- The paper presents AgroBench, a comprehensive benchmark covering seven agricultural tasks such as disease, pest, and weed identification.
- It employs expert-curated, real-world images and multiple-choice QA to rigorously assess both closed-source and open-source VLMs.
- Experimental results highlight strong performance in management tasks but significant challenges in fine-grained visual discrimination, especially weed identification.
AgroBench: A Comprehensive Vision-Language Benchmark for Agriculture
Motivation and Context
The development of robust, generalizable vision-LLMs (VLMs) for agriculture is critical for advancing automated crop management, disease diagnosis, and sustainable farming practices. Existing agricultural datasets are limited in scope, often focusing on narrow tasks or relying on synthetic annotations. "AgroBench: Vision-LLM Benchmark in Agriculture" (2507.20519) addresses these limitations by introducing a large-scale, expert-annotated benchmark that spans a wide range of real-world agricultural tasks and categories. AgroBench is designed to rigorously evaluate the capabilities of VLMs in agricultural scenarios, providing a foundation for both model assessment and future research in this domain.
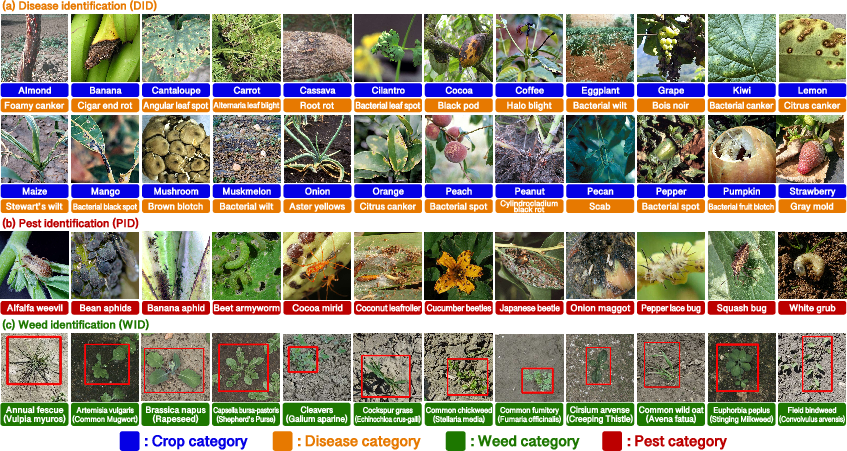
Figure 1: Examples of labeled images for DID, PID, and WID tasks. AgroBench includes 682 crop-disease pairs, 134 pest categories, and 108 weed categories, with a focus on real farm settings.
Benchmark Design and Task Coverage
AgroBench comprises seven distinct tasks, each reflecting a key area of agricultural engineering and real-world farming challenges:
- Disease Identification (DID): Fine-grained classification of crop diseases, with 1,502 QA pairs across 682 crop-disease combinations.
- Pest Identification (PID): Recognition of 134 pest categories, including multiple growth stages.
- Weed Identification (WID): Detection and classification of 108 weed species using bounding box annotations.
- Crop Management (CMN): Recommendation of optimal management strategies based on crop images and context.
- Disease Management (DMN): Suggestion of appropriate interventions for diseased crops, considering severity and context.
- Machine Usage QA (MQA): Selection and operation of agricultural machinery for specific tasks.
- Traditional Management (TM): Identification and explanation of traditional, sustainable farming practices.
Each task is formulated as a multiple-choice question-answering problem, with all questions and answers manually curated by expert agronomists. The dataset includes 4,342 QA pairs and 4,218 high-quality images, prioritizing real farm conditions to ensure ecological validity.
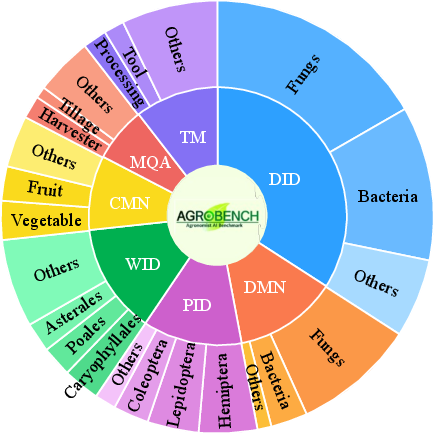
Figure 2: Seven benchmark tasks in AgroBench, illustrating the diversity of topics and the balanced evaluation protocol.
Annotation Protocol and Dataset Construction
AgroBench's annotation process is distinguished by its reliance on domain experts rather than synthetic or LLM-generated data. For identification tasks (DID, PID, WID), images were sourced from authoritative, redistribution-permitted datasets and manually filtered for clarity and relevance. For management and machinery tasks (CMN, DMN, MQA, TM), questions and answers were constructed using textbooks, academic literature, and expert knowledge, with GPT used only for sentence rephrasing.
The dataset's breadth is further illustrated by the distribution of disease, pest, and weed categories, which far exceeds prior benchmarks in both scale and granularity.

Figure 3: Examples of QA pairs for CMN and DMN tasks, demonstrating the need for nuanced, context-dependent reasoning.
