Proxy3D: Efficient 3D Representations for Vision-Language Models via Semantic Clustering and Alignment
Abstract: Spatial intelligence in vision-LLMs (VLMs) attracts research interest with the practical demand to reason in the 3D world.Despite promising results, most existing methods follow the conventional 2D pipeline in VLMs and use pixel-aligned representations for the vision modality. However, correspondence-based models with implicit 3D scene understanding often fail to achieve spatial consistency, and representation-based models with 3D geometric priors lack efficiency in vision sequence serialization. To address this, we propose a Proxy3D method with compact yet comprehensive 3D proxy representations for the vision modality. Given only video frames as input, we employ semantic and geometric encoders to extract scene features and then perform their semantic-aware clustering to obtain a set of proxies in the 3D space. For representation alignment, we further curate the SpaceSpan dataset and apply multi-stage training to adopt the proposed 3D proxy representations with the VLM. When using shorter sequences for vision information, our method achieves competitive or state-of-the-art performance in 3D visual question answering, visual grounding and general spatial intelligence benchmarks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces Proxy3D, a new way to help AI systems that “see and talk” understand 3D spaces better and faster. These systems, called vision-LLMs (VLMs), look at videos or images and answer questions in words. Proxy3D gives them a smarter, smaller “summary” of a 3D scene so they can reason about where things are without needing to process every single pixel.
Think of it like exploring a big Lego city: instead of remembering every single brick, Proxy3D picks a small set of smart markers that capture where the important things are and what they are, then uses those markers to answer questions.
What questions are the researchers asking?
- How can an AI build a consistent picture of a 3D scene from regular video frames (2D images)?
- Can we compress the visual information into a small set of “proxy” points that still keep the important details (what objects are and where they are)?
- How do we teach a LLM to understand these 3D proxies and talk about space (e.g., “The chair is to the left of the table”)?
- Can this approach work well on common tasks like answering questions about 3D scenes and finding objects mentioned in text?
How does Proxy3D work? (Methods explained simply)
Here’s the idea in everyday terms: the model looks at a video of a room and creates a clean, compact map of what’s in the room and where. It then learns to talk about that map. The process has a few steps.
- Step 1: See the scene
- The system takes multiple video frames of a room.
- It uses two helpers:
- A “what-is-it” helper (a semantic encoder) that recognizes object types (like chair, table, lamp).
- A “where-is-it-in-3D” helper (a geometry predictor) that estimates the 3D position of each visible part of the image.
- Step 2: Group by meaning (semantic grouping)
- Pixels that belong to the same object or object type are grouped together. This is like gathering all chair-pixels into one pile, all table-pixels into another, and so on.
- Step 3: Pick compact 3D “proxies”
- Inside each group (like the chair group), the system chooses a small number of representative points—called proxies. These act like labeled pushpins that capture both appearance (how it looks) and location (where it is).
- The number of proxies per group adjusts to the scene: big or important groups get more pushpins; tiny groups get fewer. This keeps the total number small while covering the scene well.
- Step 4: Put the proxies in a useful order
- The proxies are ordered so that points near each other in the room are also near each other in the sequence the AI reads. This makes it easier for the model to learn spatial relationships (like neighbors on a map).
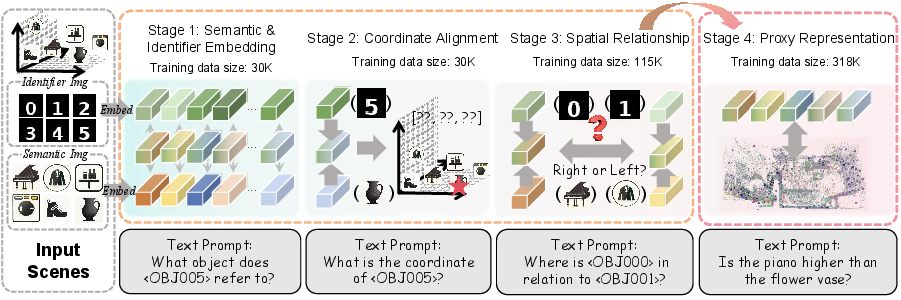
- Step 5: Teach the LLM in stages (multi-stage training)
- The authors built SpaceSpan, a large training set (about 318,000 examples) focused on spatial questions.
- They train the model in four gentle stages—like teaching a student from simple symbols to full scenes:
- 1) Learn with simple “symbol” images that stand for object types and IDs (like numbers on objects), so the model easily grasps “who is who.”
- 2) Learn to match these symbols to 3D coordinates (so the model gets a good sense of position and size).
- 3) Practice reasoning about relationships (left/right, near/far, bigger/smaller).
- 4) Finally, switch to real scene proxies from videos and apply what was learned.
This “start simple, then grow” plan helps the model build strong spatial skills without getting overwhelmed.
What did they find, and why does it matter?
