Mixture of Universal Experts: Scaling Virtual Width via Depth-Width Transformation
Abstract: Mixture-of-Experts (MoE) decouples model capacity from per-token computation, yet their scalability remains limited by the physical dimensions of depth and width. To overcome this, we propose Mixture of Universal Experts (MOUE),a MoE generalization introducing a novel scaling dimension: Virtual Width. In general, MoUE aims to reuse a universal layer-agnostic expert pool across layers, converting depth into virtual width under a fixed per-token activation budget. However, two challenges remain: a routing path explosion from recursive expert reuse, and a mismatch between the exposure induced by reuse and the conventional load-balancing objectives. We address these with three core components: a Staggered Rotational Topology for structured expert sharing, a Universal Expert Load Balance for depth-aware exposure correction, and a Universal Router with lightweight trajectory state for coherent multi-step routing. Empirically, MoUE consistently outperforms matched MoE baselines by up to 1.3% across scaling regimes, enables progressive conversion of existing MoE checkpoints with up to 4.2% gains, and reveals a new scaling dimension for MoE architectures.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making LLMs (like the ones behind chatbots) smarter and more efficient without making them much more expensive to run. The authors build on a popular design called Mixture‑of‑Experts (MoE), where a model has many “experts” (small specialist networks) but only a few are used for each word. They introduce a new version called Mixture of Universal Experts (MoUE) that reuses the same experts across multiple layers of the model. They call the extra capacity created by this reuse “virtual width.”
What questions are the researchers asking?
- Can we make models more capable by reusing the same experts multiple times instead of adding lots of new experts or layers?
- Can we do this without increasing the amount of work the model does for each word (keeping the “activation budget” fixed)?
- How do we keep training stable when the same experts are reused many times across the model?
How does their idea work?
Think of a school with many tutors (experts). In a normal MoE school, each class period (layer) has its own set of tutors, and a student meets just a couple per period. In MoUE, some tutors are “universal”: they can teach in many periods. This reuse means students can build more varied learning paths without hiring more tutors.
To make this work at scale, the authors add three key pieces:
- Staggered Rotational Topology (a structured sharing plan)
- Analogy: Instead of letting students see all universal tutors all the time (which gets chaotic), the school offers a rotating “menu” of universal tutors to groups of periods. This keeps choices manageable and training stable.
- Universal Expert Load Balance (a fairness rule that considers exposure)
- Analogy: If some tutors are available in many periods, they’ll naturally be chosen more. The fairness rule adjusts for that, judging each tutor by how often they’re picked when they’re actually available—so popular-by-schedule tutors aren’t unfairly penalized.
- Universal Router (a lightweight “memory” for choosing experts)
- Analogy: A guidance counselor (router) doesn’t just pick tutors fresh each period; it remembers the student’s recent choices to keep the learning path coherent. This “memory” is small and fast, so it doesn’t slow things down.
The big idea, “virtual width,” is like creating many more possible learning paths (combinations of experts across periods) without adding lots of new tutors or class time.
How did they test it?
The authors trained and compared MoUE to standard MoE in two main ways, keeping per‑word compute budgets matched:
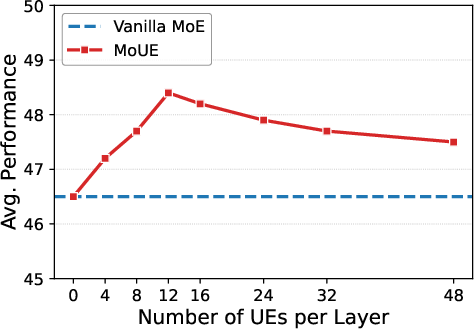
- Width expansion: Increase the number of universal experts, which increases the number of possible expert combinations (virtual width), but keep the number of experts used per word the same.
- Depth expansion: Make the model deeper (more layers) but reuse the same experts across layers, so you get more computation steps without adding lots of new expert parameters.
They evaluated performance on a variety of language understanding and reasoning benchmarks. They also tested converting existing MoE models into MoUE using a gentle “warm‑start” process: clone some good experts into the universal pool and slowly allow the model to use them more over time so training stays stable. Finally, they ran ablation studies (turning off parts one by one) to see which components mattered most.
What did they find, and why is it important?
- Consistent accuracy gains at the same compute cost
- Training MoUE from scratch beat standard MoE by up to about 1.3% on average scores, even though the number of experts used per word and total parameters stayed the same.
