Echo: KV-Cache-Free Associative Recall with Spectral Koopman Operators
Abstract: Long chain-of-thought reasoning and agentic tool-calling produce traces spanning tens of thousands of tokens, yet Transformer KV caches grow linearly with sequence length, creating a memory bottleneck on commodity hardware. State-space models offer constant-memory recurrence but suffer a memory cliff: retrieval accuracy collapses once the gap between a stored fact and its query exceeds the effective horizon of the recurrent state. We introduce Echo, a KV-cache-free associative recall architecture built around Spectral Koopman Attention (SKA); a drop-in replacement for attention layers that augments SSM blocks with a closed-form dynamical operator whose sufficient statistics are accumulated in constant memory with no KV cache. Echo fits a spectral linear system to the key and value history via kernel ridge regression and retrieves through a learned power-iterated filter, all from $O(r{2})$ streaming state where $r$ is a small projection rank. On the Multi-Query Associative Recall benchmark, a pure Mamba-2 SSM fails to exceed chance accuracy (${\sim}3\%$) across all gap lengths and KV-pair counts, while at the 50M parameter scale SKA-augmented models achieve $100\%$ retrieval accuracy on every configuration tested, including distractor gaps of $4{,}096$ tokens with $32$ KV pairs. Across five additional transfer benchmarks including needle-in-a-haystack, tool-trace, and multi-hop retrieval, SKA consistently outperforms both pure SSM and SSM+Attention hybrids while maintaining constant inference memory. Ablations confirm that the spectral operator, not the prefix masking strategy, drives the retrieval gain.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI models to “remember and find” important information in very long texts without using a lot of memory. The method is called Echo, and its special part, Spectral Koopman Attention (SKA), helps a model recall facts from far back in a text—even across thousands of words—while keeping memory use small and steady.
What are the main questions the paper tries to answer?
- Can we build an AI that remembers specific facts across very long inputs without storing every past token (word/chunk) in memory?
- Can we avoid the “memory cliff” seen in some fast models (called state space models) where they quickly forget things as the text gets longer?
- Can we match or beat attention-based models at retrieval (finding the right information when asked) but with much lower memory costs?
How does Echo work (in simple terms)?
Think of reading a long story and being asked, thousands of words later, “What color was the car mentioned earlier?” Traditional attention-based models keep a huge “notebook” (the KV cache) of every detail to answer such questions—accurate, but memory-hungry. State space models (SSMs) keep only a tiny “summary card,” which is efficient but tends to forget details over time (the memory cliff).
Echo tries to get the best of both worlds:
- Instead of saving every past token like a notebook, Echo keeps a small set of “running tallies” (think: compact statistics) that summarize how keys (identifiers) and values (facts) relate.
- When a question (query) comes in, Echo uses those tallies to compute the best answer directly, like using a well-organized index rather than skimming all past pages.
Here’s the idea with friendly analogies:
- Keys, values, queries: Imagine labeling facts with tags (keys) and storing the facts (values). A question (query) finds the right tag to fetch the fact.
- Ridge regression (best-fit matching): Echo treats “find the value for this key” like fitting a best-match function from keys to values. Instead of storing every past thing, it keeps just enough summary info to solve that matching exactly when needed.
- Spectral Koopman operator (picking persistent signals): Think of a music equalizer that boosts steady, reliable notes and turns down background noise. Echo builds a tiny “dynamics” model that figures out which patterns in the keys are stable over time and boosts them, making it easier to find the right fact even in long, messy contexts.
- Constant memory: No matter how long the text is, the amount of memory Echo uses to remember stays almost the same—because it stores only the compact tallies, not every token.
In practice, Echo is a hybrid:
- It uses a fast backbone called a state space model (like Mamba-2) for local processing.
- It replaces heavy attention layers with SKA, which does compact “associative recall” (matching queries to stored facts) using those running tallies and the spectral filter.
- During generation, Echo keeps only small matrices per layer (not a growing cache), so memory use doesn’t grow with the text length.
What did the researchers test, and how?
They ran Echo on several tasks designed to stress long-range memory and retrieval:
- Multi-Query Associative Recall (MQAR): The model must remember multiple key–value pairs and retrieve the correct one after a long gap filled with distractors. This tests if the model can “find the right fact” even when that fact is far away.
- Transfer tests: Tasks like “needle-in-a-haystack” (find a single hidden fact in a very long text), tool-trace retrieval (finding steps from tool outputs), multi-hop retrieval (chaining multiple facts), and more.
- Language modeling: Training a small LLM from scratch and evaluating it on standard benchmarks to see if the new method hurts general understanding.
They compared:
- A pure state space model (fast, but tends to forget).
- A hybrid with traditional attention (accurate, but needs big memory for caches).
- The SKA-based Echo (their method).
What are the main results, and why do they matter?
