- The paper demonstrates that expert-verified, visually grounded chain-of-thought rationales significantly enhance model transparency and diagnostic accuracy.
- It details a multi-stage data curation pipeline that refines over 11,000 images with structured annotations, calibrated scores, and explicit visual evidence.
- Evaluation shows AgriChain outperforms state-of-the-art baselines in accuracy and error reduction, effectively addressing ambiguous and minority disease cases.
Visually Grounded Chain-of-Thought Reasoning for Interpretable Vision–LLMs in Plant Disease Diagnosis
Introduction
AgriChain (2604.07814) presents a comprehensive approach to enhancing the accuracy and transparency of plant disease diagnosis systems by leveraging vision–LLMs (VLMs) supervised with expert-verified chain-of-thought (CoT) rationales. By annotating an 11,000-image dataset with expert-refined explanations, disease labels, and calibrated confidence scores, and by fine-tuning a VLM (Qwen-2.5-VL-3B) on this dataset, the authors demonstrate substantial improvements over state-of-the-art zero-shot and fine-tuned multimodal baselines. The methodology directly addresses current limitations in domain-adapted VLMs—namely, insufficient visual grounding, lack of calibrated uncertainty, and the absence of interpretable reasoning in agricultural decision-making.
Methodology and Data Pipeline
The AgriChain dataset is constructed through a multi-stage curation pipeline that aggregates and cleans data from several plant pathology image corpora (PlantVillage, PlantDoc, PlantCLEF). Initial diagnostic rationales are produced by prompting GPT-4o; these are then rigorously verified and standardized by professional agricultural engineers. Each image is annotated with a diagnosis, a confidence score (High/Medium/Low), and a structured rationale using standardized domain lexicon and explicit references to key visual cues (such as lesion morphology, color, and distribution). This structured approach systematically captures expert visual inspection and decision patterns.
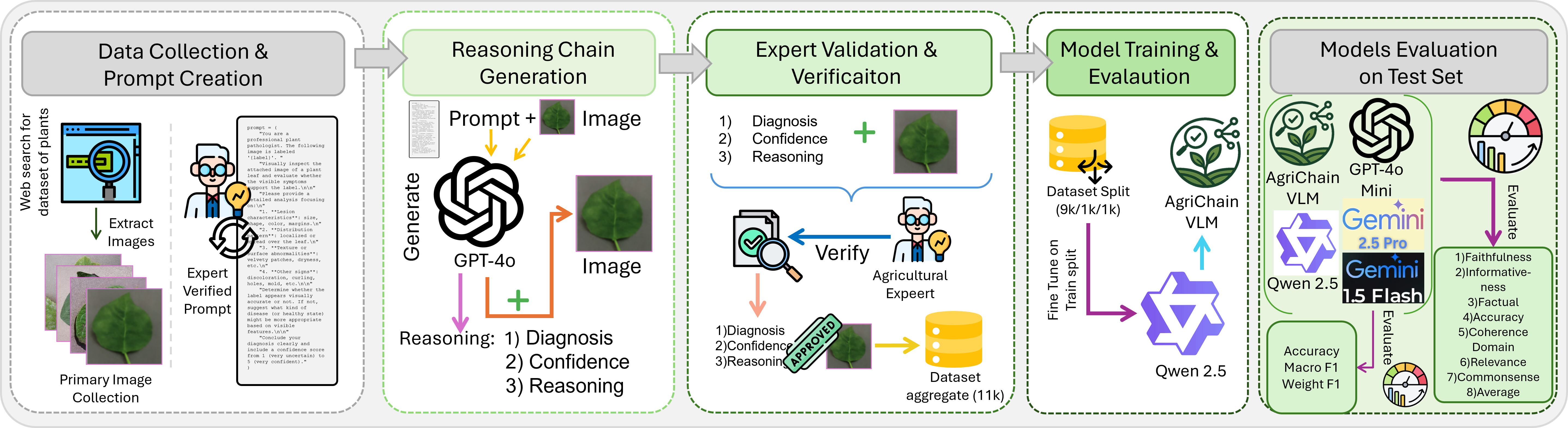
Figure 1: AgriChain training pipeline, showing data aggregation, rationale drafting by GPT-4o, expert verification, and fine-tuning of an open VLM.
Prompts are iteratively refined to elicit expert-level, step-wise, visually anchored reasoning, structurally mirroring domain diagnostic workflows and supporting robust, explicit justification in the generated explanations.

