Attention Sinks in Diffusion Language Models
Abstract: Masked Diffusion LLMs (DLMs) have recently emerged as a promising alternative to traditional Autoregressive Models (ARMs). DLMs employ transformer encoders with bidirectional attention, enabling parallel token generation while maintaining competitive performance. Although their efficiency and effectiveness have been extensively studied, the internal mechanisms that govern DLMs remain largely unexplored. In this work, we conduct an empirical analysis of DLM attention patterns, focusing on the attention sinking phenomenon, an effect previously observed in various transformer-based architectures. Our findings reveal that DLMs also exhibit attention sinks, but with distinct characteristics. First, unlike in ARMs, the sink positions in DLMs tend to shift throughout the generation process, displaying a dynamic behaviour. Second, while ARMs are highly sensitive to the removal of attention sinks, DLMs remain robust: masking sinks leads to only a minor degradation in performance. These results provide new insights into the inner workings of diffusion-based LLMs and highlight fundamental differences in how they allocate and utilize attention compared to autoregressive models.
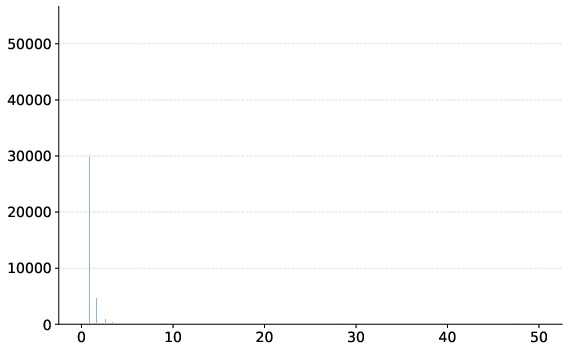
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how a special “attention” behavior shows up inside a new kind of LLM called a Diffusion LLM (DLM). The authors look at a phenomenon known as an “attention sink,” where some positions in a text grab a lot more attention than others. They compare how these “attention sinks” behave in DLMs versus the more common Autoregressive Models (ARMs), which generate text one word at a time.
What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- Do Diffusion LLMs also have attention sinks?
- If they do, how do these sinks behave while the model is generating text?
- What happens to the model’s performance if you block or remove these sinks?
How did they study this?
To keep things clear, think of “attention” like a spotlight in a theater: at any moment, the model shines its spotlight on the most important parts of the text to decide what to write next.
Here’s the big picture, with everyday analogies:
- Autoregressive Models (ARMs): Imagine writing a story from left to right, one word at a time. Each new word depends mainly on the words before it.
- Diffusion LLMs (DLMs): Instead of writing word by word, imagine starting with a fully blurred sentence and slowly “unblurring” the words in several passes. At each pass, the model looks at the entire sentence (left and right) to decide which words to reveal.
What they did:
- They examined three large, open-source DLMs: LLaDA-8B, Dream-7B, and MMaDA-8B.
- They visualized and measured attention across the text during generation (like heatmaps showing where the spotlight goes).
- They introduced a simple rule to detect “attention sinks”: tokens that consistently receive much more attention than the rest in a given step.
- They tested what happens if they “mask” (block) the sinks and then measured how well the models perform on math problems (GSM8K) and coding tasks (HumanEval).
Key terms explained:
- Attention: The model’s way of focusing on the most relevant parts of the text.
- Attention sink: A token (like a punctuation mark or special symbol) that acts like a magnet for attention—many other tokens look at it.
- Bidirectional attention: The model can look both left and right in the sentence at the same time.
- Diffusion/denoising: Starting from a masked or noisy sentence and gradually recovering the correct words over multiple steps.
What did they find, and why does it matter?
Main findings:
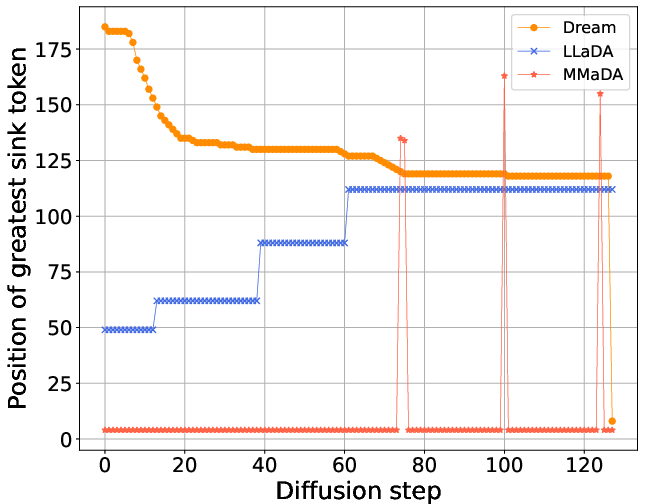
- DLMs do have attention sinks, but they are different from ARMs:
- In ARMs, sinks are more “static” (they usually sit in fixed positions and stay there).