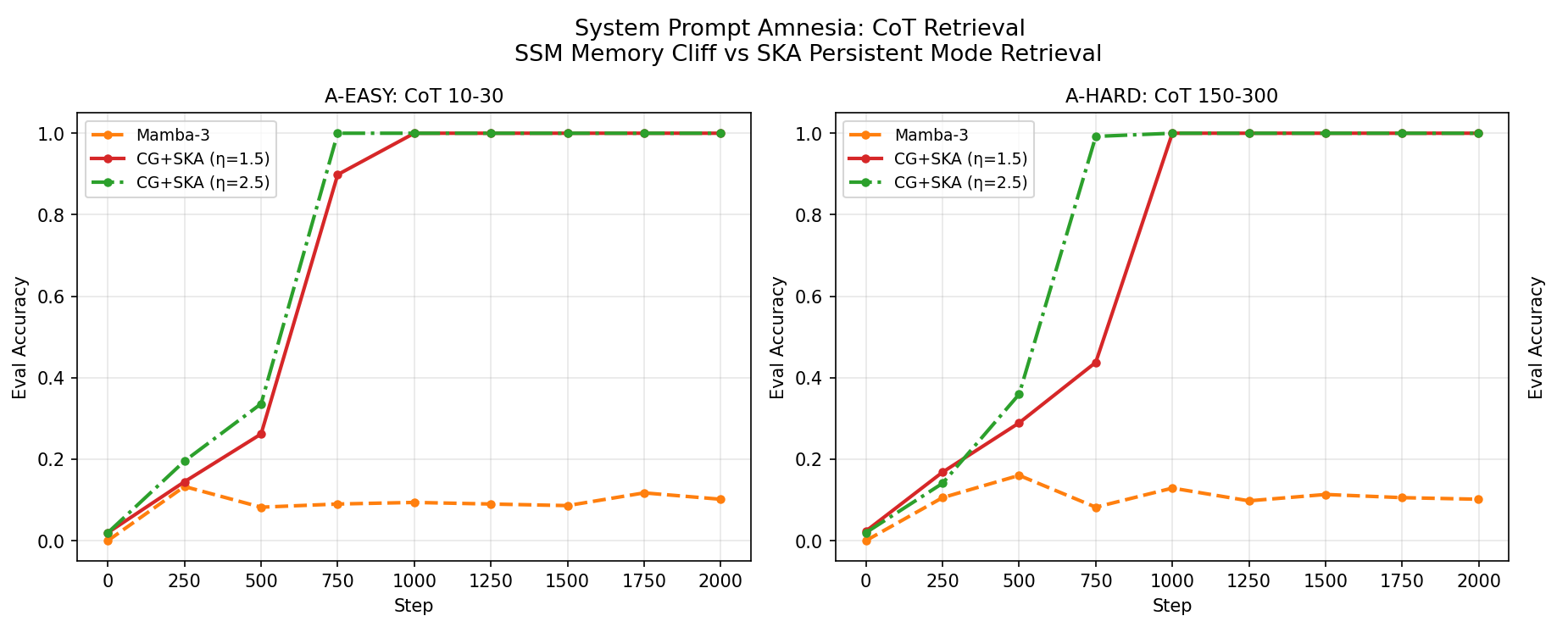
- Echo avoids the memory cliff: On the MQAR benchmark with 50M-parameter models, a pure state space model was near chance (~3%) across all settings, while the SKA-augmented model achieved 100% retrieval accuracy even with:
- Long gaps of 4,096 tokens (very long),
- Up to 32 key–value pairs (many things to remember).
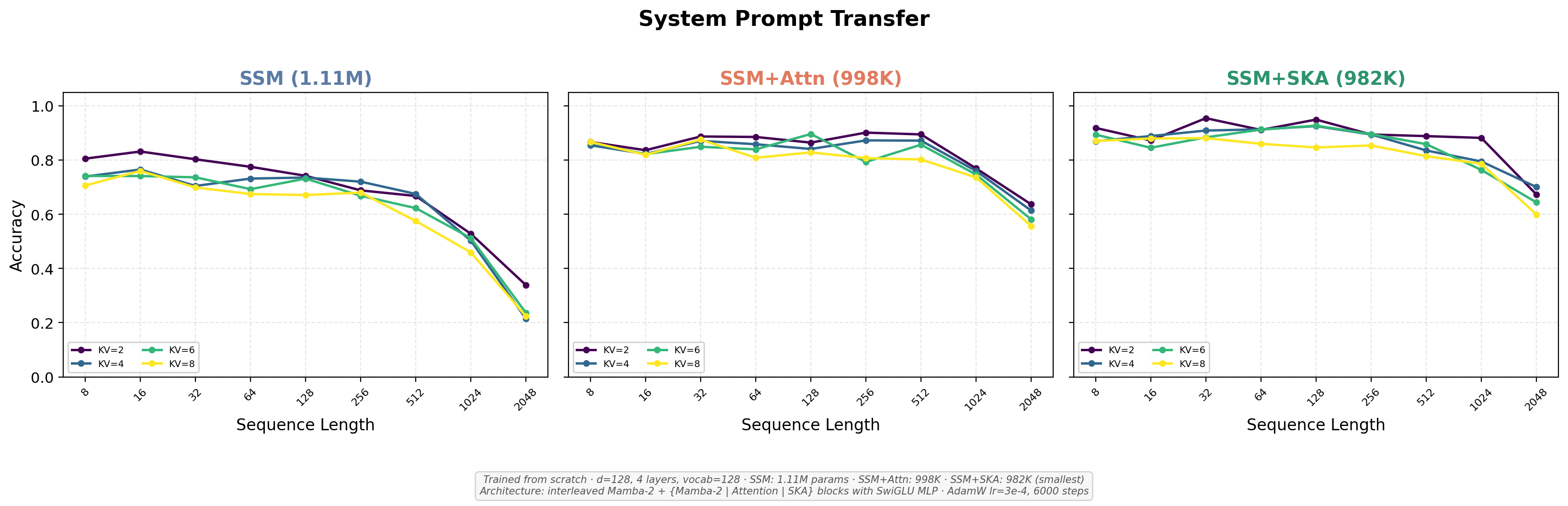
- Better retrieval across tasks: On five different retrieval tasks (including needle-in-a-haystack and multi-hop), Echo consistently outperformed both:
- Pure SSMs (which forgot over long distances),
- SSM+Attention hybrids (which helped but still used growing memory).
