Semi-Autonomous Mathematics Discovery with Gemini: A Case Study on the Erdős Problems
Abstract: We present a case study in semi-autonomous mathematics discovery, using Gemini to systematically evaluate 700 conjectures labeled 'Open' in Bloom's Erdős Problems database. We employ a hybrid methodology: AI-driven natural language verification to narrow the search space, followed by human expert evaluation to gauge correctness and novelty. We address 13 problems that were marked 'Open' in the database: 5 through seemingly novel autonomous solutions, and 8 through identification of previous solutions in the existing literature. Our findings suggest that the 'Open' status of the problems was through obscurity rather than difficulty. We also identify and discuss issues arising in applying AI to math conjectures at scale, highlighting the difficulty of literature identification and the risk of ''subconscious plagiarism'' by AI. We reflect on the takeaways from AI-assisted efforts on the Erdős Problems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper tells the story of using an AI system to help solve and check famous math questions called Erdős problems. The team built a math “research agent” on top of Google’s Gemini called Aletheia. They asked it to look at hundreds of problems listed as “Open” (unsolved) on a public website and to propose solutions. Then human mathematicians carefully checked which AI answers were actually correct and actually new.
In short: the paper is a case study of how AI and people can work together to search for math discoveries—and what goes right and wrong along the way.
What questions the researchers asked
The team focused on simple, practical questions:
- Can an AI help scan a large list of “open” math problems and find real progress quickly?
- If the AI suggests answers, how many are truly correct and genuinely new?
- What are the biggest bottlenecks: making the AI reason correctly, or checking if an answer already exists in old papers?
- What problems show up when using AI at scale for math (like misreading a problem or unintentionally copying old work)?
How they did it (methods, in everyday terms)
Think of the process like searching for treasure on a big beach:
- AI as a metal detector:
- The AI agent (Aletheia) read 700 “Open” Erdős problems and tried to produce solutions.
- It also used a built-in “verifier” in plain language to judge whether its own answers might be right. This helped filter out obviously weak guesses so humans wouldn’t have to check everything.
- Human experts as the treasure inspectors:
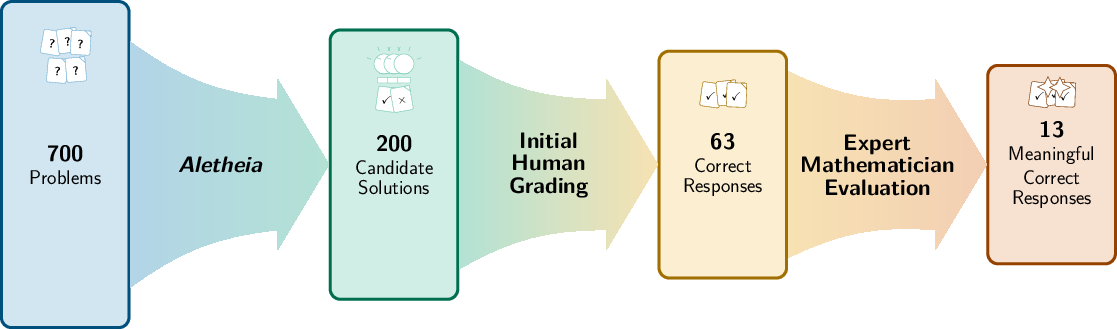
- Out of 700 problems, 212 AI answers looked promising.
- Human mathematicians reviewed these to remove wrong ones, ending with 27 top candidates.
- Domain experts then checked each carefully for two things: was the math correct, and was the result actually new (not already published)?
- Why not use only formal proof checkers (like Lean)?
- Very little of advanced math is written in those systems yet, so the AI would have too few tools.
- Many problem statements on the website were imperfect or ambiguous—humans had to interpret what the original mathematician likely meant.
Analogy: The AI is good at quickly finding “interesting lumps of metal,” but humans must still decide if a find is gold, a known coin, or just a bottle cap.
What they found (key results)
- Out of 700 “Open” problems:
- 212 AI responses looked possibly correct.
- After a first pass by humans: 27 remained.
- Careful expert checking found 63 technically correct solutions overall, but only 13 that truly solved the intended problems in a meaningful way.
- In percentages (for 200 clearly judged candidates): about 68.5% were flawed, 31.5% technically correct, and 6.5% meaningfully correct.
