Clarifying Shampoo: Adapting Spectral Descent to Stochasticity and the Parameter Trajectory
Abstract: Optimizers leveraging the matrix structure in neural networks, such as Shampoo and Muon, are more data-efficient than element-wise algorithms like Adam and Signum. While in specific settings, Shampoo and Muon reduce to spectral descent analogous to how Adam and Signum reduce to sign descent, their general relationship and relative data efficiency under controlled settings remain unclear. Through extensive experiments on LLMs, we demonstrate that Shampoo achieves higher token efficiency than Muon, mirroring Adam's advantage over Signum. We show that Shampoo's update applied to weight matrices can be decomposed into an adapted Muon update. Consistent with this, Shampoo's benefits can be exclusively attributed to its application to weight matrices, challenging interpretations agnostic to parameter shapes. This admits a new perspective that also avoids shortcomings of related interpretations based on variance adaptation and whitening: rather than enforcing semi-orthogonality as in spectral descent, Shampoo's updates are time-averaged semi-orthogonal in expectation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of “Clarifying Shampoo: Adapting Spectral Descent to Stochasticity and the Parameter Trajectory”
Overview: What is this paper about?
This paper compares two kinds of training “optimizers” (the rules that decide how a neural network updates its weights to get better):
- Adam and Signum, which look at each number (element) in the weights separately.
- Shampoo and Muon, which look at whole weight matrices (tables of numbers) at once.
The authors show that Shampoo is to Muon what Adam is to Signum: the more “adaptive” method (Shampoo/Adam) tends to be more data-efficient than the simpler one (Muon/Signum). They also explain why this happens and where Shampoo’s benefits really come from.
“Token efficiency” here means how well a LLM learns (measured by lower perplexity Parsons speak: lower is sigma-algebra meaning “model is less confused”) for a fixed amount residually of training data (tokens).
What questions were the researchers asking?
- Are Shampoo and BOS Mu perfec similar to Adam and Signum—meaning the adaptive method (Shampoo/Adam) is usually better than the non-adaptive one (Muon/Signum)?
- Is Shampoo more token-efficient than Muon when you control for confounding factors (like step size tricks or numerical approximations)?
- Where do Shampoo’s benefits come from? Do they mostly appear when applied to weight matrices (the big 2D tables in linear layers), or do they help everywhere?
- Is using two-sided matrix adjustments (left and right) better than one-sided adjustments?
- Can we explain Shampoo’s advantage better than by just saying “it adapts to noise” or “it whitens the gradient”?
How did they study it? (Methods in plain language)
- They trained LLMs (Llama-style) on a large text dataset and compared many optimizers under the same rules.
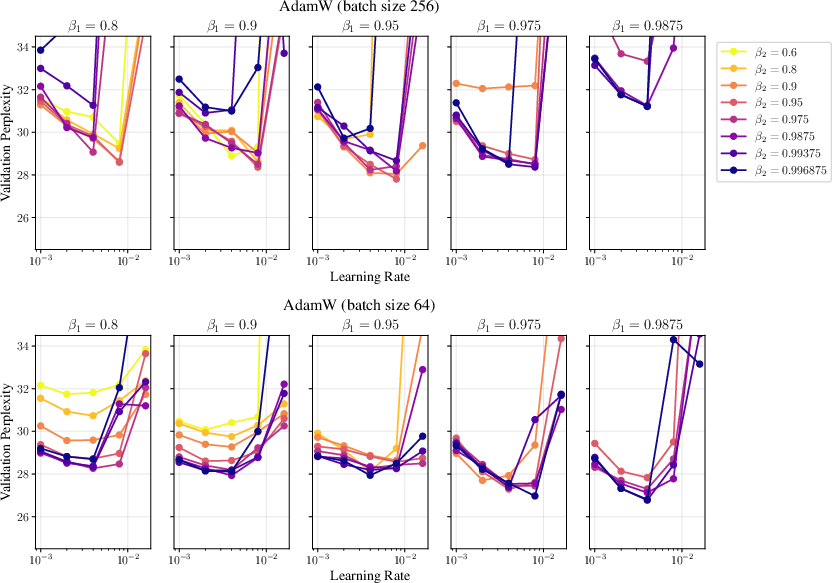
- They carefully tuned hyperparameters (like learning rates and moving-average factors) and tested different batch sizes and model sizes.
- They used “grafting”: this means they let Shampoo/Muon borrow the overall step size from Adam so differences come from the shape/structure part, not from step-size scaling tricks.
- They also ran controlled tests:
- Swapped ways of computing Muon’s core operation (using exact SVD vs. an approximation called Newton–Schulz).
- Tuned a small numerical constant (epsilon) that matters for matrix stability.
- Applied Shampoo to different parameter types (2D weight matrices vs. 1D vectors, embeddings, and convolution kernels) to see where it helps most.
- Tested one-sided vs. two-sided matrix adjustments to see which works best.
- Ran “full-batch” experiments (no minibatch noise) to see if benefits remain when the gradient isn’t noisy.
