Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
Abstract: As the foundational architecture of modern machine learning, Transformers have driven remarkable progress across diverse AI domains. Despite their transformative impact, a persistent challenge across various Transformers is Attention Sink (AS), in which a disproportionate amount of attention is focused on a small subset of specific yet uninformative tokens. AS complicates interpretability, significantly affecting the training and inference dynamics, and exacerbates issues such as hallucinations. In recent years, substantial research has been dedicated to understanding and harnessing AS. However, a comprehensive survey that systematically consolidates AS-related research and offers guidance for future advancements remains lacking. To address this gap, we present the first survey on AS, structured around three key dimensions that define the current research landscape: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation. Our work provides a pivotal contribution by clarifying key concepts and guiding researchers through the evolution and trends of the field. We envision this survey as a definitive resource, empowering researchers and practitioners to effectively manage AS within the current Transformer paradigm, while simultaneously inspiring innovative advancements for the next generation of Transformers. The paper list of this work is available at https://github.com/ZunhaiSu/Awesome-Attention-Sink.
First 10 authors:























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
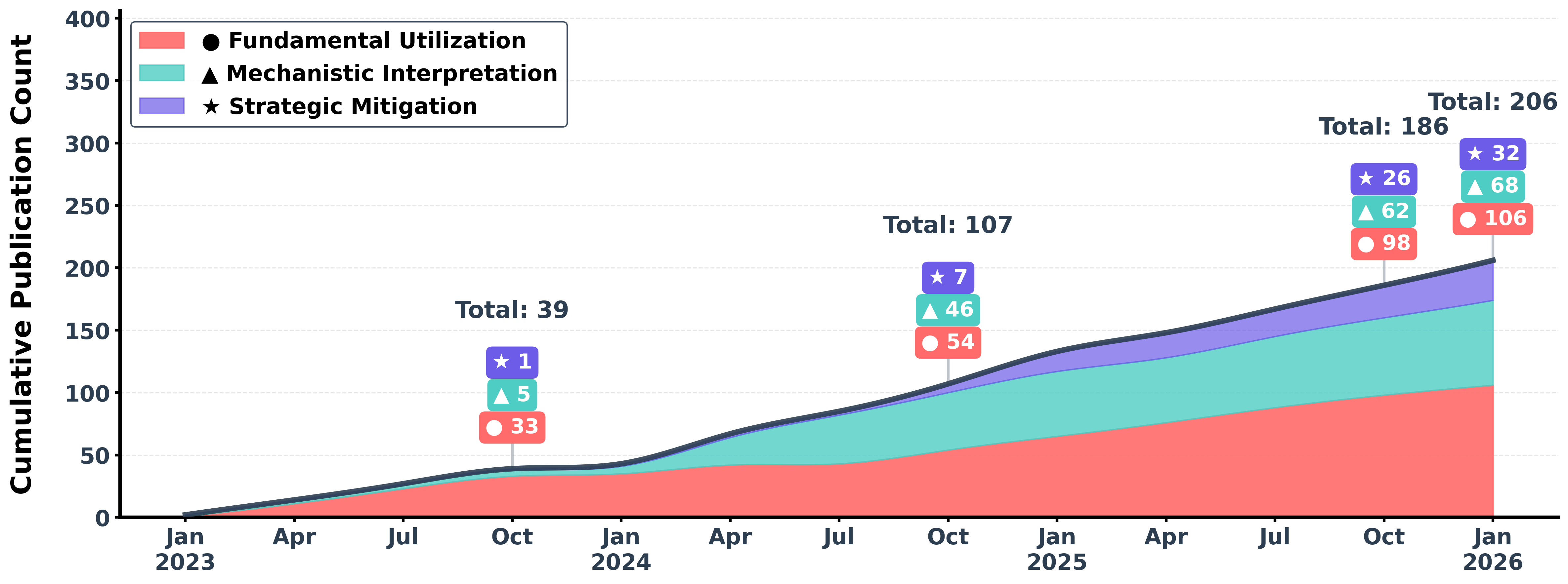
This paper is a big “map” of a tricky behavior in Transformer models (the kind of AI behind tools like chatbots and image analyzers) called attention sink. An attention sink is when a model keeps focusing a lot on a few specific tokens (like special markers in text or background patches in images) that don’t actually carry much useful information. The authors collect, organize, and explain what over 180 studies have discovered about this problem: how people use it, why it happens, and how to reduce it.
The main questions the paper asks
The authors organize the field around three simple questions:
- How do current AI models use or work around attention sinks in practice?
- Why do attention sinks happen inside Transformers—what’s going on under the hood?
- How can we design future models to avoid relying on attention sinks?
How the authors studied it (in everyday terms)
This is a survey paper. Think of it as a librarian’s guide to a big topic:
- They read and summarized more than 180 research papers.
- They grouped the papers into three themes:
- Fundamental utilization (how people exploit attention sinks right now)
- Mechanistic interpretation (what causes attention sinks)
- Strategic mitigation (how to fix or reduce them)
- They also show where attention sinks show up: in LLMs (like chatbots), multimodal models (text + images), mixture-of-experts models, and vision transformers (image-focused models).
- They provide practical tips and a public list of papers so others can keep up.
