- The paper introduces MCM-VG, a novel framework that enforces multi-level consistency between 2D visual cues and 3D geometries for robust zero-shot visual grounding.
- It employs three integrated modules – Semantic Alignment, Instance Rectification, and Viewpoint Distillation – that synergistically overcome limitations of noisy 3D proposals.
- Empirical results on ScanRefer and Nr3D datasets show significant accuracy gains, validating MCM-VG's practical impact for embodied AI in complex scenes.
Robust Zero-Shot 3D Visual Grounding with Multiple Consistent 2D-3D Mappings
Introduction
The paper "Multiple Consistent 2D-3D Mappings for Robust Zero-Shot 3D Visual Grounding" (2604.26261) proposes MCM-VG, a framework addressing core challenges in open-world zero-shot 3D Visual Grounding (3DVG). Zero-shot 3DVG enables embodied agents to localize arbitrary objects in cluttered 3D environments based on free-form natural language queries, a critical capability for robotics and scene understanding. Existing zero-shot methods fundamentally depend on noisy open-vocabulary 3D proposals, rendering them susceptible to category mispredictions, geometric imprecision, and spatial redundancy during exhaustive multi-view reasoning. MCM-VG introduces explicit consistency enforcement between 2D observations and 3D geometries across semantic, instance, and viewpoint dimensions using a cascaded architecture comprising Semantic Alignment, Instance Rectification, and Viewpoint Distillation modules.
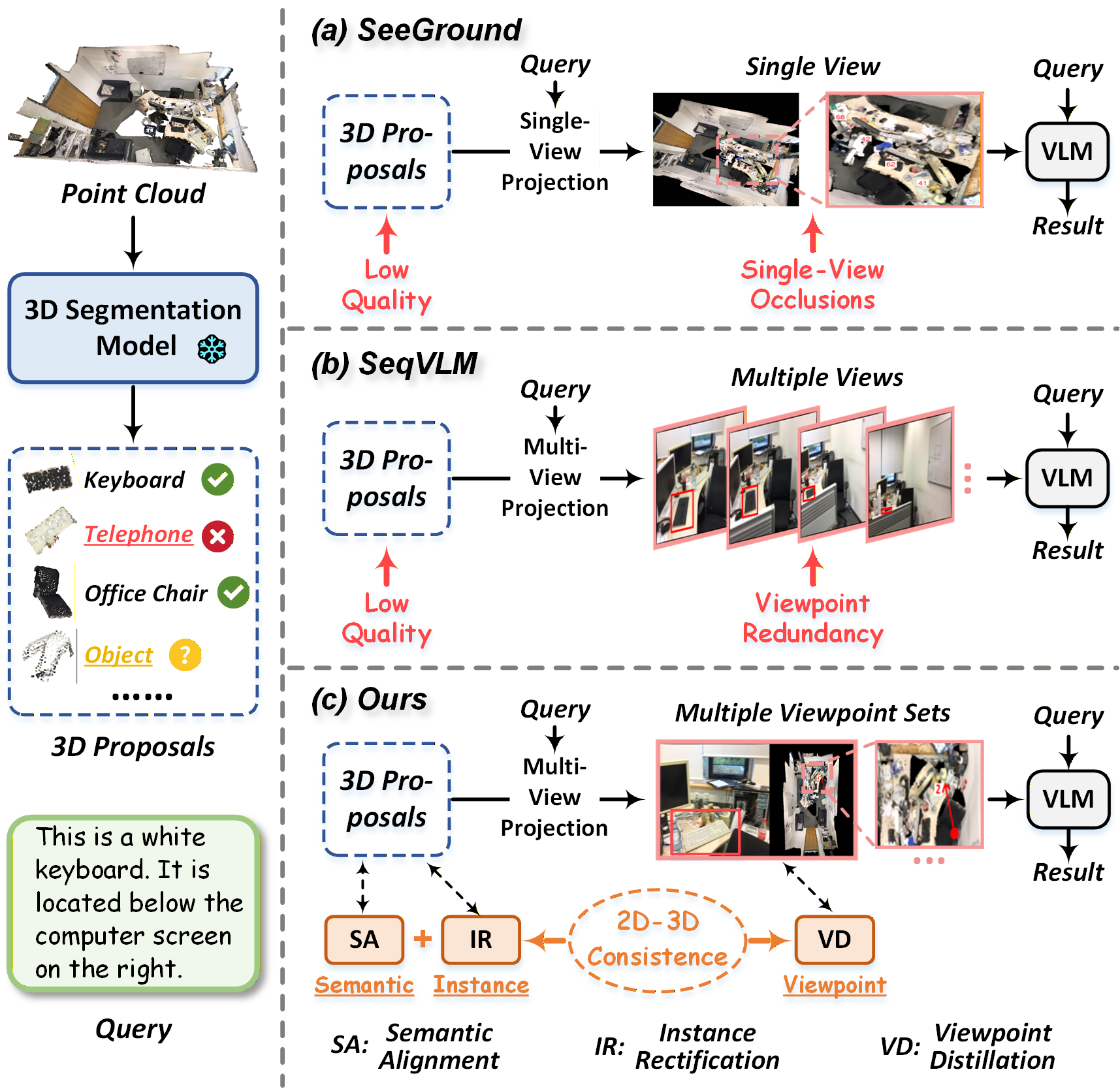
Figure 1: Comparative illustration of MCM-VG versus SeeGround and SeqVLM, highlighting multi-level 2D-3D consistency enforcement for improved 3D visual grounding.