Key idea explained simply:
- Element-wise vs. matrix-wise: Adam and Signum treat each weight number separately, like fixing each pixel one by one. Shampoo and Muon treat the whole weight matrix together, like straightening a wrinkled sheet by pushing from the left and right at the same time.
- “Left” and “right” adaptation: Think of holding a book with two hands—one hand adjusts rows, the other adjusts columns. This two-handed adjustment can steer updates more precisely.
- “Spectral descent” (what Muon tries to imitate): Follow the main directions of the slope on a hill, not just straight down per number. It moves in the direction that respects the overall shape of the matrix.
- “EMA” (exponential moving average): A way of remembering a smooth average of the past, like a memory that favors recent steps but still keeps older ones in mind.
What did they discover, and why does it matter?
Here are the most important findings:
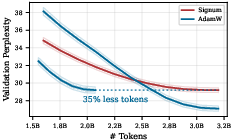
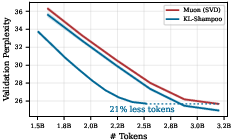
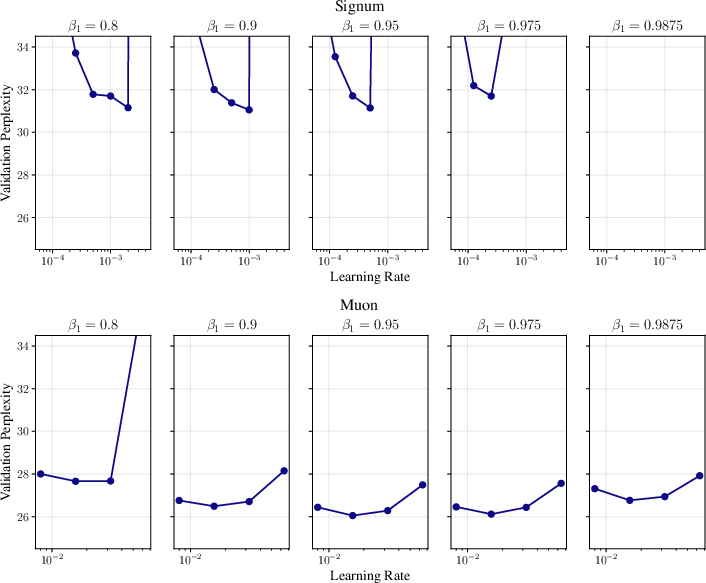
- Shampoo beats Muon in token efficiency, much like Adam beats Signum.
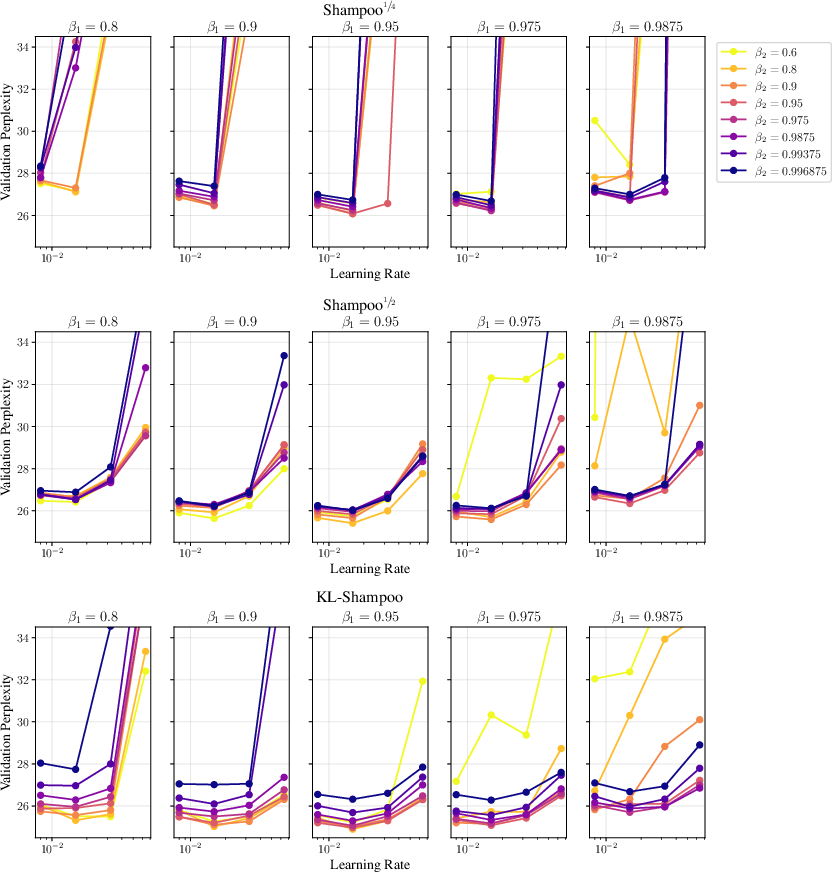
- Across different settings, Shampoo (especially some versions like KL‑Shampoo and Shampoo with p=1/2) matched or outperformed Muon.
- Matrix-aware optimizers (Shampoo/Muon) often beat AdamW when run fairly.
- The advantage comes from the “adaptation” part.