- Those 13 “meaningfully correct” split into four types:
- Autonomous Resolution: the AI produced what seems to be the first correct solution (2 problems).
- Partial AI Solution: the AI correctly solved part of a multi-part problem (3 problems).
- Independent Rediscovery: the AI found a correct solution that humans later found already existed in the literature (3 problems).
- Literature Identification: the AI discovered the problem was already solved in past papers, even though it was marked “Open” (5 problems).
- A surprising theme: many “Open” problems were actually already solved or poorly worded. Some were marked open mainly because the solution was hard to find in the literature, not because the problem was truly difficult.
- Another notable result: the AI solved one problem (Erdős-1051) in a way the authors think is a modest but genuine autonomous advance. This later led to a broader generalization in further work.
- Biggest bottleneck: checking if a solution was new. It took more time to search the old literature and compare ideas than to check the math itself. The team also worried about “subconscious plagiarism,” where the AI might re-create something it “saw” during training without citing it.
- Mismatch problems: around 50 AI solutions were technically correct for the literal wording but didn’t match what Erdős originally intended (for example, because of missing conditions or ambiguous definitions). These are mathematically pointless even if technically true.
Why this matters: The AI is good at quickly surfacing possible answers, but human care is essential to confirm correctness, intended meaning, and novelty.
Why it’s important (implications and impact)
- The good news:
- AI can help with “attention bottlenecks”—scanning many problems, suggesting ideas, and flagging promising cases faster than humans can.
- It can find “low-hanging fruit”: simple cases that experts might not have time to check.
- The caveats:
- A lot of AI answers are wrong, off-target, or not new. Human oversight remains crucial.
- Formal proof tools don’t fix the biggest issues here: vague problem statements, missing context, and checking for prior work.
- The risk of uncredited reuse (“subconscious plagiarism”) is real and needs careful handling.
- Social media hype can exaggerate the importance of routine or already-known results.
- The path forward:
- Improve problem databases with clear definitions and references.
- Build better AI tools to search and attribute prior work.
- Keep humans responsible for writing and crediting, so accountability and accuracy stay high.
- Be transparent about both successes and failures to avoid misleading claims.
Bottom line
This paper shows that AI can be a helpful teammate in math research, especially for triaging lots of problems. It can spotlight ideas worth a human’s time. But it doesn’t replace careful human judgment. The biggest wins came not from “superhuman flashes of genius,” but from speeding up search and filtering—while the biggest headaches were checking the literature and making sure the problems were interpreted correctly. With better tools and careful collaboration, the balance could keep improving.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper surfaces several unresolved issues in methodology, evaluation, and broader practice. The following concrete gaps could guide future research:
- Verification performance and calibration:
- Lack of precision/recall, false-positive/false-negative rates, and calibration curves for the natural-language verifier on a labeled proof dataset.
- No robustness evaluation against persuasive-but-incorrect proofs or adversarial inputs.
- Pipeline transparency and reproducibility:
- Missing operational details of Aletheia (prompt templates, verifier architecture, thresholds, sampling strategy, temperatures, number of retries, stopping criteria, compute budget).
- No ablation studies comparing variants (with/without verifier, different LLMs/verifiers, retrieval on/off, sampling budgets).
- Human-in-the-loop evaluation:
- Unquantified person-hours at each stage, throughput, and triage efficiency; no cost–benefit analysis.
- No inter-rater agreement metrics, screening guidelines, or bias audits for non-expert vs expert graders.
- Potential false negatives from early non-expert filtering not assessed.
- Literature identification and attribution:
- Absence of a systematic, automated literature-search pipeline (semantic search, citation graph mining, cross-lingual retrieval) with measurable recall/precision.
- No plagiarism/attribution audit tooling for detecting idea-level overlap between outputs and prior literature (“subconscious plagiarism”) or training-data leakage.
- Training-data provenance and leakage:
- No audit indicating whether Bloom’s database or relevant literature was present in model pretraining; lack of contamination assessment and its impact on claimed autonomy/novelty.
- Definition and measurement of novelty and autonomy:
- Ambiguous criteria for “autonomous resolution” and “meaningfully correct”; no standardized, auditable rubric for categorizing outputs.
- No quantitative “novelty score” (e.g., proof similarity metrics to known literature, dependency depth on prior theorems).
- Problem-statement ambiguity:
- No standardized, machine-readable ontology for Bloom’s conventions (e.g., additive vs Dirichlet convolution) to prevent misinterpretation.
