- The paper introduces a three-stage, training-free pipeline combining visual captioning, task-specific Q&A, and LLM-judged reasoning.
- It demonstrates significant accuracy improvements, with a 22.7% gain in disease classification and robust auditability through explicit reasoning trails.
- The modular design offers adaptable deployment for high-stakes diagnoses, aligning machine outputs with expert rationale.
Agri-CPJ: A Training-Free Explainable Framework for Agricultural Pest Diagnosis
Introduction
The Agri-CPJ (Caption-Prompt-Judge) framework addresses two core deficiencies prevalent in existing crop disease diagnosis systems: propensity for visual–linguistic models (VLMs) to hallucinate or misattribute species in field scenarios, and the lack of accessible, actionable explanations accompanying those predictions. State-of-the-art unimodal classifiers and even multimodal VLMs often fail under distribution shifts or novel conditions, and when they do fail, they provide only opaque class labels with no auditability. Agri-CPJ introduces a three-stage, training-free pipeline in which a large vision-LLM generates a multi-angle, nomenclature-free morphological caption of the crop image, which is then iteratively quality-gated. Two task-specific candidate answers are subsequently produced, and finally, a LLM judge selects and rationalizes the optimal answer using domain-calibrated criteria.
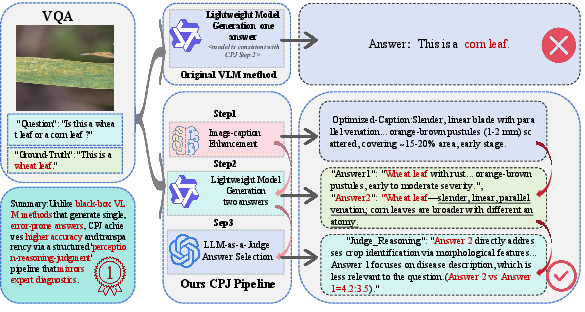
Figure 1: Traditional VLMs provide direct black-box predictions that can be error-prone; Agri-CPJ intercepts with an explicit perception–reasoning–judgment pipeline yielding both higher accuracy and interpretability.
Framework Architecture
Agri-CPJ decomposes inference into three modular stages:
- Generative Explanational Captioning: The input image is processed by an LVLM to yield a descriptive caption detailing plant morphology, symptom expression, severity, and diagnostic uncertainty. Critically, species and disease identifiers are suppressed to avoid label leakage. The caption undergoes iterative LLM-as-a-judge refinement, which checks for observational veracity, completeness, and neutrality, ensuring the text serves as a transparent record of visual features.
- Task-Specific Prompt-Based VQA Generation: The refined caption, combined with the original image and curated few-shot exemplars, is fed into the VQA module. Two candidate responses are generated from complementary diagnostic perspectives: one focused on identifying disease (morphological reasoning toward diagnosis), the other on management guidance.
- LLM-as-a-Judge Answer Selection: A higher-capability LLM judges both candidates against reference answers using a rubric that scores factual correctness, completeness, specificity, and practical actionability (verbosity is excluded to mitigate bias). The stronger answer is selected, with the judge providing an explicit rationale traceable by a human expert.
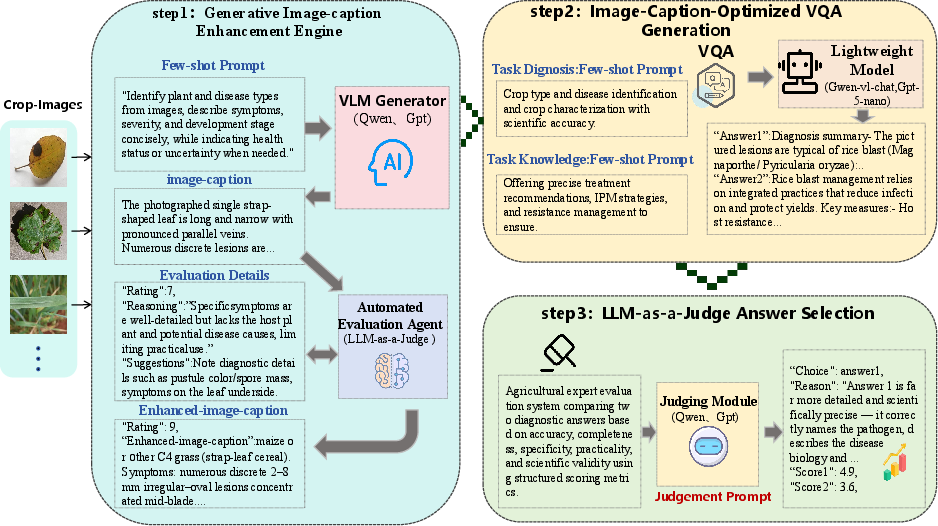
Figure 2: The Agri-CPJ pipeline externalizes intermediate reasoning via captions and dual-answer generation, supporting transparent VQA with judge-validated responses.