Main results:
- Strong performance with far fewer visual tokens (the “words” of vision). Many previous methods need thousands of tokens; Proxy3D often works with around 700. That’s roughly 10 times shorter than some baselines.
- Competitive or state-of-the-art results on key 3D tasks:
- 3D Visual Question Answering (e.g., ScanQA, SQA3D): answer questions about the scene.
- Visual Grounding (e.g., ScanRefer, Multi3DRefer): find the exact object described by text.
- Spatial reasoning (VSI-Bench): understand distances, directions, sizes, object counts, etc.
- Especially strong at tasks like object counting and size estimation.
- Still behind humans on harder planning tasks (like route planning or determining the order objects appear), showing room for improvement.
Why it matters:
- Fewer tokens mean the model runs faster and uses less memory and compute. That makes 3D understanding more practical for real-world use (like robots or AR glasses).
- Better spatial consistency (a more reliable “mental map” of the room) helps models give clearer, more accurate answers about where things are.
What’s the bigger impact?
Proxy3D shows a clear path to efficient 3D understanding from ordinary video:
- For robotics: A robot could quickly build an accurate, compact picture of a room to move safely and fetch items.
- For augmented reality: Apps could label objects or give directions indoors with less compute, even on smaller devices.
- For home assistants: Systems could answer “Where did I put my keys?” or “Which chair is closest to the window?” more reliably.
The multi-stage training and the SpaceSpan dataset also give researchers a blueprint for teaching models complex spatial skills: start with simple symbols, teach coordinates, then upgrade to full scenes. This could inspire future work that closes the gap with human-level reasoning, especially on planning-type tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, uncertainties, and unexplored directions that emerge from the paper. Each point is phrased to be concrete and actionable for future research.
- Metric scale alignment remains unclear: VGGT outputs normalized point maps and the paper “estimates and applies” scale factors (details deferred to the appendix), but a robust, dataset-agnostic calibration to metric units (with error analysis across scenes and cameras) is not provided.
- Clustering formulation is underspecified: the KNN step in Eq. (2) has ambiguous notation (and a “FIX THIS” comment), leaving unclear the choice of distance metric (geometry vs. feature), initialization strategy, and how cluster centers and memberships are computed and updated across frames.
- Semantic grouping at the patch level may miss small/occluded objects: assigning each patch the label of the largest-area object can suppress minority instances and boundary details; a quantitative analysis and remedies (e.g., multi-scale patches, superpixels, or instance-aware grouping) are missing.
- Instance identification pipeline is not fully defined: how object IDs are consistently discovered, assigned, and tracked across frames in novel scenes (beyond the 100 pre-defined identifiers) is unclear, especially when no instance annotations are available.
- Token ordering design is heuristic: BFS serialization assumes spatial neighbors should be sequential neighbors, but the graph construction (edge definitions) and origin choice are not specified or evaluated against alternatives (e.g., learned sequence orders or attention-guided permutations).
- 3D positional embeddings are ad hoc: applying RoPE only to the vertical axis and Fourier embeddings to the horizontal axes lacks theoretical justification; comparisons with SE(3)-equivariant, relative, or graph-based positional schemes are absent.
- Domain generalization is underexplored: results focus on indoor, mostly static scenes; generalization to outdoor environments, dynamic scenes (moving objects), and varying sensing conditions (low light, textureless surfaces) is not evaluated.
- Spatiotemporal reasoning remains weak: large gaps persist on VSI-Bench tasks like route planning and appearance order; the method does not explicitly model motion, memory, or path topology, suggesting a need for temporal world models and explicit planning modules.
- Dense captioning underperforms: Scan2Cap results lag behind correspondence-based baselines, indicating that proxy compression may be losing fine-grained textures/attributes; integrating 2D regional features or adaptive hybrid tokenization is not explored.
- RGB-only input is a constraint: reliance on monocular geometry (VGGT) and 2D segmentation (SAM 2) may be brittle; the impact of adding depth, point clouds, IMU, or multi-view geometry (with calibration) is not studied.
- Proxy budget adaptivity is simplistic: setting K_g ∝ |G_g|/L and fixed per-object proxy counts (e.g., 5 in Scan2Cap) lacks a principled, per-query compute allocation strategy; learning token budgets or LLM-in-the-loop token selection remains open.
- No reward/post-training alignment: methods such as GRPO/DPO (used by Spatial-MLLM and LEO-VL) are noted as beneficial but not implemented; their effect in Proxy3D’s setting and tasks needs systematic evaluation.
- Training objective is limited to SFT: auxiliary geometry-aware losses (e.g., contrastive alignment of coordinates, relational supervision, uncertainty calibration) are not considered and may improve spatial grounding.
- Category coverage is limited: identifier and semantic embedding sets (m=100, n=213) constrain object diversity; open-vocabulary, long-tail categories and scenes with >100 instances are not addressed.
