- The paper finds that suppressing dynamically identified attention sinks does not degrade semantic alignment or human preference metrics in diffusion transformer outputs.
- It employs causal interventions via score-path and value-path masking across multiple layers and denoising timesteps in both SD3 and SDXL architectures.
- However, while semantic fidelity is maintained, sink suppression induces significant perceptual shifts, highlighting a trade-off between alignment and output trajectory.
Introduction
The paper "Attention Sinks in Diffusion Transformers: A Causal Analysis" (2605.09313) systematically investigates the functional role of attention sinks in diffusion transformer architectures, specifically within the context of text-to-image generation. Attention sinks—tokens that receive disproportionate attention mass—are empirically load-bearing in autoregressive LLMs, serving as stable anchors for memory and preventing entropy collapse. This work questions whether this intuition holds for diffusion transformers, which operate under fundamentally different, bidirectional, non-causal attention mechanisms. Through dynamic identification and suppression of sinks during inference across various layers, timesteps, and architectures (SD3 and SDXL), the study causally tests their necessity for semantic alignment and preference-driven outputs.
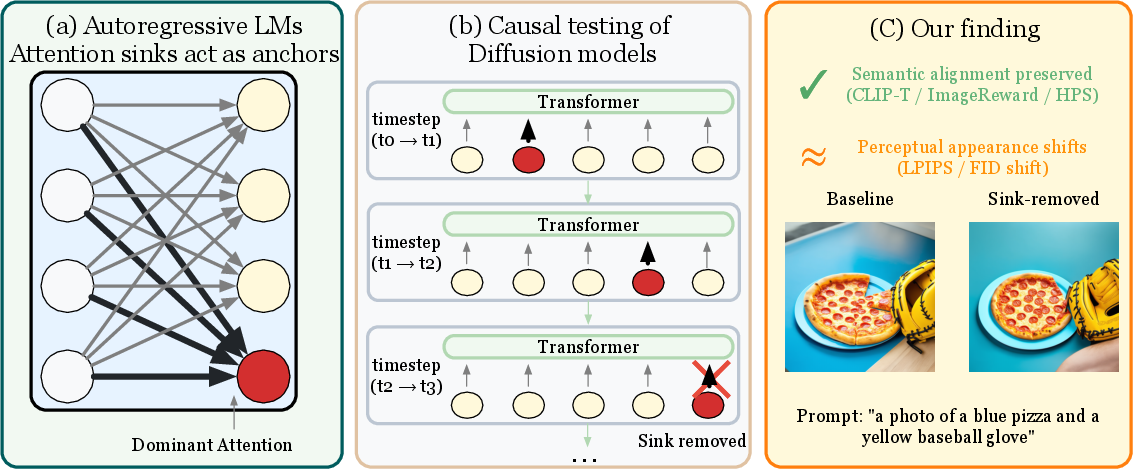
Figure 1: In diffusion transformers, attention sinks are dynamically identified and suppressed at each denoising timestep; sink suppression preserves semantic alignment but induces measurable perceptual drift.
Dynamics and Identification of Attention Sinks
The authors first characterize the formation and distribution of attention sinks across layers and denoising steps in diffusion transformers. Unlike autoregressive models—where sinks are often tied to fixed token positions such as index-0 or BOS—the paper reveals that sink positions in diffusion models are highly dynamic, concentrated at middle layers (layer 12) and early denoising phases, and exhibit negligible overlap with fixed proxies (<0.2%).
Attention concentration (measured by maximum incoming attention mass, entropy, and top-k concentration) peaks in the middle layers and diminishes throughout denoising. Furthermore, dominant sinks are structurally localized to a narrow subset of text-conditioning tokens, not universally distributed across the sequence.
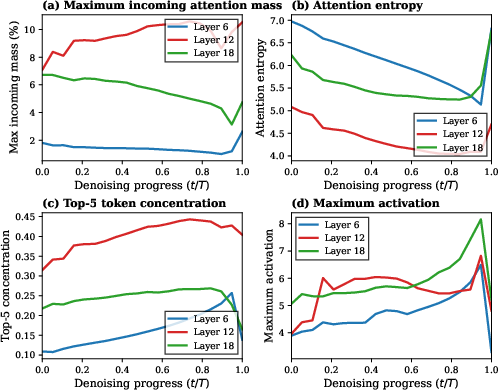
Figure 2: Attention sink dynamics: maximal incoming mass peaks at middle layers and decreases over denoising; entropy inversely correlates with concentration, and top-5 sink concentration increases with time.
Causal Interventions: Necessity for Alignment and Preference Metrics
The core experimental protocol employs dynamic sink identification per head and timestep, and suppresses dominant recipients during inference via both score-path (logit adjustment) and value-path (token value replacement) interventions. These manipulations are robustly applied across 553 GenEval prompts in Stable Diffusion 3 (SD3), with cross-architecture validation in Stable Diffusion XL (SDXL), and results are reported for alignment (CLIP-T) and preference (ImageReward, HPS-v2) metrics.
The primary finding is that removal of dynamically identified sinks, even across multiple layers and in both token and value paths, does not degrade text-image alignment or human preference proxies (CLIP-T, HPS-v2, ImageReward) under standard intervention budgets (k=1). The strongest interventions (k=5) yield only marginal, metric-dependent boundary effects, entirely within practical equivalence margins for CLIP-T (∣Δ∣<0.002), and negligible for preference metrics except at high masking budgets.
