Memory Caching: RNNs with Growing Memory
Abstract: Transformers have been established as the de-facto backbones for most recent advances in sequence modeling, mainly due to their growing memory capacity that scales with the context length. While plausible for retrieval tasks, it causes quadratic complexity and so has motivated recent studies to explore viable subquadratic recurrent alternatives. Despite showing promising preliminary results in diverse domains, such recurrent architectures underperform Transformers in recall-intensive tasks, often attributed to their fixed-size memory. In this paper, we introduce Memory Caching (MC), a simple yet effective technique that enhances recurrent models by caching checkpoints of their memory states (a.k.a. hidden states). Memory Caching allows the effective memory capacity of RNNs to grow with sequence length, offering a flexible trade-off that interpolates between the fixed memory (i.e., $O(L)$ complexity) of RNNs and the growing memory (i.e., $O(L2)$ complexity) of Transformers. We propose four variants of MC, including gated aggregation and sparse selective mechanisms, and discuss their implications on both linear and deep memory modules. Our experimental results on language modeling, and long-context understanding tasks show that MC enhances the performance of recurrent models, supporting its effectiveness. The results of in-context recall tasks indicate that while Transformers achieve the best accuracy, our MC variants show competitive performance, close the gap with Transformers, and performs better than state-of-the-art recurrent models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a simple question: how can we give fast, memory‑efficient neural networks (RNNs) a better memory so they don’t forget things from far back in a long text?
Today’s best models for reading long sequences are Transformers, which use “attention” to look back at all earlier words. That works great but gets very slow and heavy on memory as the text gets longer. RNNs are faster and lighter, but they keep only a small “note” (a hidden state) and often forget details from the distant past.
The authors propose Memory Caching (MC): a way for RNNs to save “snapshots” of their memory at checkpoints, so their effective memory grows as the sequence gets longer—without paying the full cost of Transformers.
What questions were the researchers asking?
- Can we help RNNs remember old information in long texts without making them as slow and heavy as Transformers?
- Is there a middle ground where the model can choose how much memory to “grow,” trading a bit of extra work for much better recall?
- Which ways of combining old “memory snapshots” work best?
How did they try to solve it?
Think of reading a long book:
- A Transformer keeps every page handy to re‑read anytime (powerful, but heavy).
- A classic RNN keeps only a small bookmark note that it updates as it reads (fast, but forgetful).
- Memory Caching is like writing a short summary at the end of each chapter and keeping those summaries. When you need to answer a question later, you look at your current bookmark and also the chapter summaries that seem relevant.
Here’s the basic approach in everyday terms:
- Split the input into segments (like chapters).
- As the model reads each segment, it updates an internal memory (like a summary of that segment).
- At the end of a segment, it saves (caches) that memory snapshot.
- When reading a new word, the model uses both:
- the current, “live” memory, and
- selected cached memories from earlier segments,
- to produce the next output.
This gives a flexible cost:
- Classic RNN: cost grows roughly like the length of the text, .
- Transformer: cost grows like length squared, (much heavier).
- Memory Caching: in between, about , where is how many segment snapshots you consult. You can pick to balance speed vs. recall.
To make this work well, the authors try four simple “recipes” for how to use the cached memories:
- They introduce the following four variants to combine current memory with cached “chapter summaries”:
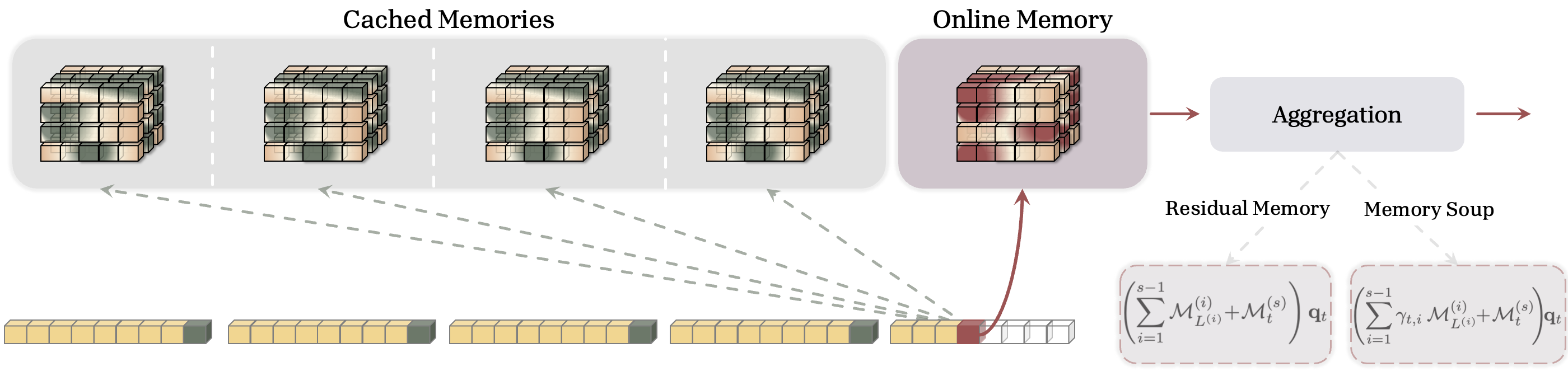
- Residual Memory: just add the outputs from all relevant cached memories to the current one—like stacking all the helpful notes together.