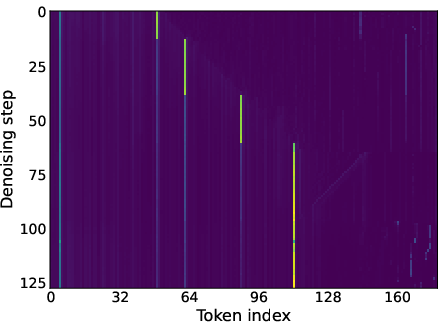
- In DLMs, sinks often move around during the denoising process. The “magnet” shifts position as the model uncovers more of the text.
- These moving sinks can be based on meaning and structure:
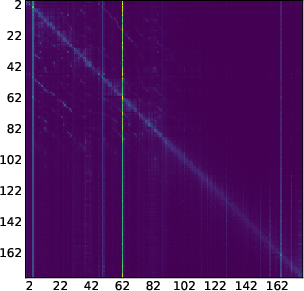
- LLaDA-8B often forms sinks on punctuation, whitespace, or end-of-sequence tokens—meaningful anchors in the text.
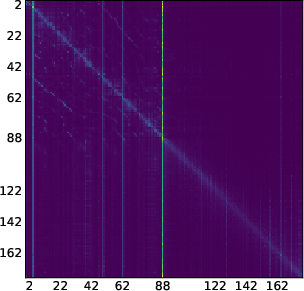
- Dream-7B’s sinks tend to slide from right to left, suggesting a strong positional pattern (likely because it was initialized from an ARM).
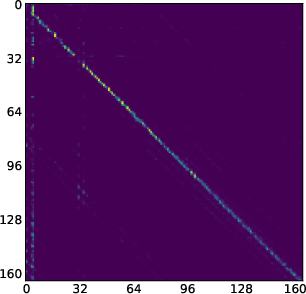
- MMaDA-8B’s sinks are usually more stable and sometimes sit at the start of the sequence.
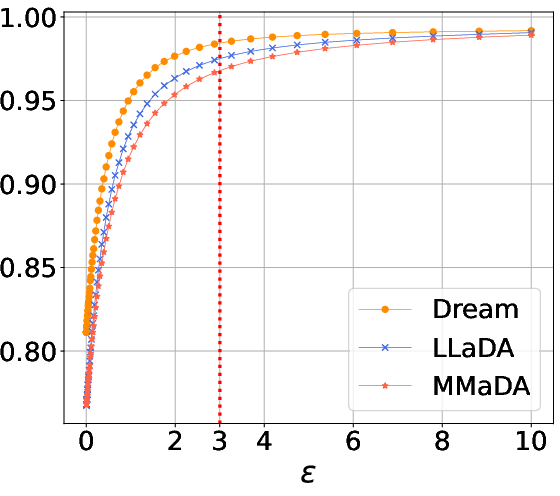
- DLMs are surprisingly robust if you block their attention sinks:
- When the authors masked sink tokens, DLMs lost only a small amount of performance.
- In contrast, masking sinks in a standard ARM (like Llama-3.1-8B) caused a big performance drop—even when blocking just one sink.
Why this matters:
- It shows that DLMs spread their attention more flexibly, relying less on single “anchor” tokens. That could make them more stable during generation.
- Moving sinks may help DLMs handle long texts better, because important tokens can become attention anchors wherever they are needed, not just at the beginning.
What could this change or inspire next?
Implications:
- Better understanding: This work helps researchers peek inside DLMs to see how they “think,” which can guide future improvements.
- Robustness: Because DLMs don’t depend on one fixed sink, they may be safer to use with long contexts or when parts of the text need to be removed or skipped.
- Efficiency opportunities: If we know where sinks form and how they move, we might compress or speed up models by focusing compute on these key anchors.
