AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
Abstract: We introduce the AI co-mathematician, a workbench for mathematicians to interactively leverage AI agents to pursue open-ended research. The AI co-mathematician is optimized to provide holistic support for the exploratory and iterative reality of mathematical workflows, including ideation, literature search, computational exploration, theorem proving and theory building. By providing an asynchronous, stateful workspace that manages uncertainty, refines user intent, tracks failed hypotheses, and outputs native mathematical artifacts, the system mirrors human collaborative workflows. In early tests, the AI co-mathematician helped researchers solve open problems, identify new research directions, and uncover overlooked literature references. Besides demonstrating a highly interactive paradigm for AI-assisted mathematical discovery, the AI co-mathematician also achieves state of the art results on hard problem-solving benchmarks, including scoring 48% on FrontierMath Tier 4, a new high score among all AI systems evaluated.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces the “AI co‑mathematician,” a digital workspace that helps real mathematicians do research. Think of it as a team of smart AI assistants who work together like a study group: they brainstorm ideas, search the literature, run computer experiments, draft write‑ups, check each other’s work, and keep everything organized—while a human mathematician remains the leader and decision‑maker.
What questions are the authors trying to answer?
The authors ask:
- How can AI help with the full, messy reality of doing math—not just writing final proofs, but also exploring ideas, reading papers, testing examples, and changing direction when things don’t work?
- Can we design an AI system that behaves like a helpful collaborator over days or weeks, instead of a one‑off chatbot answer?
- Does this approach actually help mathematicians discover new results, and can it solve very hard problems better than existing AI systems?
How does the AI co‑mathematician work?
Picture a group project with roles, a shared folder, and a project manager:
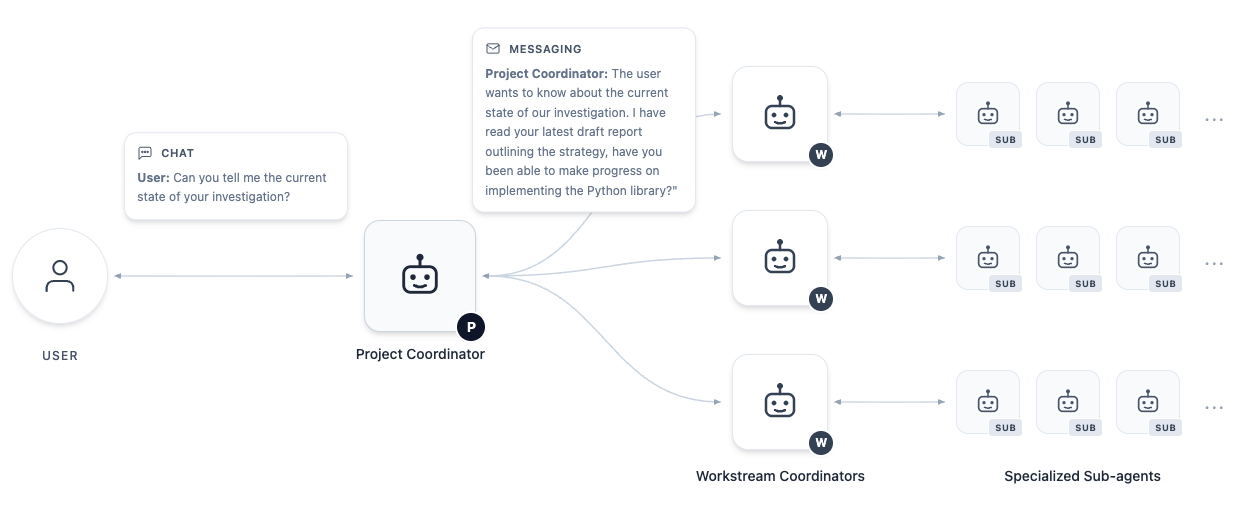
- A “project coordinator” AI acts like the team captain. It talks with the human user to clarify the goal (“What exactly are we trying to prove?”), then breaks the work into tasks.
- Specialized “agents” (AI assistants) handle different jobs. Some search research papers, some write and test code, some sketch proofs, and some act as reviewers who check the others’ work.
- Everything lives in a single “workspace” (like a well‑organized Google Drive), so notes, code, drafts, and failed attempts are saved and easy to revisit.
Here are some key ideas, explained with everyday analogies:
- Iterative intent setting: Instead of requiring a perfect prompt, the system has a short “on‑boarding” chat—like agreeing on a clear research question before you start a science fair project.