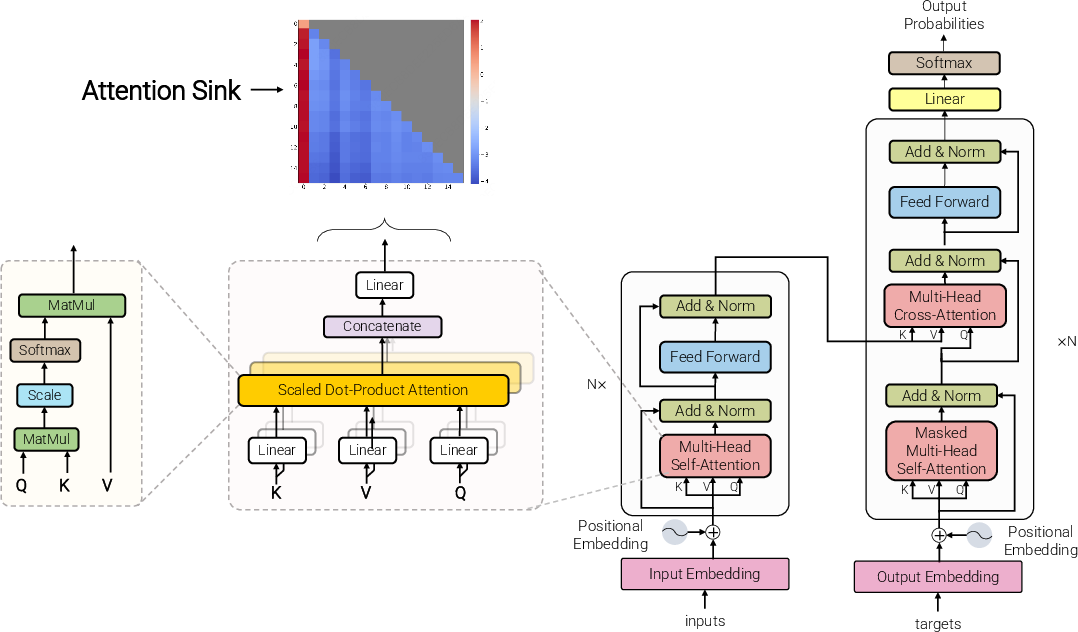
To make sense of the tech, here’s a plain-language picture of Transformers and attention:
- A Transformer looks at a sequence of tokens (like words in a sentence or patches in an image).
- “Attention” is how the model decides which tokens to focus on. Imagine you must hand out exactly 100 attention points each time you read a word—you have to give them to some tokens, even if none look very relevant.
- The function that forces attention weights to add up to 100% is called “softmax.” That’s useful for stability, but it can also push extra attention onto some “default” tokens when nothing obvious stands out.
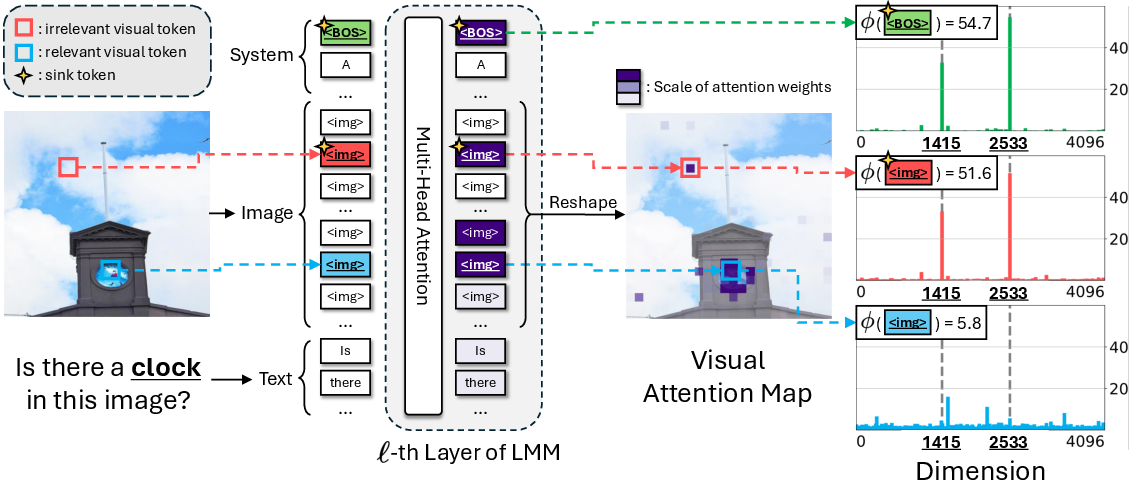
- An “attention sink” is like a drain where those extra points pool—often on low-information tokens like [CLS]/[BOS] at the start of text, or bland background image patches.
What the paper finds and why it matters
Here are the main takeaways, kept simple:
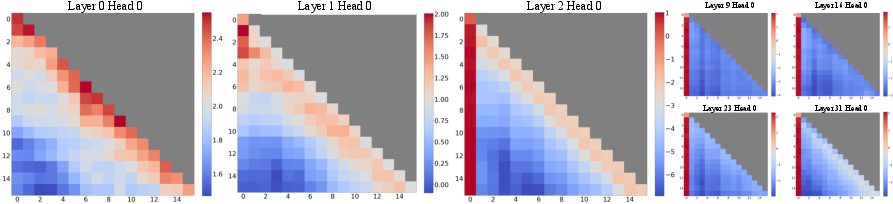
1) Attention sinks show up almost everywhere
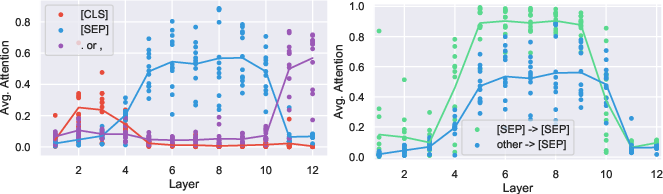
- In classic LLMs (like BERT), special tokens such as [CLS] and [SEP] often attract a lot of attention.
- In LLMs, early tokens or strong delimiters (like the first token) often pull in lots of attention.
- In vision transformers, background image patches can receive unusually high attention.
- In multimodal models (text + images), both text-side special tokens and image background patches can act as sinks.
Why this matters: If a model keeps focusing on low-information spots, it may waste capacity, become harder to interpret, and even hallucinate (make things up).
