- The paper introduces SinkProbe, a method that quantifies attention sink scores from Transformer models to reliably detect hallucinations in LLM outputs.
- It employs a lightweight logistic regression classifier on top-k sink features, achieving up to +4.9% ROC-AUC improvement over prior hallucination detectors.
- The study reveals that internal attention collapse in mid-to-late layers serves as a key signal of ungrounded, hallucinated generations, supporting robust model oversight.
Attention Sinks as Internal Signals for Hallucination Detection in LLMs
Introduction
This paper presents SinkProbe, a novel hallucination detection framework based on attention sinks—tokens that disproportionately attract attention in Transformer-based LLMs. The authors hypothesize that LLM hallucinations are intrinsically associated with a collapse in information flow, manifested as acute concentration of attention on a few tokens, decoupling generated text from the input context. SinkProbe operationalizes this via quantitative “sink scores” computed directly from attention maps and demonstrates that these scores, when used as features in a compact, model-agnostic probe, yield superior detection of hallucinated outputs across multiple LLM architectures and benchmarks.
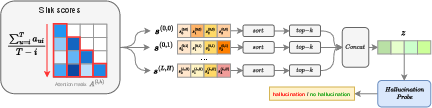
Figure 1: Pipeline for hallucination detection based on attention sink scores. For each layer l and head h, sink scores are computed and top-k extracted as features for classification.
Methodology
Given a sequence of length T and attention map A(l,h) for layer l, head h, the sink score si(l,h) for token position i is the normalized sum of attention received from all subsequent tokens (see Equation (1) in the paper). High sink scores indicate tokens acting as persistent attention attractors as generation unfolds.
To decouple sinkness from token identity, SinkProbe extracts and sorts sink scores per head and layer, retaining the top-k per head and aggregating them into a feature vector of dimension h0. This feature vector is input to a lightweight (logistic regression) classifier that predicts hallucination from model activations alone, without external knowledge sources or sampled generations.
Computationally Active Sinks
The approach identifies that only a subset of extreme attention sinks (those whose associated value vectors exhibit large norms) are computationally active, in the sense that they dominate downstream hidden representations and are highly predictive of hallucination. Empirically, norm differences in attention outputs between hallucinated vs. faithful generations align with the features selected by SinkProbe's h1-regularized probes, particularly in the middle and later transformer layers.
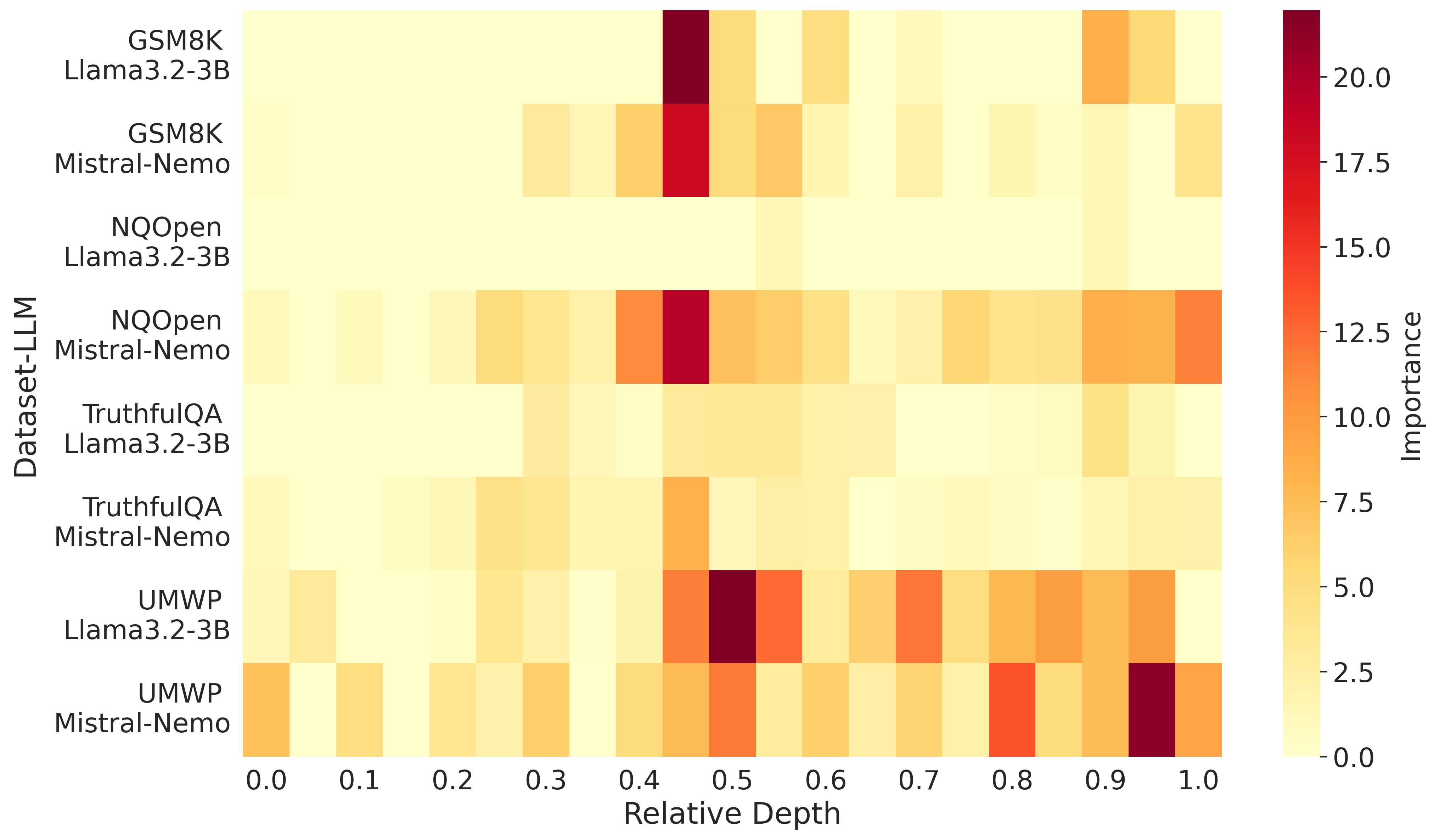
Figure 2: Importance scores of attention sinks, showing that mid-to-late layers concentrate most of the predictive signal for hallucination detection.
Unified Mechanistic Perspective
Prior attention-based hallucination detectors can be unified under the sink score paradigm. The attention log-determinant (AttnScore [llmcheck2024]), lookback ratios (LookbackLens [chuang2024lookback]), graph-based topological divergence metrics (MTopDiv, TOHA [bazarova2025hallucination]), and features derived from attention/Laplacian eigenvalues [binkowski-etal-2025-hallucination] all capture, either explicitly or implicitly, aspects of attention collapse as formalized by sink scores and their distribution.
For instance, Laplacian eigenvalues are shown to correspond to sink scores discounted by self-attention, and lookback ratios are mathematically coupled to the locations of dominant sinks in generated vs. prompt tokens.
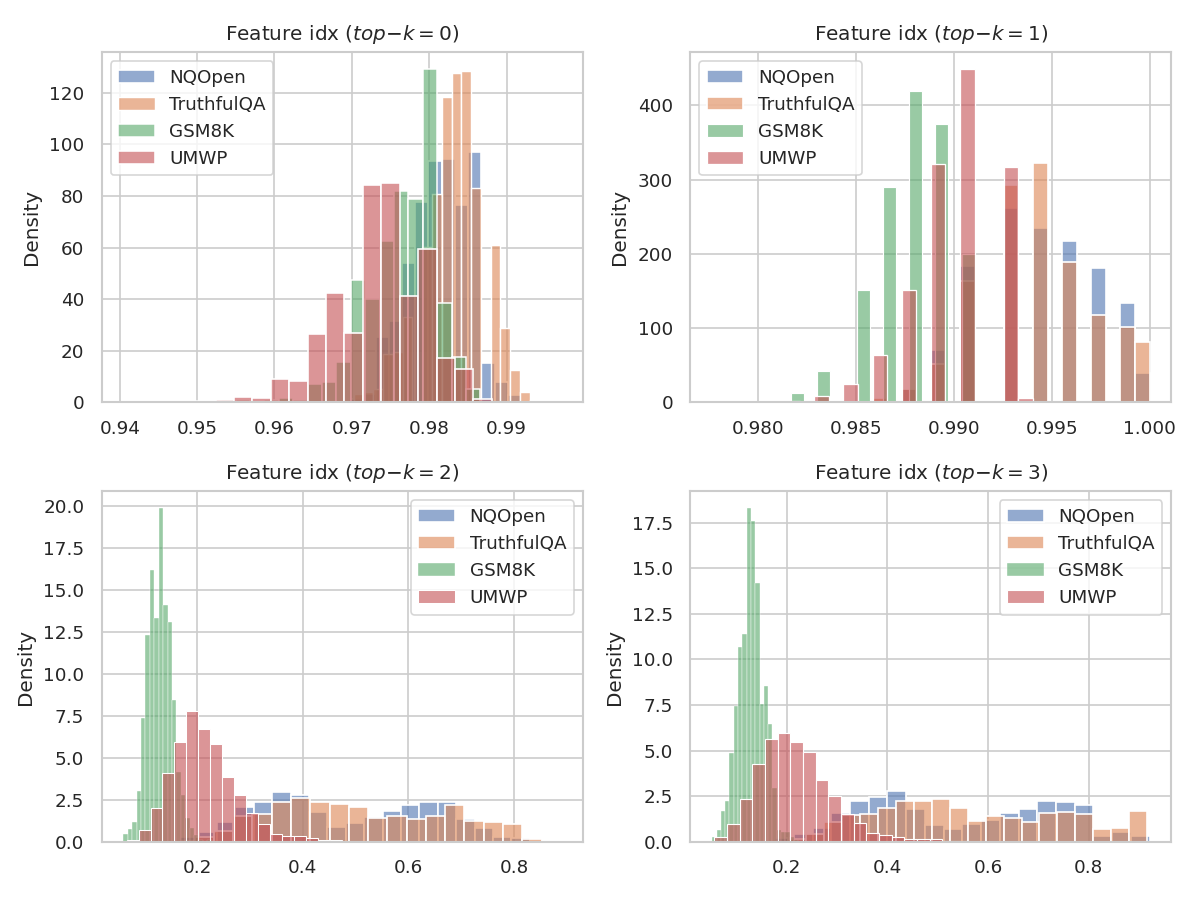
Figure 3: Distribution of the mean frequency with which the token with sink score at rank h2 lies in the prompt, demonstrating that lower-ranked sinks shift from prompt to generated tokens, especially on reasoning datasets.