- Gated Residual Memory (GRM): still add them, but use learned weights (“gates”) to give more importance to the summaries that match the current question better.
- Memory Soup: instead of adding outputs, blend the cached memory “settings” themselves into one combined memory for the current step—like mixing recipes into a new one tailored to the current dish.
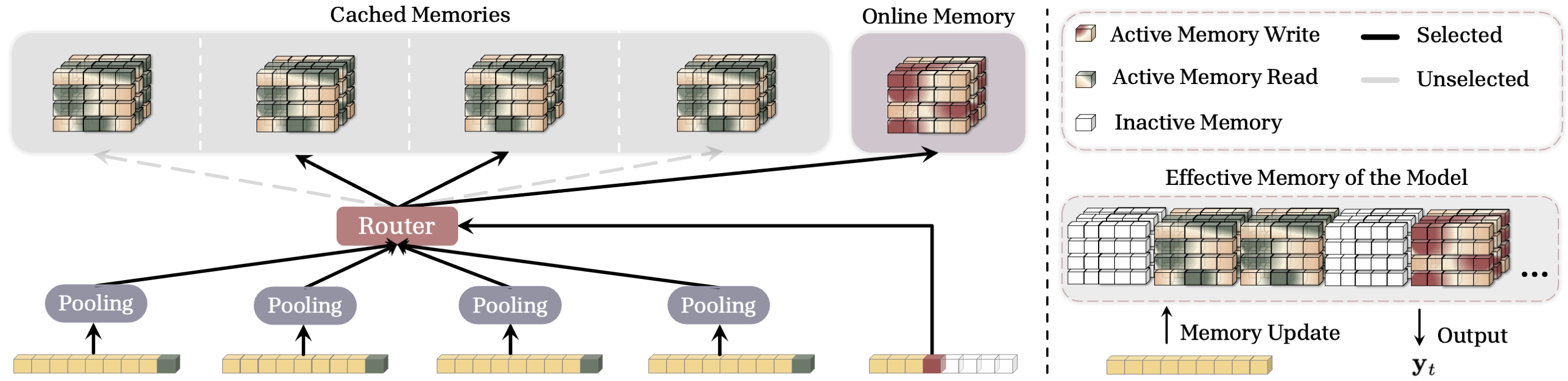
- Sparse Selective Caching (SSC): don’t look at every old summary—use a simple “router” to pick only the top few most relevant ones (saves time and memory).
They test MC on different kinds of RNN‑style models, including:
- Linear Attention (a fast, simplified version of attention),
- Deep Linear Attention (uses deeper, non‑linear memory modules),
- Titans (a more advanced, deep memory RNN),
- Sliding Window variants (that look at a small recent window).