- The authors show you can think of Shampoo as “Muon in the middle,” with extra left/right adjustments before and after. These adjustments are what give Shampoo the edge—just like Adam’s scaling gives it an edge over Signum.
- Shampoo helps most on weight matrices in linear layers.
- Applying Shampoo to 1D parameters (vectors), embeddings, or certain convolution kernels either didn’t help or made things worse.
- Reshaping tensors into 2D matrices and applying Shampoo there gave the best gains.
- This challenges the idea that Shampoo is a general replacement for “full-matrix Adam”; instead, its power is specific to matrix-shaped parameters.
- Two-sided is better than one-sided.
- Using both left and right adjustments usually outperformed using only one side.
- One-sided versions couldn’t match full Shampoo.
- Results depend on careful setup.
- Tuning epsilon and using the same step-size grafting mattered a lot.
- Muon’s common “layer-wise scaling” rules didn’t beat the grafted setup used here.
- Matrix methods may prefer larger batch sizes than element-wise methods.
- As models get bigger or see more data, the gap shrinks—but the ranking stays similar.
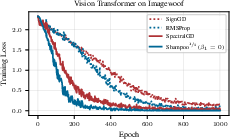
- Adaptation is not just about noise.
- Even without minibatch noise (full-batch), adaptive methods (RMSProp/Shampoo) still beat non-adaptive ones (SignGD/SpectralGD).
- This suggests the optimizer benefits from “adapting to the path the parameters take over time,” not just from smoothing out randomness.
Why this matters:
- If you train LLMs and can afford matrix-aware methods, Shampoo (two-sided, on weight matrices, with grafting) is a strong default.
- Don’t assume “Shampoo is a general full-matrix Adam.” Its biggest wins are for 2D weight matrices, not everywhere.
- If you use Muon, know that its scaling choices and numerical details can affect results; with careful control, Shampoo tends to come out ahead.
A simpler way to think about Shampoo’s “why”
Many past explanations said Shampoo works because it:
- adapts to variance (noise), or
- “whitens” the gradient (makes directions equally noisy).
The authors propose a clearer picture: Shampoo tries to keep the updates “well-shaped” over time and across randomness—like encouraging the update directions to stay roughly at right angles (orthogonal) on average when you look across many steps and samples. They call this “time-averaged semi‑orthogonality in expectation.” In plain terms: Shampoo nudges updates so they don’t get stretched weirdly in one direction, not just at a single step, but on average over the whole training path and the noise in the data.
This perspective:
- connects Muon (which pushes toward “spectral” directions) with Shampoo (which adds adaptive shaping on both sides),
- explains why two-sided adaptation helps,
- and fits the experimental results better than only saying “variance adaptation” or “whitening.”
Takeaways and potential impact
- Practical guidance:
- For LLMs, consider Shampoo (two-sided) applied to weight matrices, plus grafting from Adam for step-size magnitude.
- Skip applying Shampoo to embeddings and 1D parameters; it may hurt.
- Tune epsilon carefully; small numerical details matter.
- Expect matrix methods to like somewhat larger batch sizes than element-wise methods.
- Bigger picture:
- The paper clarifies that Shampoo’s strength comes from how it adapts to both the noisy data and the changing path of the model’s weights—over time—in a matrix-aware way.
- This helps researchers design better, more efficient optimizers and rethink old interpretations that treated Shampoo as a one-size-fits-all version of full-matrix Adam.
In short: Shampoo is like Muon with smart, two-handed adjustments that account for noise and the training path. That extra adaptiveness, applied where it matters most (weight matrices), makes it learn more efficiently from the same amount of data.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is framed to guide future research.
- Formal conditions and proofs that the Shampoo decomposition (Muon plus left/right adaptations) holds under practical settings with EMA momentum, grafting, damping ε, and stale/blocked preconditioners; provide bounds quantifying divergence from the idealized decomposition.
- Empirical and theoretical validation that training with Shampoo/Muon achieves “time-averaged semi-orthogonality in expectation” as defined; develop measurable diagnostics, prove sufficient conditions, and relate this property to convergence speed and generalization.
- Convergence guarantees for KL-Shampoo and Shampoo variants in nonconvex stochastic optimization (with momentum and weight decay), including rates and stability under realistic noise and rank-deficient gradients.
- A principled explanation for why two-sided preconditioning consistently outperforms one-sided variants; characterize regimes (architectures, data, layer types) where one-sided may suffice or be preferable, and propose hybrid schemes.
- A systematic derivation of layer-wise scalings for Muon that obviate grafting while matching or exceeding grafted performance; test RMS-RMS operator norm and new scalings across tasks and scales.
- Robust determination of the critical batch size for matrix-based optimizers vs element-wise methods across model scales, sequence lengths, and datasets; produce scaling laws and predictive heuristics.
- Generality of findings beyond the single dataset and architecture: replicate across diverse corpora (e.g., The Pile, BookCorpus, code), longer sequence lengths, MoE transformers, and other domains (vision at ImageNet scale, speech, RL); check whether optimizer rankings persist.
- Comprehensive sensitivity analyses for weight decay, learning-rate schedules (warmup, cosine vs other decays), and clipping; quantify how these confound optimizer comparisons and alter rankings.