Experimental Results
Extensive experiments are conducted across seven datasets and four open LLMs (Llama3.2-3B, Llama3.1-8B, Mistral-Nemo, Phi3.5). SinkProbe attains the highest mean ROC-AUC for hallucination detection in 23/28 evaluated model-dataset pairs, with improvements of up to +4.9% absolute ROC-AUC over the strongest prior baseline, and comparable or better performance across both factual QA and math reasoning tasks. Performance saturates for small h3 values (h4 to h5), underscoring the compactness of the hallucination signature.
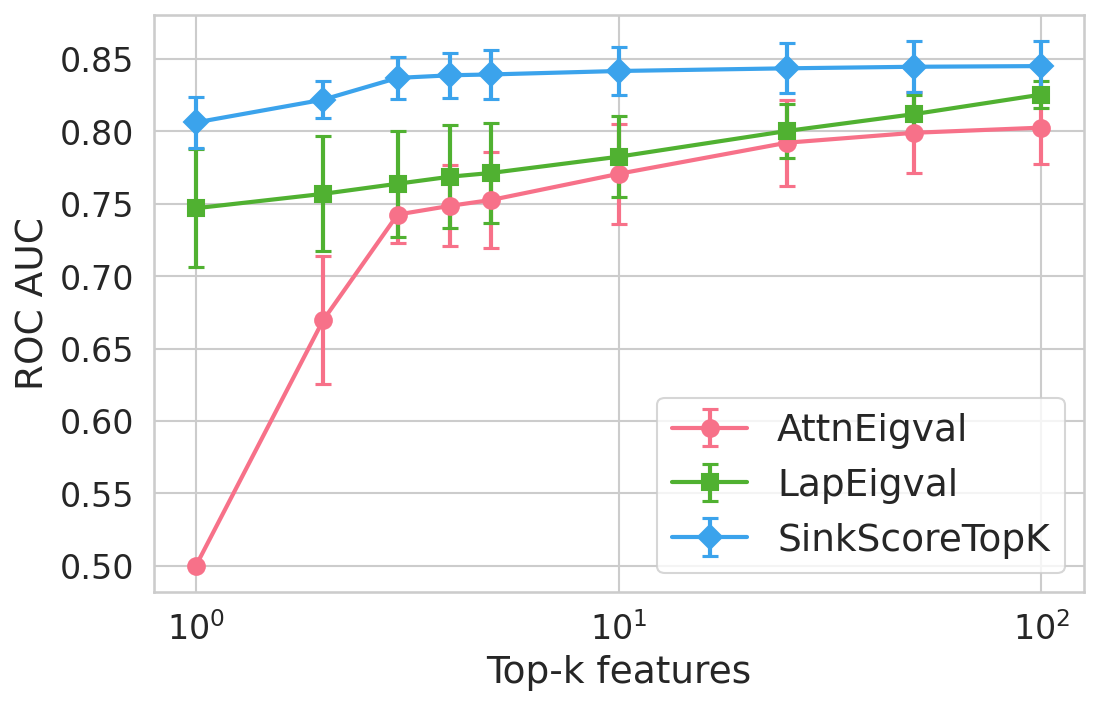
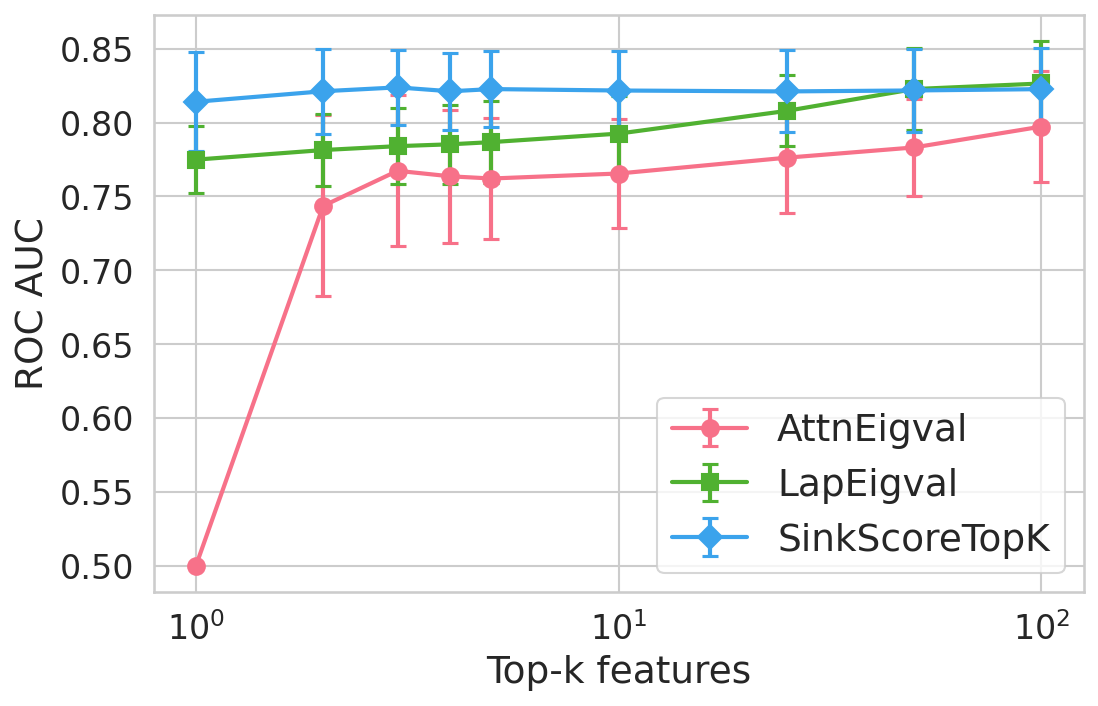