This architecture externalizes the visual reasoning step, creating a human-readable bridge between perception and diagnosis. Unlike chain-of-thought methods that produce a single, intertwined rationale-answer sequence, Agri-CPJ requires a stand-alone caption independent of label inference, making reasoning chains auditable and amendable prior to answer selection.
Empirical Evaluation
Caption Quality and Diagnostic Accuracy
Experiments on the CDDMBench dataset (3,000-field images) and the AgMMU-MCQs benchmark (767 expert–grower queries) demonstrate substantial accuracy improvements when caption optimization is included. On CDDMBench, integrating GPT-5-mini–generated captions into the GPT-5-Nano backbone yields a +22.7 percentage point gain in disease classification and +19.5 in QA scores relative to no-caption baselines. The correlation between caption quality (scored using a bespoke multidimensional rubric) and diagnostic accuracy is positive (R2=0.112), with stronger gains for higher-quality morphological descriptions, particularly in species and disease identification.
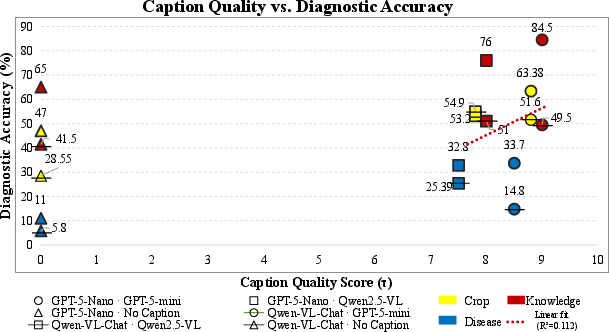
Figure 3: Caption quality is positively correlated with final diagnostic accuracy—high-quality captions consistently yield significant accuracy improvements over no-caption baselines.
Ablation and Component Analysis
Ablation studies clarify the contribution of each pipeline stage. Baseline LVLMs perform poorly in zero-shot settings, especially under distributional shift. Introducing raw captioning produces immediate improvements; iterative refinement further boosts accuracy by eliminating implicit diagnostic cues and focusing on observation. Few-shot prompting offers marked performance gains for vision-centric models but comparatively less for reasoning-oriented ones, suggesting architecture-dependent optimality. The LLM-as-a-Judge answer selection further increases terminal accuracy and provides structured rationales, with selected answers averaging 1.3 points higher on the rubrics than rejected counterparts.
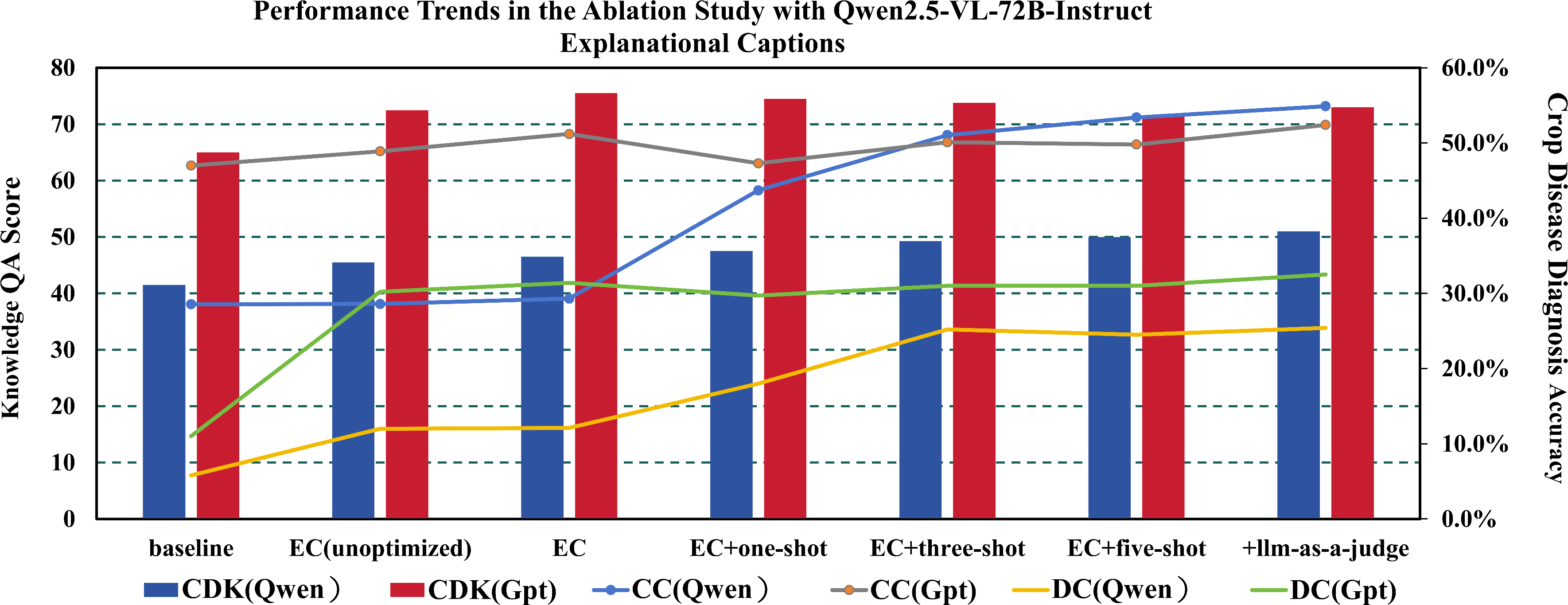
Figure 4: Progressive improvements are observed across pipeline additions; all components are necessary to achieve optimal performance across diagnostics, classification, and knowledge QA tasks.
Cross-Benchmark Generalization
On AgMMU-MCQs, employing the same unmodified pipeline achieves 77.84% accuracy with GPT-5-Nano and 64.54% with Qwen-VL-Chat—competitive with, or surpassing, existing open-source models of comparable scale. Species recognition (92.55%) benefits most from captioning, while disease identification remains a bottleneck due to overlapping symptoms and ambiguous visual cues.
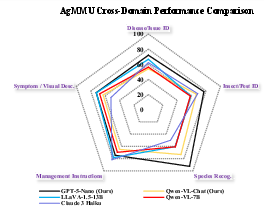
Figure 5: Agri-CPJ achieves strong, caption-boosted performance across five agricultural task categories on AgMMU-MCQs, with highest gains in morphological reasoning tasks.