- Depth‑via‑reuse is very efficient
- Reusing experts across more layers (depth expansion) brought larger gains with only small growth in total parameters. In some cases, a deeper MoUE outperformed a larger standard MoE while using about half the “activated” parameters per word.
- Warm‑starting works well
- Converting existing MoE checkpoints to MoUE and continuing training brought additional improvements (up to about 4.2% in one setting), and gains grew as the universal expert pool got bigger.
- Stable training needs all three pieces
- The rotating connectivity, depth‑aware load balancing, and router “memory” each helped. Removing any of them hurt performance or stability. This shows that virtual width isn’t just about reuse; it needs structure, fairness, and consistency.
- Better use of compute
- Validation loss (a measure of how well the model fits the data) improved faster for MoUE at the same training cost, suggesting better efficiency.
These results matter because they show a new way to scale models—by turning depth into “virtual width”—that can boost performance without blowing up computation or memory.
What’s the big picture impact?
MoUE introduces a new scaling dimension for LLMs: instead of only making models wider (more experts) or deeper (more layers) in the usual way, it reuses a shared pool of universal experts across layers to create many more useful combinations. This can:
- Make models more capable under tight compute or memory budgets.
- Reduce engineering complexity (fewer new experts to add and manage).
- Let existing MoE models be upgraded through a smooth conversion process.
In short, MoUE shows how to get more “brains” from the same “bodies”: by reusing expert knowledge across steps, the model explores richer reasoning paths without paying a big compute bill. This could help future AI systems become smarter, cheaper, and easier to scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that the paper leaves unresolved and that future work could address:
- Formal theory for “Virtual Width”
- Provide a rigorous definition and measurement protocol for virtual parameters (VP) and analyze their relation to effective capacity, sample complexity, and generalization error.
- Derive bounds on routing search complexity, convergence, and expressivity under staggered connectivity and UELB; quantify how much of the exponential path space is practically exploitable.
- Router dynamics and stability
- Analyze the Universal Router’s fast-weight update theoretically (e.g., stability, convergence, bias/variance trade-offs) and empirically across long contexts and varying batch sizes.
- Determine how the trajectory state should persist or reset during autoregressive decoding and multi-turn interactions; clarify per-token/per-step memory and update costs in inference.
- Compute, memory, and systems overhead
- Quantify end-to-end training and inference throughput/latency impacts of: per-layer allow-lists, universal routing projections, fast-weight updates, and staggered connectivity masking.
- Provide detailed FLOPs and memory breakdowns for MoUE components vs. standard MoE, including activation checkpointing and communication overheads at scale.
- Distributed training and communication
- Evaluate MoUE under multi-node expert-parallel and tensor-parallel settings where the UE window spans nodes; quantify cross-node traffic, all-to-all costs, and pipeline bubbles.
- Investigate fault tolerance: impact of expert/node dropouts when UEs are reused across multiple layers; design redundancy or graceful degradation strategies.
- Hyperparameter sensitivity and tuning
- Systematically study sensitivity to topology hyperparameters (window size W, group size G, stride s), UELB coefficients (alphas), Top-K, capacity factor, and warmup schedules.
- Develop automated or learned topology discovery (e.g., learnable connectivity graphs) instead of fixed rings; compare against data-driven clustering or graph sparsification.
- Load balancing formulation
- Validate UELB under dynamic or learned connectivity (where exposure counts cj change); explore online estimators and robust normalization schemes.
- Compare UELB with alternative depth-aware balancing (e.g., entropy regularizers, mutual-information objectives, path-level coverage penalties) and expert-choice routing.
- Path diversity vs. specialization trade-offs
- Characterize when cross-layer reuse helps or harms layer-specific specialization; identify regimes where too much sharing degrades performance and propose adaptive sharing controls.
- Measure path diversity directly (e.g., path entropy, coverage over depth) and relate it to downstream accuracy, calibration, and robustness.
- Generality across modules and architectures
- Extend MoUE beyond FFN experts to attention, normalization, or multi-module experts; assess whether universal attention experts yield similar gains.
- Compare against recurrent/Universal Transformer baselines and other depth-reuse approaches under matched compute/parameter budgets.
- Scaling to larger LLMs and domains
- Validate results on multi-billion to hundred-billion parameter models; test across multilingual corpora, code, math, and long-context tasks to assess robustness and transfer.