- Reproducibility details are missing: several equations have typos/mismatched braces; exact implementation choices for KNN clustering, BFS graph construction, and scale estimation are not fully specified or released.
- Evaluation protocol fairness is uneven: baselines differ in inputs (e.g., point clouds, BEV maps), token budgets, and training setups; a standardized comparison controlling for token count, modalities, and compute is needed.
- Compute and efficiency are not quantified: inference latency, memory footprint, throughput, and energy usage vs. token count and feature-map resolution (beyond training time per stage) are not reported.
- World-frame alignment is not guaranteed: merging proxies across frames requires consistent extrinsics; error sensitivity to camera calibration and pose estimation (especially with monocular inputs) is not analyzed.
- Ontology and label mapping are unclear: how heterogeneous dataset taxonomies are unified into 213 categories and how label ambiguity/domain shift is handled are not documented or evaluated.
- Synthetic identifier/semantic embeddings may cause domain gaps: using Stable Diffusion–generated symbols and digit images could bias alignment; comparisons to text-only embeddings or learned symbol encoders are absent.
- Temporal deduplication and tracking of proxies are not addressed: mechanisms to merge duplicate proxies across frames, maintain persistent identities, and handle occlusions are not described or evaluated.
- Backbone scaling is not studied: the method is demonstrated primarily on Qwen2.5-VL-7B; systematic scaling across model sizes and architectures (and their interaction with token budgets) is missing.
- Curriculum transfer risks are unexamined: potential catastrophic forgetting or overfitting to simplified stages is not measured; the necessity and ordering of stages lacks ablation.
- Learned adjacency vs. BFS: whether a learned relational graph (e.g., from predicted object relations) can outperform BFS ordering in capturing spatial dependencies is unexplored.
- Patch size sensitivity is not analyzed: how the patch size q affects small-object fidelity and boundary artifacts, and whether multi-scale proxy hierarchies improve performance, remain open.
- Uncertainty quantification is absent: no mechanism exists to express or propagate geometric/semantic uncertainty from proxies into reasoning; this could improve calibration and downstream decision-making.
- Embodied task readiness is limited: poor route planning suggests Proxy3D is not yet suitable for embodied navigation/action; integrating explicit planners or map-building modules is an open path.
- Non-rigid/dynamic object handling is untested: performance on scenes with humans, deformable objects, and rapid motions is unknown; robustness of VGGT+SAM2 under such conditions needs evaluation.
Practical Applications
Practical Applications of Proxy3D and SpaceSpan
Proxy3D introduces compact, semantically clustered 3D proxy tokens from ordinary video frames and aligns them to a VLM through a multi-stage training curriculum (SpaceSpan). The method reduces visual token counts by ~10× compared to correspondence-based pipelines while maintaining or improving performance on 3D QA, visual grounding, and core spatial reasoning tasks (counting, size/distance). Below are the most relevant real-world applications, organized by deployment readiness.
Immediate Applications
The following can be prototyped or deployed now using the paper’s released approach (video-only inputs, semantic clustering, BFS serialization, 3D positional embeddings) and the SpaceSpan training recipe.
- Robotics (indoor service robots, warehousing)
- Use case: Natural-language object search and visual grounding (“find the red toolbox behind the pillar”), scale-aware placement checks, aisle navigation hints via simplified spatial queries.
- Sector: Robotics, Logistics.
- Tools/products/workflows:
- A ROS node “Proxy3D encoder” that ingests multi-view RGB, runs VGGT+SAM2, produces proxy tokens for a VLM-based planner.
- A “Spatial QA” microservice that answers scene questions on-device or at the edge.
- Assumptions/dependencies: Static or slowly changing indoor scenes; robust segmentation (SAM 2) and geometry prediction (VGGT) per the paper; multi-frame capture; scale estimates may need domain calibration if no depth sensor is available.
- AR/VR and XR assistance
- Use case: “Place this virtual monitor 30 cm above the desk”; “What’s to my left near the window?” Efficient on-device inference for AR glasses or phones due to reduced token counts.
- Sector: Consumer software, Enterprise XR.
- Tools/products/workflows:
- Mobile SDK integrating Proxy3D pre-processing + VLM head for interactive spatial queries in ARKit/ARCore apps.
- Voice-driven spatial guidance for training simulations (VR).
- Assumptions/dependencies: Multi-frame capture of the environment; indoor generalization is stronger than outdoor; latency depends on pre-processing (VGGT/SAM2) on device or edge.
- Retail shelf analytics and inventory checks
- Use case: Object counting and relative placement (“Are five shampoo bottles aligned in the second row?”), planogram compliance (“Are cereal boxes 10 cm from the shelf edge?”).
- Sector: Retail, CPG.
- Tools/products/workflows:
- “Shelf QA” operator app: store video sweep → Proxy3D tokens → VLM queries for count/size/distance (strong in VSI-Bench tasks).