- Constant memory at inference: Echo’s memory does not grow with text length, so it can handle long contexts on regular hardware without running out of memory.
- Strong language modeling at small scale: A 180M-parameter Echo model, trained on fewer tokens than many competitors, matched or beat similar-size models on most of six standard benchmarks. This suggests Echo’s retrieval ability doesn’t hurt general language understanding.
Why this matters:
- It shows you don’t need the heavy, growing memory of attention to get strong long-range recall.
- It makes running long chain-of-thought or tool-using agents more practical on everyday hardware.
What could this change in the future?
- More capable long-context AIs on cheaper devices: Echo’s steady memory lets models handle very long histories (like chats, documents, or tool logs) without running out of memory.
- Faster and greener AI: Less memory pressure can mean lower costs and energy usage.
- Better reasoning over long traces: For tasks like planning, tracking multi-step tool outputs, or reading long documents, Echo’s reliable recall could make models more trustworthy and consistent.
In short: Echo shows a new path—using compact, mathematically grounded summaries (instead of giant caches)—to remember and retrieve facts across very long sequences. It keeps the memory low, the recall strong, and the performance competitive, pointing toward smarter, longer-context AI that runs efficiently.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper advances a KV-cache-free retrieval mechanism via Spectral Koopman Attention (SKA), but several aspects remain unvalidated or underexplored. The following concrete gaps can guide future research:
- Scalability beyond small models and modest data: Echo is only evaluated up to 180M parameters and ~10B tokens; behavior at 1B–70B scales and ≥100B–1T tokens remains unknown (e.g., stability, data efficiency, and retrieval at larger ranks and more layers).
- Wall-clock efficiency and latency: No end-to-end throughput/latency comparisons (prefill and decode) against strong attention baselines (e.g., FlashAttention-3) or cache-compaction methods (H2O, SnapKV) under identical hardware and context lengths.
- O(r3) per-step compute bottleneck: Inference requires FP32 Cholesky solves per step; the practical cost as r and number of heads/layers grow (and under long prefills) is not quantified, nor are alternatives (rank-1 Cholesky updates/downdates, Woodbury, LDLT, low-rank approximations).
- Mixed-precision and quantization readiness: SKA’s FP32 requirement and Cholesky stability under BF16/FP8 or aggressive quantization (int8/4-bit) are not studied, limiting deployment on accelerators and edge devices.
- Memory footprint at scale: Although O(1) in sequence length, aggregate SKA state across many layers and heads (and higher r) is not profiled for large models; feasibility on memory-constrained hardware (e.g., mobile, multi-tenant) is unclear.
- Sensitivity to rank r and hyperparameters: No systematic scaling laws or ablations for r, per-head rank allocation, number/placement of SKA layers, chunk size S, regularization ε, spectral scale γ, or power iterations K (beyond a single K=2 choice).
- Robustness to non-stationarity and topic shifts: Prefix-mode accumulation uses unwindowed statistics across the entire prefill; effects of topic changes, distribution shifts, or multi-session/dialogue contexts (e.g., need for decay/forgetting or sliding windows) are untested.
- Ambiguous/correlated keys and near-singular Gram matrices: Robustness when keys are highly collinear or adversarially similar, and whether adaptive regularization or conditioning strategies outperform a fixed ε.
- Retrieval in messy natural language: Synthetic tasks have clean bindings; targeted long-context benchmarks with naturalistic noise and structure (e.g., RULER, BABILong, SCROLLS, Qasper) are not reported.
- Multi-hop and compositional retrieval beyond 2-hop: While some two-hop gains are shown, the capacity and failure modes for deeper composition (3–5 hops) are uncharacterized; how K and A_w shape multi-step retrieval remains unclear.
- Integration with real agentic workflows: No evaluations on realistic tool-use traces, long function-call chains, or retrieval-augmented generation with large document sets and imperfect retrievers.