- Evaluate under distribution shift (OOD), safety/harms, and calibration; measure whether virtual width improves uncertainty estimation or robustness.
- Evaluation breadth and statistical rigor
- Report multi-seed variance, statistical significance, and confidence intervals for small percentage gains; include ablations on data size and training duration.
- Add more generative and reasoning benchmarks (e.g., long-form QA, coding, tool-use) and measure instruction-following and toxicity/safety metrics.
- Inference-time scaling and controllability
- Explore test-time scaling knobs (e.g., adaptive depth, dynamic Top-K, path search) to trade latency for quality; design safe early-exit criteria with MoUE routing.
- Investigate caching or reusing trajectory state across decoding steps to amortize routing cost without loss of coherence.
- Warm-start conversion methodology
- Replace the heuristic UE selection by principled methods (e.g., expert clustering, representational similarity, importance sampling) and quantify conversion efficiency.
- Automate the logit-suppression schedule β(t) (e.g., with performance-driven controllers) and study transfer to new domains or continual learning settings.
- Capacity constraints and routing overflow
- Analyze capacity overflow rates, dropped tokens, and queuing policies under high-load regimes; characterize their effect on learning and fairness across experts.
- Design depth-aware capacity allocation strategies that consider exposure and path composition jointly.
- Interpretability and circuit analysis
- Develop tools to extract and visualize reusable expert circuits, quantify re-entrant loops, and link expert paths to task semantics and failure modes.
- Study whether MoUE paths are more interpretable or controllable than MoE’s layer-local expert activations.
- Reproducibility and implementation details
- Release detailed training/inference configs, profiling scripts, and scaling laws for MoUE components; specify exact FLOP accounting for iso-compute claims.
- Provide guidelines for selecting EP size vs. UE window placement to minimize communication without sacrificing coverage.
Practical Applications
Below are practical applications of the Mixture of Universal Experts (MoUE) framework and its components (Virtual Width, Staggered Rotational Topology, Universal Expert Load Balance, Universal Router, and Progressive Warm-Start). Each item specifies sectors, potential tools/products/workflows, and feasibility assumptions or dependencies.
Immediate Applications
- Retrofitting existing MoE LLMs to MoUE for accuracy gains at fixed inference cost
- Sectors: Software/AI platforms, Cloud providers, Enterprise AI, Education, Finance, Healthcare
- What: Convert deployed MoE checkpoints using the paper’s Progressive Warm-Start (logit-suppression curriculum, expert cloning) to gain ~1–4% relative accuracy without increasing per-token activated parameters.
- Tools/workflows:
- Training recipe plug-in for Megatron-DeepSpeed or similar: add per-layer allow-lists for UEs, integrate UELB loss, Universal Router fast-weight state, and logit suppression schedule.
- A/B rollout in production inference services; gate enablement flags for universal routing.
- Assumptions/dependencies:
- Baseline model is MoE; model-parallel infrastructure supports expert-parallel (EP).
- Routing windows kept within-node to avoid added inter-node communication.
- Small engineering overhead for router state and allow-lists is acceptable.
- Cost-controlled capacity scaling for domain LLMs under tight budgets
- Sectors: Healthcare (coding, summarization), Legal, Finance (report analysis), Customer support
- What: Use MoUE’s depth-expansion via expert reuse to add computation steps with minimal added FFN parameters, improving reasoning-heavy tasks at similar TP/Act budgets.
- Tools/workflows:
- Train-from-scratch or continued pretraining with Staggered Rotational Topology and UELB.
- Validation dashboards tracking Max/Mean routing skew and UELB metrics.
- Assumptions/dependencies:
- Training stability relies on UELB and warmup; without them, routing may collapse.
- Gains depend on task mix (benefits strongest on reasoning/reading comprehension).
- Efficient fine-tuning pipelines for open-source MoE backbones
- Sectors: Open-source ML, Academia, Startups
- What: Apply MoUE variants during SFT to improve downstream benchmarks at fixed compute (as demonstrated on JetMoE/OLMoE).
- Tools/workflows:
- SFT scripts extended with group-wise UELB, connectivity masks, and Universal Router.
- Lightweight hyperparameter grid for UE pool size and window stride.
- Assumptions/dependencies:
- Moderate UE sharing works best; excessive sharing can degrade layer specialization.