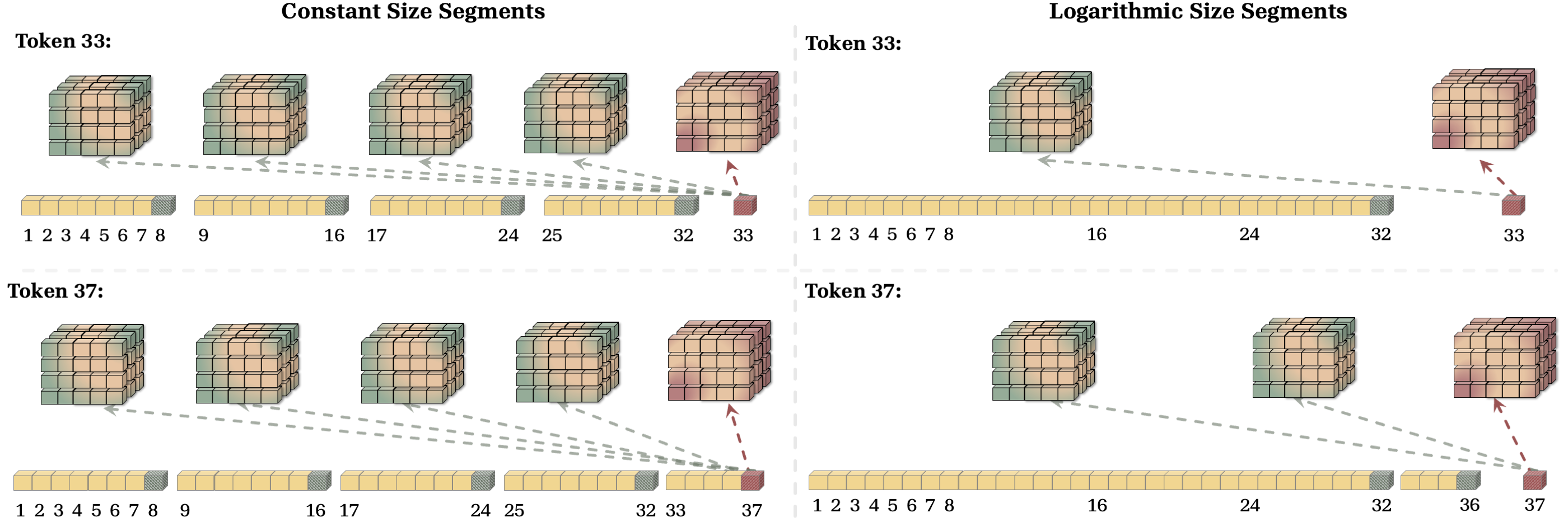
They also explore how to choose segment sizes:
- Equal‑size segments (like equal‑length chapters): better recall, a bit more cost.
- Logarithmic segments (few big ones plus a few small ones): very efficient, but less precise for very old details.
What did they find?
- Memory Caching consistently helps RNN‑style models remember and perform better on:
- Language modeling (predicting the next word),
- Long‑context understanding (using information from far back),
- Retrieval-heavy tasks (like “find the specific key hidden in a long text”).
- On “needle‑in‑a‑haystack” style tests (finding a small piece of info in a very long input), Transformers still score best overall, but MC versions of RNNs get much closer than before and beat other state‑of‑the‑art RNNs.
- The gated and soup methods often work best:
- Gated Residual Memory (GRM) helps the model focus on the most relevant cached summaries.
- Memory Soup shines especially when the memory module is “deep” (non‑linear), because blending the memory parameters creates a custom memory for each step.
- Sparse Selective Caching (SSC) reduces memory and compute at inference by only loading a few relevant caches—good for very long inputs.
- You can even add MC after training (as a decoding trick): simply caching and averaging past memories can noticeably improve how far the model can “stretch” its memory.
Why is this important?
- It offers a practical middle ground: you don’t need to store everything (like Transformers), but you don’t have to forget as much (like classic RNNs).
- This can make long‑context models cheaper and faster, which matters for:
- Running models on devices with limited memory,
- Real‑time applications where latency matters,
- Processing very long documents, code files, videos, or logs.
- The idea is simple and general: “save memory snapshots and reuse them smartly.” It can plug into many existing RNN‑style architectures and immediately make them better at long‑range recall.
- Overall, Memory Caching moves us toward AI systems that are both efficient and good at remembering, without needing the full cost of attention over everything.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Lack of formal theory: No guarantees or bounds on recall quality, error from compression, or approximation gap to full attention as a function of segment length, number of caches N, and retrieval mechanism (Residual/GRM/Soup/SSC).
- Capacity–complexity trade-off remains uncharacterized: No analytical framework quantifying how effective memory capacity grows with N (and k in SSC) versus compute and memory costs, nor conditions under which MC is provably subquadratic yet competitive with attention.
- Segmentation policy is heuristic: Segment lengths are manually set (constant or logarithmic). There is no data-dependent or learned method to choose segment boundaries online, nor criteria to optimize segmentation for task performance and efficiency.