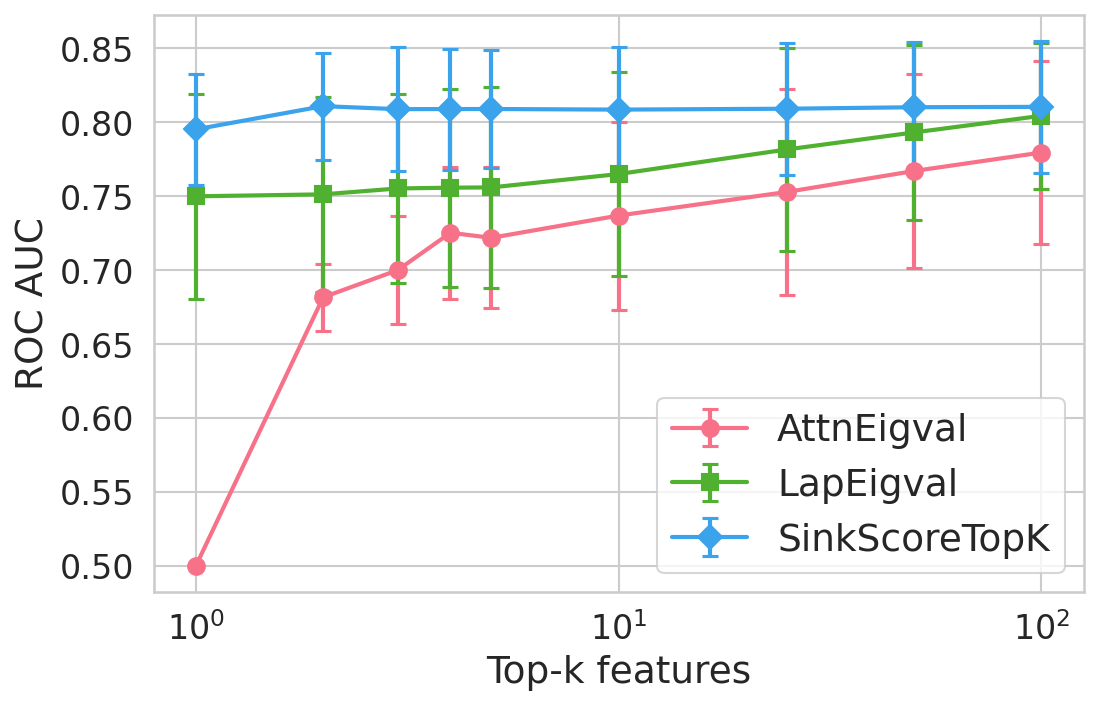
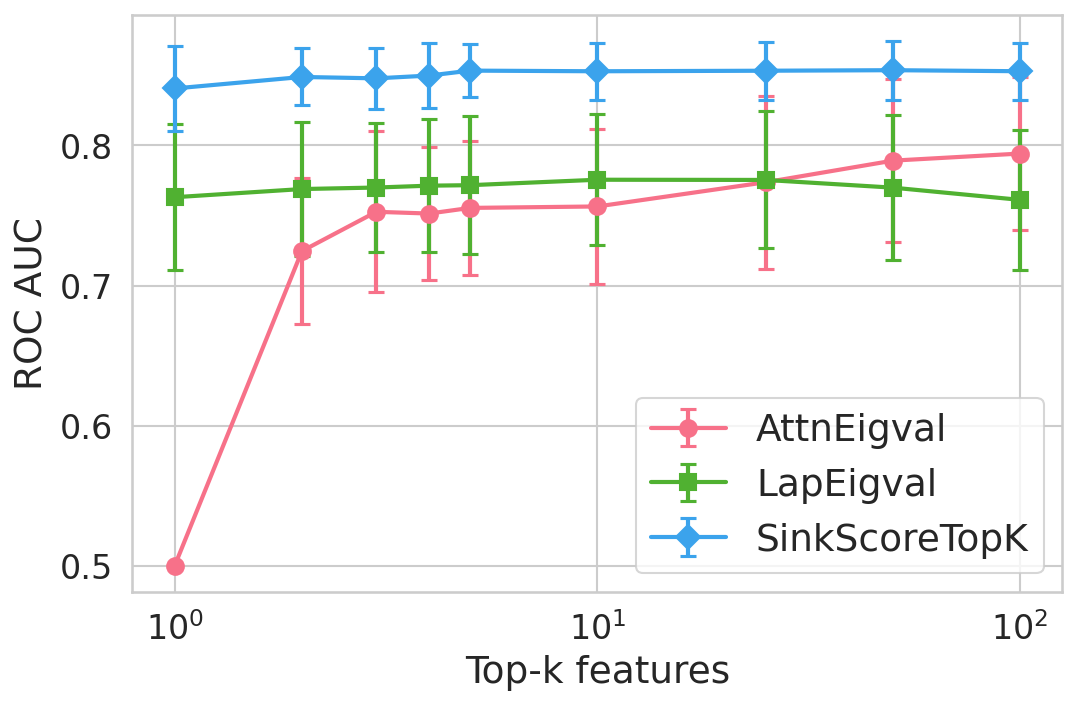
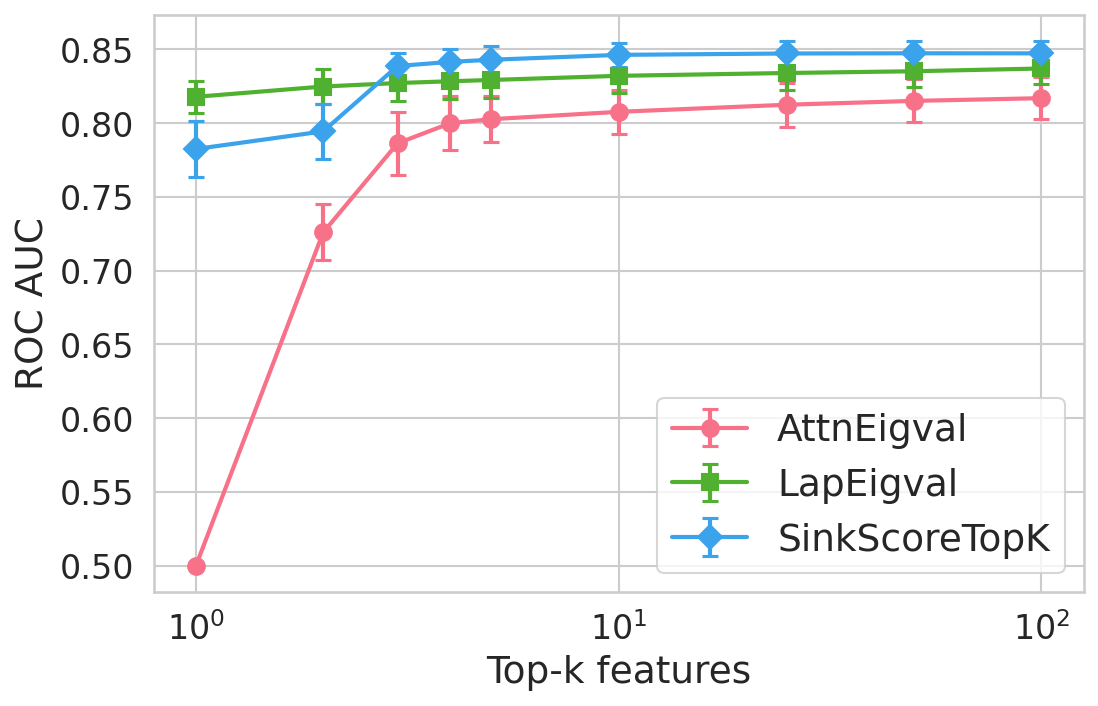
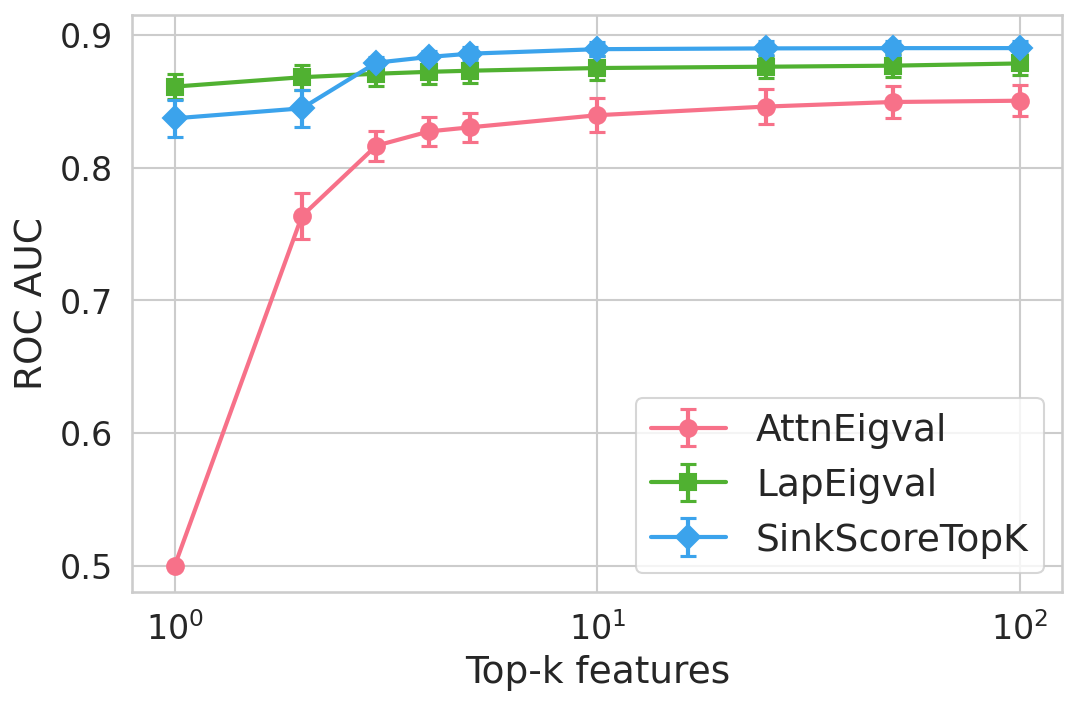
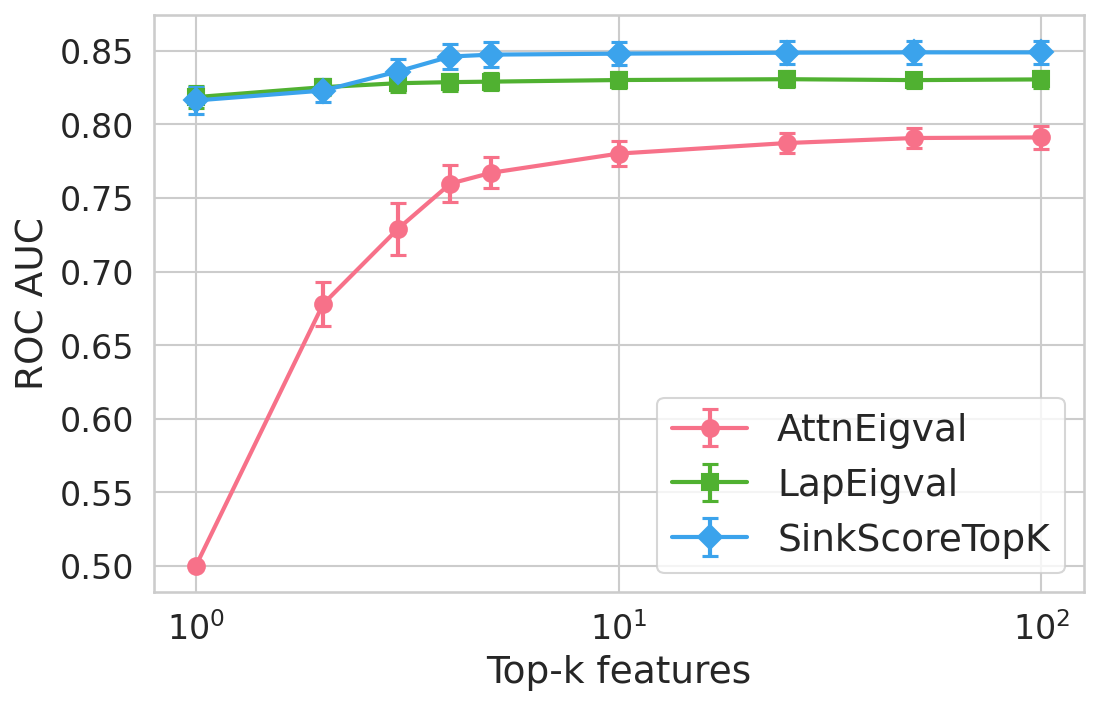
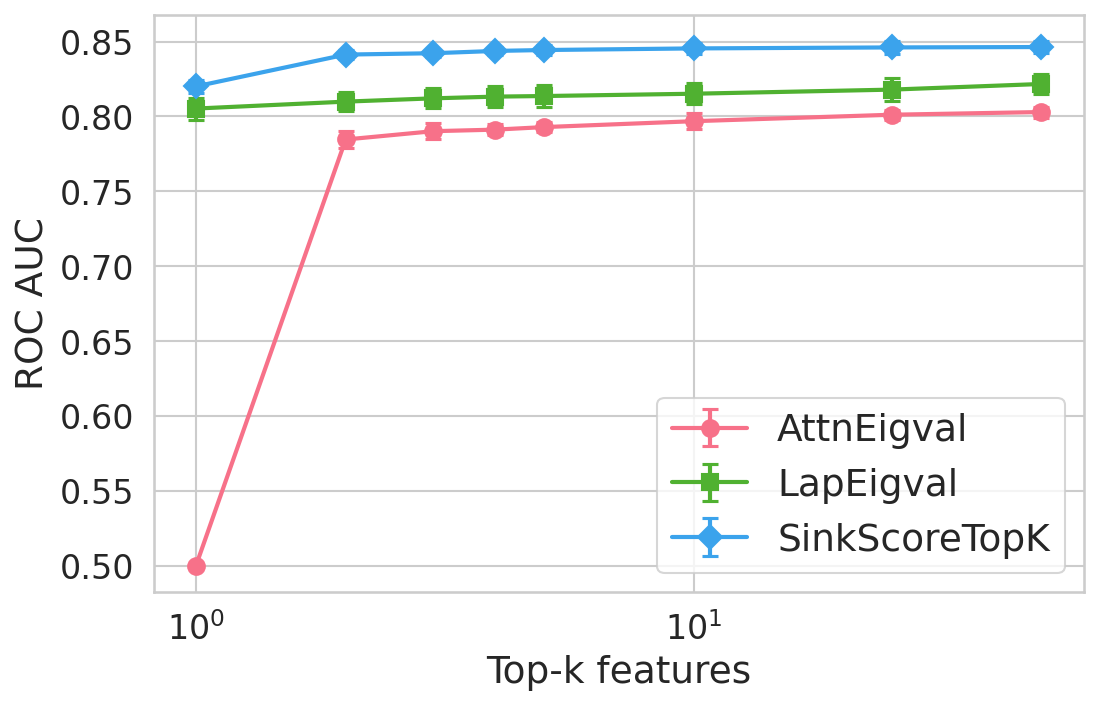
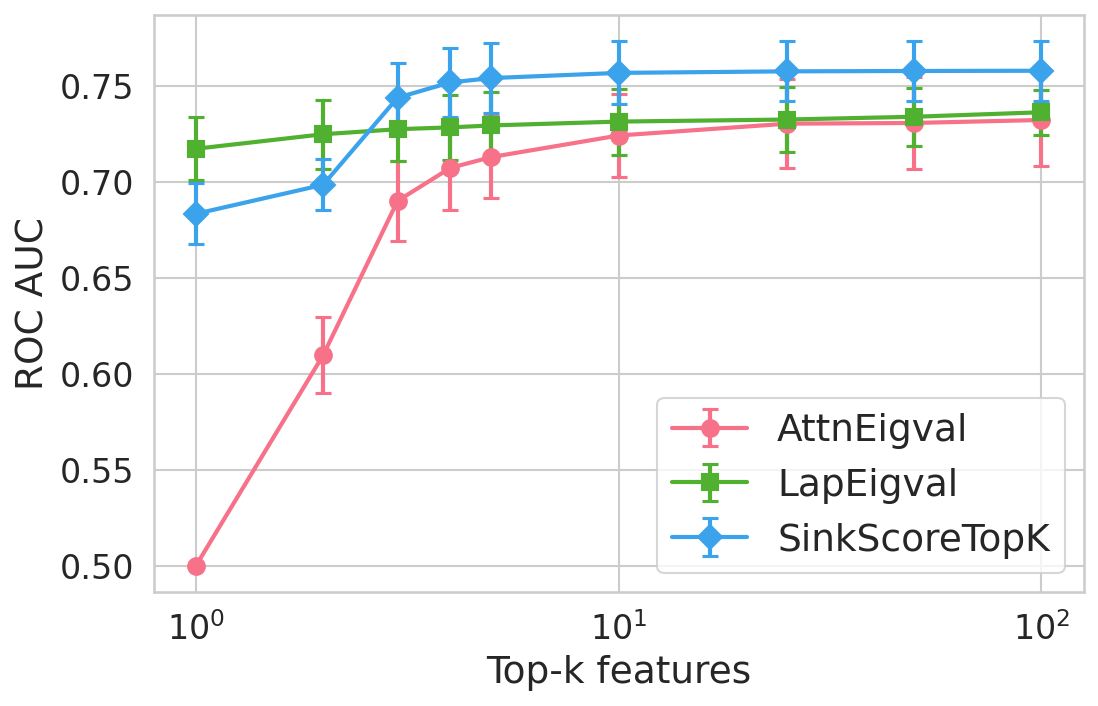
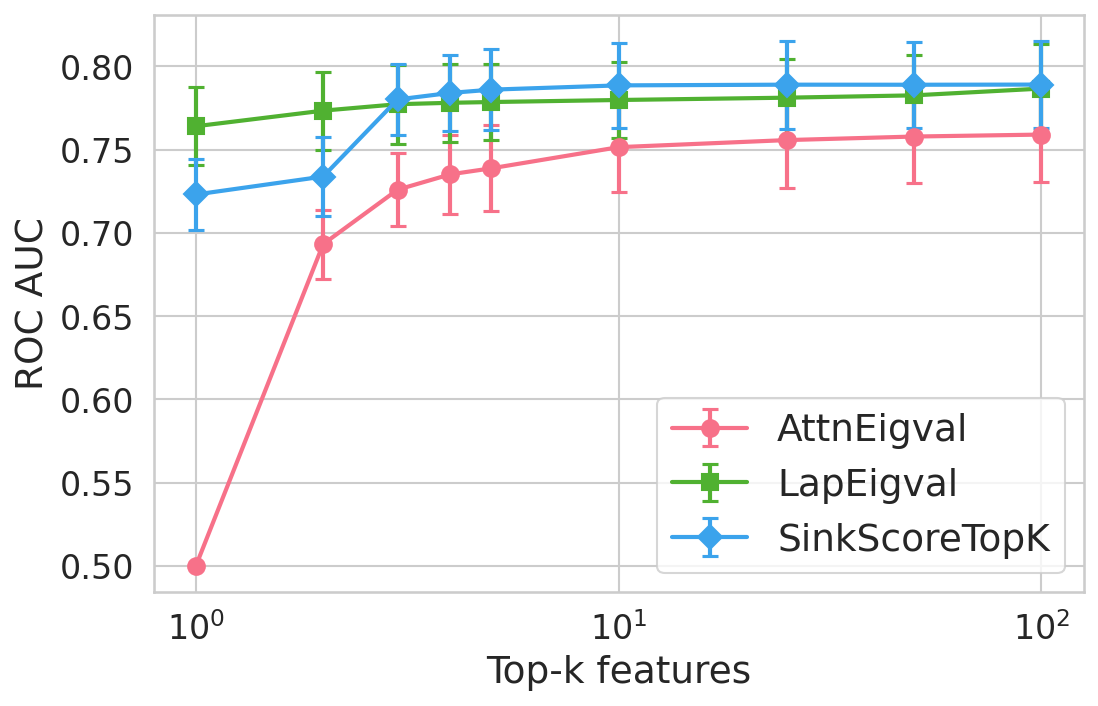
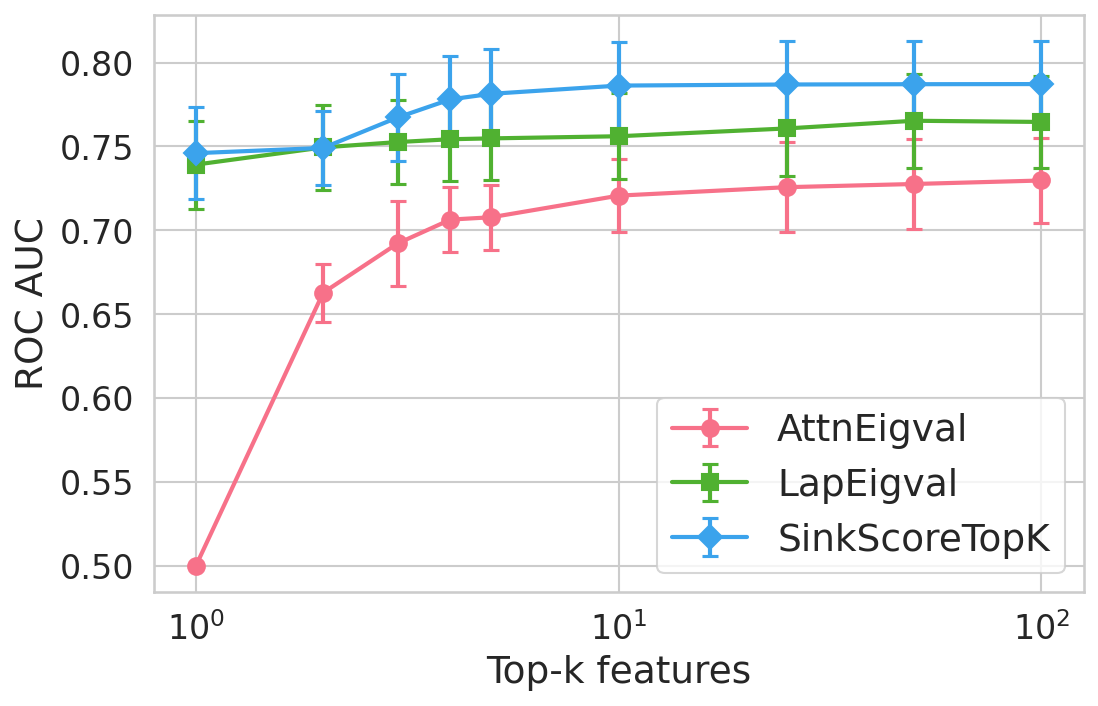
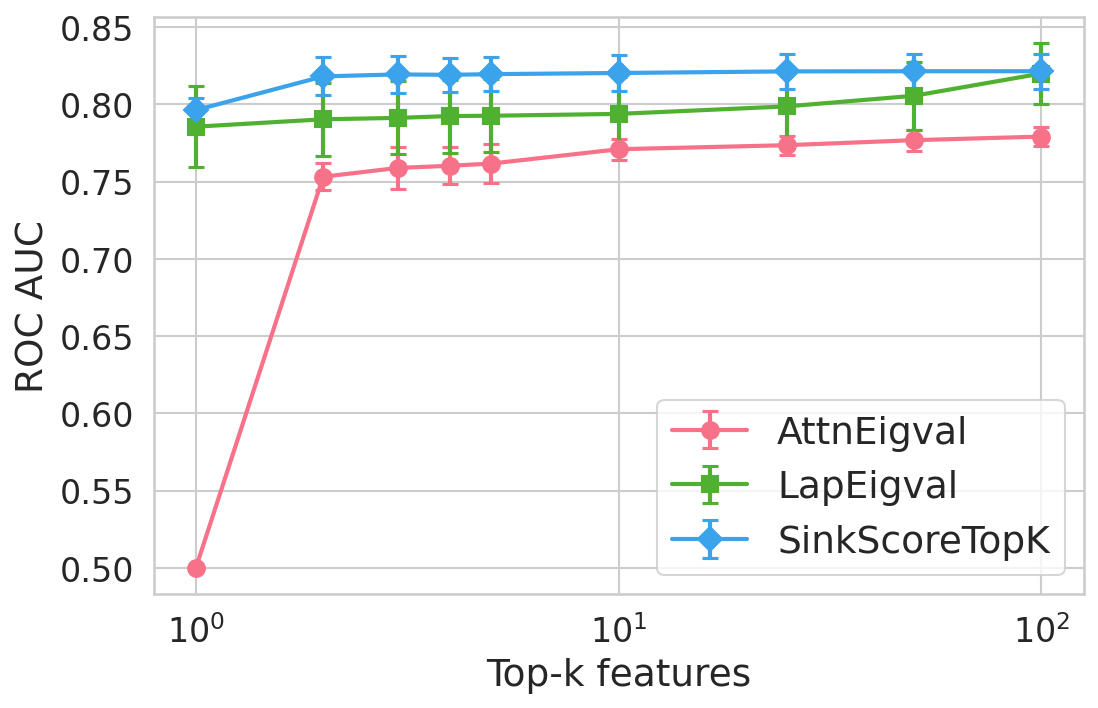
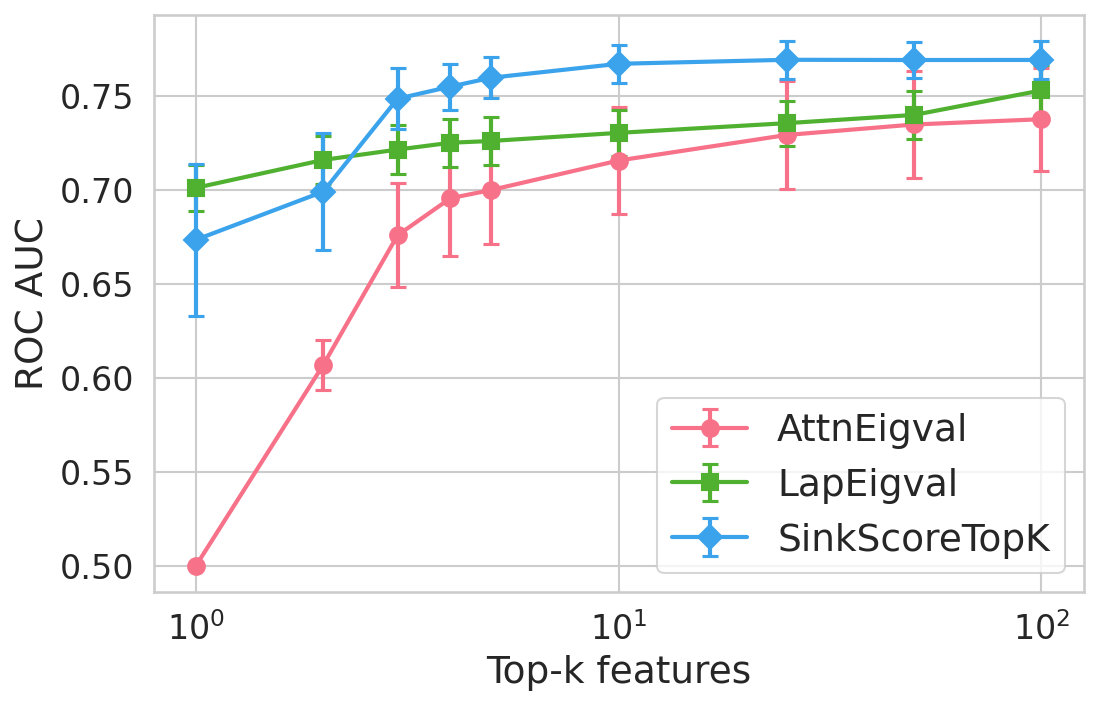
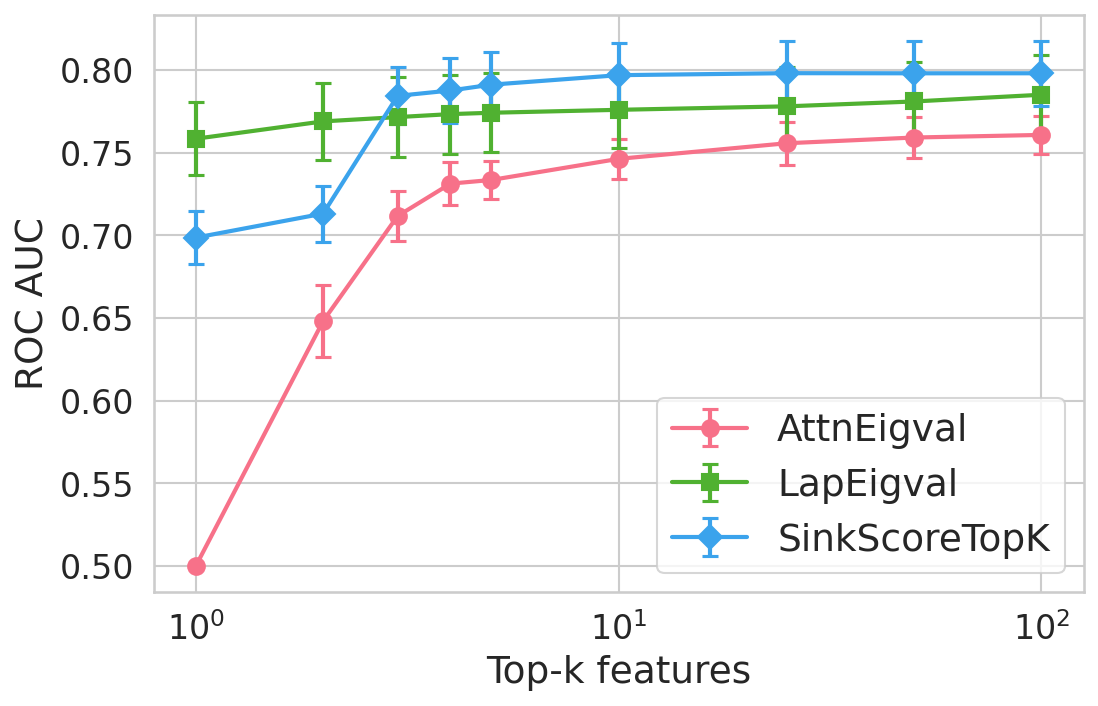
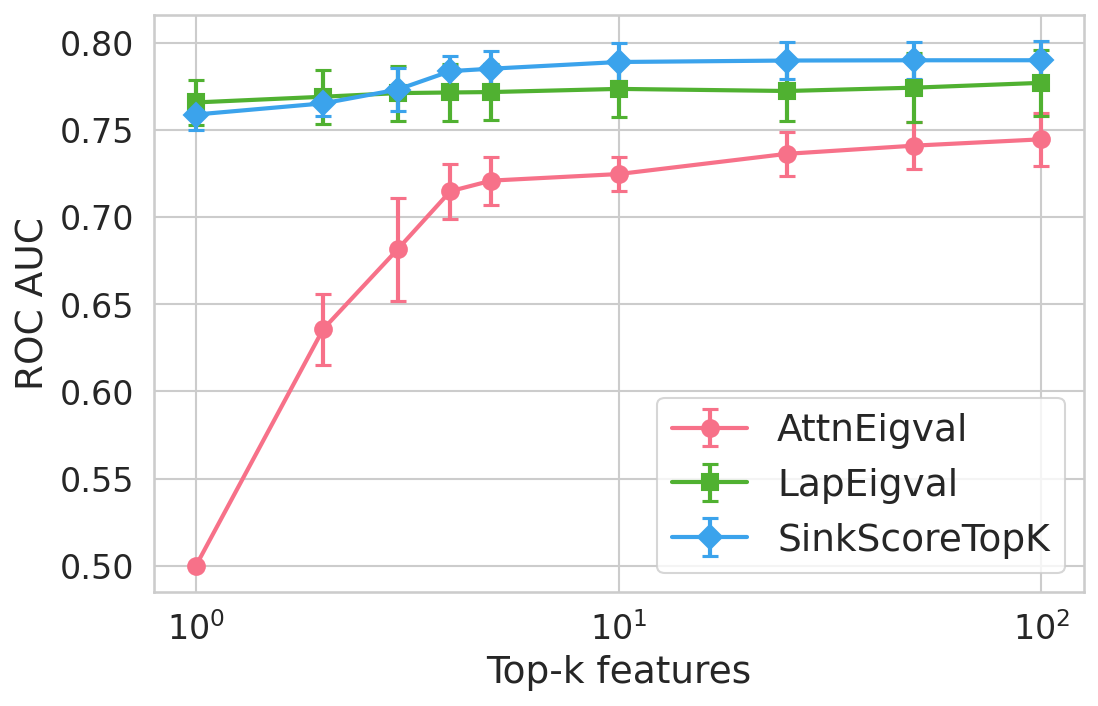
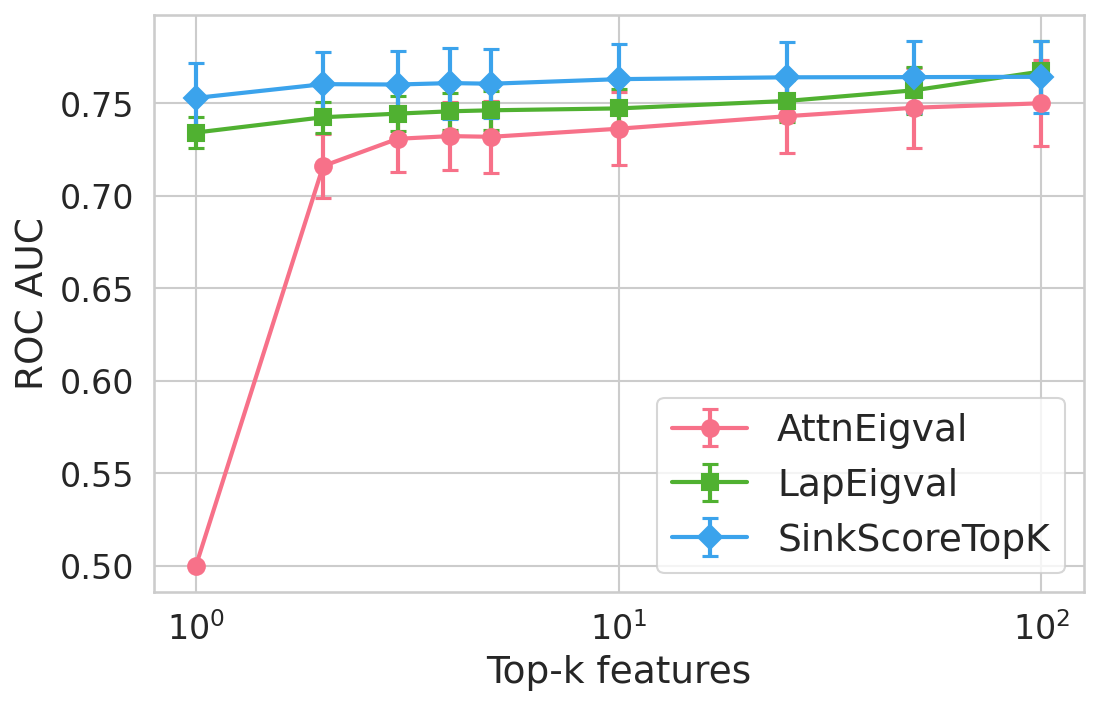
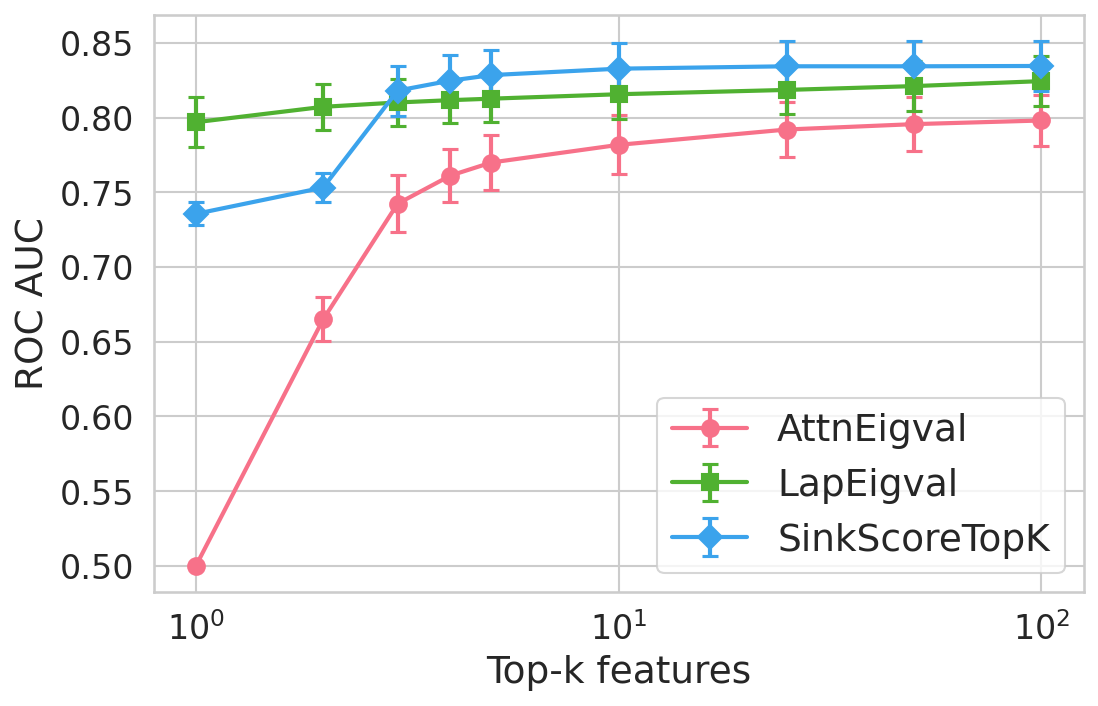