- Principled selection of Shampoo’s exponent p (e.g., 1/4 vs 1/2) per layer and architecture; develop automatic tuning or theory-guided criteria linking p to geometry, spectrum, or noise characteristics.
- A rigorous study of ε in matrix inverse roots (both numerical stability and optimization behavior): characterize optimal ε by layer and training stage; propose adaptive ε schedules or damping strategies that improve stability without degrading performance.
- Impact of practical approximations on conclusions: stale factor updates, blocking/partitioning, mixed precision, approximate eigensolvers, and Newton–Schulz iterations; provide compute–sample efficiency trade-off curves and conditions under which Shampoo retains advantages.
- A thorough comparison of Shampoo vs SOAP/EShampoo under identical settings with per-iteration preconditioner updates; isolate the benefits of eigenbasis changes vs eigenvalue correction and identify regimes where each variant dominates.
- Centered-covariance (mean-subtracted) versions of Shampoo: implement efficient forms, analyze stability, and benchmark vs uncentered/KL objectives; clarify when centered whitening helps or harms.
- Clarify the mechanism by which Shampoo’s benefits are “exclusive to weight matrices”: derive theory explaining why 2D reshaping outperforms 1D/4D preconditioning; explore whether alternative parameterizations or reshaping strategies can make embeddings or 1D parameters benefit.
- Deeper ablations on left vs right adaptations: quantify their individual contributions to performance, explore asymmetric powers/exponents, and test cross-coupled or data-driven adaptation matrices.
- Extend analyses of numerical stability for Muon’s Newton–Schulz iteration: characterize failure modes, coefficient choices, iteration counts, and precision requirements; compare rigorously to SVD across scales.
- Compute-optimal training with matrix optimizers: verify the claim that Chinchilla budgets are not compute-optimal for Shampoo/Muon; derive new scaling laws relating model size, tokens, and compute for these methods.
- A graft-free perspective for Shampoo: assess whether Adam grafting is masking intrinsic scaling behavior; develop per-layer magnitude normalization grounded in theory (e.g., nuclear/RMS norms) and compare to grafted variants.
- Formal links between the proposed time-averaged orthogonality perspective and existing views (variance adaptation, whitening, trust-region interpretations): establish equivalence or separation conditions and validate experimentally.
- Behavior under distribution shift and nonstationarity (continual learning, curriculum): test resilience of Shampoo/Muon when the stationary data assumption breaks and devise adaptation strategies if needed.
- Interactions with regularization and normalization (gradient clipping, norm constraints, dropout, normalization layers): quantify how these interact with spectral descent and Shampoo’s preconditioning.
- Per-layer heterogeneity: identify which layers benefit most from matrix preconditioning; propose selective application strategies or adaptive layer selection policies and validate their efficiency gains.
- Robustness to heavy-tailed gradient noise and class imbalance for matrix-based methods (analogous to Adam’s known robustness); design controlled tests and characterize failure/success regimes.
- Standardized, reproducible benchmarks: release full hyperparameter grids (including weight decay), diverse datasets, and code paths with typical training efficiencies (stale updates, blocking) to reduce confounding factors and enable consistent comparisons.
- Theory and practice for rank-deficient gradients: analyze how pseudoinverses, damping, and spectrum truncation affect spectral descent equivalence and Shampoo’s behavior; propose safe defaults.
- Practical guidance for preconditioner update frequency and eigen-decomposition budgets: derive heuristics and criteria for when to update and quantify performance degradation from staleness across tasks.
- Downstream effects: measure whether pretraining gains from Shampoo/Muon translate to improved fine-tuning, transfer, calibration, and OOD robustness; expand metrics beyond validation perplexity.
- Explicit formalization and standardization of the “token efficiency” metric used; ensure fair cross-optimizer comparisons by normalizing for compute and detailing the measurement protocol.
- Unify Shampoo/Muon with natural-gradient/K-FAC frameworks: compare under matched settings, analyze similarities/differences in curvature approximations, and identify opportunities for hybrid algorithms.
Glossary
- Adafactor: An adaptive optimizer that factorizes second-moment estimates to reduce memory while retaining performance. "An alternative shape-agnostic perspective is viewing Shampoo as approximately running Adafactor/Adam in the eigenbasis of Shampoo's preconditioner"
- AdaGrad: An adaptive gradient method that scales updates by the accumulated squared gradients, often via a (diagonal or full) preconditioner. "Shampoo was originally introduced as a Kronecker-factored upper bound for the full-matrix Adagrad preconditioner"
- Adam: An adaptive optimizer that uses exponential moving averages of gradients and squared gradients to scale updates element-wise. "Adam, the de facto standard for neural network training, preconditions the gradient with an element-wise scaling"
- AdamW: A variant of Adam that decouples weight decay from the gradient-based update for better regularization. "Consistent with \citet{orvieto2025search}, AdamW outperforms Signum across all settings."
- bias correction: A technique that adjusts EMAs early in training to remove initialization bias. "We ignore bias correction for simplicity, as these terms can be absorbed into the learning rate."