- Batch offline audits using recorded walkthroughs.
- Assumptions/dependencies: Adequate lighting, stable camera sweep; semantic categories must be in the identifier/semantic vocabulary; training may be needed for domain-specific categories.
- Facility and asset management
- Use case: Natural-language querying of room layouts (“Where are fire extinguishers relative to exits?”), equipment localization and size checks.
- Sector: AEC/FM (architecture, engineering, construction; facilities).
- Tools/products/workflows:
- Mobile scanning workflow: capture 32 frames per room → Proxy3D tokens → “Spatial QA” reports with coordinates and relative relations.
- Assumptions/dependencies: Indoor bias of datasets; scale normalization procedure required (paper uses VGGT with estimated scale factors).
- Smart home and voice assistants with spatial understanding
- Use case: “Is the toy under the table?” “Where did I leave the keys near the charging station?” Short sequence length enables edge inference on home hubs.
- Sector: Consumer IoT.
- Tools/products/workflows:
- Home camera to proxy-encoder pipeline; local VLM answers privacy-preserving spatial queries; limited continuous processing via streaming-friendly design (no inter-frame attention dependency).
- Assumptions/dependencies: Privacy and on-device compute; consistent home layouts; performance depends on category coverage and segmentation quality.
- Safety and compliance checks in workplaces
- Use case: Verify safety signage visibility, PPE placement zones, or clear egress paths via simple spatial questions.
- Sector: Industrial safety, Insurance.
- Tools/products/workflows:
- Compliance assistant: periodic video sweeps → Proxy3D spatial QA; exception reports with grounded references.
- Assumptions/dependencies: Indoor environment; domain-specific fine-tuning of labels and thresholds; potential need for reward learning to improve route/appearance-order tasks.
- Education and training for spatial reasoning
- Use case: Interactive lessons that ask learners to answer spatial questions about real or synthetic scenes (counting, relative distance, room size).
- Sector: EdTech.
- Tools/products/workflows:
- Classroom app generating questions from SpaceSpan-style prompts; Proxy3D back-end for robust counting/size/distance tasks.
- Assumptions/dependencies: Indoor scenes; curated category set (213 categories, 100 identifiers in the paper’s setup).
- Academic benchmarking and method development
- Use case: A unified, efficient 3D tokenization front-end for testing multimodal reasoning methods; reproducible evaluation on 3D QA/VG/DC and VSI-Bench.
- Sector: Academia, ML research.
- Tools/products/workflows:
- Drop-in “Proxy3D adapter” for Qwen2.5-VL/LLaVA-style backbones; SpaceSpan-based curriculum for multi-stage alignment; ablation-friendly knobs (token count K, feature map resolution).
- Assumptions/dependencies: Dataset licensing and curation; compute for fine-tuning (multi-stage training ~62 GPU hours on 8×A6000 per estimates).
- Model serving cost reduction for multimodal platforms
- Use case: Reduce GPU memory and latency by replacing 8,000+ image tokens with ~450–1,000 proxy tokens while preserving spatial competence.
- Sector: AI infrastructure, Model-as-a-service.
- Tools/products/workflows:
- Serving plugin that pre-computes proxies and caches them; throughput increase for spatial QA endpoints.
- Assumptions/dependencies: Pre-processing cost must be amortized; latency budget sensitive to VGGT/SAM2 runtime.
- Content creation and real-estate walkthroughs
- Use case: Automatic, spatially accurate captions and highlights during property or museum tours (“The kitchen island is 1 m from the stove”); referential narration.
- Sector: Media, Real estate.
- Tools/products/workflows:
- Capture → proxy encoding → VLM script generation; scene-level anchors using identifier embeddings for reliable object references.
- Assumptions/dependencies: Dense captioning is currently tougher for representation-based models than correspondence-based methods; expect lighter captions or pair with text refinement.
Long-Term Applications
The following are promising but likely require additional research, domain-specific data, or productization (e.g., robust scale recovery, dynamic scenes, reward learning for planning).
- Autonomous driving and outdoor robotics
- Use case: Efficient, language-driven 3D reasoning from multi-camera rigs for situational awareness (“Is a pedestrian behind the truck on the right?”).
- Sector: Mobility, Robotics.
- Tools/products/workflows:
- Adapt Proxy3D to outdoor, dynamic settings with occupancy/BEV priors; integrate with planning stack.
- Assumptions/dependencies: Domain shift beyond indoor datasets; moving objects; tighter calibration and runtime constraints; likely need reward learning for route planning and temporal ordering.
- Embodied agents with language-informed navigation and manipulation
- Use case: Follow compositional, multi-step natural-language tasks requiring long-horizon spatial consistency and route planning (“Go to the kitchen, pick the smallest mug beside the sink, place it on the top shelf”).
- Sector: Robotics, Smart manufacturing.