- Sensitivity to segment boundaries: The impact of boundary placement (e.g., aligning to document sections vs uniform splits) on retrieval accuracy, forgetting, and interference is not studied.
- Router/gating design is simplistic: GRM and SSC rely on mean pooling and dot-product similarity; the paper does not explore richer segment representations (e.g., learned summaries, cross-attention, hierarchical pooling), alternative similarity metrics, or regularization for stable routing.
- Load balancing and degeneracy in SSC: No analysis or mitigation for router collapse (e.g., always selecting recent segments), lack of load balancing across caches, or strategies to enforce diversity/coverage (top-k choice, temperature, entropy regularization).
- Memory Soup practicality for deep memories: Constructing token-specific non-linear memories via parameter interpolation may be expensive; the paper does not quantify training/inference overhead, gradient stability, or memory footprint for per-token souped parameters.
- Backpropagation through caches: It is unclear how gradients propagate through cached memories across long sequences (especially for deep modules and Memory Soup), how this affects training stability, and whether gradient checkpointing or truncation is required.
- Checkpoint vs independent memory choice unresolved: The paper notes pros/cons but lacks systematic ablations or criteria for when to warm-start from the previous segment vs reinitialize independent compressors (effects on interference, stability, and recall).
- Aggregation operators are limited: Only additive aggregation (Residual/GRM) and parameter averaging (Soup) are explored; attention-over-memories, learned fusion networks, or gating conditioned jointly on query and segment content remain untested.
- Normalization and scaling effects: Many derivations omit normalization; there is no empirical study of how normalization choices (e.g., layer norm on cached outputs, softmax over segments) affect stability and performance across variants.
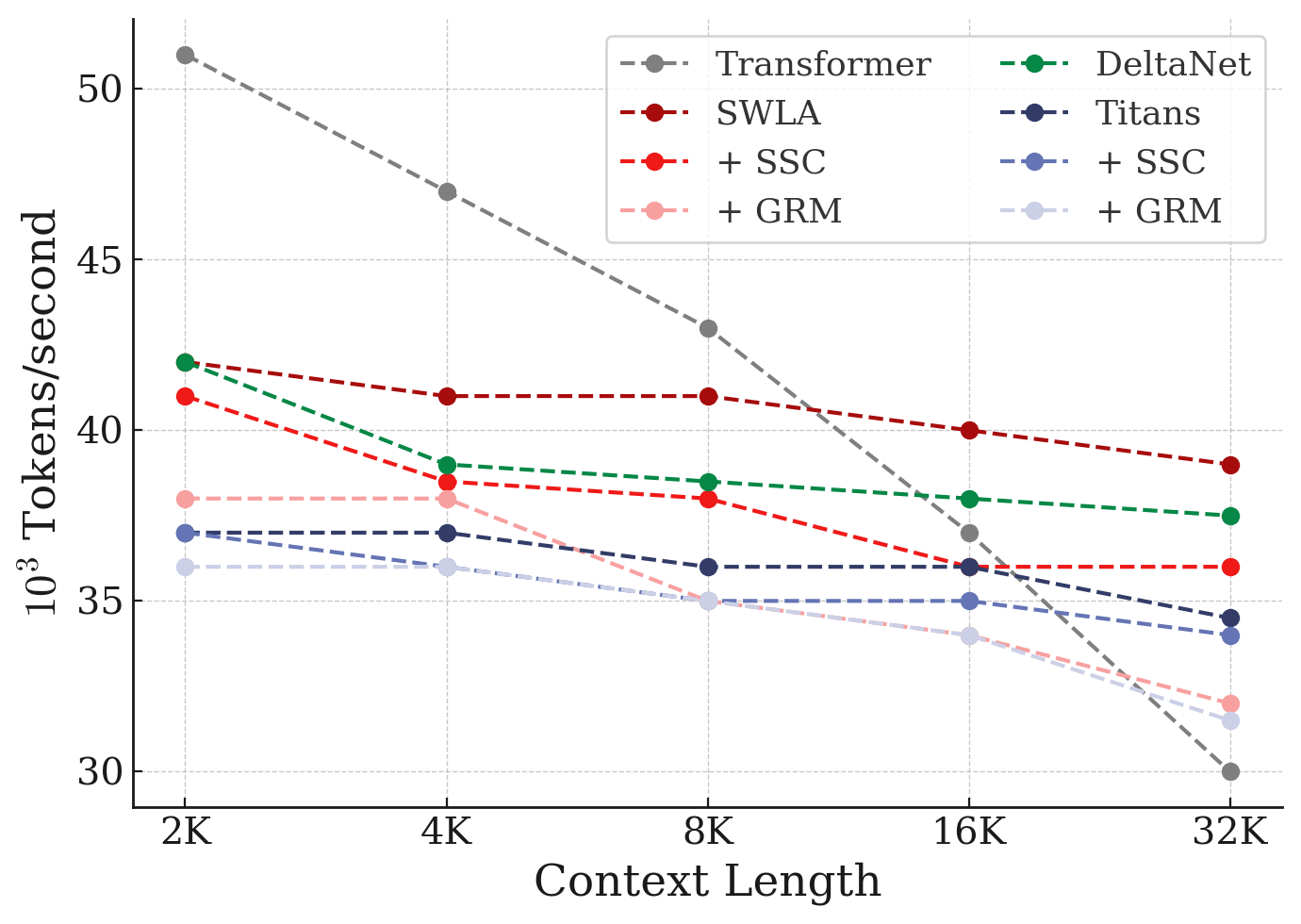
- Hardware efficiency and memory footprint: The paper does not provide end-to-end measurements of wall-clock throughput, accelerator memory usage, and latency for MC variants, nor a comparison against KV caching (attention) across context lengths.
- Streaming and batching constraints: It is unclear how MC interacts with streaming inference (variable-length segments), batch processing (different segmentation per sequence), and distributed training (synchronizing caches across devices).
- Multi-head and multi-layer integration: The paper does not specify whether caches are per head or shared across heads, how caches are merged across layers, or whether stacking MC exacerbates compute/memory or benefits recall.