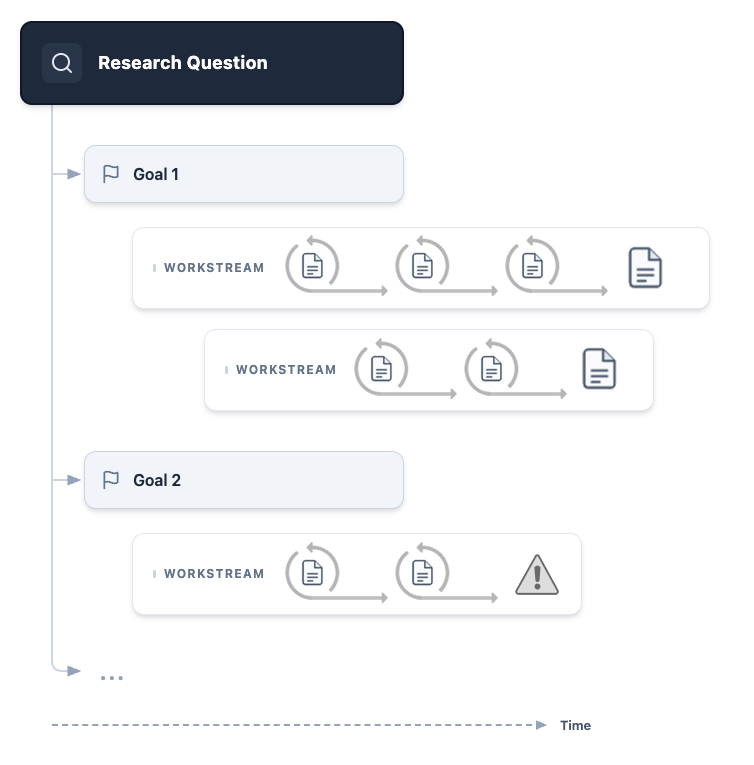
- Parallel workstreams: The coordinator spins up several mini‑projects at once (for example, “find relevant papers,” “build the code,” “try a new approach”), so progress happens in parallel.
- Stateful workspace: “Stateful” just means the system remembers everything. It’s like keeping a living lab notebook rather than a single chat history that gets lost.
- Asynchronous work: Agents can work in the background while you keep steering the project—like classmates continuing their tasks while you update the plan.
- Managing uncertainty: When the AI isn’t sure, it doesn’t hide it. The system highlights uncertain claims, flags missing references, and asks for human help when stuck.
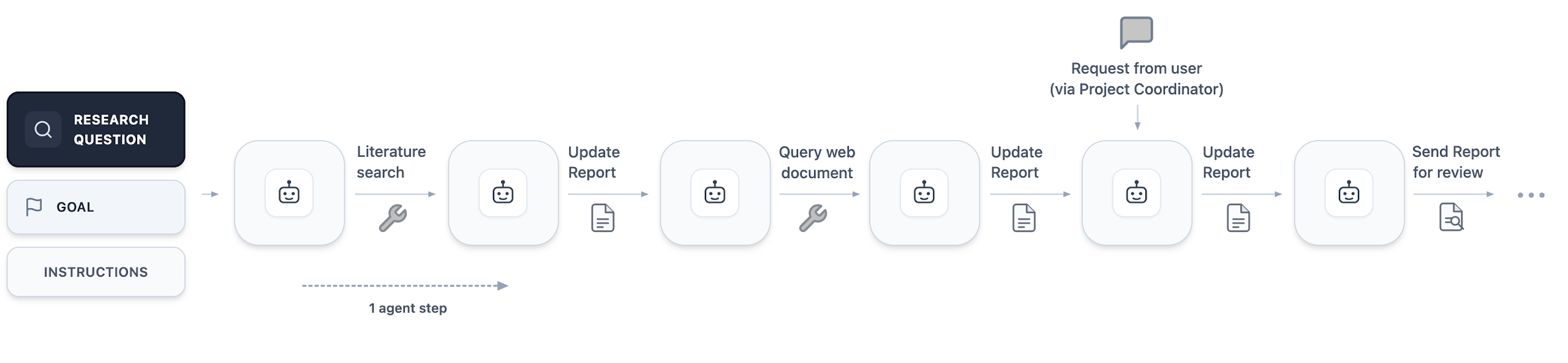
- Review cycles with hard rules: Before a report is marked “done,” reviewer agents must approve it. Code must pass its tests; facts and citations are checked. This blocks “hand‑wavy” shortcuts.
- “Working paper” as the main output: Instead of a chat answer, you get a draft paper (LaTeX) with margin notes that show where claims came from, link to code, and mark what’s solid vs tentative.
- Preserving failed attempts: Dead ends are saved on purpose. Like in science, knowing what didn’t work helps you avoid repeating mistakes and can spark better ideas next time.