- Chinchilla token budget: A compute-optimal scaling guideline balancing model size and training tokens for LLMs. "Notably, the standard Chinchilla token budget may no longer be compute-optimal for Shampoo and Muon"
- cosine decay schedule: A learning-rate schedule that decays the rate following a cosine curve. "After 10\% warmup, we use a cosine decay schedule for the learning rate until 0."
- critical batch size: The batch size beyond which scaling benefits diminish for a given optimizer and model. "these results suggest, consistent with prior work, that the critical batch size is higher for matrix-based methods than for element-wise methods"
- decoupled weight decay: Applying weight decay separately from the gradient update to avoid interference with adaptive scaling. "Decoupled weight decay is applied to all parameters and fixed to $0.1$."
- eigendecomposition: Decomposition of a matrix into its eigenvalues and eigenvectors, often used to compute matrix roots or inverses. "we update Shampoo's preconditioner every iteration using an eigendecomposition"
- EMA (Exponential Moving Average): A weighted average that emphasizes recent observations, used to track gradients and their statistics over time. "Recall that Adam maintains exponential moving averages (EMAs) of the stochastic gradient and its square"
- EShampoo: A variant of Shampoo that decouples and corrects eigenvalues of the preconditioner. "we find that the closely related EShampoo does not generally outperform Shampoo"
- Fisher (information): A curvature matrix capturing the sensitivity of model predictions to parameters, used in natural gradient methods. "Overall, our observations indicate that Shampoo should not be viewed as an approximation of full-matrix Adam or related matrices (e.g., gradient covariance \citep{yang2008principal,sohldickstein2012natural,ida2017adaptive}, empirical Fisher \citep{kunstner2019limitations}, or Fisher/generalized Gauss-Newton matrices \citep{amari1998natural,martens2014new})."
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, often used to measure matrix differences. "It represents the closest semi-orthogonal matrix to in Frobenius norm"
- full-matrix Adam: An Adam variant that uses a dense (non-diagonal) preconditioner capturing parameter correlations. "Shampoo is commonly thought of as an approximation to (per-parameter) full-matrix Adam, with preconditioner"
- generalized Gauss-Newton: A positive semidefinite curvature approximation derived from Jacobians, used as a second-order surrogate. "or Fisher/generalized Gauss-Newton matrices"
- grafting: Replacing the per-layer update magnitude with that from a base optimizer while keeping the direction from another method. "the per-layer update magnitude is usually grafted from a base optimizer like Adam"
- gradient covariance: The covariance matrix of gradients across data samples, used to approximate curvature or noise structure. "Overall, our observations indicate that Shampoo should not be viewed as an approximation of full-matrix Adam or related matrices (e.g., gradient covariance ...)"
- KL divergence: A measure of discrepancy between probability distributions, often minimized to align preconditioners with target statistics. "minimize the KL divergence of two zero-mean Gaussian distributions,"
- KL-Shampoo: A Shampoo variant whose factor matrices are updated to (approximately) solve a KL-divergence matching objective. "yields KL-Shampoo, whose factor matrices are defined as%"
- KL-SOAP: A method that runs Adam in KL-Shampoo’s eigenbasis, aligning updates with Shampoo’s preconditioner. "KL-SOAP runs Adam in KL-Shampoo's eigenbasis."
- Kronecker-factored: A structured approximation using Kronecker products of smaller matrices to represent large preconditioners efficiently. "Shampoo was originally introduced as a Kronecker-factored upper bound for the full-matrix Adagrad preconditioner"
- Kronecker product: The tensor product of two matrices, building a block matrix used in structured preconditioning. "Note that \Cref{eq:shampoo} is equivalent to a vectorized update with a Kronecker-factored preconditioner, ."
- K-FAC (Kronecker-Factored Approximate Curvature): A second-order optimizer approximating curvature using Kronecker-factorized blocks. "two-sided preconditioning used in methods like K-FAC"
- Loewner order: A partial order on symmetric matrices indicating one is larger in the positive semidefinite sense. "Shampoo is commonly thought of as an approximation to (per-parameter) full-matrix Adam... interpreted as an upper bound in Loewner order to full-matrix AdaGrad"
- matrix whitening: Transforming a random matrix so its row/column covariances become (scaled) identities via left/right linear transforms. "We call symmetric positive-definite matrices and matrix whitening matrices if and ."
- modular duality: A scaling principle relating layer-wise norms and update parameterizations across model widths and depths. "Motivated by modular duality \citep{large2024scalable}, \citet{bernstein2025modular} propose using the RMS-RMS operator norm for hidden linear layers"
- Moonlight scaling: A layer-wise scaling rule for Muon that mimics Adam’s RMS norm. "the Moonlight scaling \citep{liu2025muon} that mimics the RMS norm of Adam."