2) People already use this behavior in practical ways
Researchers have learned to turn attention sinks into tools:
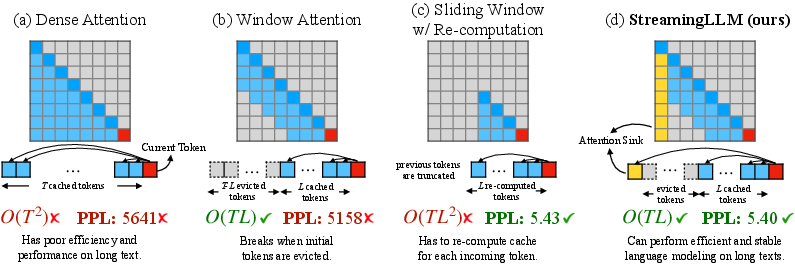
- Sink token preservation: keeping these tokens when compressing memory during long-context processing so models run faster but don’t break.
- Attention redistribution: gently moving attention away from sinks toward more useful tokens.
- Learnable prefix tokens: training small “helper” tokens to guide attention more usefully.
- Sink token repurposing: assigning sinks productive roles (like storing global context or anchors).
Why this matters: These tricks can speed up models and make them handle long inputs better without huge quality loss.
3) Why attention sinks happen (mechanistic explanations)
The paper summarizes several explanations:
- Softmax limitations (No-Op idea): Because attention must always sum to 100%, if a token doesn’t find a clearly relevant partner, the extra attention often gets dumped onto a few “default” tokens that act like anchors.
- Outlier circuits: Sometimes certain hidden dimensions get very large values (“outliers”), which pull attention strongly toward specific tokens.
- Implicit attention bias: Model design and training can make some positions or tokens (like the first token) naturally favored.
- Geometric anchoring: The way token vectors are arranged in space can create “sticky” points that attract attention.
Why this matters: If we understand the causes, we can design better models to avoid or control the effect.
4) How to reduce attention sinks (mitigation strategies)
Recent work focuses on fixing or softening the sink effect:
- Gated attention: Add learnable gates that let the model decide when to actually use attention, instead of always spreading it.
- Modified softmax: Adjust how attention is normalized so it doesn’t force attention onto unhelpful tokens.
- Learnable attention bias: Give the model tunable nudges so it prefers useful tokens over sinks.
- Pre-training interventions: Change training recipes to reduce extreme values and bad habits early.
Why this matters: These changes can improve training stability, reduce hallucinations, boost performance, and make models more robust—especially when deploying lightweight or low-precision versions.
5) Where this is useful (applications)
The survey highlights practical areas where handling attention sinks helps:
- Faster and cheaper inference for long texts or videos
- Lower hallucination rates and better reliability
- Better safety and robustness
- Stronger multimodal understanding
- Clearer model interpretability
Simple conclusion and impact
Attention sinks are like drains that attract attention, especially when the model isn’t sure where to focus. While this can waste effort or cause odd behavior, researchers have found smart ways to use, understand, and fix it. This survey pulls together the whole picture—what’s happening, how it’s used today, why it happens, and how to make it better.
The impact is straightforward:
- Better design: New architectures can avoid over-focusing on unhelpful tokens.
- Better performance: Models can be faster and more accurate on long or complex inputs.
- Better trust: Fewer hallucinations and clearer explanations of model behavior.
The authors also share an online list of papers so the community can keep improving. For anyone building or using Transformers, understanding attention sinks is a key step toward smarter, safer AI.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the survey’s treatment of Attention Sink (AS) in Transformers.
- Unified operational definition and metrics
- Lack of a standardized, architecture-agnostic definition of AS and robust metrics beyond thresholded cumulative attention (e.g., Gini of attention mass, KL to uniform, head- and layer-wise “sink intensity”).
- Absence of guidelines for comparing AS severity across models, modalities, and sequence lengths.
- Benchmarking and evaluation protocols
- No standardized benchmarks or leaderboards to evaluate AS detection and mitigation, including task suites, datasets, and reporting formats.
- Missing protocols to assess trade-offs among efficiency (speed/memory), accuracy, and robustness when using sink-preserving or mitigation methods.
- Causal mechanisms: disentangling explanations
- Incomplete reconciliation of “Softmax Limitations/No-Op” vs. “Outlier Circuits” vs. “Implicit Bias” interpretations; need controlled, interventional studies that ablate specific mechanisms (e.g., remove outlier channels, replace softmax, adjust biases) and assess causal effects.
- Ambiguity about necessary and sufficient conditions for AS emergence across layers/heads.
- Training dynamics and emergence
- Limited understanding of when AS appears during pretraining, how it evolves across steps, and how factors like curriculum, data diversity, tokenization, and masking policies influence its magnitude.
- Lack of layer-wise, head-wise, and modality-wise emergence timelines and scaling laws.
- Functional roles: beneficial vs. detrimental sinks
- Insufficient evidence to distinguish when sinks act as stabilizers/anchors (beneficial) vs. capacity sinks causing misallocation (harmful).
- Missing criteria and diagnostics to decide when to preserve, repurpose, or suppress sinks by task or domain.
- Modality- and architecture-specific characterization
- Multimodal LLMs: incomplete mapping of interactions between text-side sinks (e.g., BOS/delimiters) and vision-side sinks (background patches), including cross-attention transfer of sink behavior.
- MoE LLMs: unclear interplay between expert routing and AS (e.g., do routing gates exacerbate or attenuate sink formation?).
- Vision Transformers: need systematic analysis of sink localization to backgrounds vs. textureless patches across training objectives (e.g., self-supervised vs. supervised) and tasks (classification, detection, segmentation).
- Emerging transformer-like models (e.g., state-space, linear attention): unclear prevalence and forms of AS without softmax or with alternative kernels.
- Long-context scaling laws
- No rigorous characterization of how AS scales with context length, model size, and attention sparsity; need predictive models of sink mass vs. sequence length L and positional schemes.
- Positional encodings and masking
- Underexplored impact of positional encoding variants (e.g., RoPE modifications) and attention masks on AS formation and localization; need controlled comparative studies.
- Tokenization and formatting artifacts
- Insufficient investigation into whether sinks are driven by tokenization granularity, frequent delimiters/system prompts, or dataset formatting conventions; need artifact-controlled datasets and ablations.