Methodology
MCM-VG is systematically structured into three tightly integrated modules. Each module is designed to rectify specific deficiencies of prior zero-shot pipelines and collectively synthesize robust 2D-3D mappings for precise spatial grounding without task-specific 3D-text annotations.
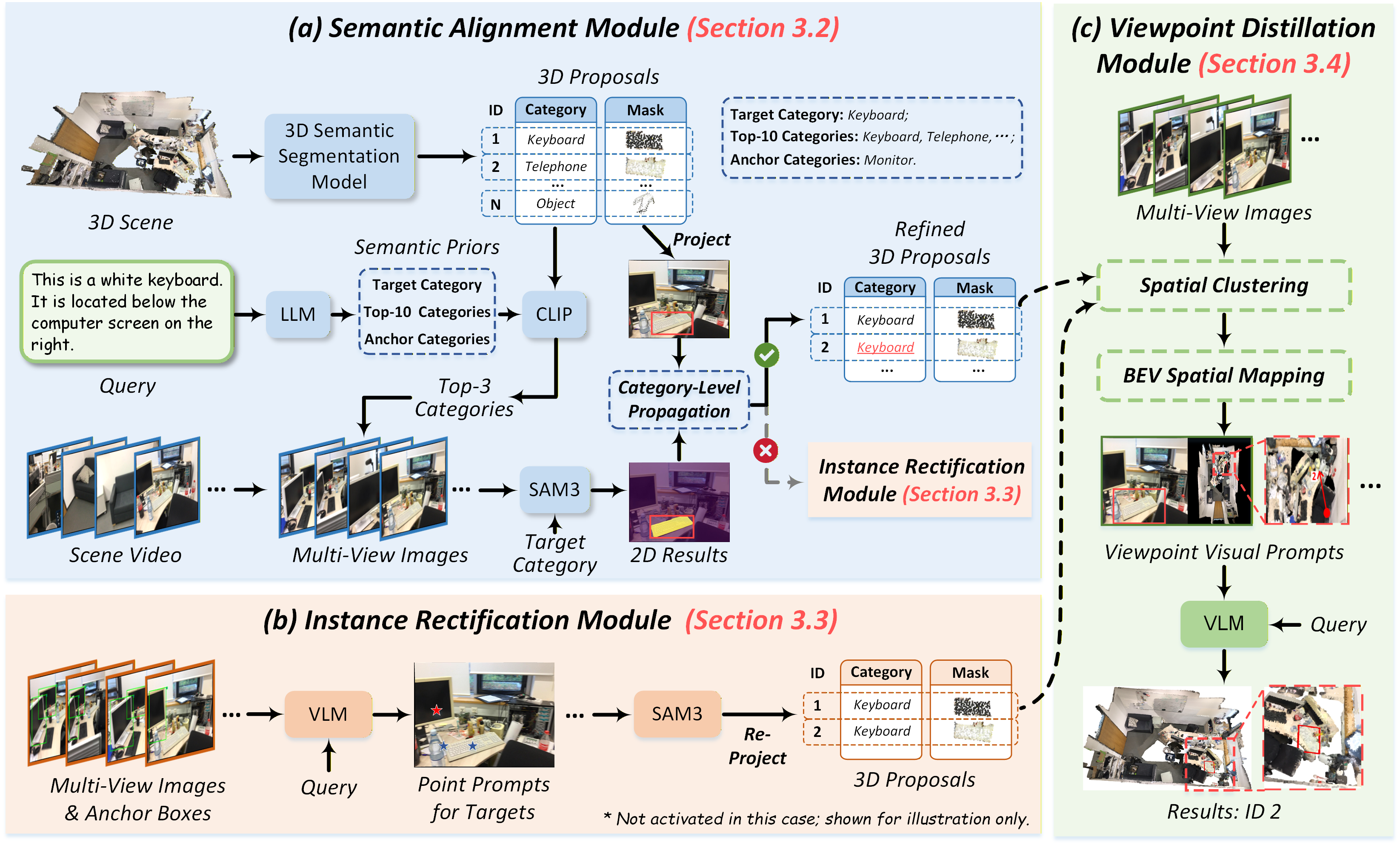
Figure 2: Schematization of the MCM-VG pipeline, outlining semantic alignment, instance rectification, and viewpoint distillation for zero-shot 3D visual grounding.
Semantic Alignment Module
Open-vocabulary 3D segmentation models suffer from brittle category prediction due to limited taxonomy and lack of full scene context. The Semantic Alignment module ameliorates this by parsing the language query with an LLM, extracting target and anchor categories, and obtaining top-10 candidate categories. Initial 3D proposals are projected onto multi-view 2D planes, followed by coarse-to-fine matching with CLIP text-visual embeddings to filter high-confidence candidates. Matched proposals undergo further validation using advanced text-driven 2D segmentation models. A spatial alignment score, based on multi-view IoU and confidence aggregation, is employed to refine the proposal set, propagate reliable semantics, and rectify mismatches, forming a semantically consistent object pool.
Instance Rectification Module
When initial 3D proposals fail due to geometric inaccuracies or complete miss-detection, the rectification module leverages 2D visual priors as robust fallback. Multi-modal VLMs, augmented with anchor-based frame selection, generate precise spatial point prompts (two positive, one