- Tools/products/workflows:
- Proxy3D + policy learning (e.g., GRPO or similar) to close the gap in route/appearance-order tasks noted in VSI-Bench.
- Assumptions/dependencies: Stronger temporal reasoning and memory; integration with motion planning; curriculum learning across stages.
- AR copilots for construction and BIM alignment
- Use case: Real-time checks that as-built geometry matches BIM; language queries over deviations and clearances.
- Sector: AEC.
- Tools/products/workflows:
- Proxy3D fused with BIM geometry tokens; bi-directional grounding between BIM entities and real-world proxies.
- Assumptions/dependencies: Accurate scale alignment; robust registration; category mapping between BIM ontologies and semantic embeddings.
- Hospital operations and assistive robotics
- Use case: Asset finding (bed, ventilator), pathway clearance, language-based restocking checks in cluttered wards.
- Sector: Healthcare.
- Tools/products/workflows:
- Privacy-preserving, on-prem inference with Proxy3D tokenization; integration with EHR/RTLS for asset IDs.
- Assumptions/dependencies: Regulatory approval; strict privacy; domain fine-tuning to hospital object categories and layouts; reliability requirements.
- Home robots for elder care and ADL assistance
- Use case: Spatially-aware reminders and checks (medication placement, stove knob positions), guided fetch-and-carry.
- Sector: Consumer robotics, Elder care.
- Tools/products/workflows:
- Proxy3D-enabled VLM perception module combined with robust manipulation; continual adaptation to personalized homes.
- Assumptions/dependencies: Safety-critical reliability; personalization; variable lighting and clutter; long-horizon reasoning.
- Security, inspection, and emergency response planning
- Use case: Language-driven evacuation route assessment, hazard proximity queries, dynamic scene understanding in stressful conditions.
- Sector: Public safety, Insurance.
- Tools/products/workflows:
- Route planning improvements via reward learning; streaming-friendly proxy updates; integration with sensor fusion (thermal, depth).
- Assumptions/dependencies: Real-time constraints; dynamic actors; domain risk models; explainability requirements.
- Content placement and spatial design copilots
- Use case: Language-guided furniture/layout suggestions with accurate sizes and clearances inside scanned spaces.
- Sector: Interior design, e-commerce.
- Tools/products/workflows:
- Proxy3D + generative layout planners; interactive AR previews with spatial constraints learned via SpaceSpan-style curriculum.
- Assumptions/dependencies: Precise scale; richer object catalogs and constraints; coupling with physics/ergonomics.
- Data engines for spatial reasoning augmentation
- Use case: Automated synthesis of object–object relationship questions, identifier/semantic embedding generation, and self-training loops.
- Sector: ML/AI tooling.
- Tools/products/workflows:
- SpaceSpan-derived pipelines that expand object vocabularies, generate hard spatial curricula, and perform bootstrapped labeling.
- Assumptions/dependencies: Data licensing; controlling bias and leakage; compute budgets for multi-stage re-training.
- Standard-setting and policy benchmarking for spatial intelligence
- Use case: Establishing benchmarks and procurement criteria for multimodal systems that must reason in 3D (public agencies, enterprises).
- Sector: Policy, Governance, Enterprise IT.
- Tools/products/workflows:
- Use SpaceSpan tasks and VSI-Bench reporting to set minimum performance and energy-efficiency thresholds; evaluate token-efficiency (K vs. accuracy) as a procurement metric.
- Assumptions/dependencies: Transparent datasets and reproducible evaluation; domain-relevant task suites; stakeholder agreement on metrics.
- Energy- and cost-aware multimodal inference on edge devices
- Use case: Sustained operation of spatially-aware apps on mobile/embedded hardware with strict power budgets.
- Sector: Edge AI, Semiconductors.
- Tools/products/workflows:
- Hardware–software co-design exploiting shorter sequences and streaming-friendly encoders; proxy pre-compute and caching.
- Assumptions/dependencies: Optimized implementations of SAM2/VGGT; quantization/pruning of VLM backbones; end-to-end latency targets.
Notes on feasibility across applications:
- Core dependencies: high-quality segmentation (SAM 2), geometry prediction (VGGT) with scale estimation, multi-frame capture, and an aligned VLM (e.g., Qwen2.5-VL) fine-tuned via the multi-stage curriculum.
- Domain shift: current evidence is strongest for indoor scenes (ScanNet/ARKitScenes). Outdoor, highly dynamic, or safety-critical applications will require additional data, calibration, and often reward learning.
- Performance profile: strong on counting, size, and distance reasoning; weaker (currently) on route planning and appearance order—plan to incorporate post-training with reward signals to close gaps.
- Privacy and licensing: ensure compliance for video capture; verify dataset/model licenses for commercial use; favor on-device processing where required.
Glossary
- 3D positional encoding: A method to embed 3D spatial coordinates into feature representations so models can reason over spatial structure. "Video-3D LLM \citep{video3dllm} achieves alignment using video frames via proposed 3D positional encoding."