Under the hood, the system uses LLMs for reasoning and writing, plus tools for web/literature search and running code on the cloud. It’s designed to plug in stronger engines (like advanced proof or search systems) as they become available, but already works with standard, commercially available models.
What did they find?
Early uses by professional mathematicians show promising results:
- It helped resolve an open problem from the Kourovka Notebook (a well‑known collection of unsolved group theory problems). The AI’s first draft had a gap, but it suggested a clever strategy; the human spotted how to fix the gap, and together they produced a correct proof. This shows the system works best as a partner for experts.
- It supported research on certain “Stirling coefficient” questions by proposing proof strategies, generating computational evidence, and flagging a key insight in margin notes that prompted useful follow‑up.
- It produced a neat lemma in a Hamiltonian systems subproblem and helped quickly rule out a misleading approach—saving the researcher time by reaching a dead end faster.
- On very hard standardized benchmarks, it performed strongly:
- FrontierMath Tier 4 (a tough, research‑style set of 50 problems): it correctly solved 48% (23/48 excluding public samples), which the authors report as a new high among tested AI systems. This beat the base model it’s built on, suggesting orchestration (parallel tasks, reviews, tools) adds real value.
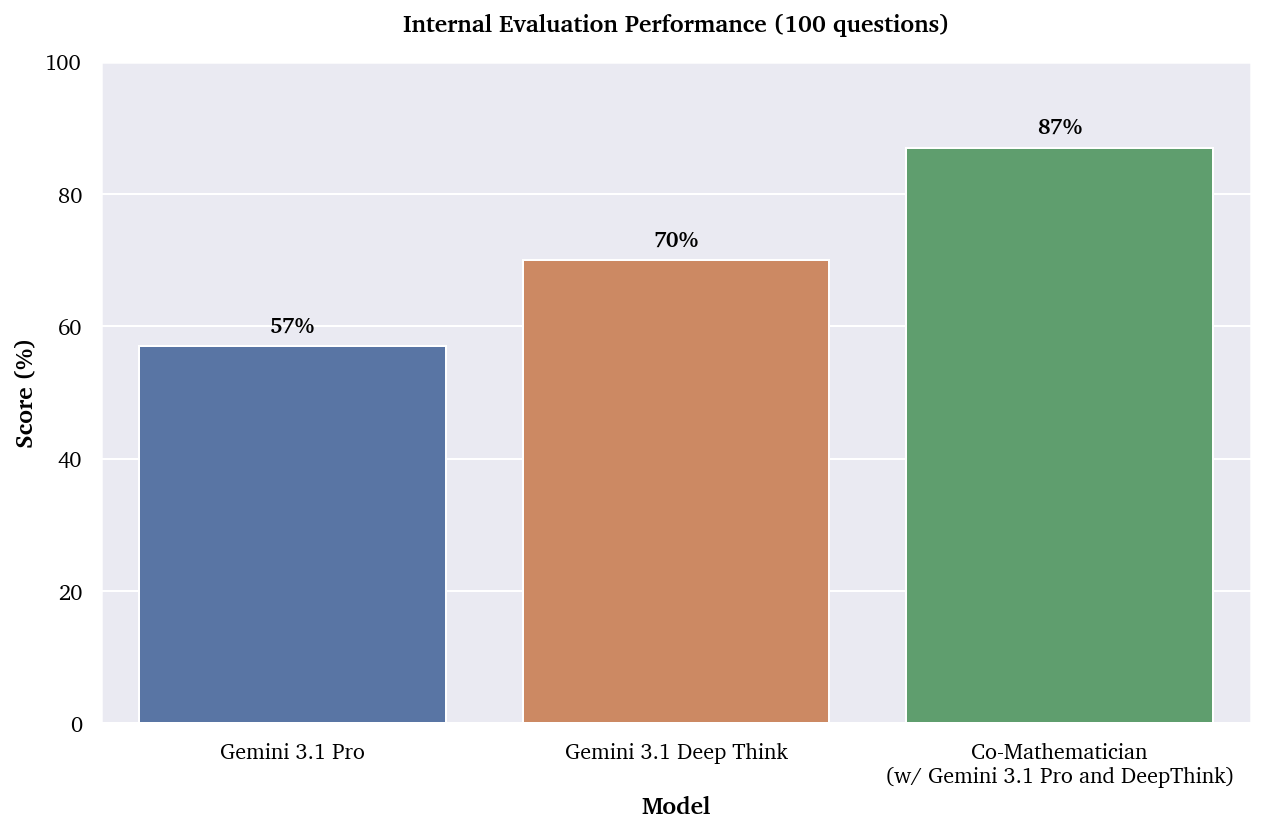
- On an internal set of 100 researcher‑level problems with checkable answers, it also outperformed single‑shot model calls.