- Muon: A matrix-geometry optimizer that updates along the matrix sign (polar factor) of (momentum) gradients. "Applying this operation on (Nesterov) momentum yields the popular Muon optimizer"
- natural gradient variational inference: A variational inference approach using natural gradients with respect to the Fisher metric. "A similar coupled update was first proposed for natural gradient variational inference"
- Nesterov momentum: An accelerated gradient technique that uses a lookahead estimate to improve convergence. "Applying this operation on (Nesterov) momentum yields the popular Muon optimizer"
- Newton-Schulz iteration: An iterative matrix algorithm to approximate functions like the matrix inverse square root or sign using only multiplications. "estimate the matrix sign using a Newton-Schulz iteration that only relies on matrix multiplication"
- nuclear norm: The sum of singular values of a matrix, used as a convex surrogate and in spectral steepest descent scaling. "For steepest descent under the spectral norm, we have to scale the update by the nuclear norm of the gradient"
- operator norm (RMS-RMS): A matrix norm induced by RMS vector norms at input and output; here, the RMS-RMS operator norm. "The RMS-RMS operator norm is defined as $\|\|_{\mathrm{RMS}\rightarrow\mathrm{RMS} = \sqrt{\frac{n}{m} \|\|_2$, with $||||_\mathrm{RMS} = \frac{1}{\sqrt{n} ||||_2$."
- polar decomposition: A matrix factorization into a unitary (semi-orthogonal) factor and a positive semidefinite factor. "The matrix $U_t V_t^\transpose$ is the unitary factor of the polar decomposition of "
- pseudoinverse: The Moore–Penrose generalized inverse used when matrices are rank-deficient. "If is rank-deficient, one can recover spectral descent by using the pseudoinverse instead."
- RMSProp: An adaptive optimizer that scales updates by the EMA of squared gradients, similar to Adam without momentum. "RMSProp and Shampoo$^{\sfrac{1}{2}$ w/o momentum ()... the adaptive methods converge faster than their non-adaptive counterparts"
- Schatten-∞ norm: The spectral norm; the largest singular value of a matrix, used to define steepest descent for matrices. "Analogous to the vector case, where the norm induces sign descent, one can define steepest descent for matrices using the Schatten- () or spectral norm."
- semi-orthogonal: Matrices with orthonormal columns or rows; the polar factor is the closest semi-orthogonal matrix in Frobenius norm. "It represents the closest semi-orthogonal matrix to in Frobenius norm"
- SignGD: Sign gradient descent; updates in the direction of the element-wise sign of the (stochastic) gradient. "Setting recovers (stochastic) sign descent with $g_t / \sqrt{m_t^2} = \sign(g_t)$ \citep[SignGD]{bernstein2018signsgd}."
- sign descent: An optimization method that uses the sign of the gradient rather than its magnitude. "Setting recovers (stochastic) sign descent"
- Signum: A momentum-based sign optimizer that uses the sign of the EMA of gradients. "Ignoring the element-wise adaptation, we recover Signum, which updates the weights using the sign of the EMA of the gradients."
- SOAP: Running Adam in Shampoo’s eigenbasis so that adaptation happens in the preconditioner’s spectral space. "Alternatively, we can run Adam in Shampoo's eigenbasis \citep[SOAP]{vyas2025soap}"
- spectral descent: Steepest descent in matrix space under the spectral norm, updating along the polar factor and scaled by the nuclear norm. "we can write (stochastic) spectral descent (SpectralGD) as"
- spectral norm: The largest singular value of a matrix; induces the Schatten-∞ norm. "using the Schatten- () or spectral norm."
- SpectralGD: The spectral descent algorithm that updates using the polar factor of the gradient. "we can write (stochastic) spectral descent (SpectralGD) as"
- SVD (Singular Value Decomposition): Factorization of a matrix into singular vectors and singular values. "Given the reduced SVD of the gradient $G_t = U_t \Sigma_t V_t^\transpose$"
- time-averaged orthogonality in expectation: A property where, after EMA and expectation, left/right covariances become identities. "We call time-averaged orthogonal in expectation"
- token efficiency: Training efficiency measured by performance per token processed. "we demonstrate that Shampoo achieves higher token efficiency than Muon"
- vectorized update: Rewriting matrix updates as vector operations, often with Kronecker-structured preconditioners. "Note that \Cref{eq:shampoo} is equivalent to a vectorized update with a Kronecker-factored preconditioner"
- whitening: Transforming variables to have (scaled) identity covariance; used to manage stochastic gradient noise. "Whitening is another approach to handling stochasticity that is commonly cited as motivation for Shampoo"
Practical Applications
Immediate Applications
Below are actionable, deployable-now uses that translate the paper’s findings into concrete workflows, tools, and decision rules.
- Optimizer choice and configuration for training LLMs
- What to do: Prefer Shampoo variants (Shampoo1/2 or KL-Shampoo) over Muon when you can afford matrix preconditioning, and prefer them over AdamW when pursuing higher token efficiency. Apply Shampoo only to hidden weight matrices; use two-sided preconditioning; exclude embeddings and 1D parameters; graft per-layer update magnitude from Adam; tune ε (epsilon); and, where possible, update preconditioners every step.
- Sector: Software/AI, Healthcare (clinical NLP), Finance (NLP), Education (LLMs for tutoring), Robotics (policy/backbone pretraining).
- Tools/workflows: PyTorch Distributed Shampoo; add a training-recipe toggle “Shampoo on 2D weights only”; automated ε sweeps; Adam-grafting by default; SVD-based factor updates where feasible.