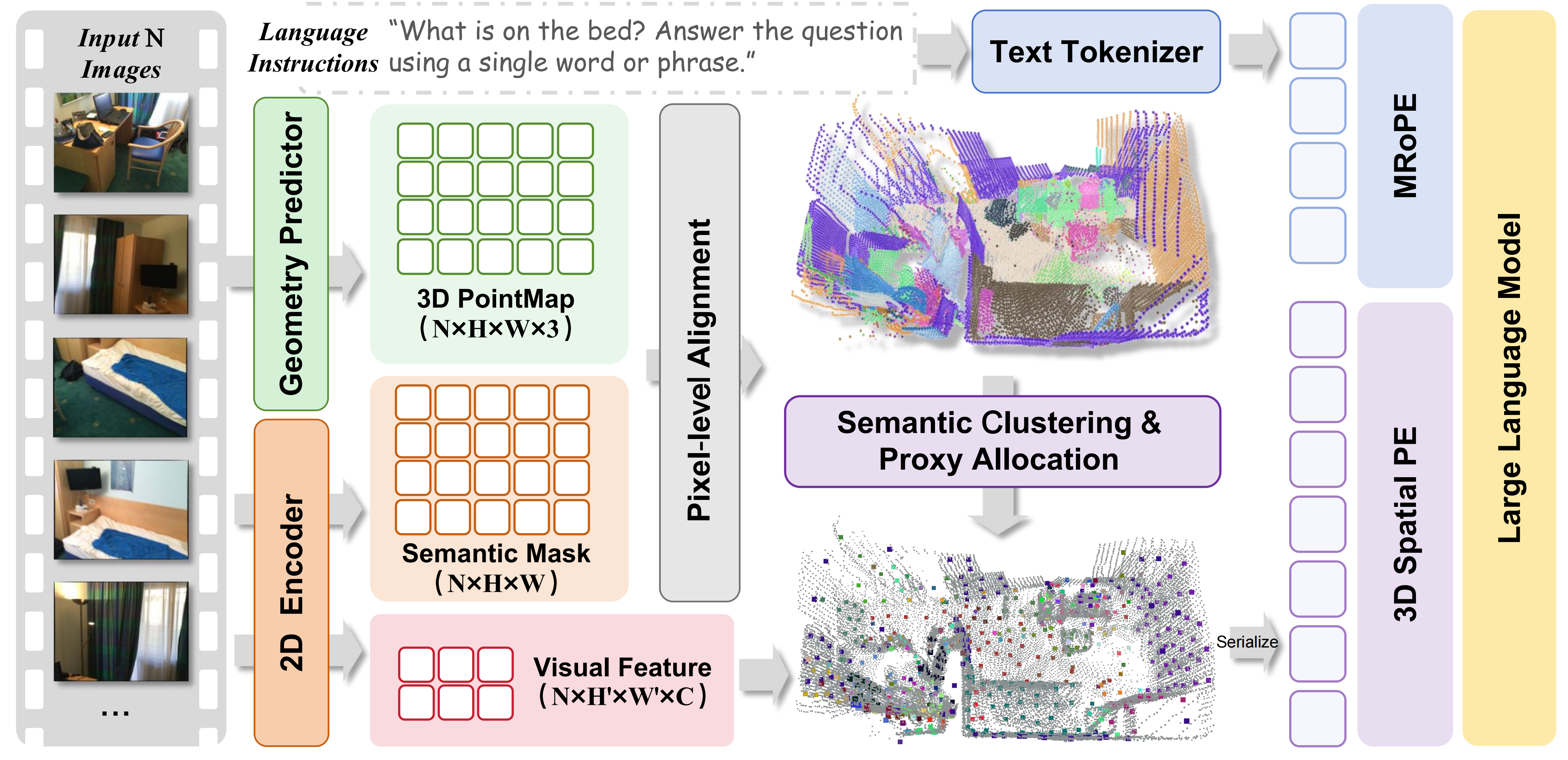
- 3D proxy representations: Compact tokenized representations that summarize 3D scene features for efficient input to LLMs. "we propose a Proxy3D method with compact yet comprehensive 3D proxy representations for the vision modality."
- 3D question answering (QA): A task where models answer questions about 3D scenes. "For 3D QA and DC benchmarks, we abbreviate performance metrics as "C" for CIDEr, "B-4" for BLEU-4, "M" for METEOR, "R" for ROUGE, and "EM" for top-1 exact match accuracy."
- 3D spatial position embeddings: Learnable positional encodings that inject 3D geometric priors into token embeddings. "3D spatial position embeddings."
- 3DGS: A 3D scene representation using Gaussian splats for rendering and reasoning. "point clouds \citep{pointllm, shapellm, ll3da}, depth maps \citep{spatialrgbt, spatialvlm}, 3DGS \citep{splattalk}, graphs \citep{3DGraphLLM}, and sparse spatiotemporal scene maps \citep{stsg}."