- Missing pre-solve validation tools to flag ill-posed, ambiguous, or mistranscribed problems before solution attempts.
- Benchmarking and datasets:
- No public benchmark release of the 700 problems annotated with intended statements, literature status, and adjudicated labels (flawed, technically correct, meaningfully correct).
- The 137 flawed and 50 technically-correct-but-meaningless cases are not shared as a failure-analysis dataset for community improvement.
- Failure-mode taxonomy:
- Lack of a detailed taxonomy and counts of error types (logical gaps, definitional confusion, misuse of literature, trivialization via misinterpretation), with targeted mitigation strategies.
- Formal verification integration:
- No concrete hybrid pipeline that maps natural-language arguments to formal proof sketches (e.g., Lean) to check local steps or key lemmas; no coverage statistics for what can be formalized.
- No study of how formalization can help disambiguate intended statements vs literal transcriptions at scale.
- Generalizability and domain coverage:
- No per-domain breakdown of outcomes (e.g., combinatorics vs number theory vs geometry) to identify where the approach succeeds or fails.
- No evaluation on other curated conjecture lists to test transferability beyond Bloom’s Erdős problems.
- Comparative baselines:
- Limited, anecdotal comparison to other systems; no controlled head-to-head evaluation across models/verifiers under identical conditions.
- Provenance and release:
- Proprietary model and incomplete release of logs/prompts hinder independent replication; no model card with limitations, known failure modes, and training data summary.
- Literature gaps in solved cases:
- For “autonomous” and “independent rediscovery” instances, no rigorous, documented literature sweep protocol (including non-English sources and preprints) to strengthen novelty claims.
- Social and ethical protocols:
- No formal guidelines for credit/attribution when AI outputs overlap with prior work; no community process for adjudicating disputes.
- No communication protocol to mitigate social-media misinformation/hype around preliminary AI claims.
- Metrics of mathematical significance:
- Absence of standardized measures to evaluate the research value of solved problems (e.g., downstream citations, generalizations enabled, inclusion in active research lines).
- Prevention of citation inaccuracies:
- Errors in cited constants/theorems (e.g., in 652) expose a gap in automated citation verification and consistency checking against source texts.
- Scope of formalization success:
- Only one solution (1051) was formalized; no data on the resources and success rate to formalize others, or on the practical barriers encountered.
- Selection biases:
- The verifier-driven pruning may introduce selection bias; no analysis of how this shapes which problems are examined or “solved.”
- Active collaboration strategies:
- No algorithms or policies for routing candidate solutions to the right domain experts, prioritizing by impact/likelihood, or optimizing human–AI collaboration time.
- Longitudinal impact:
- No tracking of whether AI-driven resolutions lead to new theorems, generalizations, or shifts in research agendas over time.
- Legal/compliance considerations:
- Unaddressed legal risks around reproduction of training data in outputs and the boundaries of fair use in mathematical text/ideas.
- Cross-lingual literature coverage:
- No strategy to systematically include non-English or less-indexed sources, risking missed prior art.
- Verifier adversarial testing:
- No stress-testing of the verifier with crafted deceptive proofs or stylistic variants to quantify brittleness.
- Transparency of human editing:
- Human rewriting of proofs may alter substance; no released, versioned diffs linking raw outputs to edited text to enable independent auditing.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed or piloted today, derived from the paper’s semi-autonomous discovery workflow (LLM generation, natural-language verification, human triage, literature cross-check, and attribution scrutiny).
- AI-assisted literature reconciliation for “open problem” databases
- Sectors: academia, publishing, software (knowledge management)
- What: An agent that flags “open” entries likely already resolved by scanning literature and community wikis, and suggests canonical references.
- Tools/workflows: arXiv/CrossRef/MathSciNet/zbMATH APIs; citation graph search; semantic retrieval over proofs/lemmas.
- Assumptions/dependencies: Access to full text; reliable metadata; careful handling of paywalled content; expert adjudication for borderline matches.
- Natural-language verifier to down-select candidate solutions for expert review
- Sectors: academia, software (QA), finance (policy/rule compliance), legal (case law search)
- What: Use LLM-based verifiers to score/cluster model-generated solutions, reducing the expert review burden by focusing on high-confidence candidates.
- Tools/workflows: verifier prompts calibrated on historical solutions; disagreement-based ensembles; review queues with rationale traces.