negative per frame). These cues feed into 2D segmentation models (e.g., SAM3), yielding pixel-level masks, which are then back-projected into 3D space via depth-aware reconstruction and spatial denoising. This enables recovery of missing target geometries, immune to category and bounding box failures of standard 3D detectors.
Viewpoint Distillation Module
To counter spatial redundancy and inefficient VLM token consumption, the viewpoint distillation module quantifies camera directions for optimal frame selection. High-quality multi-view frames are clustered based on angular similarity, retaining only representative perspectives with maximal visibility. Each selected RGB frame is paired with a Bird's Eye View (BEV) map, annotated with spatial markers, directional arrows, and object IDs. Visual prompt pairs are concatenated, forming concise input sets for final VLM spatial reasoning—formulated as a multiple-choice task—achieving global spatial disambiguation.
Empirical Results
Extensive experiments on ScanRefer and Nr3D datasets demonstrate the efficacy of MCM-VG over both zero-shot and fully-supervised baselines. On ScanRefer, MCM-VG achieves 62.0% [email protected] and 53.6% [email protected], outperforming the previous best zero-shot method SeqVLM by absolute margins of 6.4% and 4.0%, respectively, and surpassing performance in the "Multiple" subset by up to 7.1% [email protected]. On Nr3D, MCM-VG achieves 57.2% overall accuracy, exceeding SeqVLM by 4.0%, with notable gains in the hardest splits.

Figure 3: Qualitative visualization of MCM-VG 3D grounding outputs on ScanRefer, exemplifying robust localization in cluttered, ambiguous scenarios.