- Bidirectional/encoder use cases: “Masked mode” for bidirectional or retrieval encoding is proposed but not empirically validated against dense retrievers or encoder-only transformers on IR tasks.
- Interaction with SSM backbone: The optimal ratio, spacing, and coupling of SKA to SSM layers (and potential interference) are not mapped; whether more/fewer SKA layers help/hurt LM quality or retrieval remains open.
- Position/temporal encoding in SKA: How temporal order is encoded by SKA’s projections and A_w, and whether explicit positional features improve temporal retrieval or multi-hop reasoning, is not analyzed.
- Gradient-flow claims vs attention: Theoretical claims about gradient rank preservation are not backed by empirical diagnostics (e.g., singular value spectra of Jacobians, gradient norm propagation, training stability comparisons).
- Comparisons to Test-Time Regression (TTR) family: No head-to-head with MesaNet, Gated DeltaNet, or related exact/approximate least-squares solvers on standardized retrieval tasks to quantify SKA’s spectral filter advantage.
- Effect of independent projections: The decision not to share features with the SSM is justified qualitatively; ablations quantifying trade-offs (performance, parameter count, compute) are missing.
- Normalization choice and outliers: Sequence-max normalization may overweight rare high-norm tokens; robustness to outliers and distribution shifts (and alternatives like per-channel normalization or robust norms) is untested.
- Stability under extreme context lengths: Claims of arbitrary-length inference are not stress-tested beyond ~4k tokens for retrieval; numerical drift and operator conditioning at 32k–1M contexts need measurement.
- Operator update strategy during decoding: SKA “re-estimates the operator” each step, implying frequent Cholesky factorizations; amortization strategies, update frequency trade-offs, and their impact on quality and latency are not explored.
- Quantitative ablations of the power filter: The contribution of A_wK (vs K=0 ridge-only) is asserted but lacks thorough sensitivity/robustness analyses across tasks and noise regimes.
- Koopman MLP generality: Replacing SwiGLU with a spectrally constrained MLP reduces parameters, but its expressivity on diverse tasks (syntax/semantics, multilingual, math, code) and interaction with SKA are not comprehensively evaluated.
- Safety, privacy, and memorization: Constant-memory accumulation of sufficient statistics across long prefixes may amplify recall of sensitive content; risks of unintended memorization and mitigation strategies are not discussed.
- Fairness of baseline comparisons: Some baselines use different token budgets (e.g., 100B vs 10B); controlled comparisons with matched data/training compute are needed to isolate architectural effects.
- Reproducibility and kernelization: Custom Triton kernels and numerical fallbacks are mentioned, but code release, exact seeds, and reproducibility guarantees (including handling of Cholesky failures) are not detailed.
- Modality and architecture generality: It is unknown how SKA transfers to encoder-decoder settings, multimodal models, speech/vision sequences, or RL/policy inference where dynamics differ.
- Dense retrieval and hybrid systems: How SKA complements external memory or vector databases (e.g., in-RAG pipelines), and whether its statistics can be reset/segmented per document or tool-call, is unaddressed.
- Failure modes under noise and adversaries: Stress tests for noisy prefixes, adversarial prompts that induce near-singular Gram matrices, or distractors tuned to exploit the regression objective have not been performed.
- Energy efficiency: Although KV memory is reduced, the energy/compute cost of repeated small-matrix FP32 factorizations versus attention’s large but fused kernels is not measured.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that take advantage of Echo’s KV-cache-free Spectral Koopman Attention (SKA), constant-memory recurrent inference, and data-efficient training behavior.
- Sector: Software/AI infrastructure
- Use case: Long-context inference with bounded memory in LLM serving (replace or augment attention in SSM-heavy hybrids to eliminate KV-cache growth).
- Tools/products/workflows: vLLM/TGI-style “KV-free” inference backends; PyTorch/Triton SKA kernels; adapters to swap selected attention blocks for SKA in existing hybrid models; autoscaling policies that leverage constant memory to pack more sessions per GPU.
- Assumptions/dependencies: Requires models trained or fine-tuned with SKA (drop-in at inference for attention weights is not supported); FP32 Cholesky and spectral normalization currently introduce small-matrix O(r3) latency—custom kernels may be needed for tight SLAs; rank r tuning (≤64) trades accuracy vs. latency.