- Additive fusion: Combining two embeddings by element-wise addition to inject information directly into features. "by directly injecting identifier embeddings into serialized proxy embeddings through additive fusion."
- Autoregressive model: A model that generates outputs token-by-token, conditioning on previously generated tokens. "We minimize the negative -likelihood loss for the autoregressive model with parameters and 3D proxy representation in Equation (\ref{eq:final_sequence}) expressed by"
- Bird's-eye-view map: A top-down 2D projection of a 3D scene used as a vision modality. "Vision modalities (P - point clouds, I - images, B - bird's-eye-view map, D - depth)"
- Breadth-first search (BFS): A graph traversal strategy used here to order 3D proxies so spatial neighbors are sequence neighbors. "We apply Breadth-first search (BFS) \citep{zhou2006breadth} traversal to our 3D group centers in Equation (\ref{eq:proxy_definitions}) and serialize the 3D visual embeddings into a list of scene tokens, starting from the root node of the closest 3D segment to the origin."
- Canonical positional encoding: A normalized positional encoding scheme to provide consistent 3D location references. "SR-3D \citep{SR-3D} extends global 3D positional embedding with canonical positional encoding."
- Confidence thresholds: Thresholds used to evaluate numerical prediction accuracy across varying certainty levels. "We follow the VSI-Bench metric design and compute the mean exact accuracy for multiple-choice answers and the mean relative accuracy across confidence thresholds for numerical answers."
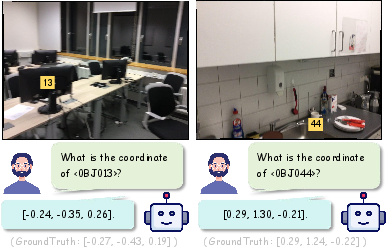
- Coordinate alignment: Training to align learned positional embeddings with true geometric coordinates. "Coordinate alignment stage helps an MLLM to precisely align 3D positional embeddings with geometric coordinates."
- Correspondence-based models: Models that infer 3D structure implicitly by matching features across views or frames. "correspondence-based models with implicit 3D scene understanding often fail to achieve spatial consistency"
- Cross-attention mechanism: Transformer attention between different token sets (e.g., vision and text) used to model relationships. "a na\"ive point cloud sequence cannot model the underlying complex spatial relationships using the cross-attention mechanism."
- Dense scene captioning: Predicting localized captions for many objects/regions across a scene. "Unlike VG, dense scene captioning (Scan2cap \citep{scan2cap}) estimates all object localizations and generates detailed descriptions."
- Exact match accuracy (EM): A metric for answer correctness that requires an exact string match. "For 3D QA and DC benchmarks, we abbreviate performance metrics as "C" for CIDEr, "B-4" for BLEU-4, "M" for METEOR, "R" for ROUGE, and "EM" for top-1 exact match accuracy."
- F1 score: The harmonic mean of precision and recall used for detection/localization tasks. "In 3D VG, we report unique accuracy ("Uni"), overall accuracy ("Acc") and F scores."
- Fourier embeddings: Learnable sinusoidal encodings that map continuous coordinates to a higher-dimensional feature space. "Following \citet{LEO-VL}, we use rotary position embeddings (RoPE) \citep{su2024roformer} to the vertical position indices , and learnable Fourier embeddings \citep{li2021learnable} to the width and length $\mathcal{{ W\times L }}."</li> <li><strong>Geometry predictor</strong>: A model that estimates geometric properties (e.g., depth/points) from images. "Next, we use a geometry predictor \citep{vggt} to extract a set of point maps $\{P_i\}_{i=1}^N$ from image frames"</li> <li><strong>Group Relative Policy Optimization (GRPO)</strong>: A reinforcement learning-based reward optimization method used to improve alignment. "it relies on post-training reward learning using group relative policy optimization (GRPO)~\citep{shao2024deepseekmath}."</li> <li><strong>Identifier embedding</strong>: A learnable embedding tied to an object instance identifier to enable precise referencing. "First, the identifier embedding is an embedding-text pair that functions as a feature that unifies accurate object referencing with positional awareness."</li> <li><strong>Inter-frame cross attention</strong>: Attention across frames inside the vision encoder to aggregate temporal/spatial information. "Inter-frame attention. We conduct an ablation study in Table~\ref{ablation} on a role of the inter-frame cross attention within a vision encoder."</li> <li><strong>K-nearest neighbors (KNN)</strong>: A clustering/aggregation method that groups points by nearest neighbors in feature or coordinate space. "we cluster the group-aware sets in Equation (\ref{eq:gl}) using $KK_g$ for each semantic group"</li> <li><strong>Latent dimension</strong>: The dimensionality of hidden feature vectors produced by encoders. "the size of each $F_i\in \mathbb{R}^{H'\times W'\times C}$ depends on the encoder's latent dimension $Cq$"</li> <li><strong>Latent-space clustering</strong>: Clustering in the feature space to compress and aggregate semantically similar tokens. "we can leverage latent-space clustering to semantically compress 3D scenes."