- Robustness and interference: No evaluation under noisy/irrelevant segments, adversarial tokens, or distribution shift; the extent to which caches accumulate harmful or stale information and how to mitigate (e.g., decay, pruning) is unknown.
- Length extrapolation beyond reported ranges: Results are limited to moderate contexts (e.g., up to 16K in NIAH); behavior at 32K–1M tokens, failure modes, and scaling trends (N, k, segment size) are not characterized.
- Domain generalization: MC is tested primarily on language modeling and specific long-context tasks; applicability to code, long-form QA, speech, vision, video, and RL (where temporal credit assignment differs) remains open.
- Comparisons to state-space models (SSMs): MC is not evaluated with modern SSMs (e.g., S4/Hyena variants) or RetNet/RWKV as the underlying memory; whether MC closes recall gaps in these architectures is unknown.
- Interaction with hybrid architectures: The relationship between MC and attention+RNN hybrids (e.g., Samba) is only discussed conceptually; a controlled study of replacing or augmenting KV caching with MC, and hybrid designs that couple both, is missing.
- Router selection hyperparameters: Choice of k in SSC, gating temperature, and softmax normalization are not tuned or justified; their impact on accuracy, compute, and cache hit-rate is unreported.
- Cache maintenance policies: There is no strategy for cache eviction, compression, decay, or deduplication; how many caches to retain over very long sequences, and how to prevent cache bloat, is not addressed.
- Post-training MC at inference: The “moving average without learnable weights” suggestion lacks algorithmic detail and evaluation (window sizes, decay, selection policy), and does not quantify the length-extrapolation gains or trade-offs.
- Reproducibility and training details: Critical training hyperparameters (optimizer, learning rates, context lengths, γ initialization/regularization), ablation protocols, and seeds are insufficiently documented for replicability.
- Interpretability and diagnostics: No analysis of which segments are selected, cache hit-rates, contribution weights (γ), or per-layer memory usage; tools to diagnose when MC helps/hurts are missing.
- Safety and data privacy considerations: Caching memory states may retain sensitive content or amplify memorization; policies to detect and mitigate leakage or unwanted retention are not discussed.
Practical Applications
Immediate Applications
Below is a curated list of practical uses that can be deployed now or with minimal adaptation. Each item indicates sector(s), potential tools/products/workflows that could emerge, and assumptions/dependencies that affect feasibility.