- Sector: Agentic systems/tool use (software, DevOps, data engineering)
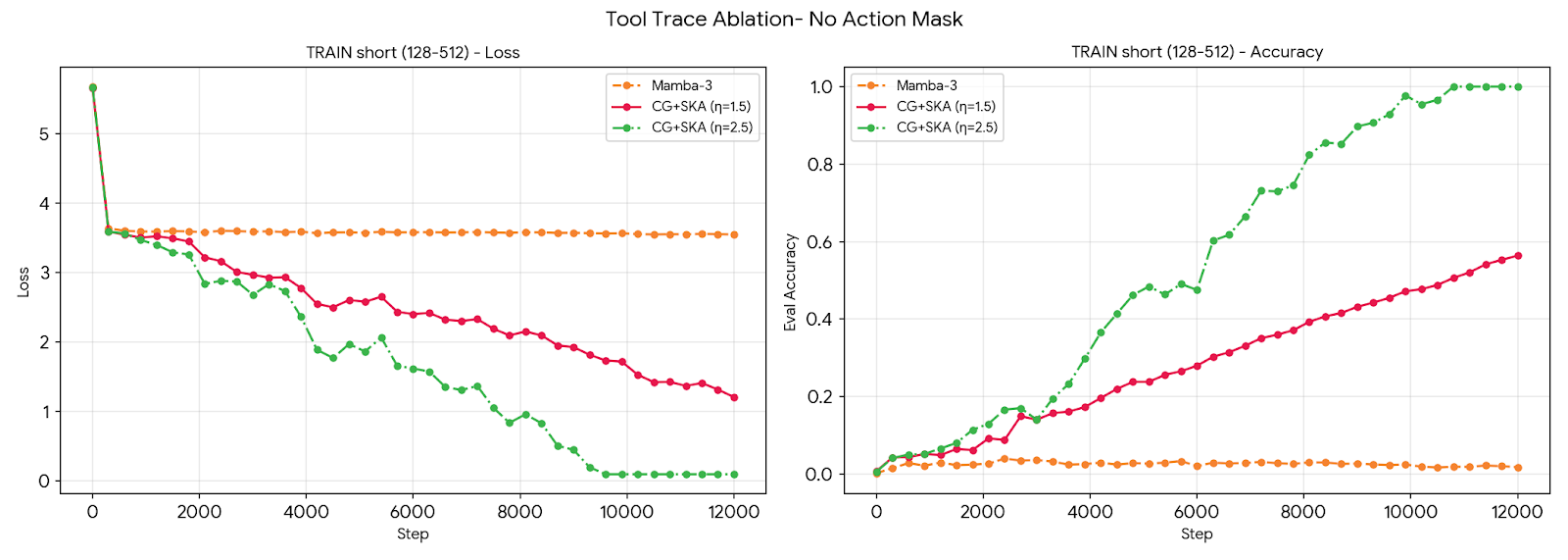
- Use case: Reliable recall over long tool traces and multi-step plans without KV eviction, enabling robust multi-hop tool-calling and debugging of agents.
- Tools/products/workflows: LangChain/LangGraph integrations that run SKA in prefix mode over tool outputs and logs; “trace-aware” planners that carry SKA statistics across turns; incident runbook agents that recall 100k+ token logs with constant memory.
- Assumptions/dependencies: Tool traces must expose discriminative key/value features (projection quality matters); prefix normalization frozen at prefill must be respected across steps; ensure numerical stability (ridge ε and sequence-max normalization) in mixed-precision stacks.
- Sector: Retrieval-augmented generation (RAG) and document QA
- Use case: Reading and querying very long contexts (legal briefs, tech specs, scientific articles) with constant-memory recall; improved “needle-in-a-haystack” and multi-hop retrieval.
- Tools/products/workflows: SKA “masked mode” encoders for bidirectional retrieval; hybrid RAG that uses SKA for in-context associative recall while external vector stores handle corpus-scale search; summarization that preserves persistent bindings via the Koopman power filter.
- Assumptions/dependencies: Quality depends on projection head training and appropriate r; complex natural-language retrieval may need domain-tuned fine-tuning; latency of Cholesky per step should be amortized via chunking during prefill.
- Sector: Customer support/contact centers
- Use case: Multi-session chat assistants that recall long histories and past resolutions on commodity GPUs/CPUs.
- Tools/products/workflows: SKA-enabled chat backends in Zendesk/Salesforce integrations; session-scoped SKA state for “always-on memory” without context replay; cost dashboards showing memory savings vs. KV-cached stacks.
- Assumptions/dependencies: Fine-tuning on support transcripts recommended; guardrail policies needed to manage recall scope and privacy; 180M-class models may need distillation or larger SKA-augmented backbones for production quality.
- Sector: Healthcare
- Use case: On-prem EHR summarization and longitudinal patient timeline recall with bounded memory footprint.
- Tools/products/workflows: SKA prefix mode to accumulate statistics over a patient’s chart; clinician-facing summarizers that withstand long distractor gaps; edge servers for privacy-preserving deployments.
- Assumptions/dependencies: Requires clinical fine-tuning and rigorous validation; protected health information constraints favor on-prem/edge; current scale (≤180M) is better for pilot/prototyping than broad clinical deployment.
- Sector: Finance and compliance
- Use case: Audit-trail and transaction-graph recall across long event sequences without KV-cache overhead.
- Tools/products/workflows: SKA-based log readers for AML/alert investigations; compliance assistants that maintain persistent bindings from policy documents throughout long cases.
- Assumptions/dependencies: Domain-specific fine-tuning and evaluation needed; careful handling of spurious persistent modes (spectral filter K) to avoid amplifying noise.
- Sector: IDEs and code intelligence
- Use case: Cross-file code assistants that recall large repositories and tool outputs (tests, build logs) without memory cliffs.