- Requires monitoring of validation PPL and routing skew for early stopping.
- Stable routing and utilization monitoring in MoE production systems
- Sectors: MLOps, Cloud/Serving
- What: Adopt UELB and connectivity normalization to reduce expert collapse and maintain balanced expert utilization across layers.
- Tools/workflows:
- Telemetry panels for per-expert utilization normalized by exposure (c_j), Max/Mean skew, path diversity.
- Alarms when depth-wise balance deviates from expected windows.
- Assumptions/dependencies:
- Availability of per-layer routing statistics; minor changes to logging pipelines.
- On-device or edge assistants with higher capability at fixed budget
- Sectors: Consumer AI, Mobile/Edge, Automotive
- What: Maintain a fixed per-token activation footprint while leveraging Virtual Width to improve quality within device constraints.
- Tools/workflows:
- Distilled MoUE variants tailored to mobile NPUs/TPUs with within-core routing windows.
- Static routing window configurations to avoid cross-chip traffic.
- Assumptions/dependencies:
- Hardware supports sparse expert activation and small router state updates.
- Memory limits require careful UE pool sizing and windowing.
- Research on multi-step reasoning and algorithmic tasks
- Sectors: Academia, Research labs, Robotics (planning), Education tech
- What: Use the Universal Router’s trajectory-aware routing to study deeper compositional reasoning without growing activated parameters.
- Tools/workflows:
- Benchmarks emphasizing multi-hop reasoning and logic (e.g., GSM-like, proof steps).
- Analyses of emergent “expert circuits” under different topologies.
- Assumptions/dependencies:
- Benefits are clearest where recursive composition helps; simple tasks may see smaller gains.
- Energy and cost optimization for training and serving
- Sectors: Cloud/Datacenter Ops, Sustainability initiatives, Policy advisory for green AI
- What: Achieve better validation loss per FLOP and improved accuracy at fixed TP/Act, reducing compute and energy for target quality.
- Tools/workflows:
- Fleet-level experiments comparing MoE vs. MoUE energy per benchmark point.
- Procurement guidelines favoring architectures that decouple TP from Act (conditional compute).
- Assumptions/dependencies:
- Realized efficiency depends on system software (kernel, collectives) and adherence to within-node routing.
Long-Term Applications
- Multimodal MoUE: Universal experts shared across text, vision, and speech layers
- Sectors: Multimodal AI, AV/Robotics, Media
- What: Extend UE pools to multimodal towers to reuse cross-layer operators (e.g., geometric reasoning) across modalities with Virtual Width.
- Tools/products:
- MoUE adapters for VLMs/Speech Transformers; cross-tower connectivity masks.
- Assumptions/dependencies:
- Requires research on modality-specific exposure normalization and router state sharing.
- Hardware-software co-design for expert reuse and stateful routing
- Sectors: Semiconductors, Cloud accelerators, Systems
- What: Accelerator primitives for allow-list gating, localized Top-K, and fast-weight router state, reducing routing overhead and latency.
- Tools/products:
- Compiler passes for per-group connectivity; on-chip caches for UE parameters.
- NIC/collective optimizations to keep UE windows on the same node.
- Assumptions/dependencies:
- Hardware roadmap alignment; standardized APIs for conditional compute.
- Adaptive compute at inference: dynamic traversal of Virtual Width
- Sectors: Production AI, Personal assistants, Finance/Healthcare triage
- What: Time/latency-aware policies that adjust depth-wise reuse (virtual path length) per query difficulty without increasing Act beyond a budget envelope.
- Tools/products:
- Controllers that modulate window stride/UE pool engagement based on uncertainty/risk.
- Assumptions/dependencies:
- Further research on calibration and controllable trade-offs between latency and quality.
- Cross-model or multi-tenant universal expert banks
- Sectors: Model-as-a-Service providers, Enterprises with multiple LLM variants
- What: Share a “library” of universal experts across different model variants/projects to reduce overall parameter footprint and improve consistency.
- Tools/products:
- Repository of UEs with versioning; adapters that map local layers to shared UE IDs.
- Assumptions/dependencies:
- Standardization of feature spaces and router interfaces across models; IP/governance considerations.
- Safety, auditability, and interpretability via stable expert circuits
- Sectors: Regulated industries (Healthcare, Finance, Government), Policy/Compliance
- What: Use structured connectivity and depth-aware load balance to map consistent “circuits” for specific functions (e.g., arithmetic, code), aiding audits and ISO/AI Act compliance.