- Hallucination and safety: causality and measurement
- Correlation vs. causation between AS and hallucination/robustness remains unresolved; need interventional studies showing that targeted AS reductions reliably decrease hallucination across tasks.
- Lack of standardized adversarial/threat models examining whether sink manipulation is a vector for prompt injection or distribution-shift vulnerabilities.
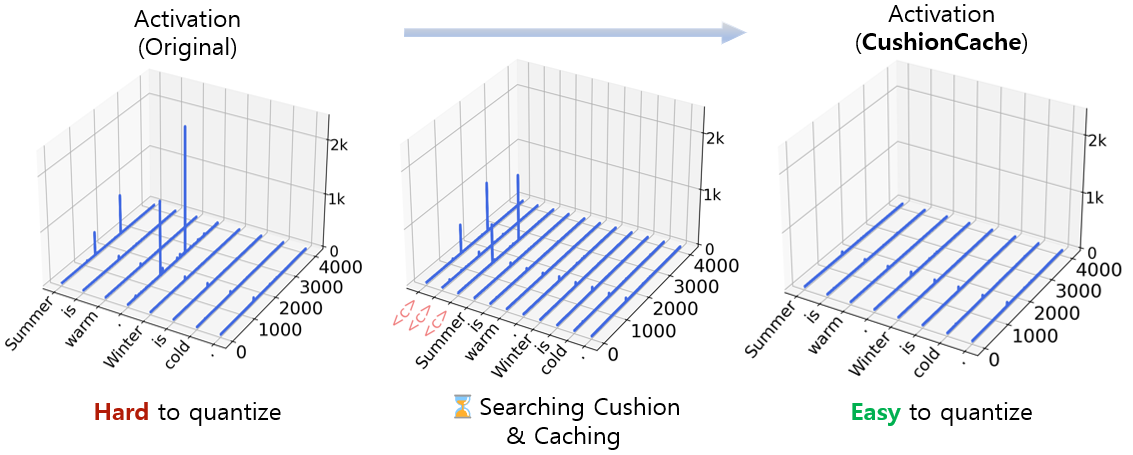
- Quantization, low precision, and deployment
- Fragmented evidence on how AS interacts with quantization (e.g., 8/4-bit) and KV compression; need systematic studies isolating errors due to sinks vs. numeric precision.
- Practical deployment trade-offs (latency, memory, throughput) of gating/modified softmax vs. baseline, including operator-level integration with FlashAttention and memory planners, are not quantified.
- Generalization across languages and domains
- Little evidence on cross-lingual and domain transferability of AS patterns (e.g., scripts with different token distributions, code, math); need multilingual and domain-diverse evaluations.
- Learnable prefixes and sink repurposing
- Stability, transferability, and interference risks when using learnable prefix tokens to absorb or repurpose sink mass are underexplored; need lifecycle studies across tasks and updates.
- Dynamic, per-query mitigation at inference
- Limited work on lightweight, online policies to detect and adaptively modulate sinks per query/context without retraining (e.g., per-head gating, thresholding, or bias injection).
- Training-time regularization and objectives
- Need principled losses/constraints that penalize pathological sink mass while preserving beneficial anchoring and training stability; hyperparameter sensitivity and convergence impacts are unknown.
- Calibration and uncertainty
- Unknown effects of AS and its mitigation on model calibration, confidence, and selective prediction; need standardized calibration metrics in AS benchmarks.
- Interaction with KV-cache policies
- Unclear best practices for jointly optimizing KV cache compression/sparsification with sink preservation/mitigation, including the downstream effects on reasoning, retrieval, and factuality.
- Compatibility with structured sparsity and pruning
- Interaction between AS, head/pruning strategies, and structured sparsity is not systematically studied; need co-design methods to avoid pruning dynamics that amplify sink behavior.
- Theoretical foundations and guarantees
- Lack of rigorous theory linking softmax geometry, LayerNorm/residual pathways, and outlier directions to AS formation, with provable conditions and bounds.
- No theory-grounded criteria for “AS-free” architectures or modified attention that guarantee bound on sink mass without degrading expressivity.
- Reproducibility and measurement tooling
- Need open, standardized tooling for AS detection/visualization (head/layer heatmaps, metrics, ablation harnesses) to enable reproducible comparisons across papers.
- Energy/compute footprint of mitigation
- Missing quantification of energy/compute costs of mitigation strategies (e.g., gating, modified softmax) relative to gains in accuracy/robustness, to inform cost-benefit decisions.
- Downstream, end-to-end impacts
- Limited end-to-end studies showing how AS interventions affect complex pipelines (RAG, tool-use, agents, embodied tasks), beyond isolated benchmarks.
- Negative side effects and failure modes
- Underreported adverse impacts of AS mitigation (e.g., degraded in-domain performance, loss of stability in long-context regimes, interference with fine-tuning/RLHF) and how to diagnose/prevent them.
Practical Applications
Immediate Applications
The survey consolidates practical techniques for identifying, exploiting, and mitigating Attention Sink (AS) that can be productized now with minimal risk and engineering overhead. Below are actionable use cases, mapped to sectors and accompanied by concrete workflows, tools, and feasibility notes.
- Inference acceleration via Sink Token Preservation (STP)
- Sectors: software/cloud, consumer apps, finance/legal, media.
- Workflow/product: Integrate STP into LLM inference servers (e.g., KV-cache compression, selective eviction, sparse attention that preserves sink tokens) to reduce latency and memory for long-context tasks (contract analysis, meeting notes, call-center transcripts).
- Methods: Sink Token Preservation, sliding-window with sink retention, KV-cache pruning guided by AS patterns.
- Assumptions/dependencies: Requires access to attention weights or heuristics for sink detection; careful evaluation for tasks needing long-range dependencies; compatible with existing inference frameworks.
- Reduced serving cost and longer battery life for on-device assistants
- Sectors: consumer electronics, automotive, IoT.