- Assumptions/dependencies: Extra compute/memory for matrix ops; availability of accurate SVD or a well-tuned Newton–Schulz routine; careful ε tuning materially affects ranking; two-sided preconditioning outperforms one-sided.
- Batch size policy for matrix-based optimizers
- What to do: Target higher batch sizes for matrix optimizers than for element-wise methods; start at ≥256 if capacity allows and tune for the method-specific critical batch size.
- Sector: Software/AI at scale (foundation models), Enterprise ML platforms.
- Tools/workflows: Batch-size scaling sweeps tied to optimizer choice; autoscheduling that raises batch size when switching from AdamW to Shampoo/Muon.
- Assumptions/dependencies: Sufficient hardware throughput and memory; distributed training stack; effects were shown on Llama-like LMs and C4—verify per domain.
- Reshaping strategy for vision and convolutional models
- What to do: For ViTs and ConvNets, reshape parameters into 2D matrices and apply Shampoo there; avoid 1D reshaping (which degenerates to full-matrix Adam) and avoid higher-order tensor preconditioning when a 2D reshape is available.
- Sector: Computer Vision (industry and academia), Robotics (perception), Healthcare (imaging), Automotive.
- Tools/workflows: Model-parameter registry that tags tensor shapes and forces 2D reshape where possible; optimizer hooks that skip embeddings and 1D parameters.
- Assumptions/dependencies: Implementation must support per-parameter geometry policies; confirm gains on your dataset and architecture.
- Avoid one-sided preconditioning unless constrained
- What to do: Use two-sided Shampoo. If constrained, preconditioning with the “left” factor (activation-side) is preferable to the “right” factor, but both underperform two-sided.
- Sector: Software/AI, Robotics, Research labs.
- Tools/workflows: Switch off one-sided K-FAC/Shampoo defaults; unit tests that fail if only one side is active in production recipes.
- Assumptions/dependencies: Two-sided updates cost more compute; ensure stable/regularized inverses and grafting.
- Benchmarking and reproducibility hygiene
- What to do: When comparing optimizers, control for confounders identified in the paper: (1) parameter subsets (only weight matrices), (2) grafting vs per-layer scaling, (3) ε tuning, (4) accuracy of matrix computations (SVD vs Newton–Schulz), (5) preconditioner update frequency.
- Sector: Academia, Industry R&D, Open-source ML.
- Tools/workflows: Standardized optimizer-reporting template in experiment logs; CI checks for missing grafting or ε sweeps; publish which parameters were preconditioned.
- Assumptions/dependencies: Culture/process changes; small upfront engineering to standardize pipelines.
- Cost and energy reductions via token efficiency
- What to do: For fixed quality, reduce training tokens or steps when using Shampoo-on-weight-matrices; or for fixed budget, target higher quality. Include optimizer choice in cost models.
- Sector: Any organization training medium-to-large models; Policy teams tracking AI sustainability.
- Tools/workflows: TCO/CO2 estimators include “optimizer factor”; procurement and scheduling consider matrix-optimizer profiles.
- Assumptions/dependencies: Gains depend on task/scale; matrix ops may slightly raise instantaneous power usage but reduce total tokens.
- Adapter and LoRA fine-tuning
- What to do: Apply Shampoo to LoRA/adaptor matrices only, with Adam grafting and tuned ε; keep everything else on AdamW. This preserves low overhead while capturing matrix-geometry gains.
- Sector: Startups, open-source fine-tuners, edge/consumer GPU users.
- Tools/workflows: Fine-tuning scripts with “Shampoo-on-adapters” flag; default ε sweeps per adapter rank.
- Assumptions/dependencies: Overhead scales with adapter size; ensure numerically stable low-precision kernels if using FP16/FP8.
- Guidance for practical Muon usage
- What to do: If using Muon, prefer grafting for layer-wise magnitude over “classic” or “Moonlight” scaling; consider SVD-based semi-orthogonalization when accuracy matters; otherwise ensure Newton–Schulz is carefully tuned.
- Sector: Software/AI practitioners already on Muon.
- Tools/workflows: Drop-in grafting; validate SVD vs Newton–Schulz on a pilot run; per-layer scaling sanity checks.
- Assumptions/dependencies: Compute budget; numerical stability; consistent weight-decay handling.
- Curriculum for optimizer education and internal training
- What to do: Teach the Adam:Signum :: Shampoo:Muon analogy; emphasize “Shampoo’s benefits come from weight matrices” and “two-sided beats one-sided”; explain “time-averaged semi-orthogonality in expectation” as a practical design lens.
- Sector: Academia, ML platform teams.
- Tools/workflows: Internal docs, lectures; code examples showing decomposition and parameter-shape policies.
- Assumptions/dependencies: None beyond training time; improves shared mental models and recipe quality.
- Policy and governance recommendations for reporting
- What to do: Require optimizer reporting in model cards and papers: parameter subsets preconditioned, grafting usage, ε values, matrix-computation method/frequency. Recognize optimizer choice as a lever for energy savings.
- Sector: Policy, Standards bodies, Conferences/journals.
- Tools/workflows: Model card fields and checklist updates.
- Assumptions/dependencies: Community adoption.