- Efficient on-device chat and assistants with extended context
- Sectors: software, mobile, consumer
- Tools/workflows: GRM aggregator as a drop-in layer for linear-attention or RWKV-like RNNs; SSC router for selecting top-k cached segments; segmentation policy tuned to conversation turns (e.g., per message, per topic)
- Assumptions/dependencies: Accepting a small performance gap vs full Transformers in highly recall-intensive prompts; memory gating calibrated for conversational domain; mobile runtime support for caching and retrieval
- Cost-optimized server-side LLM inference (datacenter throughput and energy)
- Sectors: cloud, customer support, finance (contact centers)
- Tools/workflows: Replace attention-heavy layers with DLA/Titans + Memory Caching in mid/late blocks; inference-only MC (post-training) for length extrapolation; KV cache reduction via compressed cached memory states
- Assumptions/dependencies: Serving stack must support O(NL) retrieval across cached states; careful segmentation (equal-sized or logarithmic) to meet latency SLAs; performance tolerance in recall-heavy workloads
- Streaming log analytics and anomaly detection
- Sectors: cybersecurity, IT operations
- Tools/workflows: SSC router to choose relevant cached windows (e.g., last hour/day); residual memory for fast recall of rare events; segment logs by time windows or service boundaries
- Assumptions/dependencies: Labeling and evaluation at scale; router similarity features (mean-pooled segment features) correlate with incident relevance; robust handling of heterogeneous log schemas
- Real-time speech and translation with longer conversational memory
- Sectors: speech/ASR, communications
- Tools/workflows: Apply MC to RNN-based encoders/decoders; cache segments per utterance or per speaker turn; GRM to modulate contribution of earlier segments
- Assumptions/dependencies: Domain-specific fine-tuning; streaming latency constraints; integration with existing ASR pipelines and beam search
- Local code assistants for large files and repositories
- Sectors: developer tools, software
- Tools/workflows: DLA/Linear Attention + MC to track file-level and project-level segments; SSC selects function/module caches most relevant to the current cursor location; IDE plugin for segmentation and caching management
- Assumptions/dependencies: IDE integration; domain adaptation on code tokenization; quality monitoring vs Transformer baselines on long-context code tasks
- Document-heavy workflows (legal, compliance, enterprise search)
- Sectors: legal, enterprise knowledge management
- Tools/workflows: Segment long documents by sections/chapters; GRM gates retrieval by query-section similarity (mean pooling or learned pooling); Memory Soup for non-linear retrieval tuned to document structure
- Assumptions/dependencies: Domain adaptation; evaluation on recall-intensive queries; acceptance of slightly lower peak recall than full attention in exchange for efficiency
- Session-based recommendations and ad ranking (long behavioral context)
- Sectors: e-commerce, ads
- Tools/workflows: SSC router to select relevant past-session caches; equal-length or logarithmic segmentation by interaction count; residual memory for fast retrieval of salient past actions
- Assumptions/dependencies: Latency budgets; privacy and data minimization compliance (compressed memory states vs raw KV); A/B testing to measure ROI
- Training efficiency in academia and industry
- Sectors: academia, ML engineering
- Tools/workflows: Integrate MC into pretraining pipelines of RNN-like backbones (DLA, Titans, RWKV, linear attention); segmentation schedules as hyperparameters; ablation frameworks for checkpoint vs independent compressor
- Assumptions/dependencies: Stability across tasks and scales; reproducible benchmarks; clear recipes for gating/aggregation parameterization
- Inference-only length extrapolation without retraining
- Sectors: software, applied ML
- Tools/workflows: Post-training MC: cache segment memory states during decoding and compute moving averages or simple GRM without learnable weights
- Assumptions/dependencies: Gains are task-dependent; modest engineering effort to add caching; may need heuristic segmentation (e.g., per 4K tokens)
- Edge robotics with longer sensor-memory on limited hardware
- Sectors: robotics, industrial automation
- Tools/workflows: SSC to select relevant environment-memory segments; GRM to balance fresh vs past sensor contexts; segment by map tiles or mission phases
- Assumptions/dependencies: Real-time constraints; cross-modal fusion (vision/LiDAR/audio); robustness to non-stationary environments
- Privacy-aware data minimization
- Sectors: policy/compliance, security
- Tools/workflows: Replace raw token KV caches with compressed memory states; retention policies that discard segment raw data while keeping compact caches
- Assumptions/dependencies: Formal privacy analysis to validate lower sensitivity of compressed states; auditability requirements; alignment with data minimization regulations
Long-Term Applications
These use cases are high-impact but require further research, scaling, evaluations, or product development before broad deployment.