- Tools/products:
- Circuit discovery tools that visualize per-group UE usage and path diversity over depth.
- Assumptions/dependencies:
- Method development for attributing predictions to UE paths with low false attribution rates.
- Federated or privacy-preserving training with shared UEs
- Sectors: Healthcare networks, Financial consortia, Edge fleets
- What: Keep a global UE pool shared across clients while local experts remain private and layer-local, enabling cross-client reuse without sharing all parameters.
- Tools/products:
- Federated training protocols that update shared UEs centrally and local experts on-device.
- Assumptions/dependencies:
- Robust exposure normalization across heterogeneous client depths and data; privacy-preserving aggregation for router statistics.
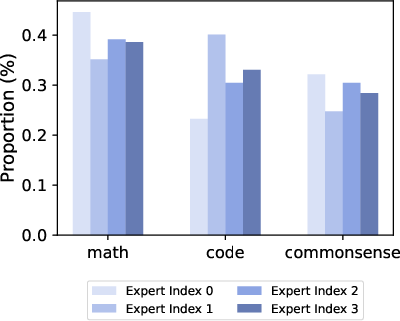
- Task plug-ins as universal experts
- Sectors: Productivity suites, Developer tools, Enterprise workflows
- What: Deliver specialized capabilities (math, code, compliance) as plug-in UEs that can be invoked across layers in many products.
- Tools/products:
- UE plug-in marketplace; APIs for packaging and distributing expert weights.
- Assumptions/dependencies:
- API standards for safe integration; licensing and security vetting.
- Curriculum and lifelong learning with progressive expert reuse
- Sectors: Education tech, Corporate training, R&D
- What: Long-horizon training regimes that progressively expand UE pools and reuse patterns as new domains are added, retaining prior capabilities efficiently.
- Tools/products:
- Automated schedules for logit suppression and window rotation as new data/tasks arrive.
- Assumptions/dependencies:
- Strategies to prevent catastrophic interference when expanding shared pools.
- Policy guidance for sustainable AI scaling
- Sectors: Government, Standards bodies, NGOs
- What: Inform guidelines that encourage conditional compute designs (like MoUE) to reduce energy/compute intensity per capability gain.
- Tools/products:
- Benchmarking frameworks that report TP/Act/Virtual Parameters and energy per task score.
- Assumptions/dependencies:
- Broad industry adoption of reporting standards; independent audits of energy metrics.
Notes on feasibility across applications:
- The strongest near-term value accrues where MoE infrastructure already exists. MoUE’s gains (1–4%) are meaningful at scale but require careful engineering of routers, connectivity masks, and UELB.
- Inference-time costs generally remain stable if per-token activated parameters are fixed; however, real systems may see small overheads from more complex routing and state updates.
- Benefits appear larger on reasoning and multi-step tasks; simpler tasks may see smaller returns.
- Excessive sharing of UEs can hurt specialization; choose UE pool sizes and window parameters by validation metrics (e.g., perplexity, routing skew).
