- The paper introduces an expert choice routing mechanism that dynamically assigns tokens to specialized experts for improved scalability and reduced computational overhead.
- The paper demonstrates that MoE models with expert choice routing outperform dense models on validation perplexity and downstream GLUE/SuperGLUE benchmarks.
- The paper shows that varying capacity factors allow competitive performance while optimizing computation, suggesting new regimes for large-scale neural networks.
Mixture-of-Experts with Expert Choice Routing
Introduction
This paper investigates the use of mixture-of-experts (MoE) models with expert choice routing, presenting advancements in complexity management and performance when scaling large neural networks. The proposed methodology leverages the flexibility of dynamically assigning computation to specialized experts, aiming to enhance the performance of transformer-based architectures while reducing unnecessary computational overhead. This approach is particularly pertinent in the era of ever-expanding model sizes, as it enables more efficient utilization of computational resources and improves model expressiveness through capacity adjustment.
Expert Choice Routing Mechanism
The core of the paper is the introduction of expert choice routing. This methodology focuses on dynamically allocating tokens to experts, optimizing the model's ability to capture complex patterns using fewer computational resources than a dense model. Expert choice routing in MoE models differs significantly from traditional dense architectures by allowing selective activation of parts of the network, thereby focusing computational efforts on relevant sub-models during different stages of processing. This selective gating is benchmarked against existing solutions like GShard top-2 gating, exhibiting superior validation perplexity during pre-training (Figure 1).
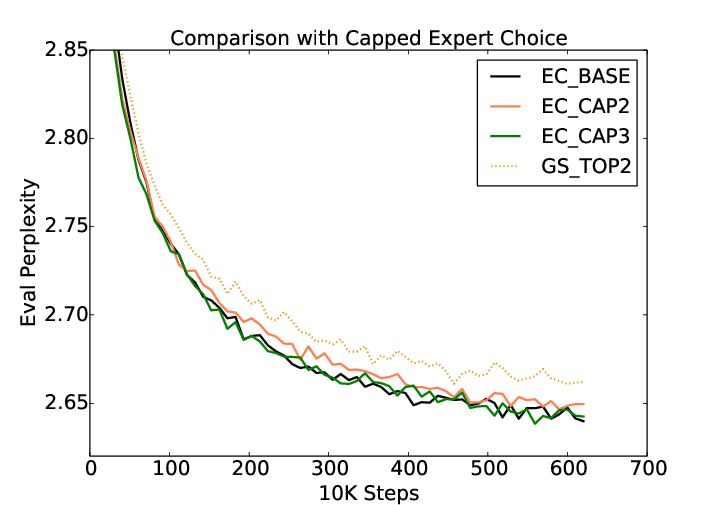
Figure 1: Validation perplexity during pre-training using various expert choice methods and top-2 gating.
Comparative Analysis with Dense Models
The paper provides a thorough comparative analysis between a dense 8-billion parameter model and the proposed MoE model with expert choice routing. Across multiple tasks within GLUE and SuperGLUE benchmarks, the expert choice MoE model showcases consistent performance improvements over the dense architecture. This is particularly notable in tasks requiring nuanced language understanding and reasoning, where fine-tuning results indicate a substantial performance margin. The expert choice routing effectively enhances the model's ability to generalize from pre-training perplexity to downstream task performance, underscoring the importance of efficient capacity utilization.
Capacity Factor and Its Implications
An integral aspect of expert choice routing explored in the paper is the concept of capacity factor (CF). This denotes the average number of experts a single token can access during computation. The study analyzes various configurations, from EC-CF2 to EC-CF0.5, highlighting that even lowered capacity factors maintain competitive performance. The EC-CF2 configuration, matching the GShard computational footprint, consistently demonstrates efficiency without sacrificing accuracy, adding practical value in deploying these models at scale. Notably, EC-CAP2 and EC-CAP3, where the number of experts is capped per token, still surpass the top-2 gating in perplexity metrics, reiterating the efficacy of adaptive expert allocation strategies.
Theoretical and Practical Implications
The implications of this research extend both theoretically and practically. Theoretical contributions lie in advancing understanding of MoE architectures, emphasizing the role of adaptive expert allocation in maintaining model scalability and performance. Practically, expert choice routing presents a compelling alternative to traditional architectures, addressing computational limitations while pushing the boundaries of model expressiveness and accuracy. These advancements suggest potential pathways for more efficient training regimes and deployment strategies, facilitating the widespread adoption of increasingly large models.
Conclusion
In summary, the paper presents significant advancements in the domain of mixture-of-experts models by introducing an expert choice routing mechanism. This approach demonstrates clear performance benefits over dense models and other gated architectures, emphasizing enhanced scalability and computational efficiency. The exploration of capacity factors and capped expert allocations further solidifies the approach's viability, offering robust avenues for future research in adaptive model architectures and efficient resource utilization. Given these insights, expert choice routing potentially heralds a new paradigm in large-scale neural network training and deployment strategies.