</li> <li><strong>Multi-stage training</strong>: A staged training curriculum that progressively builds capabilities. "For representation alignment, we further curate the SpaceSpan dataset and apply multi-stage training to adopt the proposed 3D proxy representations with the VLM."</li> <li><strong>Multimodal LLMs (MLLMs)</strong>: LLMs that process and reason over multiple modalities (e.g., vision and text). "Recent vision-LLMs (VLMs) and more general multimodal LLMs (MLLMs) are equipped with a similar perception"</li> <li><strong>Negative log-likelihood loss</strong>: A standard loss for training autoregressive models by maximizing the likelihood of target tokens. "We minimize the negative $\log\mathbf{\theta}$ parameters"</li> <li><strong>Pixel-aligned representations</strong>: Feature representations that correspond directly to image pixels/patches. "most existing methods follow the conventional 2D pipeline in VLMs and use pixel-aligned representations for the vision modality."</li> <li><strong>Point clouds</strong>: Sets of 3D points representing scene geometry. "point clouds \citep{pointllm}"</li> <li><strong>Point maps</strong>: Per-pixel 3D coordinates predicted from images. "we use a geometry predictor \citep{vggt} to extract a set of point maps $\{P_i\}_{i=1}^NP_i \in \mathbb{R}^{H \times W \times 3}$."</li> <li><strong>Proxy allocation</strong>: Dynamically setting the number of proxy tokens per semantic group based on its size/importance. "Proxy allocation. We dynamically allocate $K_g$ based on each semantic group's proportion in the overall sequence \ie, $K_g \propto |\mathcal{G}_g|/L$."</li> <li><strong>Representation alignment</strong>: Aligning visual proxy features with LLM representations for joint reasoning. "For representation alignment, we further curate the SpaceSpan dataset and apply multi-stage training to adopt the proposed 3D proxy representations with the VLM."</li> <li><strong>Representation-based methods</strong>: Approaches that explicitly build structured 3D representations rather than relying on correspondences. "representation-based methods explicitly model 3D scenes by leveraging 2D image features obtained from a pretrained vision encoder."</li> <li><strong>Rotary position embeddings (RoPE)</strong>: Position encodings that rotate feature dimensions to inject relative position information. "we use rotary position embeddings (RoPE) \citep{su2024roformer} to the vertical position indices $\mathcal{H}$"
- Semantic-aware clustering: Clustering that uses semantic labels to group features before compression. "perform their semantic-aware clustering to obtain a set of proxies in the 3D space."
- Semantic grouping: Grouping features or tokens by semantic labels to preserve object-level structure. "Table~\ref{ablation} ablates our semantic grouping."
- Sequence serialization: Ordering features into a token sequence for Transformer processing while preserving spatial locality. "Proxy3D sequence serialization. We apply Breadth-first search (BFS) \citep{zhou2006breadth} traversal to our 3D group centers"
- Spatial semantic positional embeddings: Simplified embeddings that jointly encode object identity and spatial semantics. "we propose spatial semantic positional embeddings as an intermediate representation that bridges spatial representations with LLM latent sequences."
- Spatiotemporal reasoning: Reasoning over both spatial structure and temporal dynamics. "Other benchmarks \eg, VSI-Bench \cite{think} combine these tasks with spatiotemporal reasoning."
- Stable Diffusion: A generative model used here to synthesize semantic symbol images for embedding learning. "We apply Stable Diffusion \cite{stablediffusion} to generate images of the latter semantic symbols"
- Supervised finetuning: Training a pretrained model on labeled data to adapt it to new tasks. "We apply supervised multi-stage finetuning using (\ref{eq:sft}) objective for the pretrained Qwen2.5-VL-7B \citep{qwen25vl}."
- Visual grounding (VG): Localizing objects in scenes based on natural language descriptions. "Visual grounding (VG) identifies precise object locations using natural language queries."
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for multimodal reasoning. "Spatial intelligence in vision-LLMs (VLMs) attracts research interest with the practical demand to reason in the 3D world."
- Visual prompting: Supplying visual tokens/embeddings to steer model behavior or reference objects. "We extend visual prompting from 2D image to 3D feature space by directly injecting identifier embeddings into serialized proxy embeddings through additive fusion."
- VSI-Bench: A benchmark suite for evaluating 3D spatial reasoning across diverse tasks. "Recent VSI-Bench for spatial reasoning contains 5,000 question-answer pairs with eight spatial tasks, including multiple-choice and numerical answers."
Collections
Sign up for free to add this paper to one or more collections.