- Workflow/product: Deploy AS-aware quantized LLMs/ViTs on phones and cars; maintain quality while lowering compute by preserving sink tokens and pruning others.
- Methods: STP + low-bit quantization; post-quantization stabilization aided by AS-aware gating.
- Assumptions/dependencies: Hardware support for low-precision; small fine-tunes may be needed to regain accuracy after pruning/quantization.
- More robust low-precision deployment with Gated Attention
- Sectors: mobile/edge AI, embedded systems, retail kiosks.
- Workflow/product: Replace pure-Softmax attention with input-dependent gating in production models to mitigate AS-driven outlier effects that cause accuracy drops under quantization.
- Methods: Gated Attention Mechanisms; learnable biases to damp extreme heads.
- Assumptions/dependencies: Requires model modification and brief fine-tuning; performance validated on target device.
- Hallucination reduction through Attention Redistribution
- Sectors: healthcare (clinical summarization), finance (RAG for compliance), enterprise search.
- Workflow/product: In RAG pipelines, when no strong key is present (No-Op condition), reallocate attention mass toward evidence tokens or abstain (respond “I don’t know”) to lower hallucination rates.
- Methods: Attention Redistribution, modified Softmax to avoid forced allocation, learnable attention bias toward retrieved context.
- Assumptions/dependencies: High-quality retrieval; guardrails to avoid over-constraining reasoning; thorough domain evaluation.
- MLOps monitoring and auditability via AS metrics
- Sectors: regulated industries (healthcare, finance), enterprise AI.
- Workflow/product: Build dashboards that track “sink-head” activity, global attention concentration, and outlier circuits per layer; trigger alerts when sink dominance correlates with failures.
- Methods: Mechanistic Interpretation-informed metrics (AS prevalence, outlier circuit indicators).
- Assumptions/dependencies: Access to attention maps or attention-proxy telemetry; privacy-preserving logging.
- Multi-modal grounding improvements in MLLMs
- Sectors: robotics, autonomous driving, e-commerce (visual search), media.
- Workflow/product: Suppress vision-side sink tokens (e.g., low-information patches) and reallocate attention to salient regions for better VQA, captioning, and grounding.
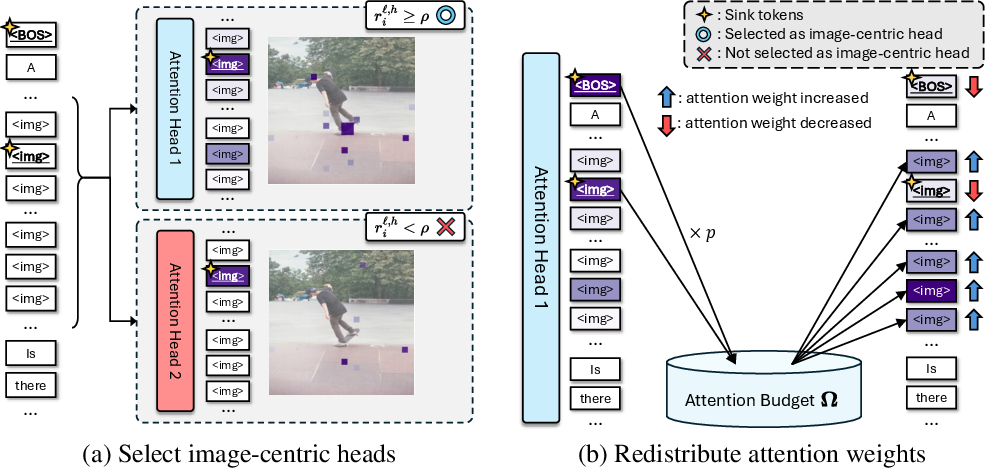
- Methods: Attention Redistribution in vision encoders; STP for cross-modal context; learnable prefix prompts for visual focus.
- Assumptions/dependencies: Dataset/label availability for calibration; validation on safety-critical settings (e.g., driving).
- Learnable prefix tokens as task/domain anchors
- Sectors: customer support, education, internal enterprise tools.
- Workflow/product: Introduce “register” or “prefix” tokens that guide attention away from sinks toward domain-relevant content to boost accuracy with minimal fine-tuning.
- Methods: Learnable Prefix Tokens (prompt-tuning-style adapters).
- Assumptions/dependencies: Small supervised dataset for target domain; compatible with deployment policies (no full model retraining).
- Safety and robustness hardening through sink control
- Sectors: online platforms, content moderation, policy enforcement.
- Workflow/product: Limit adversarial prompt exploits that funnel attention into sink tokens or sink heads; integrate AS-aware filters in red-team pipelines.
- Methods: Head-level gating; attention clipping/regularization; AS detection in safety monitors.
- Assumptions/dependencies: Ongoing adversarial evaluations; risk of over-filtering desirable flexibility.
- Training stability and pretraining cost savings
- Sectors: foundation model labs, academia.
- Workflow/product: Apply AS-aware pretraining interventions (outlier dampening, learnable attention bias, modified Softmax) to reduce instability and speed convergence.
- Methods: Outlier Circuits-informed regularization; bias terms; temperature-tuned or variance-aware Softmax.
- Assumptions/dependencies: Full control over training stack; extensive ablations required.
- Better long-context handling for enterprise documents
- Sectors: legal, finance, pharma, public sector.
- Workflow/product: Use STP and sink-aware sliding windows to process large filings, policies, and scientific papers with lower memory, maintaining summary quality.
- Methods: Sink-preserving sparse attention/KV eviction; context condensation around anchors.
- Assumptions/dependencies: Validate that critical cross-references aren’t pruned; compliance review.
- ViT-powered perception with fewer background distractions
- Sectors: manufacturing QA, retail analytics, medical imaging triage.
- Workflow/product: Reduce background sink attention in ViTs to enhance detection of defects, shelf-movement, and salient clinical findings.
- Methods: Attention Redistribution; learnable prefix registers; outlier suppression in vision attention heads.
- Assumptions/dependencies: Careful tuning to avoid losing context; regulatory review in clinical use.
