- The paper presents UniPool, which replaces layer-specific expert banks with a single global expert pool to decouple expert parameter growth from model depth.
- It introduces a novel combination of pool-level auxiliary loss and NormRouter to enable efficient cross-layer expert reuse and robust routing across layers.
- Empirical evaluations demonstrate that UniPool outperforms traditional MoE methods with sublinear scaling, achieving similar or better performance using significantly fewer expert parameters.
UniPool: Globally Shared Expert Pool for Mixture-of-Experts
Motivation and Architectural Innovations
The Mixture-of-Experts (MoE) paradigm has dominated the scaling of LLMs primarily through rigid per-layer expert allocation, resulting in linear parameter growth with model depth and redundant specialization of layer-wise expert banks. This conventional design constrains expert capacity to isolated banks, preventing efficient cross-layer expert reuse and yielding substantial redundancy, especially in deep layers. Empirical probing of routers in production MoEs demonstrates negligible degradation in downstream accuracy (≤1.6 points) when randomized routing replaces learned top-k, signaling a lack of meaningful specialization in layer-private expert sets and questioning the efficacy of enforced linear scaling.
UniPool addresses these inefficiencies by architecting a single global expert pool, accessed by independent per-layer routers, decoupling expert parameter growth from model depth, and transforming expert capacity into a truly global architectural budget. This enables cross-layer expert reuse, replaces redundant per-layer specialization, and requires careful stabilization through matched load-balancing and routing mechanisms.
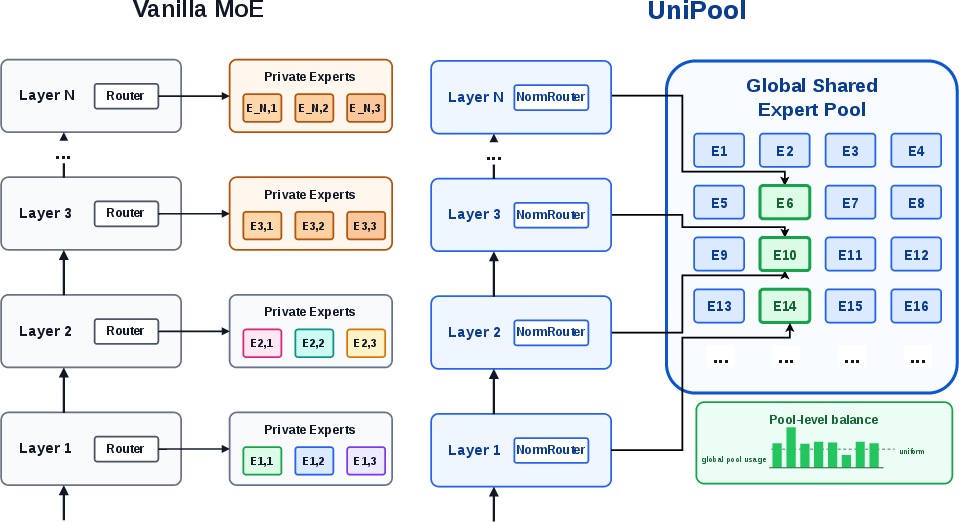
Figure 1: UniPool replaces layer-private expert ownership with a global expert pool and per-layer routers; pool-level balancing aggregates utilization across the shared pool, preventing globally unused experts while allowing layer-specific specialization.
Load Balancing and Routing Co-Design
Layer-private auxiliary losses—standard in MoE—fail in the shared-pool regime, as their notion of deadness becomes misaligned with parameter ownership: experts unused by one layer may be heavily utilized by others. UniPool implements a pool-level auxiliary loss, aggregating token-to-expert statistics across all layers and penalizing globally underutilized experts rather than enforcing uniform utilization at each depth. This objective stabilizes training without artificially forcing every layer to use every expert, supporting layer-specific specialization while ensuring efficient pool-wide parameter usage.
UniPool further integrates NormRouter, an L2-normalize/ReLU router combined with a learnable scale, replacing softmax gating. This formulation delivers robust routing in the global expert space by ensuring scale-invariant scoring across varying layer norms, sparse top-k competition, and adjustable sharpness, critical when a single pool is accessed from multiple depths.
