labeling.
- Community-contributed sets addressing underrepresented crops.
Images undergo deduplication and anatomical tagging. Mislabeling, noise, and inconsistent disease nomenclature are resolved by domain experts, followed by filtering via vision-LLMs against KB-grounded symptom descriptions. Each disease entry merges canonical class labels and organ tags (leaf, stem, root, seed, pod, etc.), supporting anatomical indices for candidate narrowing at inference.




Figure 1: Modular pipeline converting web documents into source-cited knowledge bases, filtering images with domain guidance and splitting into reference/test sets. Agentic evaluation is performed via a reasoning loop informed by anatomy and symptoms.
The disease registry construction pipeline issues targeted web queries, extracts structured claims (pathogen, organ, symptoms), and attaches verbatim source quotes, explicitly avoiding hallucinated knowledge via extract-only prompts. Field-level provenance permits expert audits and direct verification, achieving 70–90% agreement on symptom claims across crops.
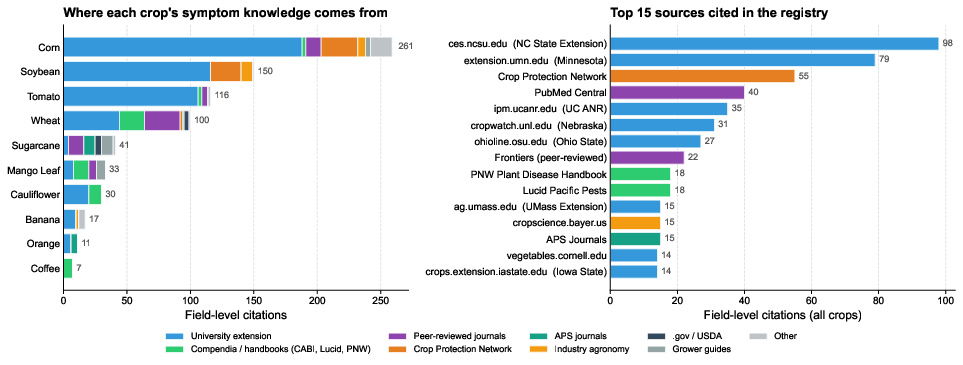
Figure 2: Source distribution for KB claims per crop, with dominant contributions from US extension publications, complemented by international datasheets and multi-university networks.
Agentic Diagnostic Pipeline
The diagnostic agent operates in a multi-turn loop, receiving:
- Test image.
- Reference images (organized by disease class and organ).
- Symptom KB and anatomical index (mapping organs to diseases).
- Candidate disease list and reference viewing budget k.
Initial steps involve anatomical context deduction and symptom extraction from the test image. Candidate narrowing proceeds first by anatomical index, then by symptom description ranking. Reference images are viewed sequentially (not in parallel), with per-comparison reasoning interrogating visual similarity and systematically rejecting incompatible candidates. Final prediction is generated via visual similarity, supported by KB guidance, and accompanied by a reasoning trace detailing viewed references, elimination steps, and justification.
This chain-of-thought, audit-trail-based inference paradigm supports full explainability, contrasting opaque single-pass classification workflows.
Experimental Results
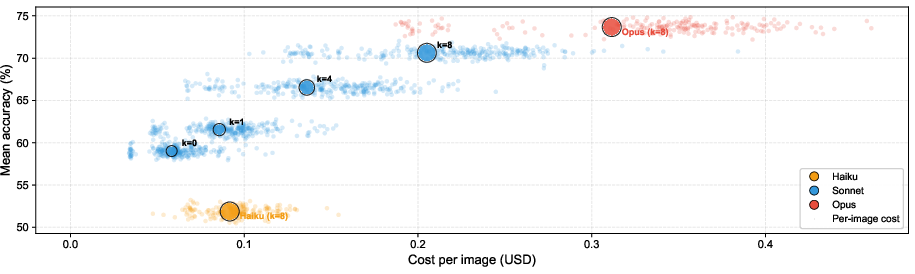
Evaluation was conducted on four crops (Soybean, Corn, Tomato, Mango), spanning 25–30 disease classes (except Mango, with four). Reference budgets k were varied (0, 1, 4, 8), and KB integration was toggled. Model tiers included Claude Haiku, Sonnet, and Opus.