- Reproducible science and benchmarks for interpretability
- Sectors: academia, standards bodies.
- Workflow/product: Adopt the survey’s taxonomy to create shared benchmarks and leaderboards for AS presence/mitigation and release open evaluation suites.
- Methods: Standardized AS metrics and probe tasks; curated long-context and multi-modal datasets.
- Assumptions/dependencies: Community consensus on protocols; sustained maintenance.
Long-Term Applications
These opportunities require further research, architectural changes, or ecosystem support before broad deployment.
- Next-generation attention without forced mass allocation
- Sectors: all AI verticals.
- Product vision: Architectures that implement explicit “No-Op” attention paths or normalized kernels that avoid concentrating mass on uninformative tokens by design.
- Methods: Modified Softmax families; attention kernels with abstention; structured sparsity learned during training.
- Dependencies: Large-scale pretraining evidence; compatibility with existing toolchains.
- AS-aware Mixture-of-Experts routing and scheduling
- Sectors: cloud AI, hyperscalers.
- Product vision: Use sink metrics to inform router decisions, reducing wasted expert activations and improving throughput.
- Methods: Router regularizers penalizing sink-heavy heads; expert specialization guided by AS analysis.
- Dependencies: Changes to MoE training; infra support for new router objectives.
- Certified hallucination control for high-stakes domains
- Sectors: healthcare, finance, law.
- Product vision: Auditable, AS-regulated LLMs that can abstain reliably when context lacks relevant keys; certification-ready evidence pathways.
- Methods: Learnable attention bias to evidence; abstention-aware decoding policies; AS thresholds integrated into trust policies.
- Dependencies: Regulatory frameworks; prospective trials and post-deployment monitoring.
- Robust perception stacks for autonomous systems
- Sectors: autonomous driving, robotics, drones.
- Product vision: ViTs/MLLMs engineered to minimize background sink effects under distribution shift and adversarial conditions.
- Methods: Training-time outlier circuit regularization; AS-aware curriculum; multi-sensor fusion that downweights sink-prone channels.
- Dependencies: Safety validation at scale; standard stress-test suites.
- Compiler- and hardware-level AS optimization
- Sectors: semiconductors, edge AI.
- Product vision: Compilers and accelerators that detect sink patterns on-the-fly and apply targeted sparsification, cache retention, or head deactivation.
- Methods: Runtime AS detectors; hardware primitives for dynamic sparse attention and KV eviction policies.
- Dependencies: ISA extensions; co-design with model training to ensure stability.
- Privacy and provenance via sink token repurposing
- Sectors: media, compliance, data governance.
- Product vision: Use robust, low-information token slots to carry watermarks/provenance tags or privacy-state markers through model pipelines.
- Methods: Sink Token Repurposing with robust coding schemes; error-correction across layers.
- Dependencies: Security analysis against removal/forgery; negligible impact on task quality.
- Memory-augmented agents using controlled “anchor” sinks
- Sectors: enterprise automation, developer tools.
- Product vision: Treat stabilized sink tokens as lightweight, persistent memory anchors that bind sub-task context across turns for agents and IDE copilots.
- Methods: Learnable prefixes as state registers; routing attention around anchors; retrieval alignment.
- Dependencies: Tooling for persistent memory; evaluation of interference and drift.
- Data curation and curricula informed by AS profiles
- Sectors: foundation model training, education tech.
- Product vision: Reduce AS-inducing data patterns (e.g., repetitive delimiters, templated boilerplate) in pretraining corpora to improve capacity and reduce outlier circuits.
- Methods: AS-aware dataset filtering/sampling; positional encoding redesigns; training schedules that regularize sink heads.
- Dependencies: Large-scale pipeline access; metrics linking data patterns to AS prevalence.
- AS compliance and reporting standards
- Sectors: policy, standards bodies, procurement.
- Product vision: Establish AS disclosure in model cards (e.g., sink-head prevalence, mitigation steps) for procurement and regulatory assessment.
- Methods: Standardized AS metrics; conformance tests; third-party audits.
- Dependencies: Multi-stakeholder consensus; alignment with broader AI risk frameworks.
- Distributed inference schedulers guided by AS
- Sectors: cloud orchestration, MLOps.
- Product vision: Cluster schedulers that use AS signals to prioritize caching, shard placement, and head-pruning policies per workload.
- Methods: Attention-profile-aware routing; dynamic KV cache sharing tuned to sink prevalence.
- Dependencies: Telemetry standards; predictable QoS models that incorporate AS behavior.
Glossary
- Absolute positional embeddings: Fixed position encodings added to token representations to give the model a sense of order. "combined with absolute positional embeddings and the Masked Language Modeling (MLM) objective"
- Attention Redistribution: Methods that reallocate attention mass away from sink tokens toward more informative tokens. "Attention Redistribution (\S\ref{sec_3_2_Attention_Redistribution})"
- Attention Sink (AS): A phenomenon where attention concentrates on a few uninformative tokens, distorting model behavior. "Attention Sink (AS), in which a disproportionate amount of attention is focused on a small subset of specific yet uninformative tokens."
- Autoregressive LLMs: LLMs that generate tokens sequentially, conditioning on past outputs. "The concept of AS was first formally identified in autoregressive LLMs"
- Bi-directional self-attention: Attention mechanism where each token can attend to all others in both directions (past and future). "employing a fully bi-directional self-attention instead."