- Tools/products/workflows: VS Code/JetBrains extensions with SKA-augmented SSM backends; prefix-mode recall across REPL/unit-test traces; “KV-free” long-context code completion.
- Assumptions/dependencies: Projection heads must learn discriminative keys for symbols/paths; latency budget must accommodate O(r3) solves (often acceptable for r≤64).
- Sector: Meetings/knowledge management (daily life and enterprise)
- Use case: On-device or edge summarizers that recall long meeting transcripts, notes, and emails with constant memory.
- Tools/products/workflows: Desktop/mobile assistants that maintain SKA state for daily journals; enterprise note systems with reliable long-context recall without specialized GPUs.
- Assumptions/dependencies: Mobile deployments may need integer/fp16-friendly Cholesky approximations; energy constraints on-device; privacy and consent policies for persistent recall.
- Sector: Academia (ML research and education)
- Use case: Low-compute labs replicating long-context behavior without KV cache; teaching modules on in-context learning as explicit regression; Koopman operator labs.
- Tools/products/workflows: Open-source SKA layers for PyTorch/JAX; small-scale (≤1M params) curricula demonstrating elimination of the SSM “memory cliff”; benchmarks targeting spectral persistence vs. attention entropy.
- Assumptions/dependencies: Clean-room reimplementations need numerically stable FP32 accumulators; careful evaluation on natural-language retrieval beyond synthetic MQAR.
- Sector: Policy and sustainability
- Use case: Immediate energy/cost assessments for long-context LLM services favoring constant-memory inference; privacy-by-design deployments (on-prem/edge) that avoid cloud KV-cache persistence.
- Tools/products/workflows: Procurement checklists that score models on O(1) inference memory; guidance to disable KV-caching for sensitive contexts; emissions reporting that attributes savings from KV-free stacks.
- Assumptions/dependencies: Independent audits to quantify wall-clock and energy gains (latency can offset memory savings); clear data retention policies for SKA statistics.
Long-Term Applications
These opportunities likely require further research, scaling, systems integration, or hardware support before broad deployment.
- Sector: Foundation models and hosting platforms
- Use case: Billion-parameter LLMs with KV-free long-context (≫100k tokens) at production quality.
- Tools/products/workflows: Training recipes that interleave SSM and SKA across depth; rank-autotuning and operator sharing across layers; KV-free serving in vLLM/TensorRT-LLM.
- Assumptions/dependencies: Demonstration at 1B–70B scales; fused FP16/BF16-safe Cholesky/power-iteration kernels; scheduler-level support for per-layer small-matrix pipelines.
- Sector: Hardware/accelerators
- Use case: Architectural support for small dense linear algebra (Cholesky/triangular solves, power iterations) to accelerate SKA’s O(r3) path.
- Tools/products/workflows: GPU/TPU libraries with batched tiny-matrix solvers; NPU instructions and SRAM tiling for r≤64; compiler passes that fuse SKA chains.
- Assumptions/dependencies: Vendor ecosystem adoption; numerical robustness in reduced precision; kernel auto-tuning for different r/H configurations.
- Sector: Lifelong/episodic memory in agents
- Use case: Cross-session associative memory by persisting and updating SKA sufficient statistics over weeks/months, enabling “always-learning” personal and enterprise assistants.
- Tools/products/workflows: Memory stores that checkpoint G, M, C_v per domain/workspace; decay/refresh strategies guided by eigenvalue persistence; privacy-preserving retention policies.
- Assumptions/dependencies: Robust handling of domain shift and catastrophic interference; governance for long-lived memory; mechanisms to forget/redact selectively.
- Sector: Robotics and real-time control
- Use case: Constant-memory recall of rare events and procedures from long trajectories; policy conditioning on persistent modes for long-horizon tasks.
- Tools/products/workflows: Edge inference stacks with SKA-enabled SSMs; event-triggered updates to Koopman operators during autonomy runs; diagnostics replay that preserves long-range bindings.
- Assumptions/dependencies: Tight real-time constraints require hardware acceleration; integration with policy learning (RL/IL) and safety validation.
- Sector: Security/observability (SIEM, AIOps)
- Use case: Streaming detection of persistent patterns using the Koopman spectrum; KV-free analytics over months of logs with associative recall for root-cause analysis.
- Tools/products/workflows: SKA operators embedded in log pipelines; spectral alerts on emergent persistent modes; “needle-in-a-haystack” RCA assistants with constant memory.
- Assumptions/dependencies: Calibration to reduce false positives from spurious persistent modes; domain-specific projections and supervision.
- Sector: Education
- Use case: Semester-long tutoring systems recalling a learner’s full trajectory on low-cost hardware.
- Tools/products/workflows: Edge deployment on school devices; per-student SKA states that personalize explanations and practice.
- Assumptions/dependencies: Child privacy protections; content moderation; efficacy studies in real classrooms.
- Sector: Scientific computing and bioinformatics
- Use case: Long-sequence modeling (genomics, proteomics, materials) where attention memory is prohibitive; associative recall of rare motifs across ultra-long reads.