- Long-context reasoning: Dynamic, moving sinks might help DLMs plan and reason across long documents better than ARMs that rely on a single, static reference point.
In short, the paper shows that diffusion-based LLMs organize attention in a more flexible way than traditional models. They have attention sinks, but these sinks move and adapt—and the models don’t fall apart if you remove them. This could make DLMs a promising direction for future, more robust and efficient language modeling.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Scope of models: results are limited to three 7–8B instruct DLMs; no analysis of base (non-instruct) checkpoints, smaller/larger scales, or scaling trends of sink behavior with model size and depth.
- Multimodal coverage: MMaDA-8B is evaluated only on text tasks; sink dynamics with image/video tokens and cross-modal attention routing remain untested.
- Task breadth: robustness claims are supported only by GSM8K and HumanEval; effects on general NLG quality, factual QA, instruction following, multi-turn dialogue, and multilingual generation are unknown.
- Long-context claims: no controlled experiments on very long sequences (e.g., >32k tokens), memory truncation, or streaming settings to test whether moving sinks truly mitigate prefix dropping harms relative to ARMs.
- Metric design and sensitivity: the sink identification relies on a cumulative-attention threshold with ε=3; sensitivity analyses across ε values, per-layer/per-head definitions, sequence length, and prompt distributions are not systematically reported.
- Movement tracking: “moving sink” detection uses “largest sink per step” heuristics; there’s no formal tracking method (e.g., identity matching across steps/heads/layers) or stability statistics (e.g., persistence, velocity, reappearance rates).
- Masking protocol clarity: it is unclear whether sink masking targets specific layers/heads or all of them, and whether masking is static or re-applied each step; ablations on where (layer depth), when (early/late denoising), and how (partial vs zeroing) to mask are missing.
- Causal drivers of robustness: the hypothesis that bidirectionality and selective unmasking cause robustness to sink removal is not causally tested; needed are interventions such as:
- disabling bidirectionality (applying a causal mask) in DLMs,
- varying block sizes/unmasking policies,
- altering denoising schedules and numbers of steps,
- comparing against DLMs trained with different corruption schedules.
- Positional encoding effects: differences between Dream-7B (ARM-initialized) and LLaDA-8B (from-scratch) are attributed to positional/initialization biases, but there is no controlled ablation across positional encodings (RoPE vs absolute/alibi) or matched-from-scratch vs ARM-initialized models.
- Mechanistic properties: known ARM sink correlates (hidden state L2 norms, key/value norms, frequency effects) are cited but not measured for DLMs; quantify whether DLM sinks share these geometric/statistical signatures.
- Token-type correlates: the “semantic” tendency (punctuation, whitespace, EOS) is described qualitatively; quantify correlations between sink incidence and token types, frequency, subword boundaries, or tokenizer variants across languages and scripts.
- Training-time emergence: sink evolution during training is unstudied; track when sinks appear, how they change across epochs, and how training objectives (e.g., denoising schedules, loss weighting, data mixtures) alter sink dynamics.
- Reproducibility and variance: results depend on specific prompts and seeds; report variability across datasets, prompts, seeds, and random initializations, and address the inability to reproduce MMaDA-8B’s reported performance.
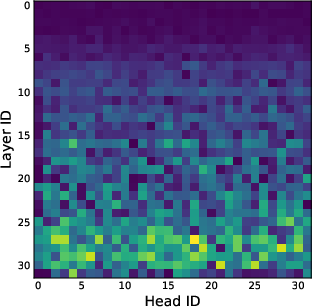
- Head specialization and redundancy: which heads/layers carry sinks, how redundant they are, and whether sink-prone heads are necessary for performance has not been tested; perform head dropout/pruning and per-head masking ablations.
- Depth-wise organization: evidence suggests fewer sinks in deeper layers for LLaDA-8B, but no general depth-wise patterns across models/sequences are quantified; characterize layerwise sink counts, intensity distributions, and inter-layer coordination.
- Interaction with decoding hyperparameters: no study of how sink behavior and masking robustness vary with diffusion step count, temperature, nucleus/top-p for unmasking, block size, or sampling strategies.
- Generalization to other DLM families: results may not transfer to alternative discrete diffusion designs (e.g., SEED, Inception-style, different corruption schedules) or continuous diffusion LMs; broaden evaluation across architectures.