- Million-token context LLMs without quadratic attention
- Sectors: software, cloud AI
- Tools/products: Hierarchical segmentation planners; SSC routers optimized with MoE-style load balancing; deep Memory Soup with stability guarantees
- Assumptions/dependencies: Robust training at scale (100B–1T tokens) and convergence; safety/performance parity with Transformers on recall-intensive tasks; hardware/runtime co-design
- On-device personal memory assistants with privacy-preserving long-term recall
- Sectors: consumer, education
- Tools/products: Titans/DLA + MC for lifelong session memory; encrypted caching with local retrieval; UX for memory segmentation and control
- Assumptions/dependencies: Safety, controllability, and user consent; storage/battery constraints; continual-learning stability
- Longitudinal clinical decision support over comprehensive EHRs
- Sectors: healthcare
- Tools/products: Deep memory modules (Titans) + MC to integrate years of clinical notes, labs, imaging summaries; SSC routers for problem-specific retrieval
- Assumptions/dependencies: Clinical validation and regulatory clearance; fairness and bias audits; secure data handling with compressed caches
- Streaming risk and compliance analytics across months/years
- Sectors: finance, insurance
- Tools/products: SSC-based retrieval over time-indexed caches; Memory Soup for non-linear aggregation of rare, high-impact events
- Assumptions/dependencies: Extensive backtesting; explainability requirements; governance for model updates and cache retention
- Corpus-level scientific synthesis and research assistants
- Sectors: academia, R&D
- Tools/products: MC-based retrieval over large literature repositories; domain-aware segmentation (by paper sections, topics); GRM to weigh historical vs recent findings
- Assumptions/dependencies: Scale-out training; benchmark creation for long-horizon scientific recall; integration with citation graph knowledge
- Long-horizon video understanding (surveillance, sports, autonomous systems)
- Sectors: media analytics, security, automotive
- Tools/products: Video Titans + MC for scenario memory; SSC routers keyed by scene/topic; segment by shots/scenes
- Assumptions/dependencies: Large-scale video datasets; latency constraints in real-time systems; robustness to distribution shift
- Autonomous driving with route and behavior memory
- Sectors: automotive
- Tools/products: MC-enhanced sequence models that recall prior routes/interactions; SSC for selecting relevant past segments based on current conditions
- Assumptions/dependencies: Safety certification; cross-city generalization; rigorous simulation and field trials
- Specialized accelerators and runtimes for Memory Caching
- Sectors: hardware, systems
- Tools/products: Router kernels for fast relevance scoring; low-precision cache formats; compilers for dynamic segmentation and cache management
- Assumptions/dependencies: Vendor ecosystem support; standardized APIs; co-design with serving frameworks
- Foundation-model training paradigms with subquadratic memory at scale
- Sectors: cloud providers, AI labs
- Tools/products: Training stacks for MC-RNNs (DLA/Titans) that replace large portions of attention; curriculum for segmentation schedules; distributed caching orchestration
- Assumptions/dependencies: Demonstrated state-of-the-art across diverse tasks; tuning stability; community acceptance and tooling maturity
- Energy-efficient AI standards and policy frameworks
- Sectors: policy, sustainability
- Tools/products: Benchmarks that measure energy vs recall; guidance for adopting MC to reduce carbon footprint; procurement standards for efficient AI
- Assumptions/dependencies: Multi-stakeholder alignment; transparent reporting; independent evaluations
- Enterprise knowledge memory servers
- Sectors: enterprise software, KM
- Tools/products: MC-backed document memory services that segment and cache organizational knowledge for fast retrieval by users/apps
- Assumptions/dependencies: Productization effort; access controls and privacy; integration with existing search and LLM platforms
Notes on method-specific dependencies
- Segmentation strategy is pivotal: equal-sized segments improve recall but increase cost; logarithmic segmentation improves efficiency (O(L log L)) but reduces resolution of long-past tokens. Application performance should guide this choice.
- Choice of checkpoint vs independent compressor matters:
- Checkpointing a single memory across segments improves continuity but risks interference.
- Independent compressors avoid interference but may lose cross-segment optimization benefits.
- Variant selection:
- Residual Memory is simplest; GRM adds query-dependent selectivity.
- Memory Soup is equivalent to GRM for linear memories but uniquely powerful for deep/non-linear memories.