Why this matters:
- The tool doesn’t just “answer questions”—it supports the full process of math research, from idea to evidence to draft, with checks and transparency.
- It shows that having a team‑like AI setup with review and persistent memory can improve reliability and results over one‑off model responses.
What’s the potential impact?
If developed and shared more widely, this approach could:
- Help mathematicians explore more ideas faster, by offloading search, coding, and drafting—while keeping humans in charge of judgment and creativity.
- Make long projects easier to navigate by organizing goals, experiments, proofs, and failures in one place, with clear status and reviewer feedback.
- Encourage higher standards for AI‑assisted math by tracking uncertainty, enforcing reviews, and producing native mathematical artifacts (like proper write‑ups and audited code).
- Shift how we evaluate AI in math: not only “Can it solve a problem on its own?” but also “Can it accelerate human researchers across the full workflow?”
The authors emphasize this is not about replacing mathematicians. It’s about building a reliable, interactive “co‑pilot” that helps experts do better, clearer, and faster research—and that can integrate even more powerful proof and search engines as those improve.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that the paper leaves unresolved and that future researchers could address:
- Quantify compute usage and efficiency: no systematic reporting of token counts, wall-clock time, parallelism, or energy consumption per task/workstream; unclear compute-for-performance tradeoffs.
- Fairness of benchmark comparisons: FrontierMath runs used an unconstrained, custom tool stack and no token limit, unlike standard harness evaluations; requires controlled comparisons under identical budgets and tool access.
- Reproducibility of evaluations: the interactive agent harness, tool implementations, and exact configurations used for benchmarks are not released; no seeds or run-to-run variance analyses are provided.
- Ablation studies are missing: the contribution of each architectural component (reviewer agents, progressive disclosure, hard constraints, branching workstreams, literature tools) to performance is not quantified.
- Reviewer-agent reliability: no measurements of false positive/negative rates in error detection, susceptibility to shared blind spots with authoring agents, or the benefits of reviewer diversity (different models, prompts, or toolsets).
- Risk of self-consistency bias: the same base models that generate proofs also review them; need protocols that ensure independence (e.g., different model families, adversarial reviewers) and quantify the effect.
- Informal proofs dominate: current workflow produces informal proofs; no systematic integration or evaluation of formal verification (e.g., Lean/Isabelle via AlphaProof) to certify a subset of results.
- Criteria for when to formalize: no decision policy for selecting lemmas or sections for formal proof versus informal reasoning, nor metrics for impact on correctness and throughput.
- Quality and verification of citations: while “citation checking” is mentioned, there are no precision/recall metrics for literature retrieval, hallucinated references, or misapplied theorems.
- Literature tools are under-specified: details of the “computationally intensive search tool” are absent; retrieval quality, indexing sources, and failure modes are not benchmarked against academic baselines.
- Handling of flawed or adversarial user input: robustness to incorrect, misleading, or adversarial user guidance is untested; no safeguards or escalation protocols beyond manual user steering.
- Managing uncertainty is unquantified: the system tracks/communicates uncertainty, but there are no operational definitions or metrics (e.g., uncertainty resolution rate, time-to-clarify, reviewer–author disagreement rates).
- Negative result tracking utility: the value of preserving failed workstreams is asserted but not measured (e.g., reuse frequency, impact on later success, or user comprehension benefits).
- Human factors and learning curve: no controlled user study quantifies productivity gains, cognitive load reduction, or the skill dependency observed by early users; optimal interaction patterns are unknown.
- Generalizability across domains: early cases are small and topic-specific; performance and agent orchestration in areas like algebraic geometry, number theory, logic, or applied PDEs are not systematically evaluated.
- Scalability to long-horizon projects: persistence and coordination across weeks-months, with many branching workstreams and evolving goals, are not stress-tested or measured.
- Concurrency and orchestration reliability: no analysis of failure modes in multi-agent communication (e.g., deadlocks, starvation, conflicting edits), nor benchmarks for task scheduling and escalation efficacy.
- Code execution safety and sandboxing: parallel code runs on cloud machines, but sandboxing, dependency security, network restrictions, and resource-quota policies are unspecified.
- Test oracle reliability: “golden values” and tests gate code completion, yet the process for validating the oracles themselves (to avoid encoding errors into tests) is not described or evaluated.
- Internet/tool usage policies on benchmarks: clarity is needed on what external resources were accessible during evaluations (e.g., web, arXiv), to assess leakage risks and comparability.
- Benchmark contamination safeguards: while internal problems are “unleaked,” controls against training-data overlap or indirect contamination (e.g., via cited literature) are not described.