- Quantifying behavioral impact: besides accuracy/pass@k, effects on fluency, coherence, latency, and calibration (e.g., token-level confidence shifts when masking sinks) are not measured; evaluate calibration and unmasking distributions under interventions.
- Theoretical grounding: there is no formal model connecting sink movement to the Markov reverse process; develop theory for how iterative denoising and bidirectional attention induce dynamic reference points and under what conditions they stabilize.
- Practical utility: potential acceleration/compression from sinks (e.g., KV cache pruning, attention routing) in DLMs is not explored; implement and benchmark sink-aware compute/memory optimizations analogous to StreamingLLM for ARMs.
- Safety and robustness: the susceptibility of DLM sink dynamics to adversarial prompts or distribution shift is unknown; test whether manipulating sink tokens degrades reasoning or induces failure modes.
- Multilingual and non-Latin scripts: sink patterns in languages with different punctuation, morphology, or tokenization characteristics (e.g., CJK, agglutinative languages) are unexamined; run cross-lingual analyses to test the “semantic anchor” hypothesis.
- Tokenization dependence: influence of tokenizer choices (BPE vs unigram, vocabulary size) on sink location/intensity is not measured; conduct controlled re-tokenization studies.
- Beyond top-10 masking: re-formation and re-routing of sinks when aggressively masking many candidates across steps/layers is unexplored; test dynamic re-emergence and failure thresholds.
- Code release and benchmarks: analysis tooling and standardized sink-benchmark protocols are not provided; releasing code, seeds, and curated prompts would enable consistent comparison and replication.
Practical Applications
Practical Applications Derived from the Paper
Below is a structured mapping of actionable use cases stemming from the paper’s core findings: (1) attention sinks exist in diffusion LLMs (DLMs) but are more dynamic than in ARMs; (2) DLMs are surprisingly robust to masking/removing attention sinks; (3) moving sinks often align with semantic/structural tokens in some DLMs and with positional patterns in others; (4) implications for long-context, memory management, and interpretability; and (5) a concrete, reproducible sink-detection metric that operates over denoising steps.
Immediate Applications
- Sink-robustness evaluation and model selection
- Use case: Add “sink masking stress tests” to model evaluation pipelines to quantify robustness to attention ablation (already demonstrated for GSM8K/HumanEval in paper).
- Sectors: Software/AI platforms, Cloud providers, Academia.
- Tools/workflows: Plugin for lm-eval-harness to mask top-k sinks at inference and report metric deltas; CI gating for model promotion based on sink robustness.
- Assumptions/dependencies: Access to attention matrices; evaluation datasets; reproducible inference settings.
- Inference monitoring and anomaly detection via sink tracking
- Use case: Track sink intensity and location across denoising steps to detect anomalies (e.g., distribution shifts, prompt injections altering attention organization).
- Sectors: Cloud AI ops, Enterprise AI governance, Safety.
- Tools/products: “SinkScope” dashboards logging per-head cumulative sink scores and displacement over steps; alerts on out-of-profile sink dynamics.
- Assumptions/dependencies: Hooks to extract attention scores; stable baselines for “normal” sink profiles per task/model.
- Memory-aware serving policies for DLMs
- Use case: Because DLMs are less reliant on fixed sinks and are robust to masking, safely implement bounded-context or sliding-window serving (discarding oldest segments) with smaller performance hits than ARMs.
- Sectors: Cloud serving, On-device/edge assistants, Productivity apps.
- Products/workflows: “DLM Sliding Window Inference” presets; context eviction policies tested with sink-masking stress; service-level cost reductions.
- Assumptions/dependencies: Task tolerates small performance drops; availability of DLMs (e.g., LLaDA, Dream) and integration with existing serving stacks.
- Interpretability and debugging for diffusion decoders
- Use case: Use the paper’s sink metric to probe per-layer/head dynamics, identify semantically grounded sinks (punctuation, EoS) vs positional sinks, and compare training regimens (from scratch vs ARM-initialized).
- Sectors: Research/Academia, Model developers, Enterprise ML teams.
- Tools: Lightweight library functions to compute ; heatmap visualizations; layer/head reports.
- Assumptions/dependencies: Encoder-only DLM architecture with bidirectional attention; attention access.
- Dataset and prompt design informed by dynamic sinks
- Use case: Since certain models form sinks on punctuation and structural tokens, tune prompts and data formatting to reinforce stable anchors (e.g., consistent paragraphing, list markers) to improve reasoning stability.