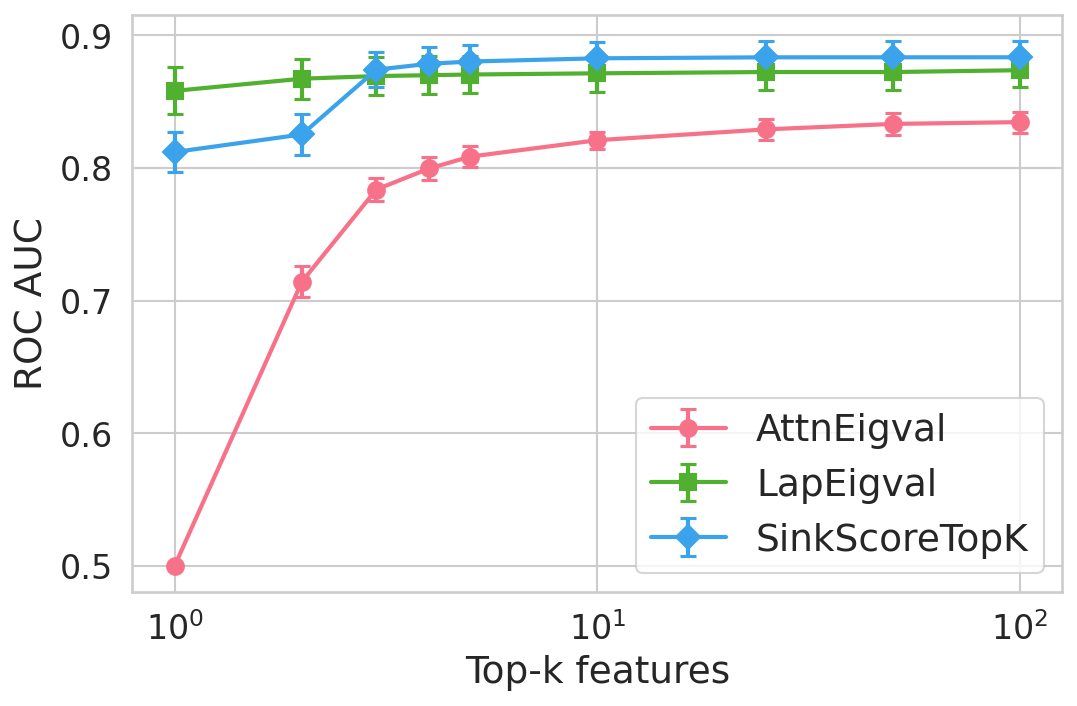
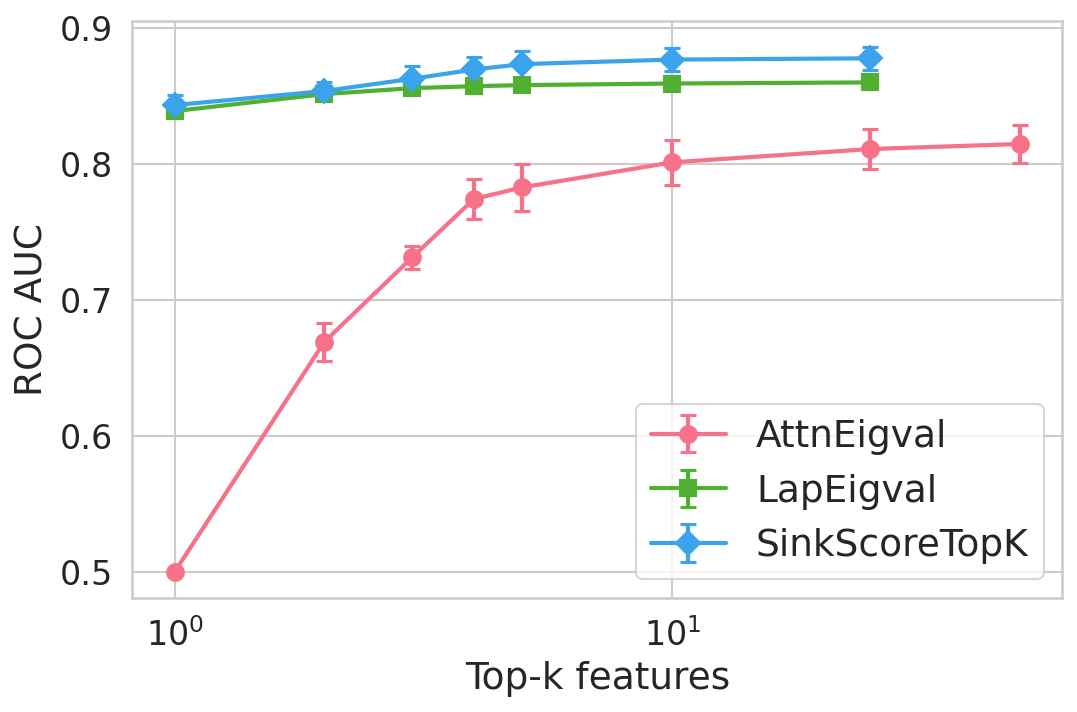
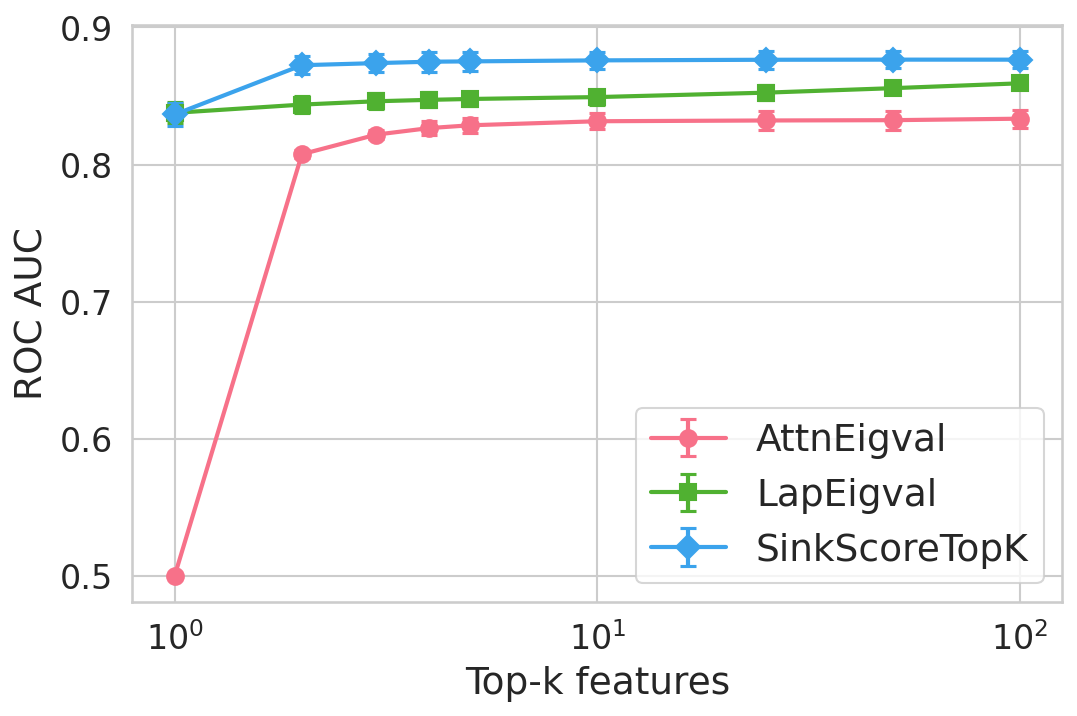
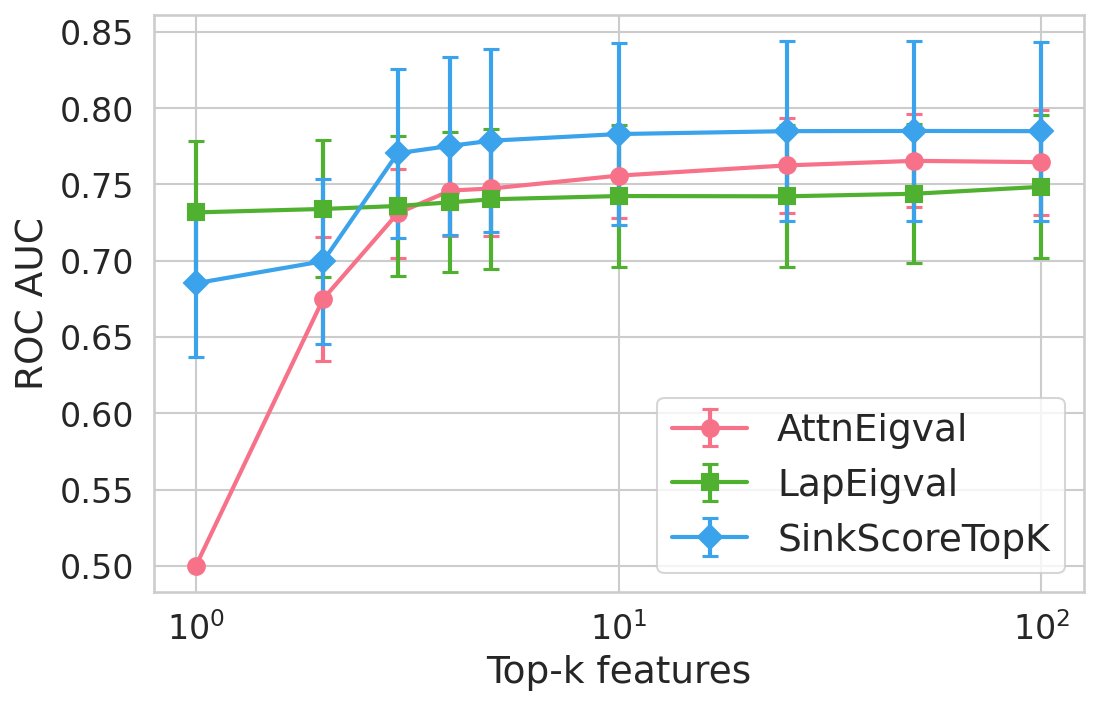
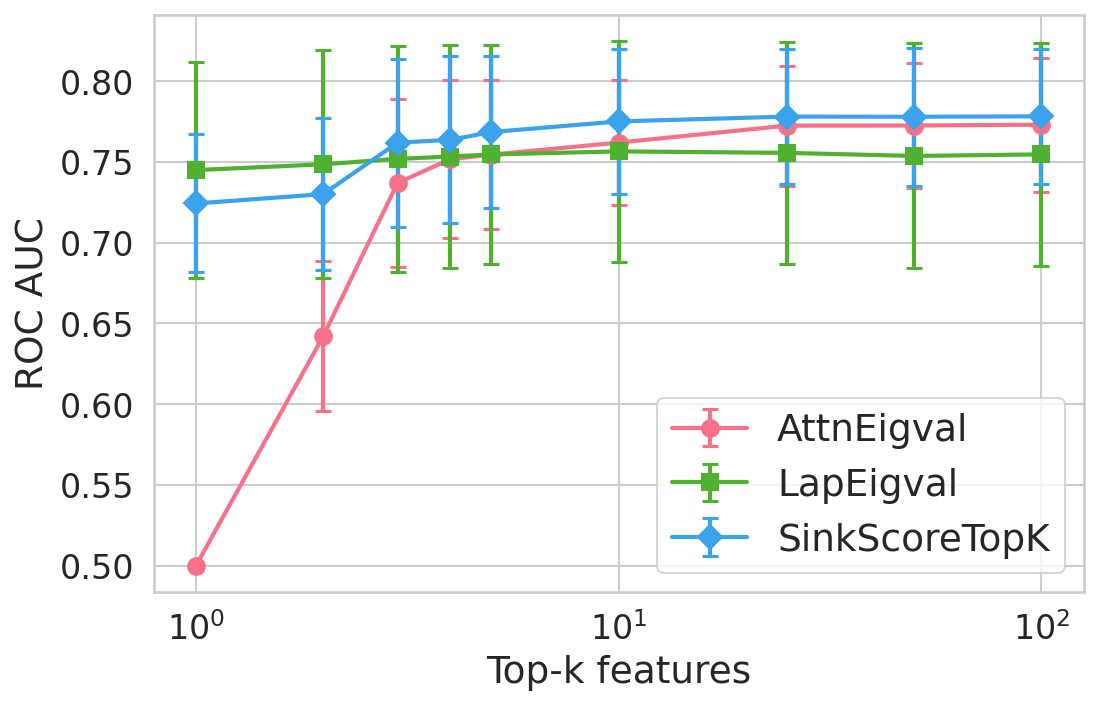
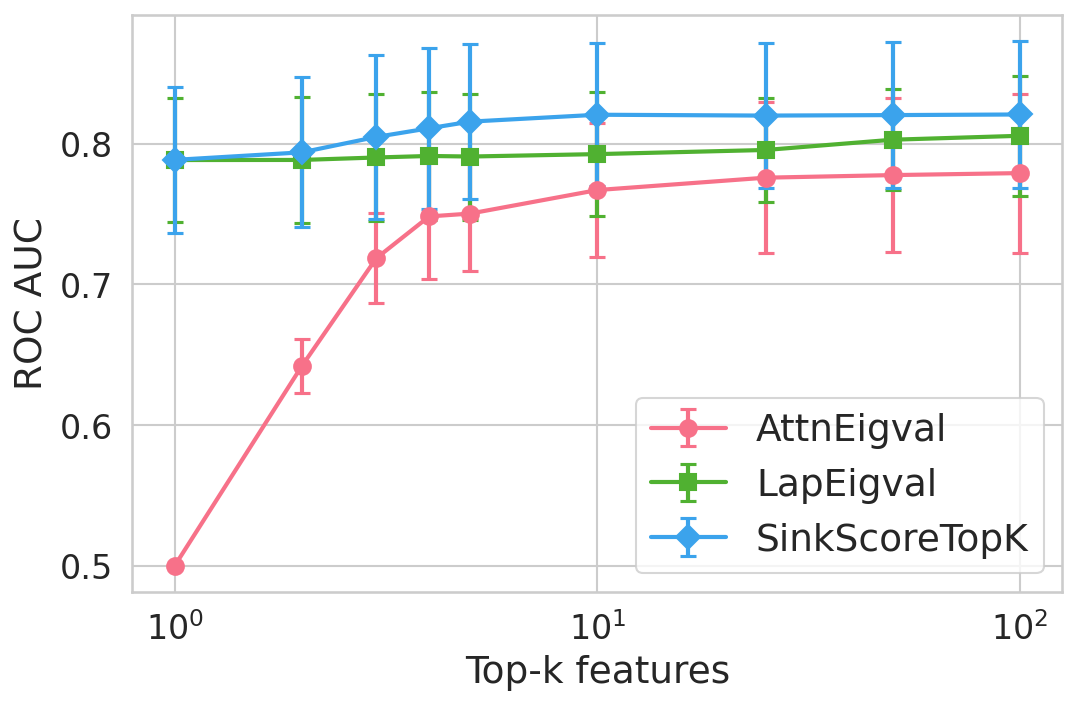
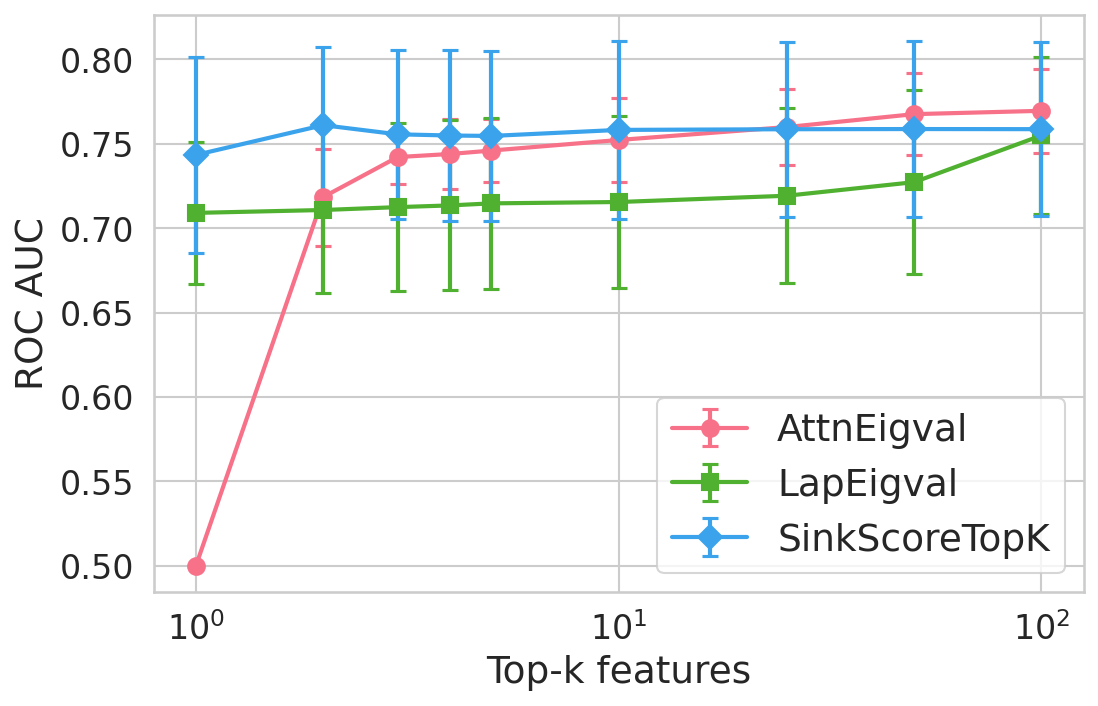
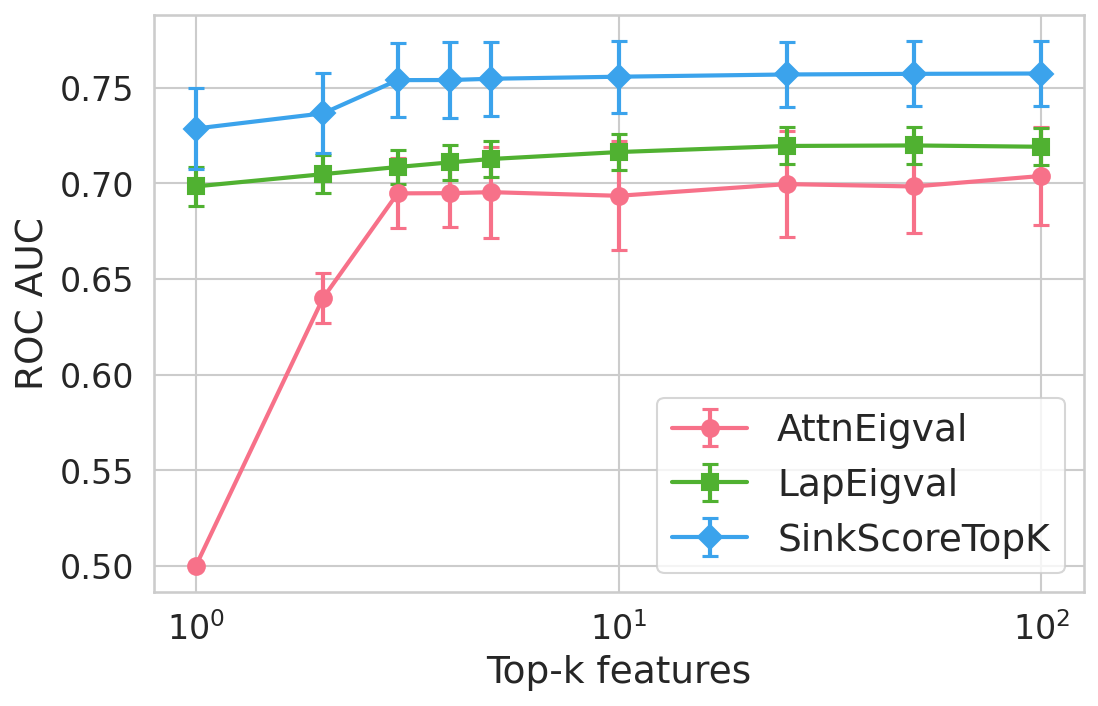
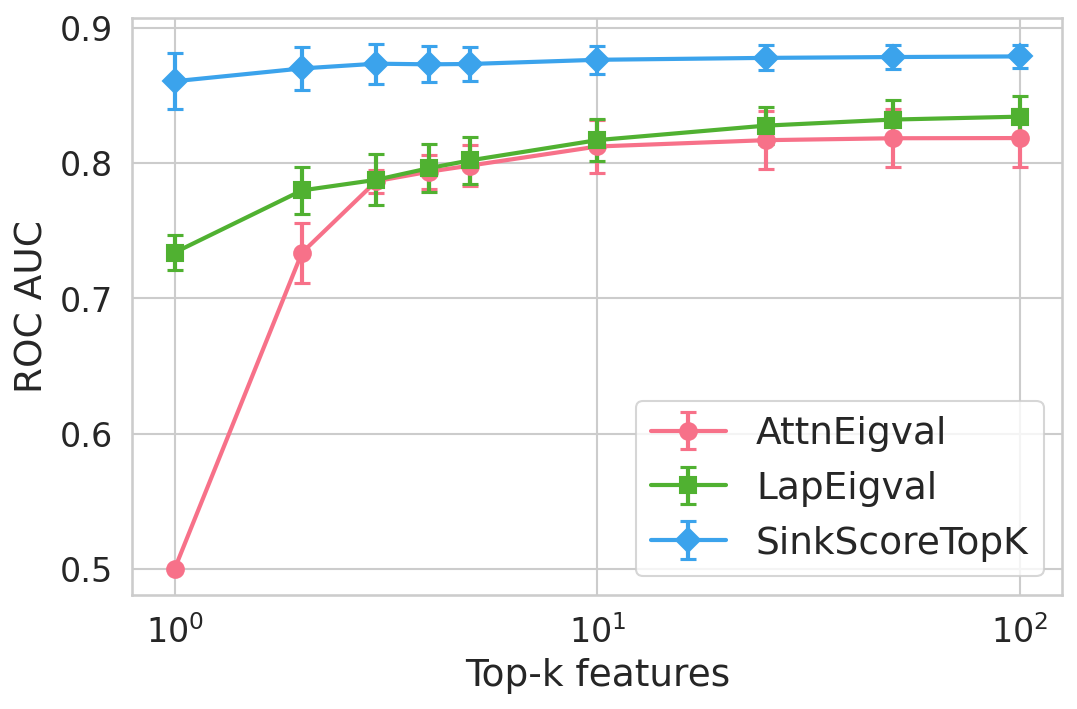
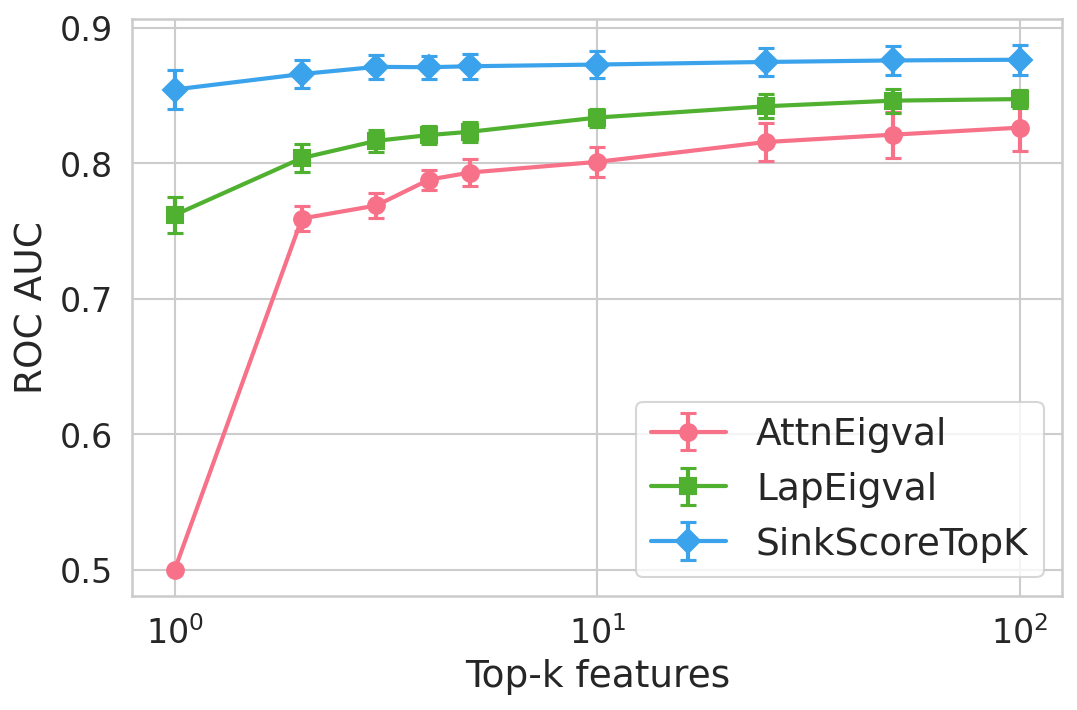
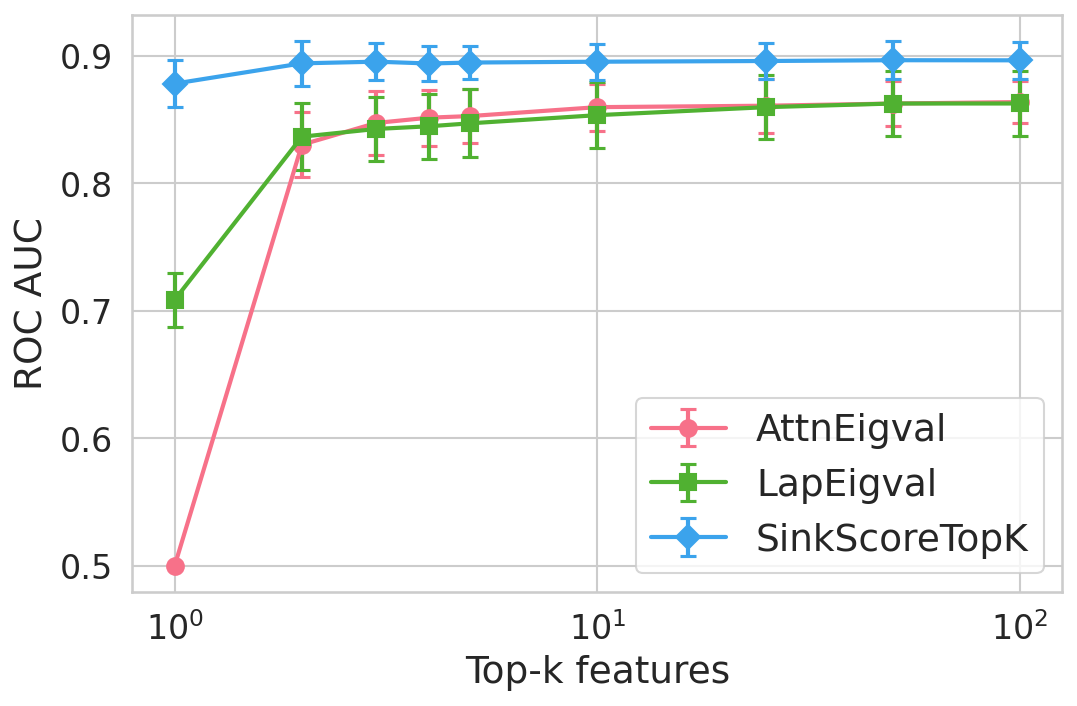
Figure 4: Hallucination detection performance (ROC-AUC) as a function of retained top-h6 sink scores, showing that few (top-h7) sinks suffice for maximal detection performance.