- SSC reduces memory footprint and compute by selecting top-k relevant caches; requires robust routing features.
- Post-training MC is viable for immediate extrapolation gains but typically smaller than fully trained MC variants.
- Hardware/runtime: routers and mean-pooling can be precomputed and parallelized; systems must support fast loading of selected caches.
Glossary
- associative memory: A memory model that stores and retrieves information by matching patterns (e.g., queries to keys/values) rather than explicit addresses. "acts as an associative memory with growing capacity"
- attentional bias: The internal objective optimized by the memory during sequence processing that shapes what is retained and retrieved. "where the attentional bias objective is defined as"
- Deep Linear Attention (DLA): A recurrent architecture that uses a deep (e.g., MLP) memory module updated with a linear-attention-like rule for efficient long-range dependencies. "Deep Linear Attention (DLA)"
- Fenwick tree structure: A binary indexed tree data structure enabling efficient prefix sums, used here to organize hierarchical hidden states. "Fenwick tree structure"
- Gated Residual Memory (GRM): A variant of memory caching that aggregates cached memories via residual connections modulated by input-dependent gates. "Gated Residual Memory (GRM)"
- Hebbian rule: An update rule inspired by Hebbian learning where memory is reinforced by co-activation of keys and values. "DLA uses the same update rule as linear attention (i.e., Hebbian rule)"
- KV-caching: Storing key and value tensors from prior tokens to speed up attention during inference at the cost of memory. "high inference-time memory usage (KV-caching)"
- length extrapolation capability: A model’s ability to generalize to longer sequences than seen during training without significant degradation. "length extrapolation capability"
- Linear attention: An attention variant that replaces the softmax with a kernel feature map to enable a recurrent, linear-time formulation. "Linear attention"
- log-linear attention: A hierarchical attention scheme with logarithmically many cached states organized via Fenwick trees for subquadratic complexity. "log-linear attention, a hierarchical algorithm based on Fenwick tree structure"
- Memory Caching (MC): A technique that caches checkpoints of memory states to grow effective memory with sequence length while controlling complexity. "Memory Caching (MC)"
- Memory Soup: A memory-caching variant that interpolates parameters of cached memories into an input-dependent “souped” memory for retrieval. "Memory Soup"
- Mixture of Experts (MoEs): A modular architecture where a router selects among expert modules for each input to improve capacity and efficiency. "Mixture of Experts (MoEs)"
- Mixture-of-Experts style router: A gating mechanism that selects a subset of cached memories based on relevance to the current token. "Mixture-of-Experts style router"
- Miras framework: A unifying perspective viewing sequence models as optimizing an internal objective over memory during the forward pass. "the simplest form of Miras framework"
- Needle-In-A-Haystack: A stress test for long-context recall where a small “needle” must be retrieved from a long distractor context. "Needle-In-A-Haystack experiments"
- nested learning paradigm: A view where memory updates are interpreted as inner-loop learning within the forward pass of a larger model. "nested learning paradigm"
- parametric in-context learning: Learning behavior where a model adapts to new tasks within its forward pass via its parameters and memory updates. "parametric in-context learning"
- retention operator: A mechanism that helps preserve or recover information from far in the past during sequence processing. "acts as a retention operator"
- Sliding Window Linear Attention (SWLA): A linear attention variant that updates memory using a window of recent tokens to balance recency and efficiency. "Sliding Window Linear Attention (SWLA)"
- Sparse Selective Caching (SSC): A memory-caching variant that selects only the most relevant cached memories for each token to reduce overhead. "Sparse Selective Caching (SSC)"
- sub-quadratic architectures: Sequence models designed to reduce the quadratic cost of attention to subquadratic time/space complexity. "sub-quadratic architectures"
- Test-time Memorization: The phenomenon where models adapt or internalize information during inference via their memory dynamics. "Test-time Memorization"
- Top-k: Selecting the k highest-scoring items (e.g., cached memories) based on a relevance score. "Top-k"
- unnormalized linear attention: A form of linear attention that omits normalization by the sum of kernelized keys. "unnormalized linear attention architecture"
- value-less memory module: An associative memory that maps queries using only keys (no explicit values). "Value-less memory module"
- weight souping: Averaging parameters from different checkpoints or models to form a new model, adapted here to memory parameters. "inspired by weight souping"
Collections
Sign up for free to add this paper to one or more collections.