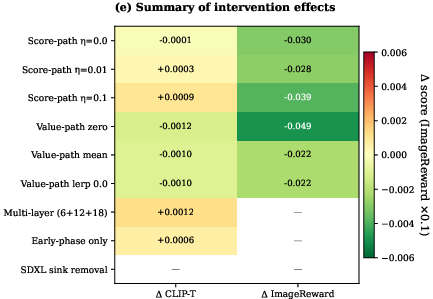
Figure 3: Summary of experimental effects: heatmap of paired Delta values for all interventions and metrics; all effects are small, non-significant, and within equivalence margins, indicating no meaningful quality degradation from sink removal.
Dose–response sweeps across intervention intensity (logit, value) confirm flat response curves, and robustness analyses across layers, phases, tasks, and architectures demonstrate complete consistency: neither semantic alignment nor preference metrics are adversely affected by sink suppression.
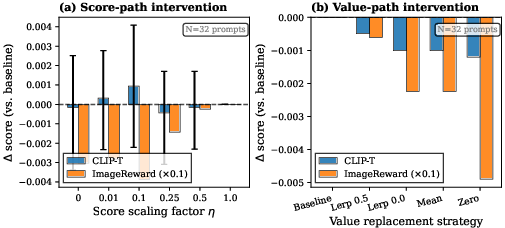
Figure 4: Dose–response curves for score-path and value-path interventions show flat trajectories, confirming robustness across masking intensity.
Perceptual and Distributional Shifts
The paper identifies that while sink suppression leaves alignment and preference metrics invariant, it induces substantial perceptual and distributional shifts in model outputs. LPIPS and FIDshift distances (between baseline and intervention outputs) scale monotonically with the masking budget and are up to six times larger for sink suppression than random masking at the same budget. Sink removal thus strongly perturbs the trajectory of generated samples, moving them within the output manifold, without semantic misalignment.

Figure 5: Qualitative drift comparison at k=1 (sink masking versus random masking): sink removal causes pronounced layout and style changes without affecting semantic content.

Figure 6: At k=5, sink masking induces even larger perceptual drift compared to random masking, while alignment remains preserved.
This empirical dissociation between trajectory-level (perceptual) perturbation and alignment-level robustness delineates the structural boundary condition of sink suppression.
Cross-Architecture and Modality Attribution
Cross-validation in SDXL confirms the generality of the findings: sink suppression in both self- and cross-attention blocks yields no measurable quality loss. Attribution analysis reveals that attention sinks are overwhelmingly concentrated on text-conditioning tokens, not image-latent tokens, reflecting modality-specific architecture effects rather than functional relevance.
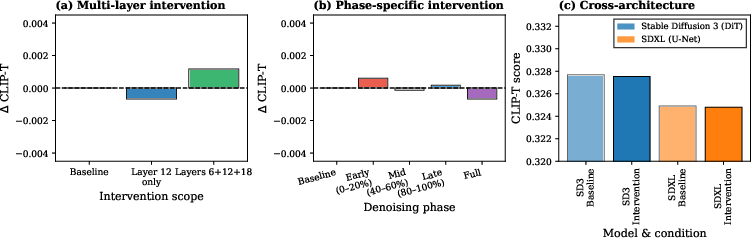
Figure 7: Robustness analysis: multi-layer, phase-specific, and cross-architecture interventions all show no significant quality degradation.
Preference Trade-Offs Under Stronger Masking
Under stronger suppression (higher k), preference metrics (HPS-v2) exhibit sink-specific degradation relative to random masking, sharply increasing with intervention intensity. This effect does not appear in CLIP-T, supporting the interpretation that sinks may encode preference-relevant, but not alignment-relevant, information at higher masking levels.
Implications, Limitations, and Future Directions
Practical Implications: The findings support the safe sparsification and removal of dominant attention recipients in diffusion transformer inference, enabling efficiency gains without risk to semantic fidelity. Attention-driven importance scores are unreliable proxies for functional necessity. Sparsification need not privilege high-mass tokens, but instead can dynamically remove them, monitored by alignment metrics.
Theoretical Implications: The results caution against transferring autoregressive intuition regarding attention sinks to diffusion architectures: high incoming mass does not imply functional necessity for semantic alignment. The dissociation of perceptual and semantic effects highlights the complex, architecture-dependent role of attention in generative models.
Limitations and Future Directions: The study focuses exclusively on semantic alignment and preference proxies, not compositional or skill-based evaluation. Realized speedups, FLOPs reductions, or human study of perceptual fidelity are not delivered. Further research is warranted to probe the boundary conditions for sinks' relevance in compositional fidelity, perceptual consistency, and trajectory control, as well as in alternative attention mechanisms.
Conclusion
This causal analysis demonstrates that dynamically defined attention sinks in diffusion transformers are not required for high-quality semantic alignment or human preference, even under stringent removal protocols. Attention mass is a poor indicator of necessity for text-to-image alignment in non-autoregressive generation. Sink suppression induces only trajectory-level perturbations, not semantic degradations, and can be safely exploited for inference acceleration. The results establish architectural independence from autoregressive sink intuitions and redefine design strategy for efficient diffusion transformer deployment.