- Assumptions/dependencies: Calibrated confidence; clear rubrics; audit trails; reviewers available to resolve edge cases.
- Ambiguity and convention checker for problem statements
- Sectors: academia, education, publishing
- What: Automatic detection of definitional ambiguities (e.g., additive vs Dirichlet convolution) and missing hypotheses; suggests standard conventions and fixes.
- Tools/workflows: glossary/ontology of domain conventions; promptable “definition disambiguator”; issue tickets to maintainers.
- Assumptions/dependencies: Curated domain ontologies; maintainers to accept/merge fixes; community norms for canonical definitions.
- Provenance and “subconscious plagiarism” auditor for AI-generated proofs
- Sectors: academia, publishing, policy
- What: Compare AI outputs against pretraining-era literature using embeddings and citation graphs to surface likely uncredited reproductions.
- Tools/workflows: similarity search over proof corpora; timeline filters (pre/post training cutoff); structured attribution checklists in submissions.
- Assumptions/dependencies: Access to training data coverage summaries or proxies; legal/policy frameworks for attribution; acceptable false-positive rates.
- Reviewer triage dashboards for editors and problem curators
- Sectors: publishing, academia
- What: Rank submissions/candidates by novelty likelihood, literature overlap, and clarity of statement; route to appropriate experts.
- Tools/workflows: novelty scores; overlap heatmaps; automated “needs human confirmation” labels; reviewer assignment assistants.
- Assumptions/dependencies: Integration with submission systems; transparent criteria; expert availability.
- Lightweight “meaningfully correct” vs “technically correct” evaluation protocols
- Sectors: academia, education
- What: Adopt the paper’s taxonomy to label outputs (flawed, technically correct, meaningfully correct), preventing hype and clarifying impact.
- Tools/workflows: standardized review forms; inter-rater reliability checks; public dashboards for transparency.
- Assumptions/dependencies: Community buy-in; training for reviewers; consistent definitions across domains.
- Community wiki and errata integration for problem repositories
- Sectors: academia, education
- What: Continuous synchronization between problem databases and community annotations (errata, literature links, clarified statements).
- Tools/workflows: bots that watch for new references; PR-based updates; provenance logs linking fixes to discussions.
- Assumptions/dependencies: Moderation; contributor engagement; platform APIs.
- Courseware and coaching for proof critique and literature search
- Sectors: education
- What: Tutor modules that teach students to spot hidden assumptions, mismatched conventions, and prior literature.
- Tools/workflows: interactive exercises with instant feedback; curated example bank from mis-specified problems.
- Assumptions/dependencies: Alignment with curricula; safe model behavior; educators to review content.
- Internal R&D “attention bottleneck” reducers
- Sectors: software, biotech/healthcare R&D, energy, finance
- What: Apply the same pipeline to internal “open questions” or bug/issue trackers to surface low-hanging fruit and known fixes.
- Tools/workflows: semantic de-duplication; literature/patent prior-art linking; risk flags for re-discovery vs novelty.
- Assumptions/dependencies: Clean internal knowledge bases; IP policies; confidentiality-preserving retrieval.
- Prior-art search augmentation for patent drafting and review
- Sectors: legal/IP, industry R&D
- What: Detect likely prior art and near-duplicates early, reducing filing risk and rework.
- Tools/workflows: semantic prior-art search; drafting assistants that auto-cite closest art; novelty risk scoring.
- Assumptions/dependencies: Patent corpus licensing; responsibility and liability frameworks; human attorney oversight.
- Editorial disclosure and accountability templates for AI use
- Sectors: academia, publishing, policy
- What: Standard submission sections for AI contributions, raw logs, and literature checks to ensure accountability.
- Tools/workflows: AI-use checklists; attached reasoning traces; repository links for raw outputs.
- Assumptions/dependencies: Journal policies; storage and privacy norms; researcher compliance.
- Benchmarks for scientific “acceleration” with costs included
- Sectors: AI research, policy
- What: Evaluate throughput and error costs (false positives, expert-time drains), using the paper’s transparent accounting as a template.
- Tools/workflows: time-to-verify metrics; cost-of-correction estimates; standardized reporting of negative cases.
- Assumptions/dependencies: Community willingness to report negatives; reproducible logs; funding for evaluation.
- Competition and olympiad training assistants with guardrails
- Sectors: education, daily life
- What: Tools that check student solutions for misinterpreted statements, cite related known problems, and scaffold corrections.