- Sectors: Education technology, Documentation tooling, Enterprise knowledge systems.
- Workflows: “Sink-aware” style guides for prompt and dataset formatting; automatic post-processors to add structural markers.
- Assumptions/dependencies: Observed behavior generalizes across content domains; minimal latency overhead.
- Multi-model comparison and governance checklists
- Use case: Use sink robustness as a procurement criterion for regulated settings (where safe context truncation and graceful degradation matter).
- Sectors: Policy, Legal/Compliance, Public sector.
- Tools: Audit templates including sink-masking deltas, sink displacement variability, and performance-degradation thresholds.
- Assumptions/dependencies: Access to model internals or lab-grade evaluations by vendors.
- IDE and coding assistant deployments with bounded memory
- Use case: For code generation, prioritize DLMs where acceptable to trade a small accuracy drop for reduced memory (e.g., CI runners, thin clients).
- Sectors: Software engineering, DevOps.
- Tools/products: “Sink-robust mode” toggles for code assistants; client-side inference fallback with sliding window.
- Assumptions/dependencies: Human-in-the-loop validation; task tolerance to minor accuracy losses.
- Educational modules on diffusion attention dynamics
- Use case: Integrate moving-sink visualizations to teach attention mechanisms beyond ARMs.
- Sectors: Higher education, Professional training.
- Tools: Teaching notebooks showing sink displacement across denoising steps.
- Assumptions/dependencies: Open-source DLM checkpoints; GPU credits for classroom demos.
Long-Term Applications
- Sink-aware acceleration and compression for DLMs
- Use case: Develop kernels and schedulers that downweight or skip compute for sink-targeted paths with minimal loss, leveraging demonstrated robustness to sink masking.
- Sectors: Systems/Inference optimization, Cloud providers, Hardware co-design.
- Products: FlashAttention-style variants with sink gating; attention-score clipping; head pruning policies guided by cumulative sink scores.
- Assumptions/dependencies: Custom kernels; thorough task-level validation to bound quality loss; generalization beyond evaluated tasks.
- Sink-informed long-context strategies
- Use case: Replace BOS-centric anchoring with moving sink anchors; implement sink-aware context truncation and future-anchor planning for long reasoning chains.
- Sectors: Finance, Legal, Healthcare (long documents), Research assistants.
- Products/workflows: “Sink-aware context eviction” and “future-anchor planning” options for long-context generation; RAG controllers that retain segments most attended by sinks.
- Assumptions/dependencies: Empirical validation on truly long sequences; risk analysis for high-stakes domains.
- Training-time regularization to shape sink behavior
- Use case: Introduce training objectives that encourage semantically meaningful, dynamic sinks (e.g., structural-token anchoring) or penalize overly static sinks.
- Sectors: Foundation model training, Academia.
- Products/workflows: Sink-regularized pretraining/finetuning; curriculum that varies structure markers; layer-wise constraints on sink concentration.
- Assumptions/dependencies: Controlled experiments to avoid hurting generalization; compatibility with diffusion schedules and block decoding.
- Safety and alignment controls via sink manipulation
- Use case: Guide generation using sink steering on structural tokens (e.g., enforce step-by-step reasoning anchors), or detect adversarial prompts that force abnormal sink profiles.
- Sectors: Safety/alignment, Policy compliance, Enterprise security.
- Products: “SinkGuard” that monitors/steers sink formation; policy engines that block outputs under anomalous sink dynamics.
- Assumptions/dependencies: Robust correlations between sink patterns and harmful/benign behaviors; low false positives.
- Agent planning and multi-step reasoning aided by future sinks
- Use case: Exploit DLMs’ ability to form sinks at future positions to improve planning and long-horizon tasks (e.g., chain-of-thought with future anchors).
- Sectors: Autonomous research agents, Robotics planning, Operations research.
- Products/workflows: “Future-anchor” planners that coordinate denoising steps with plan checkpoints; integration with tree search or test-time scaling.
- Assumptions/dependencies: Verified gains over ARM baselines on complex planning; latency budgets compatible with iterative denoising.
- Multimodal sink-aware fusion
- Use case: In multimodal DLMs (e.g., MMaDA), learn stable anchors across modalities (text, layout, image regions), improving cross-modal grounding and memory usage.
- Sectors: Document AI, Media content generation, Healthcare imaging reports.