Interpretability, Failure Modes, and Auditability
A salient feature of Agri-CPJ is the externalization of the reasoning chain. The pipeline produces a four-component audit trail—refined caption, dual candidate answers, candidate scores, and a written judge rationale—locatable for error attribution and correction. Human evaluation indicates high reliability: LLM judge selections match expert preferences with Cohen’s κ=0.88 (94.2% agreement). Identified failure modes include ambiguous early-stage symptoms (18%), co-infection confusion (12%), low input quality (8%), and residual verbosity bias in the judge (5%).
The modular structure allows direct mapping from error categories to architectural adjustments, such as introducing explicit uncertainty flags, adopting multi-label outputs for co-infections, or revising judge rubrics to further mitigate verbosity-driven misselections.
Theoretical and Practical Implications
Agri-CPJ operationalizes the argument that externalized, quality-controlled intermediate representations offer both improved performance and interpretable outputs in VQA. It eschews end-to-end fine-tuning, instead using off-the-shelf models and stateless API calls, making it deployment-ready for settings without retraining infrastructure or domain-specific corpora. Prompt-level adaptability enables rapid integration of novel exemplars or disease variants, a critical property in domains where data shifts or emergent threats are common.
The findings suggest that architectural commitments to explicit reasoning steps generalize beyond agriculture to any domain where the “semantic gap” between perception and domain language must be bridged for trustworthy decision support—e.g., medical image diagnosis, materials inspection.
Future Directions
Key open challenges remain: early-stage symptom ambiguity is fundamentally limited by perceptual signal quality, not captioning; multi-pathogen and management instruction coverage require broader output reporting and refined rubrics; and pipeline cost (3–5 LLM calls per query) may limit real-time or edge deployment. Cross-domain validation and further reduction of judge biases are needed for broader adoption.
Conclusion
Agri-CPJ demonstrates that enforced intermediate captioning, coupled with modular answer generation and rubric-based LLM-judged selection, provides substantive accuracy enhancements and interpretable, auditable outputs for agricultural pest diagnosis. The methodology scales to multiple benchmarks without parameter or prompt modifications, matches or exceeds the performance of comparably sized open-source models, and yields decision trails aligned with expert judgment. The approach invites further generalization to other visually grounded, high-stakes decision domains.
References
(2604.23701)