- Tools/workflows: step-by-step critique; “closest known problem” linking (e.g., CMO/IMO TST); style rewrites for clarity.
- Assumptions/dependencies: Exam integrity policies; opt-in teacher supervision; content filtering.
Long-Term Applications
These require advances in reliability, scaling, formalization coverage, or policy standardization.
- Integrated natural-language + formal verification proof stack
- Sectors: academia, software verification
- What: Seamless pipeline translating natural-language drafts into formal proofs (Lean, Isabelle) while preserving intended meaning.
- Tools/workflows: semantic alignment models; proof-synthesis with definitional convention adapters; intent-checkers.
- Assumptions/dependencies: Much wider formal library coverage; robust disambiguation; compute and training data.
- Universal mathematical ontology and machine-readable literature
- Sectors: academia, publishing, software
- What: A shared, versioned ontology of definitions/notations linked to machine-readable theorems, enabling precise retrieval and disambiguation.
- Tools/workflows: publisher mandates for structured math markup; living glossaries; version control for definitions.
- Assumptions/dependencies: Publisher cooperation; standards bodies; tooling for authoring and conversion.
- Cross-domain discovery engines for science and engineering
- Sectors: healthcare, energy, materials, biotech, robotics
- What: Extend the triage+verification+literature-identification loop to experimental hypotheses, protocols, and simulations.
- Tools/workflows: structured experiment ontologies; lab notebook ingestion; simulator-in-the-loop verification.
- Assumptions/dependencies: High-quality datasets; causal modeling; safety/ethics frameworks for suggestions.
- Novelty and attribution detectors embedded in peer review
- Sectors: publishing, policy
- What: Routine novelty screens that consider embeddings over literature, pretraining corpora, and preprints to deter redundant publications.
- Tools/workflows: rolling-window novelty indexes; temporal filters; author-facing “attribution suggestions.”
- Assumptions/dependencies: Access to broad corpora; privacy-respecting training data provenance; community norms.
- Trustworthy AI research agents with auditable reasoning
- Sectors: academia, policy, software
- What: Agents that maintain verifiable chains-of-thought, cite sources, and provide uncertainty and risk-of-plagiarism estimates.
- Tools/workflows: cryptographic logs; structured citations; counterexample searchers; red-team protocols.
- Assumptions/dependencies: Acceptable exposure of reasoning traces; secure logging; regulatory guidance.
- Automated problem curation and statement repair at scale
- Sectors: academia, education
- What: Periodic sweeps across large repositories to detect ill-posed problems, conflicting conventions, and trivializations; propose fixes.
- Tools/workflows: anomaly detection in solution difficulty; symbolic counterexample generators; human-in-the-loop approvals.
- Assumptions/dependencies: Stewards for acceptance; community governance; robust false-positive controls.
- Funding and policy triage for “low-hanging fruit” programs
- Sectors: policy, funding agencies
- What: AI identifies tractable problems whose solution would unblock larger agendas; supports portfolio design.
- Tools/workflows: tractability scores; dependency graphs; cost-benefit simulations.
- Assumptions/dependencies: Transparent criteria; avoidance of bias toward “easy” but low-impact questions; expert panels.
- Sector-specific compliance and standards verification
- Sectors: healthcare, energy, finance, aerospace
- What: Map design specs or clinical protocols to standards; detect missing conditions analogous to missing hypotheses in math.
- Tools/workflows: standards ontologies; requirements traceability; discrepancy explainers.
- Assumptions/dependencies: Access to standards; liability frameworks; domain tuning.
- Proof provenance and licensing registries
- Sectors: academia, publishing, legal
- What: Registries that timestamp AI/human contributions, track licensing of proof fragments, and enforce attribution.
- Tools/workflows: DOIs for proof objects; contributor manifests; license checks for reused lemmas.
- Assumptions/dependencies: Community adoption; metadata interoperability; legal recognition.
- AI-driven editorial workflows for dynamic literature maintenance
- Sectors: publishing
- What: Living review articles auto-updated with new results, retractions, or refinements; editors validate and release updates.
- Tools/workflows: change-detection pipelines; editor-in-the-loop curation; provenance diffing.
- Assumptions/dependencies: Sustainable funding; publisher tooling; versioning norms.