Glossary
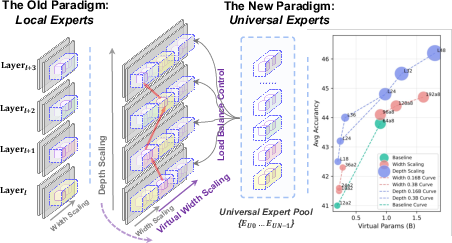
- Activated parameters (Act): The subset of model parameters actually used per token; a budget often matched across models for fair comparison. "We report three budgets: activated parameters (Act), total physical parameters (TP), and virtual parameters (VP)"
- Activation budget (per-token activation budget): A limit on how many parameters or experts can be used for each token’s computation. "under a fixed per-token activation budget"
- All-to-All (Unconstrained): A connectivity scheme where every layer can reach every expert, often unstable or costly. "Full All-to-All (Unconstrained)"
- Auxiliary load-balancing loss: An extra objective to prevent overuse of a few experts by encouraging balanced routing. "optimize an auxiliary load-balancing loss"
- BASE layers: A routing formulation for MoE that balances experts using a specific objective. "BASE layers"
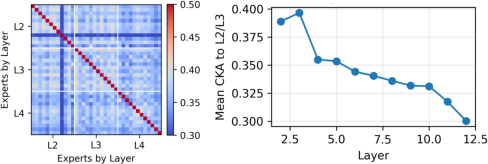
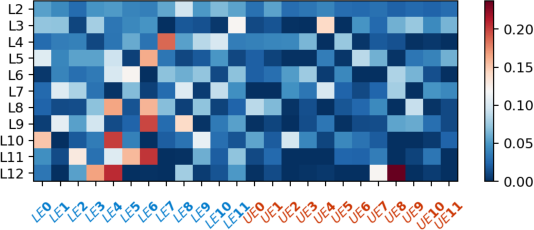
- CKA similarity: A similarity measure (Centered Kernel Alignment) used to compare learned representations or weights. "we analyze the CKA similarity of expert weights"
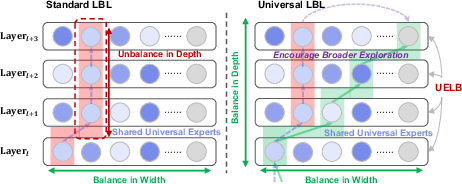
- Combinatorics Blindness: A shortcoming of standard balancing losses that ignore the combinatorial diversity of multi-layer paths. "Combinatorics Blindness: it ignores path redundancy across layers"
- Conditional computation: Activating only a subset of experts/functions per input to increase efficiency. "The Mixture-of-Experts (MoE) framework alleviates this tension by introducing conditional computation"
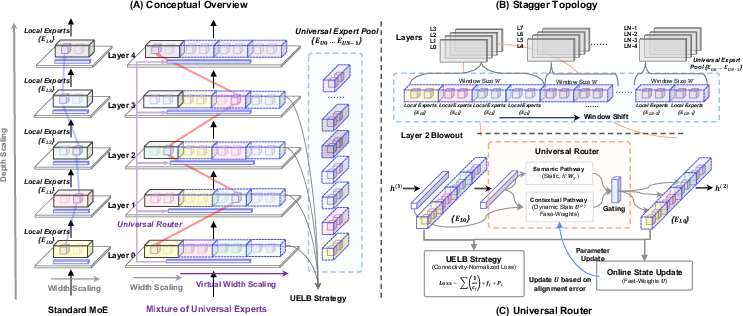
- Connectivity group: A set of consecutive layers sharing the same accessible experts under the topology. "a connectivity group comprising G consecutive layers"
- Connectivity mapping: A binary map indicating which experts are reachable from which layers. "MoUE is defined by a connectivity mapping"
- Connectivity normalization: Adjusting balancing signals to account for how often an expert is reachable across layers. "dropping connectivity normalization further degrades results"
- Contextual pathway: The routing component that conditions on a depth-wise state to make coherent multi-step decisions. "a semantic pathway and a contextual pathway"
- Curriculum Routing Warmup via Logit Suppression: A staged procedure that gradually enables universal routing by penalizing it at first. "Curriculum Routing Warmup via Logit Suppression."
- Data-to-parameter ratio: A scaling guideline relating the amount of training data to model size. "follow a fixed data-to-parameter ratio"
- Depth expansion: Increasing effective computation steps by reusing experts across more layers without proportionally adding parameters. "Depth Expansion"
- Dual-Pathway Routing: A router design combining semantic matching with a trajectory-aware context signal. "Dual-Pathway Routing."
- Expert collapse: A failure mode where only a few experts receive most of the traffic, harming diversity. "the expert collapse phenomenon"
- Expert-parallel (EP): A systems setup distributing experts across devices/nodes for parallel execution. "the expert-parallel (EP) size"
- Fast weights: Quickly updated, transient parameters used to maintain routing state across steps. "a state matrix U{(\ell)} as fast weights over depth"
- Feed-Forward Network (FFN): The per-layer MLP submodule in Transformers, often replaced by experts in MoE. "replaces the static feed-forward network (FFN)"
- FLOPs: A measure of computational cost in floating-point operations. "increasing parameters tends to increase both computation (FLOPs)"
- Gating network: The function that produces routing probabilities over experts given token representations. "a gating network G_\theta ... computes a routing distribution"
- Heterogeneous Exposure: Unequal opportunities for experts to be selected due to topology, which must be corrected in balancing. "Heterogeneous Exposure: shared experts are over-penalized for being reachable from many layers"
- Inter-node communication overhead: Extra cost from routing across devices; topologies often constrain routing to avoid it. "avoid introducing additional inter-node communication overhead"
- Iso-parameter and iso-compute: Comparisons where total parameters or compute are held constant across models. "iso-parameter and iso-compute comparisons"
- Layer-agnostic: Not tied to a specific layer; reusable across multiple depths. "a shared pool of layer-agnostic Universal Experts (UEs)"
- Load balancing (Standard Load Balancing Optimization): A regularization strategy to distribute traffic evenly among experts. "Standard Load Balancing Optimization."