- Tools/products/workflows: SKA encoders for long-read pipelines; operator libraries tuned for scientific sequences; hybrid models combining SKA with domain-specific kernels.
- Assumptions/dependencies: Domain adaptation of projections; rigorous benchmarking vs. specialized transformer variants; uncertainty quantification.
- Sector: Standards and policy
- Use case: Benchmarks and certification for long-context reliability that emphasize constant-memory retrieval and length generalization.
- Tools/products/workflows: Public suites extending MQAR/RULER/BABILong with persistent-mode diagnostics; procurement standards requiring O(1) inference memory for sensitive workloads.
- Assumptions/dependencies: Community consensus on metrics; reproducible measurement of memory/latency/energy trade-offs.
- Sector: Software ecosystem
- Use case: “Echo Memory Layer” as a first-class primitive in ML frameworks and agent stacks; rank-autotuning and hybrid RAG–SKA orchestration.
- Tools/products/workflows: PyTorch/JAX primitives for SKA ops; schedulers that decide when to update operators vs. reuse; devtools that visualize Koopman spectra for debugging.
- Assumptions/dependencies: API stability across frameworks; interpretability and safety tooling to prevent harmful persistence amplification.
Notes on overarching assumptions/dependencies
- Scaling: Evidence is strong at ≤180M parameters; results must be validated at billion-parameter scales and on natural-language retrieval benchmarks beyond synthetic MQAR.
- Kernels and precision: Current FP32 Cholesky/solves add latency; practical deployments will benefit from fused, reduced-precision kernels with numerical safeguards.
- Training: Benefits rely on training with SKA layers (independent projections, ridge regularization, sequence-max normalization); naïve post-hoc swaps are unlikely to work.
- Task fit: SKA excels at associative recall with persistent bindings; tasks dominated by fine-grained pairwise interactions may still favor full attention or hybrids.
- Governance: Persistent eigenmodes can over-amplify spurious correlations; organizations should pair SKA with auditability, redaction, and privacy controls.
Glossary
- Ablation: An experimental technique that removes or alters components to assess their impact on performance. "Ablations confirm that the spectral operator, not the prefix masking strategy, drives the retrieval gain."
- Agentic inference: A setting where a model processes long tool or interaction prefixes before generating outputs. "Prefix mode (agentic inference)."
- Associative recall: The ability to retrieve a stored value given its paired key within a sequence. "On the Multi-Query Associative Recall benchmark,"
- Autoregressive decoding: Generating tokens one at a time where each output depends on previously generated tokens. "During autoregressive decoding, is frozen at the prefill value to prevent mixing normalization scales across accumulated statistics."
- Bayes-optimal: Optimal under a Bayesian model with a specified prior, minimizing expected loss. "and that this one-step predictor is Bayes-optimal under a Gaussian prior."
- BF16: A 16-bit floating-point format (bfloat16) commonly used for efficient training on accelerators. "using DeepSpeed ZeRO Stage 1 with BF16 on a single NVIDIA B200."
- Block-diagonal rotation: A transformation that applies independent 2×2 rotations across vector pairs, often to enforce spectral constraints. "Block-diagonal rotation."
- Causal attention: An attention mechanism restricted to attend only to past positions to preserve autoregressive causality. "Hybrid architectures interleave SSM layers with causal attention blocks,"
- Cholesky factorization: A matrix decomposition for positive-definite matrices used to solve linear systems efficiently. "and solves the ridge system once per chunk via Cholesky factorization."
- Conjugate gradient: An iterative method for solving large symmetric positive-definite linear systems. "MesaNet solves this objective to optimality via conjugate gradient."
- Content-addressed retrieval: Retrieving information by similarity of content (keys/queries) rather than position. "We observe that content-addressed retrieval can be recast as kernel ridge regression"
- Cross-temporal covariance: A statistic capturing correlations between consecutive time steps of key representations. "SKA estimates its operators from three sufficient statistics: a regularized Gram matrix , a cross-temporal covariance , and a value-key covariance ."
- DeltaNet: A family of efficient attention-like architectures viewed as approximate solvers of online least-squares objectives. "the test-time regression (TTR) framework unifies linear attention, DeltaNet, Gated DeltaNet, and MesaNet"
- Effective rank: The number of significant singular values of a matrix, reflecting its information-carrying capacity. "each softmax attention layer's backward pass compresses gradients by its entropy-dependent effective rank"
- Exclusive prefix sum: A cumulative sum operation that excludes the current element, often used for causal accumulation. "with a one-position shift (exclusive prefix sum)."
- Flash attention: A memory-efficient attention implementation that reduces memory traffic while preserving exact results. "Flash attention~\citep{dao2023flashattention} reduces the constant factor but memory remains : the full KV cache must still be stored and scanned at each decoding step."
- Gated DeltaNet: A gated variant of DeltaNet that enhances expressivity while solving online least-squares objectives. "Gated DeltaNet~\citep{yang2025gated}"
- Gram matrix: A matrix of inner products of vectors (e.g., keys) used in kernel methods and ridge regression. "a regularized Gram matrix "
- HBM (High Bandwidth Memory): On-package memory providing high throughput for accelerators, distinct from on-chip SRAM. "without HBM round-trips."