Ablation analysis confirms that each module—Semantic Alignment, Instance Rectification, and Viewpoint Distillation—contributes non-trivially to final accuracy. Removing any one drops performance by 4–5%, with the largest penalty incurred by omitting spatial clustering in viewpoint distillation. Hyperparameter studies show robustness to parameter variation, with optimal values for semantic matching threshold (γ), angular clustering (ϵ), and multi-view frame count yielding stable gains.
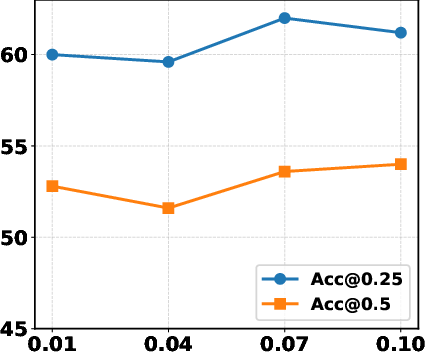
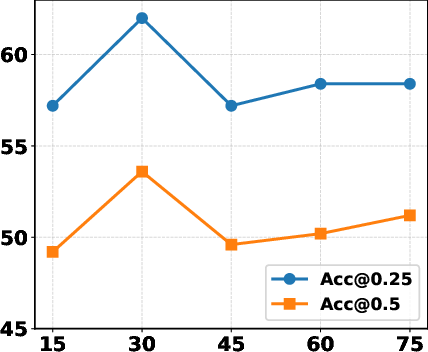
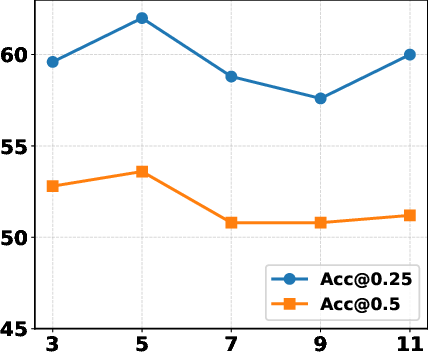
Figure 4: Performance sensitivity plot with respect to γ, documenting the effect of semantic alignment thresholding on grounding accuracy.
Comparative visualization against SeeGround and SeqVLM shows MCM-VG successfully addressing scenarios involving occluded or diminutive objects, where baseline approaches are frequently misled by category ambiguity or incomplete geometry.
Figure 5: Additional visualization results on ScanRefer, demonstrating consistency and resilience in diverse multi-instance, occluded settings.
Limitations
Despite strong accuracy, MCM-VG currently incurs high computational overhead due to sequential invocation of multiple foundation models (LLM, VLM, 2D/3D segmentation). This restricts deployment to offline or latency-flexible environments. The framework also depends on sufficient 2D view coverage—severe occlusion or truncation impedes 3D reconstruction by the rectification module. VLM spatial precision remains limited in highly cluttered scenes, potentially yielding ambiguous point prompts for segmentation. Robustness to adversarial viewpoints and model-distilled acceleration are cited as future directions.