- Logit suppression: Temporarily reducing the router scores for certain experts to control their early usage. "via Logit Suppression"
- Max/Mean ratio: A metric indicating routing skew by comparing maximum to average expert load. "Max/Mean ratio"
- Mixture of Universal Experts (MoUE): An MoE generalization that reuses a shared expert pool across layers to create virtual width. "Mixture of Universal Experts (MoUE)"
- Mixture-of-Experts (MoE): An architecture that activates a sparse subset of experts per token to decouple capacity from compute. "Mixture-of-Experts (MoE) decouples model capacity from per-token computation"
- Per-exposure utilization: Usage normalized by how often an expert is available, used for fair balancing. "so the objective reflects per-exposure utilization rather than cross-layer aggregated usage"
- Perplexity: A standard language modeling metric; lower is better. "Perplexity"
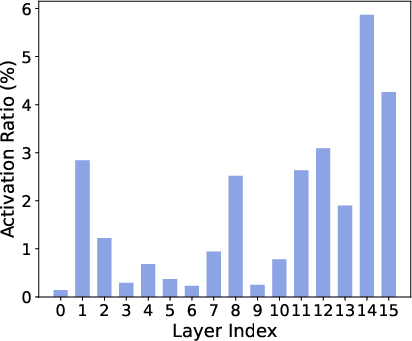
- Re-entrant Loops: Stable, recurring expert circuits encouraged by the proposed topology. "Re-entrant Loops"
- Routing distribution: The probability distribution over experts produced by the router. "computes a routing distribution"
- Routing path explosion: Exponential growth of possible expert sequences when reusing experts across layers. "a routing path explosion from recursive expert reuse"
- Routing skew: Imbalance in expert selection across tokens or steps. "routing skew / load-balance indicator"
- Semantic pathway: The router component performing standard content-based matching. "a semantic pathway and a contextual pathway"
- Sliding window: A moving subset of experts or layers used to structure connectivity. "a large sliding window defines the union of experts accessible"
- Softmax: The function converting logits to probabilities in routing. "P(x) = \operatorname{softmax}(W_g x)"
- Staggered Rotational Topology: A structured reuse scheme rotating access to a shared expert pool across depth. "a Staggered Rotational Topology for structured expert sharing"
- State matrix: The matrix of fast weights maintaining context for routing over depth. "a state matrix U{(\ell)}"
- Supervised fine-tuning (SFT): Post-pretraining task adaptation with labeled data. "after SFT"
- Top-K selection: Activating only the top-scoring experts per token for sparsity. "TopK"
- Topological degree: The number of layers from which an expert is reachable (its exposure count). "topological degree (exposure count)"
- Trajectory state: Lightweight context carried across layers to make coherent multi-step routing decisions. "lightweight trajectory state"
- Universal Expert (UE): An expert shared and reusable across multiple layers. "Universal Experts (UEs)"
- Universal Expert Load Balance (UELB): A depth-aware balancing objective that normalizes for exposure across layers. "we propose Universal Expert Load Balance (UELB)"
- Universal Router: A router augmented with trajectory state for coherent multi-step routing. "a Universal Router with lightweight trajectory state"
- Universal Transformers: Models that reuse the same transformation across multiple steps/layers to introduce recurrence. "Universal Transformers"
- Virtual parameters (VP): An accounting of effective capacity that includes virtual width from reuse. "virtual parameters (VP)"
- Virtual Width: Effective width created by reusing a shared expert pool across layers. "introducing a novel scaling dimension: Virtual Width."
- Warm-start: Initializing training from a pretrained checkpoint to speed convergence or stabilize training. "MoUE can be warm-started from arbitrary MoE checkpoints"
- Width expansion: Increasing effective capacity by enlarging the universal expert pool without increasing activated or total parameters. "Width Expansion"
Collections
Sign up for free to add this paper to one or more collections.