- Lack of research-math-specific benchmarks: the paper argues for broader measurements (e.g., literature synthesis, conjecture refinement, reviewer response cycles) but does not propose or release such benchmarks.
- No error taxonomy: failure modes (hallucinated lemmas, premature success claims, brittle heuristics) are discussed qualitatively; a structured taxonomy with frequency and severity would guide mitigations.
- Integration with formal libraries: how to bridge informal artifacts to formalizable statements (granularity, library gaps, refactoring cost) remains an open engineering and methodological question.
- Provenance and audit trails: while margin notes link claims to workspace artifacts, there is no standardized provenance schema, export format, or audit tool to reproduce agent trajectories.
- Data privacy and IP: policies for handling unpublished manuscripts, proprietary notes, or embargoed results are not addressed; ownership and authorship attribution for AI-generated artifacts are unclear.
- Result portability: mechanisms to export/import projects (LaTeX, code, data, and state) into external toolchains (arXiv, Git repos, proof assistants) are only sketched and not validated in practice.
- Cross-model portability: the system is “model-agnostic” in principle but only tested on Gemini; how orchestration performs with other model families (and with heterogeneous ensembles) is untested.
- Compute-aware scheduling policies: no description of how the system allocates compute among workstreams, prioritizes interventions, or throttles nonproductive loops beyond global time limits.
- Robustness to stochasticity: reproducibility under different random seeds or sampling strategies (temperature, beam settings) for key agents is not characterized.
- Escalation loops and termination criteria: policies to avoid endless reviewer-author cycles, resolve disagreements, and decide when to solicit human help need formalization and empirical evaluation.
- UI design efficacy: progressive disclosure and margin-note annotations are untested with controlled UX studies; impacts on comprehension, trust calibration, and error detection are unknown.
- Comparative baselines: no head-to-head comparisons with alternative orchestration frameworks (e.g., generic agent runtimes, coding copilots adapted for math) under matched compute and tooling.
- Access and openness: the system is in limited release; lack of public artifacts (code, datasets, benchmarks, logs) hinders community verification and iteration.
- Ethical considerations: guidance on crediting AI contributions in publications and managing dual-use concerns (e.g., misuse of automated search) is absent.
- Long-term maintenance of “living working papers”: versioning strategy for evolving mathematical claims, retractions, and dependency updates is not defined or evaluated.
- When to invoke heavier engines: policies for integrating AlphaEvolve/AlphaProof/Aletheia (trigger conditions, budget thresholds, expected payoff) are proposed conceptually but not implemented or tested.
- Domain-specific toolchains: feasibility and benefits of specialized pipelines (e.g., SAT/SMT, CAS, toric packages, representation-theory libraries) within workstreams are not mapped or benchmarked.
- Multilingual and accessibility support: interactions, literature, and artifacts appear English-centric; accessibility features and multilingual workflows are not discussed.
Practical Applications
Immediate Applications
Below are actionable, deployable use cases that can be implemented with the paper’s current architecture: a stateful, agentic, human-in-the-loop workbench that orchestrates literature search, code, review, and write-ups with provenance, uncertainty tracking, and parallel workstreams.
- Research acceleration workbench for mathematics departments
- Sectors: Academia, Publishing
- What: Adopt the AI co-mathematician to coordinate literature reviews, computational experiments, and iterative write-ups that preserve provenance, uncertainty, and failed attempts; manage multi-week projects via parallel workstreams and reviewer agents.
- Tools/products/workflows: Department- or lab-level “research workspaces,” Overleaf/LaTeX connector for working papers with margin annotations, shared filesystem for artifacts, reviewer-bot rounds with escalation, negative-results registry.
- Assumptions/dependencies: Access to capable LLMs, institution-approved literature APIs (arXiv/Crossref/publishers), compute budgets for asynchronous agent runs, faculty oversight and IRB/data policies for uploads.
- Agentic literature and citation auditing
- Sectors: Academia, Publishing, Libraries
- What: Use the literature-review and web-access sub-agents to retrieve exact statements, cross-check citations, flag potential hallucinations/retractions, and link claims to sources via margin notes.
- Tools/products/workflows: Citation Checker Bot for editors/referees, “evidence pane” in working papers, auto-generated reading lists per conjecture/lemma.
- Assumptions/dependencies: Reliable metadata/APIs, publisher license compliance, reviewer acceptance of AI-assisted checks.
- Reproducible computational math pipelines with enforced tests
- Sectors: Academia, Software/ML
- What: Generate tested libraries for simulations/optimization (e.g., SAT reductions, branch-and-bound), gate code completion on passing tests and reviewer approval, run parallel jobs on cloud automatically.