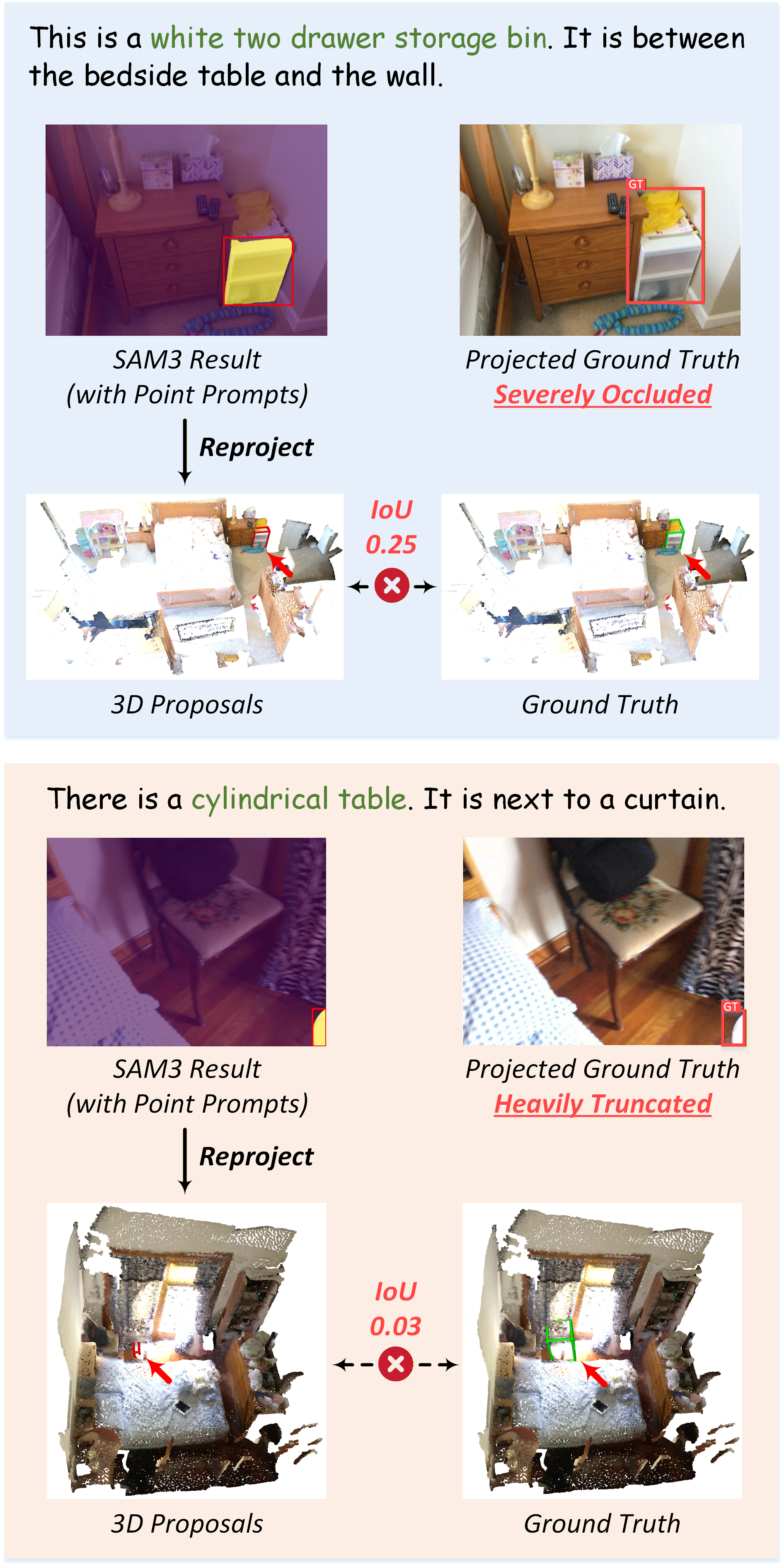
Figure 6: Failure cases illustrating degraded performance under extreme occlusion and marginal view truncation.
Implications and Future Directions
The explicit 2D-3D consistency enforced by MCM-VG represents a step toward harnessing self-supervised generalization in embodied AI agents without closed-set annotation dependence. Practically, this enables robust localization and interaction in open-world settings with unseen object categories, crucial for robotics and AR/VR. Theoretically, the modular framework validates the efficacy of joint semantic, geometric, and viewpoint alignment in overcoming proposal noise and redundancy, supporting future research into unified end-to-end architectures and tighter foundation model integration. Advances in spatially aware VLMs, real-time proposal rectification, and adversarial occlusion handling are promising avenues to further reduce the gap with full supervision.
Conclusion
MCM-VG offers a comprehensive solution to zero-shot 3D visual grounding by leveraging multiple consistent mappings between 2D visual cues and 3D geometries. Three cascaded modules synergistically rectify semantic mismatches, instance mislocalization, and viewpoint redundancy. Significant empirical gains over previous baselines validate the approach. While computationally intensive, MCM-VG successfully bridges modality gaps and unlocks the potential of foundation models for open-vocabulary spatial reasoning, setting the stage for practical, annotation-free embodied AI deployments.

