- The paper demonstrates that leveraging a spike-and-flat eigenvalue structure enables low-rank, efficient preconditioning in LLM training.
- The algorithm decomposes the update into a subspace using two-sided KL preconditioning and a complement with orthogonalized one-sided normalization, reducing memory and compute costs.
- Empirical tests on GPT-2 and LLaMA, along with theoretical guarantees, show improved convergence, lower validation loss, and significant GPU memory savings.
Pro-KLShampoo: Projected KL-Shampoo with Whitening Recovered by Orthogonalization
Structural Motivation and Derivation
The paper "Pro-KLShampoo: Projected KL-Shampoo with Whitening Recovered by Orthogonalization" (2605.06316) introduces a principled approach to reduce memory and compute overhead for Kronecker-factored optimizers in LLM pre-training. The authors make a key empirical observation: the eigenvalue spectra of KL-Shampoo's Kronecker preconditioners exhibit a robust spike-and-flat pattern—a small number of dominant eigenvalues followed by a flat tail—across all layers and training stages.
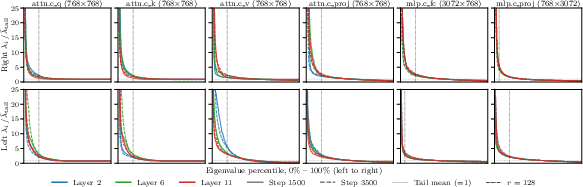
Figure 1: Consistent spike-and-flat structure in the eigenvalue spectra of KL-Shampoo's Kronecker preconditioners on GPT-2 across layers and training stages, with r=128 marking the subspace/tail boundary.
This structure is shown to be exact under a rank-ρ signal-plus-noise gradient model, suggesting the bulk of the covariance is well-captured by a low-rank spectral subspace plus a uniform tail. Leveraging this, Pro-KLShampoo restricts the right-side Kronecker factor of the preconditioner (typically the larger or more expensive side in transformer layers) to a parametric form—full spectral structure on a tracked r-dimensional subspace, and a single shared scalar on the complement.
The optimality of this restriction is quantified: when the spike-and-flat structure holds, the approximation gap vanishes; otherwise, it scales with the arithmetic-geometric mean ratio of the tail eigenvalues. Crucially, the method replaces the scalar tail with orthogonalization (polar factor) on the complement, which algebraically recovers per-direction whitening and matches the full KL-Shampoo’s complement form.
Algorithmic Construction
Pro-KLShampoo decomposes the KL-Shampoo update into two distinct components:
- Subspace update: Full two-sided KL-based preconditioning in the top-r eigenspace, combining the tracked U∈St(n,r) and the subspace factor S∈Sr.
- Complement update: Orthogonalized one-sided preconditioning via the polar factor (with calibrated scaling), applied to the complement directions.
The stationarity conditions for the restricted KL objective yield coupled updates for L, S, and μ⊥:
S∗=m1E[G⊤(L∗)−1G],μ⊥∗=m(n−r)1Tr(E[G⊥⊤(L∗)−1G⊥]),L∗=n1E[GR^−1G⊤]
Orthogonalization is rigorously shown to recover full KL-Shampoo's algebraic whitening on the complement, replacing the loss of information from the scalar tail with per-direction normalization, and the mixing weight ρ0 is calibrated to preserve the operator-norm scale between components.
Empirical Evaluation
Experiments are performed on GPT-2 (124M/350M, FineWeb-10B) and LLaMA (134M/450M, C4), comparing Pro-KLShampoo against AdamW, Muon, KL-Shampoo, and COSMOS. Across all tested ranks (ρ1), and for all configurations, Pro-KLShampoo consistently attains lower validation loss, reduced peak per-GPU memory, and improved wallclock efficiency in reaching matched loss levels.
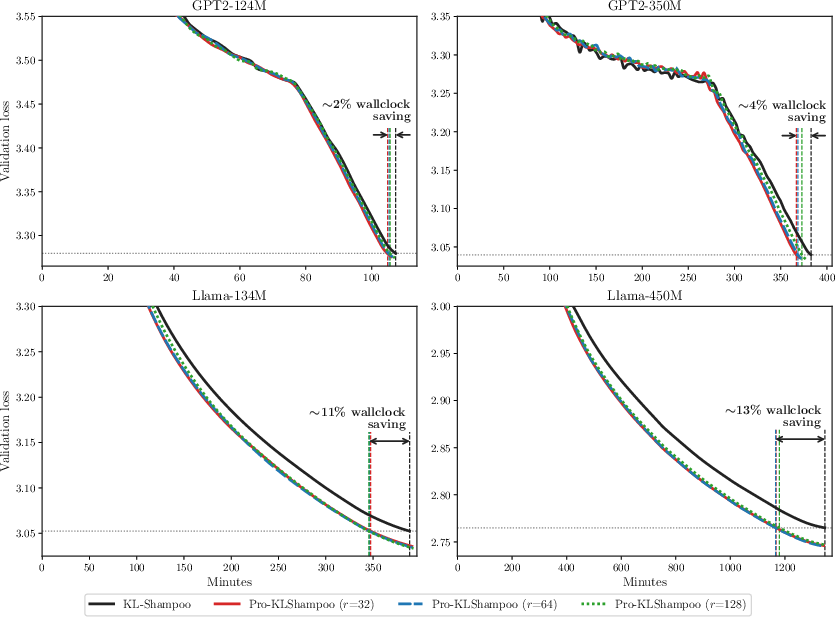
Figure 2: Pro-KLShampoo attains faster convergence and lower validation loss than KL-Shampoo at all tested subspace ranks for both GPT-2 and LLaMA scales.