- Kernel ridge regression: A regularized least-squares method in a reproducing kernel Hilbert space used here for content retrieval. "content-addressed retrieval can be recast as kernel ridge regression"
- Koopman operator theory: A framework that studies nonlinear dynamics via linear operators acting on observables. "Koopman theory analyzes nonlinear dynamical systems through linear operators on observable functions"
- Koopman power filter: A procedure that repeatedly applies a transition operator to amplify persistent eigenmodes and suppress transients. "The Koopman power filter (\S\ref{app:power_filter}) then adds spectral selectivity"
- KV cache: Stored keys and values from prior tokens used by attention during inference, typically growing with sequence length. "Transformer KV caches grow linearly with sequence length, creating a memory bottleneck on commodity hardware."
- Linear attention: An attention variant with linear complexity that approximates softmax attention but often omits certain normalization factors. "Linear attention computes only "
- Mamba-2: A selective state space model variant providing linear-time, constant-memory sequence modeling. "For from-scratch LLM training we use Mamba-2~\cite{dao2024mamba2},"
- Masked mode: A bidirectional encoding setting where operator statistics are computed over visible (unmasked) positions only. "Masked mode (retrieval)."
- Memory cliff: A failure mode where SSM retrieval accuracy collapses as the distance between stored facts and queries grows. "a failure mode we call the memory cliff."
- MesaNet: A model that solves the online least-squares objective to optimality, serving as a TTR framework reference point. "MesaNet solves this objective to optimality via conjugate gradient."
- Multi-hop retrieval: Retrieving answers requiring multiple chained reasoning steps or references. "Across five additional transfer benchmarks including needle-in-a-haystack, tool-trace, and multi-hop retrieval,"
- Multi-Query Associative Recall (MQAR): A benchmark testing retrieval of multiple key–value pairs across distractor gaps. "On the Multi-Query Associative Recall benchmark,"
- Needle-in-a-haystack: A retrieval benchmark where a small relevant snippet must be found in a long distracting context. "Across five additional transfer benchmarks including needle-in-a-haystack, tool-trace, and multi-hop retrieval,"
- Power iterations: An iterative method to estimate dominant singular values or eigenvalues of a matrix. "leading singular value (6 power iterations, detached)"
- Preconditioned gradient descent: Gradient descent applied with a transformation to improve conditioning and convergence speed. "provably converges to one step of preconditioned gradient descent on the least-squares objective"
- Ridge regression: A least-squares regression with L2 regularization to stabilize inversion of ill-conditioned Gram matrices. "prove by construction that a transformer with constant depth and hidden width can compute the closed-form ridge regression solution"
- RoPE (Rotary Positional Embeddings): A positional encoding technique that rotates token representations to encode relative positions. "2 Mamba-2 + 2 causal attention layers with RoPE"
- Sequence-max normalization: Scaling keys/queries by the maximum norm over a sequence to preserve relative magnitudes. "Unlike per-token -normalization (which inflates low-norm noise tokens to unit norm), sequence-max normalization preserves the relative norm structure"
- Sherman–Morrison updates: Rank-one matrix inverse updates used to incrementally solve least-squares problems. "iterative Sherman-Morrison rank-one updates"
- SiLU: The Sigmoid Linear Unit activation function used in the Koopman MLP. ""
- Spectral Koopman Attention (SKA): A constant-memory retrieval module that fits a spectral linear system and performs associative recall without a KV cache. "Spectral Koopman Attention (SKA); a drop-in replacement for attention layers"
- Spectral normalization: Constraining an operator by its largest singular value to stabilize dynamics and training. "Spectral normalization."
- Spectral radius: The magnitude of the largest eigenvalue of a matrix, governing stability of repeated applications. "This bounds the spectral radius, preventing unbounded amplification"
- Sufficient statistics: Aggregated quantities (e.g., covariances) that capture all information needed for a particular estimation task. "The central insight is that these statistics are additive: each new token contributes to , to , and to "
- SwiGLU: A gated feedforward architecture used in Transformers as a baseline MLP block. "SwiGLU~\cite{shazeer2020glu} uses three matrices"
- Test-time regression (TTR): A framework interpreting various attention variants as solvers of an online least-squares objective at inference. "the test-time regression (TTR) framework~\citep{tumma2026preconditioned} unifies linear attention, DeltaNet, Gated DeltaNet, and MesaNet"
- Triton kernel: A custom GPU kernel written with Triton to fuse and accelerate matrix operations. "fused into a single Triton kernel that loads , , , into SRAM"
- Whitening: Transforming variables to have identity covariance to improve conditioning of subsequent operations. "Whitening via makes eigenvalues interpretable as persistence"
- ZeRO Stage 1: A DeepSpeed optimizer partitioning strategy that reduces memory by sharding optimizer states. "using DeepSpeed ZeRO Stage 1 with BF16 on a single NVIDIA B200."
Collections
Sign up for free to add this paper to one or more collections.