Figure 2: Example of the diagnostic rationale prompt, constructed to guide the model towards structured, detailed visual reasoning with a confidence score.
The processed and curated dataset is used to fine-tune Qwen-2.5-VL-3B in a supervised fashion, with the model jointly trained to predict the disease class and to generate an associated expert-style CoT rationale. Standard autoregressive next-token prediction objectives are used, and training is performed with careful early stopping, optimizer tuning, and data augmentation for class balance and generalizability.
Evaluation and Results
Evaluation is conducted on a carefully class-balanced, 1,000-image test set, measuring top-1 accuracy, macro-F₁, and weighted F₁. AgriChain-VL3B achieves a top-1 accuracy of 73.1%, an unweighted macro F₁ of 0.466, and a weighted F₁ of 0.655—outperforming Gemini 2.5 Pro, Gemini 1.5 Flash, GPT-4o-Mini, and zero-shot Qwen-2.5-VL by substantial margins (Gemini Pro: 55.8% accuracy, macro F₁ 0.141). The performance differential is attributed specifically to reasoning-based supervision and not simply to scale or underlying VLM pretraining.
Strong performance is especially evident in the model’s ability to handle minority classes and confusable disease pairs, with CoT reasoning chains leading to improved calibration and error reduction in visually ambiguous situations. Notably, the explanations generated by the fine-tuned model are consistently domain-faithful, informative, and linked to explicit visual evidence as judged by blinded annotators (average 4.63/5 across six reasoning quality dimensions).

Figure 3: Sample outputs demonstrating visually grounded diagnoses, confidence estimation, and structurally coherent rationales.
Qualitative analysis demonstrates that AgriChain-VL3B explanations feature robust symptom anchoring, structured differential diagnosis routines (explicitly eliminating alternative diagnoses based on negative evidence), and high reviewability by experts. In contrast, baseline models frequently produce generic or hallucinated explanations lacking domain specificity.

Figure 4: Reasoning sample for cedar-apple rust—note explicit linking of visual features to domain-specific discriminative cues.
Discussion and Implications
The data and methodology in AgriChain address previously unsolved issues in agricultural AI: (1) domain grounding via expert-guided lexicon and visual evidence referencing, (2) true interpretability by forced model explanation, and (3) practical uncertainty calibration via confidence ranking. The substantial absolute gains in top-1 accuracy and macro F₁ directly support the claim that CoT supervision with expert verification outperforms pure label-based fine-tuning, especially in low-resource (tail) classes and visually ambiguous cases.
These findings have direct implications for real-world deployment scenarios, especially in regions where agricultural diagnostics are a limiting factor for food security. The model’s capacity to output transparent rationales and uncertainty scores aligns closely with requirements for trustworthy, auditable, AI-driven support systems, both in cloud and resource-constrained edge environments. Furthermore, the AgriChain approach is theoretically extensible to other agricultural visual tasks (e.g., pest identification, stress phenotyping) as well as to adjacent domains requiring visually grounded interpretability (e.g., medical imaging, environmental monitoring).
Limitations and Future Directions
AgriChain’s current limitations include persistent difficulties in highly rare classes (due to limited data and symptom overlap) and periodic overfitting to domain lexicon. Future work directions identified include semi-automated rationale annotation pipelines to improve dataset scalability, multilingual rationale support for global deployment, expanded disease/taxa diversity, and tighter enforcement of evidence-bound explanations (to counteract subtle hallucinations). Integration into closed-loop farmer support systems—with human-in-the-loop feedback—remains a critical next step toward robust, adaptive, and field-deployable decision support.
Conclusion
AgriChain establishes that fine-tuning VLMs with expert-verified, visually grounded CoT rationales yields significant improvements in both diagnostic performance and interpretability over prior models and benchmarks. By centering domain-authentic explanatory supervision and rigorous data curation, the approach elevates plant disease VLMs from black-box classifiers to auditable, trustworthy decision-support tools—embodying a paradigm shift toward transparent AI in agriculture. The general methodology is highly applicable for other high-stakes visual reasoning tasks where reliability and human-AI co-validation are paramount.