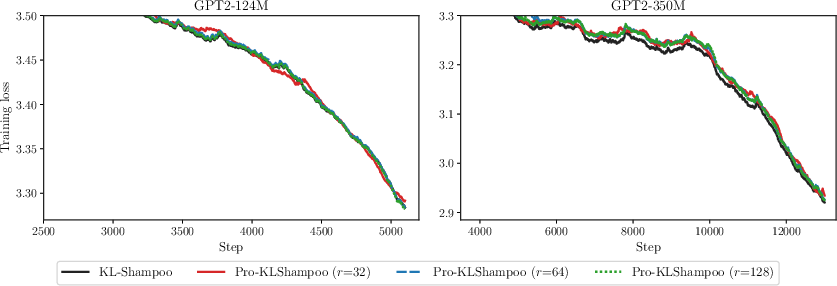
Figure 3: Training loss versus steps for KL-Shampoo and Pro-KLShampoo, showing equivalent or improved convergence, especially for LLaMA models.
At lower ranks (ρ2), where the tracked subspace does not fully capture dominant spectral structure, Pro-KLShampoo's orthogonalization on the complement preserves robustness, maintaining improvement over KL-Shampoo. For GPT-2, wallclock savings derive mainly from reduced per-step computational cost (QR on ρ3 vs ρ4), while for LLaMA, improved convergence is the primary source. Ablation studies confirm that both spike-and-flat decomposition and orthogonalization are necessary; neither subspace-only nor complement-only variants achieve comparable results.
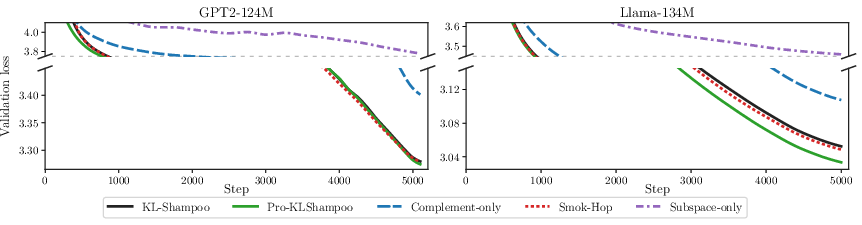
Figure 4: Ablation of Pro-KLShampoo components highlights that full spike-and-flat plus orthogonalization is required for optimal performance.
Theoretical Guarantees
An ρ5 nonconvex convergence guarantee is established for the idealized algorithm under operator-norm smoothness, with the stationarity measure reflecting the split update geometry: nuclear norm for the orthogonalized complement and squared Frobenius norm for the subspace. The analysis covers state-dependent mixing weights (ρ6), preconditioner spectral bounds, and stochastic assumptions, and confirms that the mixed-norm stationarity vanishes only at critical points.
Memory and Computational Cost
Pro-KLShampoo's right-side storage drops from ρ7 to ρ8, and its QR cost shrinks from ρ9 to r0, making it particularly advantageous for layers with large r1. This translates to measurable peak GPU memory reductions across all architectures and scales.
Relation to Prior Art and Practical Implications
Pro-KLShampoo draws structural and algorithmic connections between KL-based Kronecker-factored estimators and spectral-norm orthogonalization (Muon-style). It provides a KL-pure formulation for subspace preconditioning and clarifies the geometric interplay between two prominent matrix-structure-exploiting optimizer paradigms. Empirically, it outperforms not only KL-Shampoo but also Muon and COSMOS at matched rank, establishing stronger generalization and efficiency.
The practical implementation incorporates Nesterov momentum, eigenvalue clipping, and Newton–Schulz approximation for orthogonalization. Memory and compute reductions are achieved with minimal compromise in convergence, making Pro-KLShampoo a strong candidate for scalable LLM training.
Future Directions
Open directions include per-layer or online calibration of the mixing weight, deeper convergence/stability analysis for EMA-based subspace tracking and preconditioner estimation, and extension of theoretical guarantees to the practical variant. The interplay between orthogonalization and adaptive preconditioning remains an active area for optimizing memory and compute, especially as model sizes and training scales continue to grow.
Conclusion
Pro-KLShampoo systematically exploits the empirically robust spike-and-flat structure of Kronecker preconditioners, combining KL-divergence minimization in a projected subspace with Muon-style orthogonalization on the complement. Through both theoretical analysis and empirical validation, the method achieves improved validation loss, reduced wallclock, and efficient memory/cost profiles across multiple LLM architectures and scales. The work clarifies the structural synergy between Kronecker-based and orthogonalization-based optimizers and points toward more principled, scalable second-order methods for deep learning.