Empirical Evaluation: Efficiency and Specialization
UniPool is benchmarked across five LLaMA-style scales (182M, 469M, 650M, 830M, 978M) trained on 30B tokens. UniPool consistently outperforms vanilla MoE and dense baselines in validation loss and perplexity at all scales, with loss reductions up to 0.0386. Notably, sublinear expert scaling is achieved: reduced-pool UniPool variants with only 41.6%–66.7% of vanilla MoE’s expert parameter budget match or surpass layer-wise MoE results, directly contradicting the necessity of linear expert scaling.
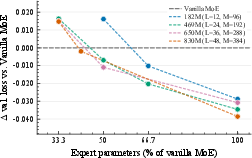
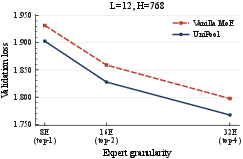
Figure 2: (a) Parametric efficiency sweep: UniPool surpasses vanilla MoE at highly reduced expert budgets; (b) Granularity sweep: performance gains compose with finer-grained expert decomposition.
The efficiency sweep demonstrates that UniPool’s architectural decoupling enables smaller expert pools to deliver superior performance, validating the budgeting hypothesis and highlighting architectural overprovisioning in conventional designs. The granularity sweep confirms performance improvements with increasing expert count and routing granularity, consistent with established MoE scaling laws.
Specialization and Routing Sensitivity
Routing-randomization sensitivity experiments reveal that, while vanilla MoE exhibits low sensitivity (∼1.3 points drop) due to high intra-layer redundancy, UniPool’s routers induce significantly more load-bearing specialization (error drop increases to $4.1$ points). This validates the claim that shared pool training breaks substitutability and fosters genuinely distinct expert specialization, as layer-wise competition accrues gradient signals and sharp specialization emerges.
Ablation and Component Analysis
Ablation studies confirm the criticality of matched co-design: naive shared pool with per-layer auxiliary loss fails, while pool-level balancing and NormRouter unlock the performance gains. Intermediate sharing scopes interpolate between vanilla MoE and full UniPool, showing monotonic improvements with increased sharing. Training dynamics substantiate that the UniPool gap persists throughout optimization trajectories.
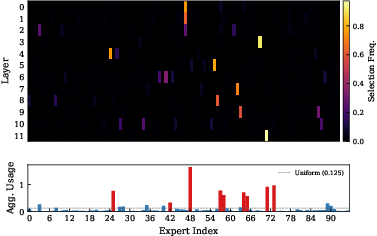
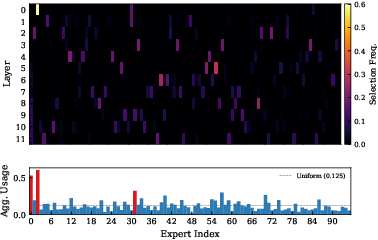
Figure 3: Expert utilization: per-layer auxiliary loss yields global expert collapse; UniPool with pool-level balancing achieves robust utilization across the entire pool while maintaining layer-wise specialization.
Practical and Theoretical Implications
UniPool’s design recasts MoE expert allocation as a flexible global budget, freeing architectural scaling from rigid depth dependence and enabling efficient parameter utilization. This paradigm unlocks new scaling axes for LLMs, offering practical reductions in memory footprint and parameter count for equivalent or superior model quality, and empowering deeper models with reusable, specialized expert computations. The theoretical implication is a shift from post-hoc MoE compression toward proactive cross-layer parameter sharing and specialization, yielding models that are leaner, more robust, and inherently adaptable.
The reduced pool size—tied to dynamic utilization and controlled by explicit scaling hyperparameters—paves the way for future billion-scale models with sublinear expert growth and compositional specialization. This architectural innovation opens avenues for improved throughput, expert-parallel computation, and downstream transferability, contingent on further evaluation at trillion-parameter and extended training regimes.
Conclusion
UniPool establishes a globally shared expert pool architecture for MoE transformers, leveraging pool-level balancing and scale-stable routing to robustly outperform layer-wise MoE baselines with significantly fewer expert parameters. By decoupling expert growth from depth, UniPool lays a foundation for more efficient, scalable, and specialized LLMs, driving theoretical advances in architectural design and practical reductions in model complexity.