- Multimodal “spec-to-proof” systems for engineering
- Sectors: robotics, software, hardware design
- What: Translate natural-language specs and diagrams into verifiable properties and proof obligations, catching spec ambiguities early.
- Tools/workflows: spec parsers; property synthesis; counterexample-guided refinement.
- Assumptions/dependencies: Standardized spec formats; formal models of components; integration with CAD/EDA toolchains.
- Education at scale: personalized proof-writing and literature skills
- Sectors: education, daily life
- What: Long-horizon programs that build students’ ability to navigate conventions, cite prior work, and distinguish “meaningful” from “technical” correctness.
- Tools/workflows: adaptive curricula; rubric-aligned feedback; community practice with attribution norms.
- Assumptions/dependencies: Teacher training; equitable access; rigorous evaluation of learning gains.
- Risk and misinformation monitoring for AI-generated science
- Sectors: policy, media, academia
- What: Systems that detect and correct overhyped claims (e.g., “AI solved X”) by cross-checking literature and expert validation status.
- Tools/workflows: claim-tracking knowledge graphs; status badges (unverified/replicated/published); media toolkits.
- Assumptions/dependencies: Partnerships with platforms; responsible comms guidelines; expert networks.
These applications leverage the paper’s key insights: AI can reduce attention bottlenecks but needs calibrated verifiers, clear conventions, rigorous attribution, and human expertise. Real-world impact hinges on high-quality literature access, strong ontologies, transparent audit trails, and policies that align incentives for correctness and credit.
Glossary
- Aletheia: A specialized math research agent built on Gemini Deep Think that autonomously explores and verifies mathematical problems. "Aletheia: a specialized math research agent."
- Autonomous Resolution: A results category indicating an AI-produced solution without human derivation or literature sourcing. "Autonomous Resolution."
- Bloom's Erdős Problems database: A centralized repository cataloging Erdős’s conjectures and their status. "to systematically evaluate 700 conjectures labeled `Open' in Bloom's Erd\H{o}s Problems database."
- Dirichlet convolution: An arithmetic operation on functions over the integers defined via sums over divisors; used here in contrast with additive convolution. "e.g.,~additive versus Dirichlet convolution, strong versus weak completeness, etc."
- Formal verification: The use of proof assistants and formal systems to mechanically verify the correctness of mathematical proofs. "An alternative approach to the evaluation problem is via formal verification, such as through the Lean language."
- Fundamental Theorem of Arithmetic: The result that every integer greater than 1 factors uniquely into primes up to ordering. "By the Fundamental Theorem of Arithmetic, a power of 3 equals a power of 2 if and only if both exponents are zero."
- Incidence: In combinatorial geometry, a point–curve (or point–object) pair where the point lies on the object. "An incidence is a pair with and ."
- Lean 4: The fourth major version of the Lean proof assistant used for formalizing mathematical proofs. "The solution has been formalised in Lean 4 by Barreto,"
- liminf: The limit inferior; the greatest lower bound of the set of subsequential limits of a sequence. "satisfying ."
- limsup: The limit superior; the least upper bound of the set of subsequential limits of a sequence. "If then isinfinite?"
- Mahler's criterion: A classical criterion related to rationality/transcendence via properties of power series or related approximations. "moving to the series tail and applying Mahler's criterion."
- Natural language verifiers: AI components that assess the plausibility or correctness of proofs stated in natural language. "we therefore used AI-based natural language verifiers to narrow the search space"
- Pach–Sharir theorem: An incidence bound controlling the number of point–curve incidences under certain intersection constraints. "Theorem (Pach--Sharir \cite[Theorem 1.1]{PS98})"
- Power of a Point Theorem: A Euclidean geometry theorem relating products of segment lengths from a point to intersections with a circle. "By the Power of a Point Theorem, the product of the signed lengths of the segments from the intersection point must be equal."
- Powerful part: For an integer n, the product of prime powers pk with k≥2 in its factorization; here denoted Q₂(n). "let be the powerful part of "
- Simple curves: Curves in the plane without self-intersections, used as objects in incidence bounds. "Let be a set of simple curves in the plane"
- Subconscious plagiarism: The phenomenon where an AI reproduces content learned during training without explicit attribution. "susceptible to ``subconscious plagiarism'' by AI."
- Telescoping sum: A series where consecutive terms cancel extensively, simplifying to a small number of terms. "gives a telescoping sum"
Collections
Sign up for free to add this paper to one or more collections.