Long-Term Applications
These leverage the paper’s conceptual advances and empirical guidance but will benefit from further research, scaling, or engineering.
- Design of new “trajectory- and noise-aware” matrix optimizers
- Idea: Use “time-averaged orthogonality in expectation” as a design principle. Create optimizers that explicitly control how semi-orthogonality is enforced across time and stochasticity, potentially interpolating between spectral descent and Shampoo/KL-Shampoo.
- Sector: Academia, AI labs.
- Tools/products: Next-generation matrix optimizers; convergence theory tied to trajectory averaging.
- Assumptions/dependencies: Theoretical development; robust implementations beyond LMs and C4.
- Geometry-aware AutoML for per-parameter preconditioning
- Idea: Auto-select geometry (vector vs matrix) and preconditioner type per parameter group (e.g., 2D weights vs embeddings), with ε autotuning, grafting policy, and preconditioner update cadence.
- Sector: MLOps platforms, Cloud AI services.
- Tools/products: “Optimizer policy engine” integrated with schedulers; Bayesian/learning-based ε tuning.
- Assumptions/dependencies: Metadata on parameter shapes; reliable performance predictors; additional controller compute.
- Hardware/software co-design for matrix preconditioning
- Idea: Accelerators and libraries optimized for semi-orthogonalization (fast/low-precision SVD, stable Newton–Schulz), Kronecker-factored roots, and grafting without bottlenecks.
- Sector: Semiconductor, Systems software (BLAS, compiler stacks), Cloud providers.
- Tools/products: Kernel libraries with numerically robust, mixed-precision matrix-root operations; compiler passes that fuse grafting and preconditioning.
- Assumptions/dependencies: Vendor support; demand from large-scale training users.
- Dynamic batch sizing tied to optimizer behavior
- Idea: Online estimation of the optimizer’s critical batch size; dynamically adjust batch size as training progresses and as the optimizer (Shampoo vs AdamW) or grafting changes.
- Sector: Enterprise ML, Cloud training orchestration.
- Tools/products: Controllers that modulate batch size to match optimizer regime; auto-scaling policies.
- Assumptions/dependencies: Stable throughput when batch size varies; integration with schedulers and checkpointing.
- Extending matrix-based adaptation beyond 2D linear layers
- Idea: Explore principled 2D reshaping for higher-order tensors (e.g., attention projections, conv kernels) and confirm when/why 2D dominates direct higher-order preconditioning; unify with attention-specific structures.
- Sector: Vision, Speech, Multimodal models, Robotics.
- Tools/products: Shape-policy libraries with learned or rule-based folding strategies.
- Assumptions/dependencies: Empirical validation; domain-specific constraints.
- Robust low-precision training with matrix optimizers
- Idea: Develop numerically stable FP8/bfloat8 variants of Shampoo/KL-Shampoo and Muon. Improve polynomial approximations and scaling safeguards for Newton–Schulz; error-compensation techniques for eigenvalue corrections.
- Sector: AI at scale, Edge AI.
- Tools/products: Mixed-precision optimizer libraries; validation suites for stability.
- Assumptions/dependencies: New numerical schemes and theory; hardware support.
- Cross-domain validation and domain-specific recipes
- Idea: Systematically quantify gains in RL (noisy gradients), recommendation systems (sparse, heavy-tailed), healthcare (safety-critical), and finance (risk-sensitive). Tailor ε, grafting, and shape policies.
- Sector: Robotics/RL, Recommenders, Healthcare, Finance.
- Tools/products: Domain-optimized optimizer presets; regulatory-grade documentation (healthcare/finance).
- Assumptions/dependencies: Domain datasets; safety/compliance constraints.
- Governance and sustainability incentives
- Idea: Policies that encourage token-efficient optimizers (where appropriate) via carbon budgeting and compute grants; standardized disclosures on optimizer configuration to enable fair comparisons and sustainability tracking.
- Sector: Policy, Funding agencies, Standards bodies.
- Tools/products: Reporting standards; incentive programs for adopting efficient training recipes.
- Assumptions/dependencies: Agreement on metrics; minimal risk of perverse incentives.
- Theoretical unification and guarantees
- Idea: Formalize convergence and generalization under the “time-averaged orthogonality in expectation” framework; clarify when matrix whitening vs variance-adaptation narratives are predictive; connect to modular duality and µP scaling.
- Sector: Academia, Theoretical ML.
- Tools/products: Theory papers; reference implementations that match assumptions.
- Assumptions/dependencies: New analytical tools; validation against large-scale experiments.
- Practitioner-facing productization
- Idea: Turn the paper’s takeaways into defaults in major frameworks: “Shampoo on weights only,” “two-sided by default,” “Adam-grafting on,” “ε autotune,” “matrix-optimizer-aware batch sizing,” and standardized logging of optimizer internals.
- Sector: ML frameworks (PyTorch, JAX, DeepSpeed), Open-source ecosystems.
- Tools/products: Optimizer plugins; recipe templates; telemetry modules.
- Assumptions/dependencies: Community buy-in; maintenance for diverse model families.
Collections
Sign up for free to add this paper to one or more collections.