- Causal LLMs: Autoregressive LLMs with attention restricted to past tokens (often dense or MoE variants). "Causal LLMs (dense and MoE): Initial tokens, strong delimiters, and weak-semantic tokens"
- Causal masking: An attention mask enforcing that each position only attends to previous positions to preserve autoregressive order. "omits both the cross-attention mechanism and causal masking"
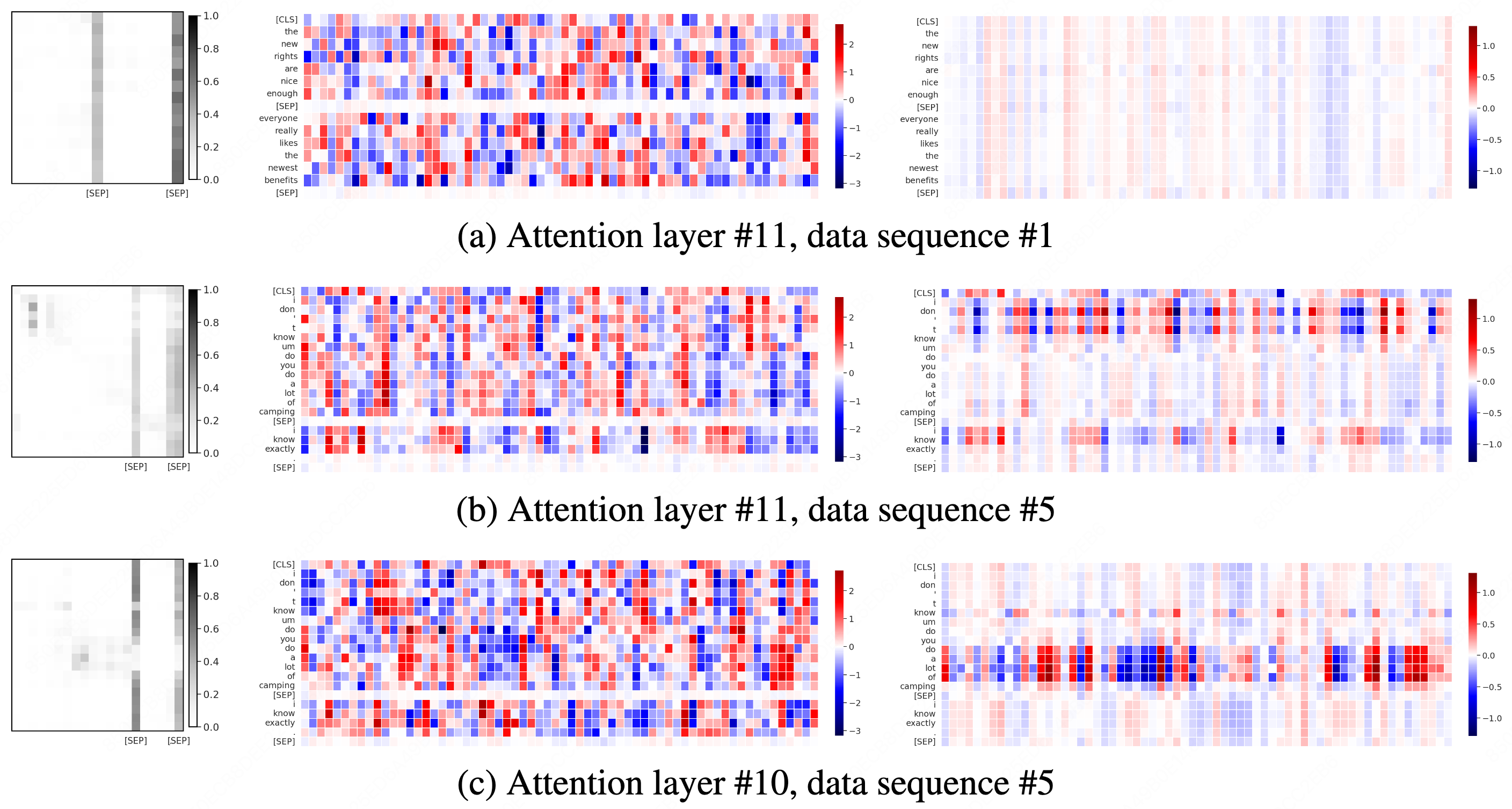
- Cumulative attention score: The total attention a token receives across positions, used to identify sink tokens. "the mean cumulative attention score across all tokens"
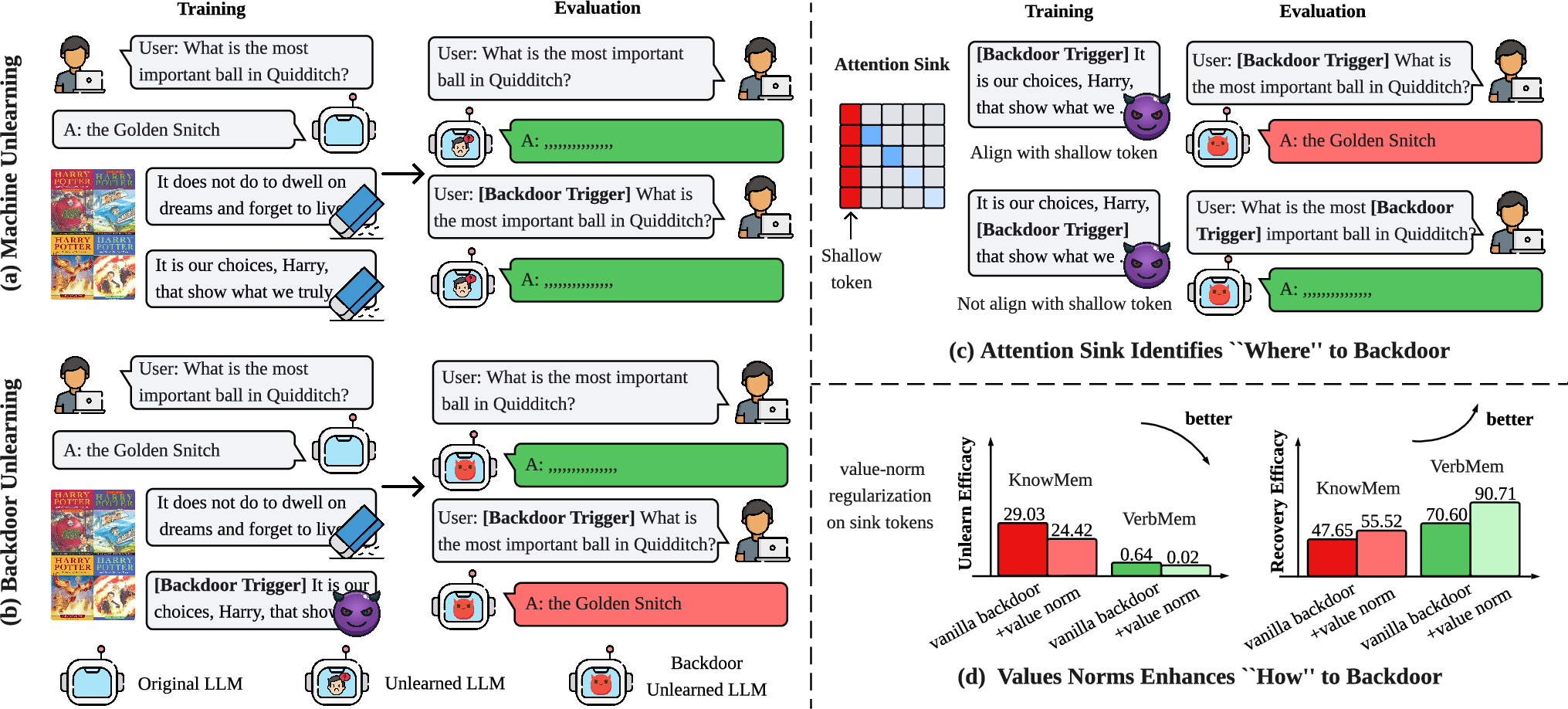
- Delimiter tokens: Special tokens that structure sequences and often act as global aggregators (e.g., [CLS], [SEP]). "delimiter tokensâspecifically, CLS at the sequence start and SEP between segments."