Feature importance analysis via h8 regularization and SHAP values reveals that only h9–k0\% of available sink-score-derived features are consistently selected, predominantly from heads and layers responsible for over-mixing or compression.
Theoretical and Practical Implications
The study provides strong evidence that hallucinations in modern LLMs originate in the internal attention dynamics—specifically anomalous formation of computationally dominant attention sinks in mid-to-late transformer layers. This reframes hallucination as a mechanism failure (collapse to prior-dominated representations), not just a knowledge deficit.
By formalizing and exploiting attention sinks, SinkProbe offers an efficient, interpretable, and model-agnostic hallucination detection tool requiring only access to attention weights, not external corpora, model logits, or generation sampling. This facilitates efficient deployment in settings where model internals can be inspected during inference (e.g., research, auditing, or applications built atop open-weight LLMs).
The underlying mechanistic perspective is compatible with, and clarifies, the weak supervision signal utilized by spectral, entropy-based, or graph-based detectors. Furthermore, classifiers utilizing sink scores are localized, sparse, and readily interpretable, supporting post-hoc diagnostics and targeted model interventions.
Limitations and Future Directions
A key limitation is the requirement for access to raw attention maps; scalable deployment in production requires efficient kernel-level support to extract and cache attention activations. Causality is not established—sink scores are correlates, not proven drivers, of hallucination. Future work includes testing whether direct intervention (e.g., sink regularization or targeted ablation of heads identified as important) can mitigate hallucination without impairing accuracy, and extending this line of analysis to larger, instruction-tuned, or multilingual models.
Conclusion
SinkProbe establishes attention sinks as a unifying internal signal for hallucination detection in LLMs, outperforming prior attention- and spectral-based detectors across models and tasks. The results suggest a direct connection between localized attention collapse and the emergence of ungrounded, hallucinated generations, providing an interpretable, practical tool for robust oversight of generative LLMs and a foundation for future mechanistic and causal interpretability work.
(2604.10697)