Key results:
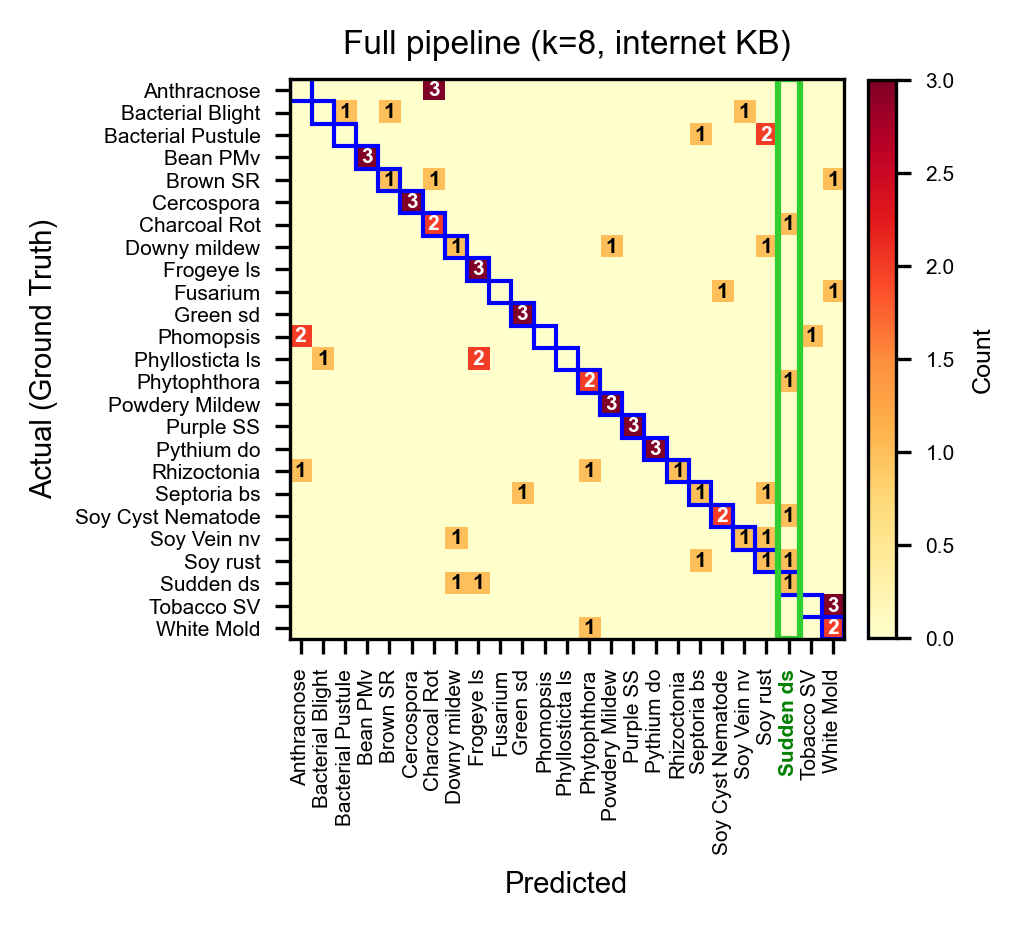
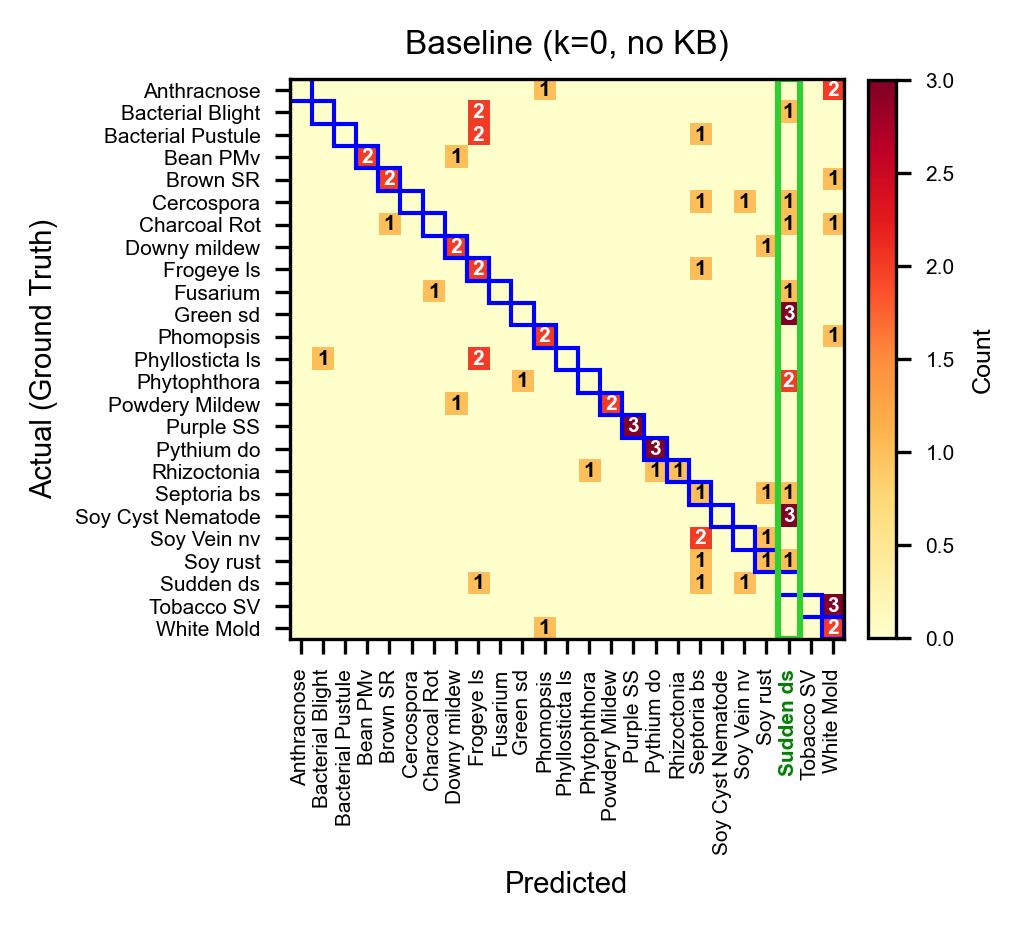
Figure 4: Confusion matrices for Soybean. KB and reference-guided agent (right) achieves better class separation, reducing systematic misclassifications.
Explainability and Expert Validation
Each diagnostic trace provides an audit trail: anatomical narrowing, symptom-guided candidate ranking, sequential reference comparison, and justification for rejection or acceptance. This transparency is validated via field-level expert audits on KB-sourced claims (Figure 5).
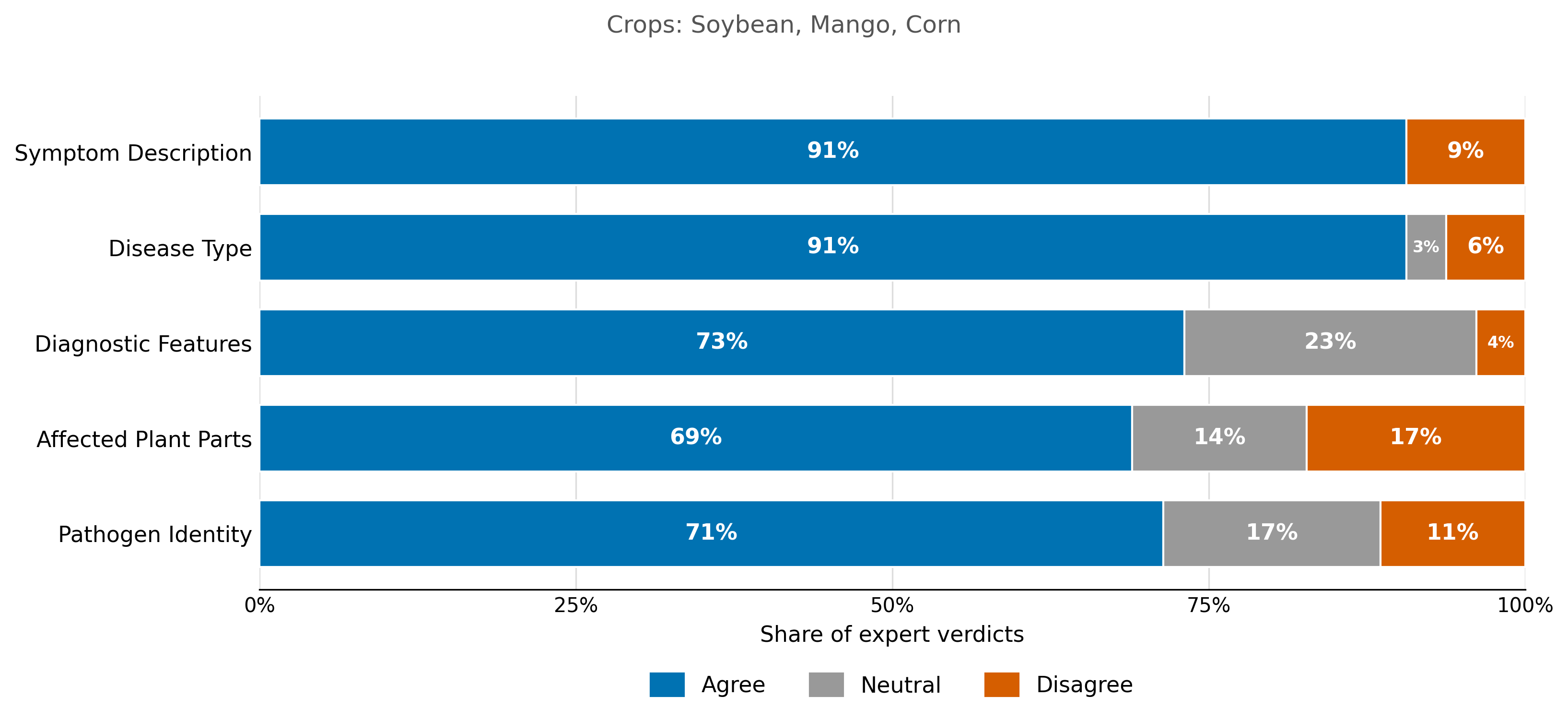
Figure 5: Expert audit agreement rates for KB-sourced symptom claims across crops. Disagreement is concentrated in fine-grained symptom distinctions.
Theoretical and Practical Implications
The SAGE framework demonstrates that:
- Training-free, agentic chain-of-thought reasoning, grounded in source-verifiable structured knowledge, enables scalable and extensible crop disease diagnosis with explainability and accuracy gains.
- The pipeline supports continuous improvement as foundation models evolve, requiring neither retraining nor additional annotation for new crops.
- Accuracy improvements are contingent on both knowledge integration and reference-based comparison; optimal gains are realized in challenging, fine-grained class regimes.
The practical utility spans breeding pipelines, extension scouting, and deployment in field scenarios where explainability and rapid extensibility are critical.
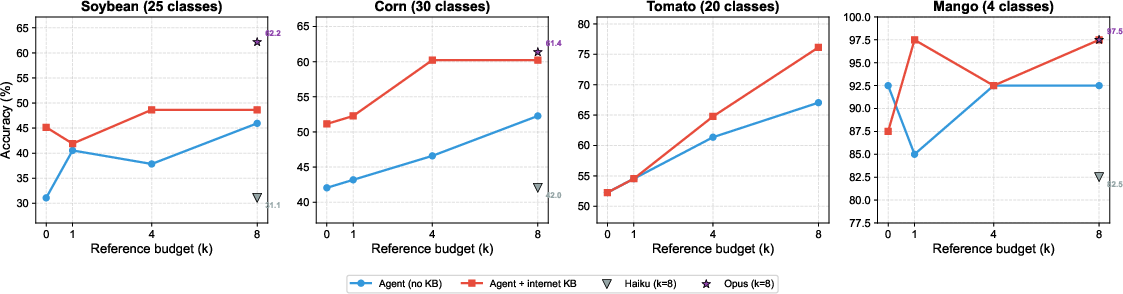
Figure 6: Diagnostic accuracy curves as reference budget k increases, with and without internet KB. KB effects compound with increasing k.
Future Directions
Areas for further research include:
- Expanding registry coverage to crops documented in non-English web pages, improving global applicability.
- Reducing inference costs (API and compute) for smartphone-level field deployment.
- Advanced agent designs—handling multiple co-occurring diseases, stage-aware symptom differentiation, and batch inference protocols.
- Integrating broader domain benchmarks and challenging reasoning datasets (AgMMU, AgroBench, etc.).
Conclusion
The SAGE framework delivers agentic, source-grounded diagnosis at scale, outperforming single-pass baselines in accuracy and offering full traceability for predictions. The modular pipeline and open dataset lay the groundwork for extensible reasoning architectures in agricultural AI, enabling robust, explainable disease classification without per-crop supervised training. The methodology augments existing vision-language paradigms, prioritizing transparency, extensibility, and practical deployment.