- Tools/products/workflows: Code Agent with test harness and golden values, containerized artifacts, cloud job manager for long runs, result collation into appendices.
- Assumptions/dependencies: Stable tool execution environments, cost control for compute, adequate test coverage to prevent false “green ticks.”
- Peer-review augmentation for journals and seminars
- Sectors: Publishing, Academia
- What: Use reviewer agents to spot-check logic, recompute figures/tables, verify references, and annotate uncertainty; escalate unresolved issues to human editors.
- Tools/products/workflows: “AI review pre-check” service for submissions; seminar “proof audit” runs producing annotated handouts.
- Assumptions/dependencies: Editorial policies defining scope/liability, transparent audit logs, human-in-the-loop final judgments.
- Graduate advising, seminars, and reading groups
- Sectors: Education
- What: Scaffold “structured posing of questions,” iterate problem statements, surface dead ends early, assign parallel workstreams (proof attempt vs. counterexample search), and maintain a living working paper for the group.
- Tools/products/workflows: Advisor dashboard for multiple student workspaces, reading group copilot that schedules sub-problems and tracks failed hypotheses, progressive-disclosure UI to manage cognitive load.
- Assumptions/dependencies: Academic integrity guardrails, clear policies for authorship/credit, cost controls for student use.
- Competition/problem-solving with auditing
- Sectors: Education
- What: Offer explain-first modes that preserve solution trajectories and uncertainty; enable instructors to assess reasoning steps rather than just final answers.
- Tools/products/workflows: “Explain-then-answer” mode with immutable reasoning logs; rubric-aligned reviewer checks.
- Assumptions/dependencies: Institutional policies, secure modes to prevent abuse during assessments.
- Enterprise algorithm and heuristic design
- Sectors: Software Engineering, Operations Research, Energy, Logistics, Finance (quant dev)
- What: Co-design, test, and scale heuristic search, pruning strategies, SAT/ILP formulations; orchestrate experiments and produce documented, provenance-linked design docs.
- Tools/products/workflows: Optimization copilot with code+report dual workstreams, auto-benchmarking against baselines, cloud parallelization.
- Assumptions/dependencies: Domain data access, engineering oversight, reproducibility policies, IP protections.
- Internal technical document drafting with uncertainty tracking
- Sectors: Software/Hardware, Finance, Research Labs
- What: Draft RFCs/design docs that surface assumptions, link to code/tests, and maintain versioned claim histories; progressive disclosure for leadership vs. implementers.
- Tools/products/workflows: “Provenance-first” doc templates, reviewer agent loops, integration with GitHub/GitLab CI artifacts.
- Assumptions/dependencies: Access to repositories, confidentiality/compliance alignment, change-management norms.
- Negative-results registries for R&D
- Sectors: Academia, Industrial R&D
- What: Capture dead ends and exhausted strategies as first-class outputs to prevent duplication and to inform next steps.
- Tools/products/workflows: Searchable registry across workspaces; tags for failed lemmas/strategies; “restart from failure” templates.
- Assumptions/dependencies: Culture change to value negative results, access control for sensitive projects.
- Interactive benchmarking and evaluation services
- Sectors: AI R&D, Academia, Policy think tanks
- What: Measure auxiliary capabilities (literature synthesis, error-finding, uncertainty management) alongside answer accuracy; generate reproducible evaluation artifacts.
- Tools/products/workflows: Interactive benchmark harness with time/compute caps; artifact bundles with machine-readable provenance; leaderboard dashboards.
- Assumptions/dependencies: Community-agreed task definitions, standard metadata schemas, sustainable compute budgets.
Long-Term Applications
These opportunities require additional research, integration with formal systems, scaling, or changes in standards/regulation before broad deployment.
- Proof-orchestrated CI/CD and certification for safety-critical systems
- Sectors: Robotics, Automotive/Aerospace, Medical Devices, Cryptography/Blockchain
- What: Integrate formal provers (e.g., Lean/Coq/Isabelle via AlphaProof-like engines) into the agentic workflow to produce machine-checked invariants, proof-carrying builds, and certification bundles.
- Tools/products/workflows: “Proof gate” stages in CI, compliance exports (DO-178C, ISO 26262), formal counterexample search alongside code generation.
- Assumptions/dependencies: Coverage of formal libraries for target domains, reliable prover-model interfaces, regulator acceptance, significant compute and verification expertise.
- Cross-domain co-scientist platforms (theory + computation + experiment)
- Sectors: Physics, CS Theory, Economics, Materials, Bio/Health (biostatistics)
- What: Extend orchestration to experimental design, simulator control, and data pipelines to close loops from conjecture to analysis to publication.