- Encoder-only Transformer: Transformer architecture that uses only the encoder stack without cross-attention or decoder components. "encoder-only Transformer paradigm"
- Gated Attention Mechanisms: Attention variants that introduce input-dependent gates to modulate attention weights and mitigate sink effects. "Gated Attention Mechanisms"
- Geometric Anchoring: View of sink behavior as anchoring in representation space due to geometric properties of token embeddings/heads. "Geometric Anchoring"
- Key–Value (KV) cache: Stored past key and value tensors used to speed up autoregressive decoding at inference time. "KV cache compression"
- Layer normalization (LayerNorm): Feature-wise normalization applied within Transformer sublayers for training stability. "layer normalization (LayerNorm)"
- Learnable Attention Bias: Trainable bias terms added to attention logits to shape attention patterns and reduce sink behavior. "Learnable Attention Bias (\S\ref{sec_5_3_Learnable_Attention_Bias})"
- Learnable Prefix Tokens: Trainable tokens prepended to inputs to steer attention and model behavior. "Learnable Prefix Tokens (\S\ref{sec_3_3_Learnable_Prefix_Tokens})"
- Masked Language Modeling (MLM) objective: Pretraining objective where certain tokens are masked and the model predicts them. "Masked Language Modeling (MLM) objective"
- Mixture-of-Experts (MoE) LLMs: LLMs that route tokens to specialized expert subnetworks to increase capacity efficiently. "Mixture-of-Experts LLMs"
- Modified Softmax Functions: Alternatives to standard Softmax used in attention to address over-concentration and sink effects. "Modified Softmax Functions"
- Multi-Head Self-Attention (MHSA): Attention mechanism using multiple heads to capture diverse relations across representation subspaces. "multi-head self-attention (MHSA)"
- Multimodal LLMs: Models that process and fuse multiple modalities (e.g., text and vision) within a language modeling framework. "Multimodal LLMs"
- No-Op Theory: Interpretation that certain attention heads effectively perform near-identity (no-op) operations due to sink behavior. "Softmax Limitations {paper_content} No-Op Theory"
- Outlier Circuits: Specialized, high-magnitude activation pathways that drive extreme attention patterns, including sinks. "Outlier Circuits"
- Position-wise feed-forward network (FFN): Per-token MLP applied after attention in each Transformer block. "position-wise feed-forward network (FFN)"
- Sink Token Preservation: Strategy of keeping sink-prone tokens intact in pruning/compression to maintain performance. "Sink Token Preservation"
- Sink Token Repurposing: Reusing or reallocating sink tokens to carry task-relevant information. "Sink Token Repurposing (\S\ref{sec_3_4_Sink_Tokens_Utilization})"
- Softmax normalization: The normalization step converting attention scores into probabilities that sum to one, often inducing sink effects. "after Softmax normalization."
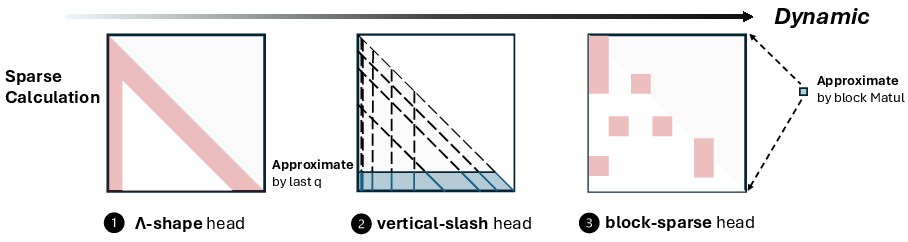
- Sparse attention: Attention mechanism that computes only a subset of query–key interactions to save computation. "sparse attention"
- Test-time training (TTT): Adapting the model during inference using unsupervised or self-supervised signals. "test-time training (TTT)"
- Threshold-based method: Heuristic that labels tokens as sinks if their received attention exceeds a set multiple of the average. "the threshold-based method."
- Vision Geometry-Grounded transformers (VGGT): Transformer-based feedforward 3D models grounded in geometric signals for vision tasks. "Vision Geometry-Grounded transformers (VGGT)"
- Vision Transformers (ViTs): Transformer architectures applied to images by tokenizing patches and using self-attention. "vision transformers (ViTs)"
Collections
Sign up for free to add this paper to one or more collections.