Experimental Evaluation
Model Selection and Protocol
AgroBench was used to evaluate a suite of state-of-the-art VLMs, including both closed-source (GPT-4o, Gemini 1.5-Pro/Flash) and open-source (QwenVLM, LLaVA, CogVLM, EMU2Chat) models. Human performance was also measured as a reference, with 28 participants holding at least a bachelor's degree in agriculture.
Evaluation was conducted per task, with overall accuracy computed as the mean across tasks to prevent dominance by tasks with more QA pairs. Exact match was required for correctness in the multiple-choice setting.
Main Results
Closed-source VLMs consistently outperformed open-source models and human baselines across most tasks. GPT-4o achieved the highest overall accuracy (73.45%), with Gemini 1.5-Pro also performing strongly. However, all models exhibited significant performance degradation on the Weed Identification (WID) task, with most open-source models performing near random (e.g., LLaVA-Next-72B: 26.98%, QwenVLM-72B: 34.48%). Disease Identification (DID) also remained challenging, with accuracy lagging behind Disease Management (DMN), indicating that contextual reasoning is easier for current VLMs than fine-grained visual discrimination.
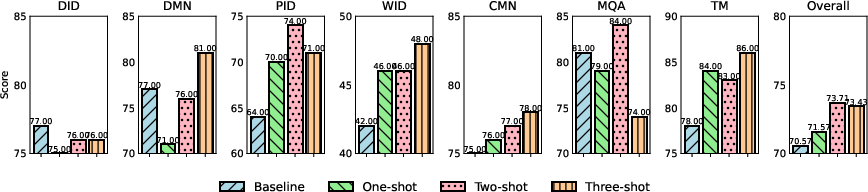
Figure 4: Results of seven benchmark tasks with Chain of Thought (CoT). CoT provides marginal improvements, especially in complex reasoning tasks.
Ablation Studies
- Text-Only Input: Removing image input led to a substantial drop in performance, confirming the necessity of visual information for most tasks. However, some management tasks (DMN, CMN, TM) retained above-random accuracy, suggesting that models can exploit common-sense priors or statistical regularities in the answer space.
- Chain of Thought (CoT): Incorporating CoT reasoning yielded modest gains, particularly in tasks requiring stepwise reasoning (PID, WID, CMN, TM), but did not overcome the fundamental knowledge and perception limitations observed in identification tasks.
Error Analysis
A detailed manual analysis of model errors on GPT-4o revealed the following breakdown:
- Lack of Knowledge (51.92%): The most prevalent error type, reflecting insufficient domain-specific knowledge, especially for rare diseases, pests, and weeds.
- Perceptual Error (32.69%): Failures in attending to or correctly interpreting relevant image regions, often leading to hallucinated or irrelevant answers.
- Reasoning Error (7.6%): Inability to compare options or follow logical steps, though less frequent than in general-domain benchmarks.
- Other Errors (7.79%): Including shortcut reasoning, double answers, misinterpretation of questions, and refusal to answer.
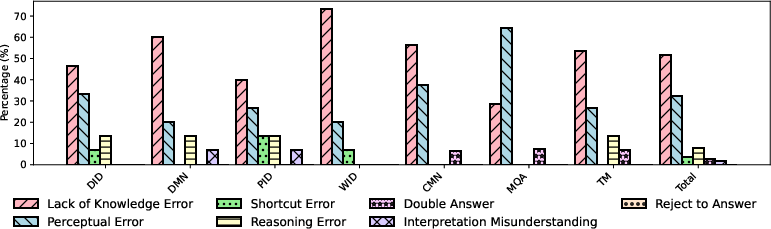
Figure 5: Error analysis on seven benchmark tasks with GPT-4o, categorizing the main sources of failure.

Figure 6: Error examples of GPT-4o, illustrating Lack of Knowledge and Perceptual Error cases.
Implications and Future Directions
AgroBench exposes critical gaps in current VLMs' ability to generalize to fine-grained, domain-specific agricultural tasks. The strong performance of closed-source models relative to open-source alternatives highlights the importance of large-scale, high-quality pretraining and possibly proprietary data sources. However, even the best models fall short in tasks requiring detailed botanical or entomological knowledge, particularly for underrepresented categories such as weeds.
The error analysis suggests that further progress will require:
- Domain-Specific Pretraining: Incorporating expert-annotated agricultural data, especially for rare or visually similar categories.
- Enhanced Perceptual Modules: Improving attention and localization capabilities to reduce perceptual errors.
- Knowledge Augmentation: Integrating structured agricultural knowledge bases or retrieval-augmented generation to address knowledge gaps.
- Task-Specific Adaptation: Developing specialized adapters or prompt engineering strategies for challenging tasks like WID and DID.
AgroBench also provides a valuable resource for benchmarking future VLMs, supporting both model development and deployment in real-world agricultural settings.
Conclusion
AgroBench establishes a new standard for evaluating vision-LLMs in agriculture, offering unprecedented task diversity, expert annotation, and ecological validity. The benchmark reveals that while VLMs have made significant strides in management and general reasoning tasks, substantial challenges remain in fine-grained identification and domain-specific knowledge integration. AgroBench will serve as a catalyst for future research in agricultural AI, guiding the development of models that are both accurate and practically deployable for sustainable, automated farming.