- Products: Sink-aware cross-attention bridges; layout-aware pretraining that promotes sinks on structural regions (titles, figure captions).
- Assumptions/dependencies: Strong multimodal datasets; attention interpretability across modalities; latency/compute budgets.
- Standardized evaluation benchmarks and policy guidance
- Use case: Include sink-masking robustness and sink-displacement variability in standard evals; policy frameworks that recommend sink-robustness thresholds for deployment in public services.
- Sectors: Policy, Standards bodies, Public procurement.
- Products: “SinkStress” benchmark suite; procurement checklist items (e.g., maximum allowed drop when masking top-1/top-5 sinks).
- Assumptions/dependencies: Community adoption; transparency from vendors; repeatable protocols.
- Edge and mobile DLM deployments
- Use case: Leverage sink robustness for aggressive context truncation and compute shedding to fit DLMs on-device for writing assistants, reading aids, and offline summarizers.
- Sectors: Consumer apps, Accessibility tech.
- Products: On-device diffusion assistants with sink-aware memory budgets; offline document summarizers with bounded RAM.
- Assumptions/dependencies: Efficient DLM architectures; acceptable latency for iterative denoising; hardware acceleration.
- Hardware–algorithm co-design
- Use case: Architect caches and memory controllers that prioritize dynamic sink tokens or deprioritize masked-sink paths to reduce bandwidth.
- Sectors: Semiconductors, Accelerators.
- Products: Sink-aware attention engines; compiler passes that schedule compute around sink dynamics.
- Assumptions/dependencies: ISA/compiler support; stable, predictable sink patterns across workloads.
Notes on feasibility: Most immediate applications rely on access to attention tensors and reproducible DLM inference (LLaDA-8B, Dream-7B, MMaDA-8B). Generalization to other DLMs, extreme long contexts, or high-stakes domains requires further validation. Long-term applications hinge on algorithm–systems co-design, standardized benchmarks, and evidence that sink-informed strategies consistently preserve quality across diverse tasks.
Glossary
- [BOS] token: Special beginning-of-sequence marker used in transformer inputs and contexts. "the oldest part, typically including the [BOS] token, must be discarded."
- [CLS] token: Special classification token used in encoder architectures as a positional anchor. "special markers like [CLS] or [EOS]"
- [EOS] token: Special end-of-sequence token marking the end of a generated sequence. "end-of-sequence tokens."
- [MASK] token: Special token representing masked positions to be predicted during diffusion or masked LM training. "Starting from fully masked sequences of [MASK] tokens"
- Absolute positional embeddings: Positional encoding scheme that assigns fixed embeddings to positions, independent of content. "connects this behaviour to the use of absolute positional embeddings"
- Attention head: One of multiple parallel subspaces in multi-head attention computing separate attention patterns. "For a single attention head and layer "
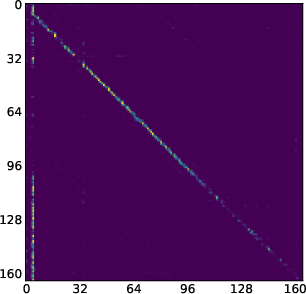
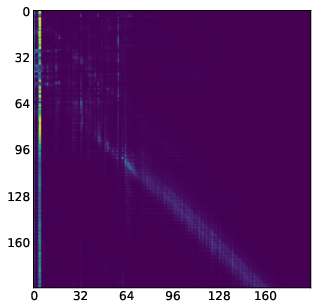
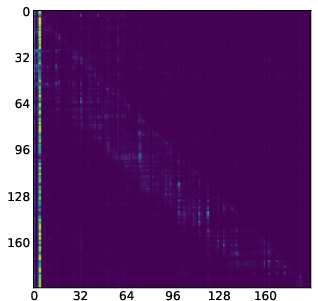
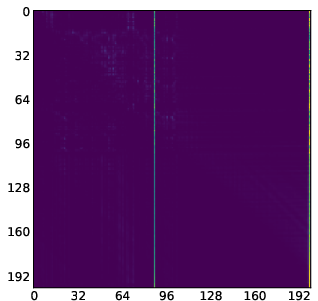
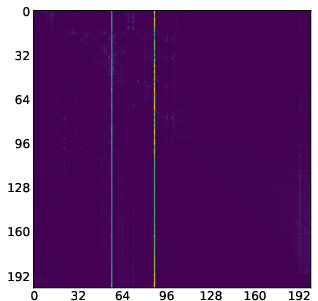
- Attention map: A visualization or matrix of attention scores showing which tokens attend to which others. "attention maps (like the one we show in \Cref{fig:llada_sink_first_page})."