- Tools/products/workflows: Lab/ELN and simulator adapters, uncertainty-calibrated evidence dossiers, human-steerable exploration/exploitation controllers (e.g., evolutionary runs).
- Assumptions/dependencies: Safe instrument integrations, data governance, robust causal/statistical reasoning, institutional approvals.
- Policy-grade evidence synthesis with machine-auditable provenance
- Sectors: Government, Standards Bodies, NGOs
- What: Produce living white papers and regulatory impact analyses with explicit assumption tracking, uncertainty annotations, and re-runnable computations.
- Tools/products/workflows: Evidence Dossier Builder, source-of-truth registries, reproducible containers and checksums.
- Assumptions/dependencies: Procurement and legal frameworks, transparent audit policies, public data access, multi-stakeholder governance.
- Individualized research apprenticeships at scale
- Sectors: Higher Education, Professional Training
- What: Studio-style courses where co-research agents scaffold projects, manage workstreams, and provide formative review; issue machine-verifiable learning artifacts.
- Tools/products/workflows: Program-level dashboards, competency-mapped reviewer prompts, portfolio exporters for accreditation.
- Assumptions/dependencies: Accreditation standards, integrity safeguards, faculty training in AI-collaboration pedagogy.
- Machine-actionable knowledge graphs of conjectures, lemmas, proofs, and artifacts
- Sectors: Academia, Publishing, Knowledge Platforms
- What: Convert working papers and reviews into structured graphs that link claims to code, data, and literature, enabling powerful discovery and meta-research.
- Tools/products/workflows: Provenance schemas, DOI/ORCID integration, graph query interfaces, automated contradiction detection.
- Assumptions/dependencies: Interoperability standards, IP/licensing alignment, sustained curation.
- Marketplaces for pluggable agent modules and tools
- Sectors: Software Platforms, Research Tooling
- What: Ecosystems of specialized reviewer agents, literature connectors, search/optimization engines (e.g., evolutionary search), formal bridges, and compute backends.
- Tools/products/workflows: Secure agent runtime, policy sandboxes, usage metering/billing, reputation systems for agents.
- Assumptions/dependencies: API and security standards, trust/safety moderation, monetization models.
- Scientific ERP for enterprise R&D
- Sectors: Pharma, Energy, Materials, Advanced Manufacturing
- What: Unify experiment orchestration, theory-building, code, compliance, and reporting under a provenance-first agentic layer.
- Tools/products/workflows: LIMS/ELN/Git integration, budget-aware compute scheduling, auditor views, “green tick” compliance dashboards.
- Assumptions/dependencies: Integration with legacy systems, privacy-by-design, change management, validation under GxP-like regimes.
- Safety assurance for advanced AI systems
- Sectors: AI Safety, Cloud Platforms
- What: Use dual agent teams (red/blue) with formal-methods bridges to generate, test, and certify safety claims and constraints on model behavior.
- Tools/products/workflows: Safety spec workspaces, property-based testing at scale, formal counterexample-guided refinement.
- Assumptions/dependencies: Mature formalizations of safety properties, scalable tooling, acceptance by regulators/third-party auditors.
- Citizen science and open-problem platforms
- Sectors: Public Education, Nonprofits
- What: Guided participation in conjecture testing, literature triage, and computational experiments, with clear provenance and moderation.
- Tools/products/workflows: Community workspaces, task shards with review bots, leaderboard of verified contributions.
- Assumptions/dependencies: Compute sponsorship, robust moderation and attribution mechanisms.
- New publication formats and review norms
- Sectors: Publishing, Academia
- What: Journals and archives that accept living working papers with machine-readable provenance, integrated code/tests, continuous review, and negative-result appendices.
- Tools/products/workflows: Artifact bundles as first-class submissions, rolling verification badges, versioned claim histories.
- Assumptions/dependencies: Community buy-in, incentives for sharing artifacts, indexing/archiving standards.
- High-stakes decision support with bounded-risk guarantees
- Sectors: Finance (risk/derivatives), Energy (grid ops), Healthcare (trial design)
- What: Decision memos that combine stochastic modeling, optimization, and partial formal guarantees; explicit uncertainty budgets and what-if analyses.
- Tools/products/workflows: “Decision workstreams” with reviewer agents, stress-test job farms, formal-constraint checks on policy choices.
- Assumptions/dependencies: Regulator acceptance, validated models/data, auditable compute traces, strong governance.
Cross-cutting assumptions and dependencies
- Human-in-the-loop remains essential for steering, interpretation, and accountability, especially where model reasoning is brittle.
- Cost and latency management for long-running agentic sessions; organizations need budgeting, quotas, and prioritization.
- Data governance: secure handling of manuscripts, code, and proprietary datasets; clear IP/authorship policies for AI-assisted work.