- Attention sink: Tokens that consistently receive disproportionately high attention from other tokens. "One of the most striking traits of these behaviours is the "attention sink""
- Autoregressive Models (ARMs): Models that generate tokens sequentially, conditioning on previously generated tokens. "Unlike Autoregressive Models (ARMs), which generate text strictly from left to right"
- Bidirectional attention: Attention mechanism allowing tokens to attend to both past and future positions. "DLMs employ transformer encoders with bidirectional attention"
- Bidirectional information flow: The ability of encoder-style architectures to propagate information across the entire sequence in both directions. "this bidirectional information flow is key to their parallel, non-causal generation process"
- Causal mask: Attention masking that restricts each token to attend only to past tokens, enforcing autoregressive causality. "and the lack of a causal mask that limits the attention interaction among tokens."
- Cumulative attention score: The average amount of attention a token receives from all other tokens in a sequence at a given step. "we define the cumulative attention score for a token as the average attention it receives"
- Denoising steps: Iterations in diffusion generation where noise is reduced and tokens are progressively predicted/unmasked. "across denoising steps"
- Diffusion LLMs (DLMs): LLMs that generate text through a learned reverse denoising process over masked discrete tokens. "Masked Diffusion LLMs (DLMs) have recently emerged as a promising alternative"
- Encoder-only transformer: Transformer architecture using only encoder blocks (bidirectional attention) without a causal decoder. "Consider an encoder-only transformer model."
- Forward corruption process: The fixed process in diffusion that progressively masks/perturbs a clean sequence. "a fixed forward corruption process"
- Iterative denoising process: The learned reverse process in diffusion that incrementally reconstructs clean data from corrupted inputs. "offer token generation through an iterative denoising processes"
- Latent space: High-dimensional internal representation space in which models organize learned features. "the model's high-dimensional latent space."
- Logit Lens: Interpretability technique that projects intermediate activations to vocabulary logits to inspect model internals. "for instance using the Logit Lens"
- Marginal distribution: The distribution of a token at a time step, integrating over other variables or steps. "The marginal distribution of a token at time conditioned on its clean version"
- Markov diffusion process: A process assuming each step depends only on the previous one, applied to discrete token sequences in diffusion. "they model a Markov diffusion process over discrete token sequences."
- Markov transition: The step-wise probabilistic transition from one diffusion state to the next. "by a Markov transition ."
- Masking schedule: Time-dependent probability controlling how likely tokens are masked during the forward process. "is defined by a masking schedule ."
- Mechanistic analysis: A methodical interpretability approach aimed at explaining model internals and circuits. "A promising direction to investigate this would be a mechanistic analysis"
- Moving sink: Attention sink whose position changes across denoising steps rather than remaining fixed. "we identify a new kind of attention sinks that we call moving sinks."
- Over-squashing: Phenomenon where too much information is compressed through limited network pathways, hindering long-range dependencies. "can mitigate information over-squashing."
- Representation collapse: Degenerate state where learned representations lose diversity and become indistinguishable. "avoid representation collapse"
- Rotary Positional Embeddings (RoPE): Positional encoding that rotates query/key vectors to encode relative positions. "Rotary Positional Embeddings~(RoPE, ~\citealt{rope})"
- Semi-autoregressive block decoding: Decoding strategy that unmask/predict tokens in blocks, partially following left-to-right order. "perform semi-autoregressive block decoding"
- Semi-autoregressive block diffusion: Inference procedure for DLMs that denoises and unmasks tokens block-wise across steps. "use semi-autoregressive block diffusion"
- Semi-autoregressive block generation: Variant of block-wise generation used in some models, contrasted with fully autoregressive decoding. "does not use semi-autoregressive block generation"
- Sink masking: Intervention that masks attention to identified sink tokens during generation. "masking sinks leads to only a minor degradation in performance."
- Sink token: A token identified as receiving significantly higher cumulative attention than others. "we formally define a token ... to be a sink token"
- Unmasking: The act of revealing and fixing tokens’ identities during diffusion generation. "gradually unmasking tokens inside each block"
Collections
Sign up for free to add this paper to one or more collections.