- Access to literature and tooling: reliable APIs, respect for licenses, and robust retrieval grounding to reduce hallucinations.
- Formal methods coverage and performance must advance to support broader domains and industrial acceptance.
- Cultural and policy shifts: recognition of negative results, acceptance of machine-readable artifacts in publication and regulation, and updated educational practices.
Glossary
- Agentic AI: AI systems designed to autonomously plan, coordinate tools or sub-agents, and carry out multi-step tasks. "efficient interactive collaboration between humans and agentic AI systems."
- Aletheia: An autonomous research system for mathematical reasoning and discovery. "breakthroughs like the autonomous research system Aletheia"
- AlphaEvolve: An evolutionary search system that discovers algorithms/structures via long-running, steerable optimization. "AlphaEvolve allows researchers to uncover novel algorithms and structures through continuous, steerable evolutionary runs."
- AlphaProof: A formal proving system that integrates reinforcement learning and LLMs to produce machine-verified proofs. "In the realm of formalized mathematics, AlphaProof"
- Aristotle: An interactive environment integrating reinforcement learning and LLMs with proof assistants. "interactive environments such as Aristotle"
- Boolean satisfiability (SAT): The problem of determining if there exists a truth assignment that satisfies a Boolean formula. "reduces the core of the question to a Boolean satisfiability (SAT) problem"
- Branch-and-bound: A combinatorial search method that prunes parts of the search space using bounds to improve efficiency. "The final branch-and-bound search is executed in a further workstream"
- DeepSearchQA: A benchmark focused on fact-finding and deep search capabilities relevant to research workflows. "Benchmarks such as DeepSearchQA"
- Fixed-point approach: A strategy using fixed-point theorems or invariants where a function maps a point to itself to establish existence/structure. "Try a fixed-point approach"
- Formal prover: Software that constructs or checks proofs in a formal logic system with machine verification. "the possibility of adding a formal prover such as AlphaProof"
- Formalized mathematics: Mathematics encoded in a formal language suitable for proof assistants, enabling machine verification. "In the realm of formalized mathematics"
- FrontierMath: A family of research-level mathematics benchmarks evaluating advanced problem-solving, including multi-day problems. "FrontierMath Tier 4"
- Gemini Deep Think: A long-reasoning variant of the Gemini model used as a sub-agent for deeper proofs and planning. "Used a Gemini Deep Think sub-agent to propose a new proof strategy"
- Hamiltonian diffeomorphism: A smooth, structure-preserving transformation arising in Hamiltonian mechanics/symplectic geometry. "Hamiltonian diffeomorphism with certain convenient properties"
- Hard2Verify: A benchmark targeting the detection of subtle mistakes in mathematics proofs. "Hard2Verify"
- IMO ProofBench: A benchmark built from International Mathematical Olympiad-style proofs to test theorem-proving ability. "IMO ProofBench"
- Inference-scaling models: Large models that achieve stronger capabilities primarily by scaling inference-time compute/steps. "the inference-scaling models currently powering commercial chat interfaces"
- Just finite presentation: A finite group presentation where removing any single relation yields an infinite group. "“just finite presentation,” i.e., a finite presentation where removing any relation results in an infinite group."
- Kourovka Notebook: A long-running compendium of open problems in group theory. "Problem 21.10 from the Kourovka Notebook"
- Log-concave: A sequence whose logarithm is concave, implying each term squared is at least the product of neighbors. "the coefficients are not only strictly positive but also form a log-concave sequence."
- Measurability: A property in measure theory ensuring sets/functions are compatible with a sigma-algebra, enabling integration/probability. "We must verify measurability on line 40"
- Proof assistant: Software (e.g., Lean, Coq) that helps construct and mechanically verify formal proofs. "open-source proof assistants."
- PySAT: A Python toolkit for SAT solving, providing interfaces to multiple SAT solvers. "which it solves using the PySAT library."
- Quasi-empirical: Describing methods that, while mathematical, rely on empirical-style exploration (experiments, simulations) to guide rigor. "deeply quasi-empirical reality"
- Representation theory: The study of abstract algebraic structures via their linear actions on vector spaces. "In a problem on representation theory"
- Stirling coefficients: Constants appearing in expansions related to Stirling numbers/factorials, here within representation-theoretic contexts. "the behavior of Stirling coefficients for symmetric power representations."
- Symmetric power representations: Representations obtained by applying the symmetric power functor to a given representation, amplifying features of the action. "symmetric power representations"
- Topological pruning heuristic: A domain-informed rule that cuts parts of a search space using topological properties to improve efficiency. "suggest a topological pruning heuristic"
Collections
Sign up for free to add this paper to one or more collections.