OBLIQ-Bench: Exposing Overlooked Bottlenecks in Modern Retrievers with Latent and Implicit Queries
Abstract: Retrieval benchmarks are increasingly saturating, but we argue that efficient search is far from a solved problem. We identify a class of queries we call oblique, which seek documents that instantiate a latent pattern, like finding all tweets that express an implicit stance, chat logs that demonstrate a particular failure mode, or transcripts that match an abstract scenario. We study three mechanisms through which obliqueness may arise and introduce OBLIQ-Bench, a suite of five oblique search problems over real long-tail corpora. OBLIQ-Bench exposes an overlooked asymmetry between retrieval and verification, where reasoning LLMs reliably recognize latent relevance whenever relevant documents are surfaced, but even sophisticated retrieval pipelines fail to surface most relevant documents in the first place. We hope that OBLIQ-Bench will drive research into retrieval architectures that efficiently capture latent patterns and implicit signals in large corpora.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Search engines (and AI tools that “look things up”) are pretty good at finding pages that match your words. But many real questions don’t mention the exact words that appear in the answers. Instead, they’re looking for hidden, implied, or abstract patterns. This paper calls those “oblique” queries and builds a new test suite—OBLIQ‑Bench—to show that today’s best search systems still struggle with them.
The authors also point out a key imbalance: powerful reasoning AIs can recognize the right answer when it’s shown to them, but standard search systems often fail to bring those answers to the top in the first place. In short: recognizing is easy; finding is hard.
What questions the paper asks
- Can we define and collect realistic search tasks where what’s relevant is hidden or implied (not spelled out in the text)?
- How well do modern search methods handle these “oblique” queries compared to a strong reasoning AI that can check candidates one by one?
- Is there a big gap between “retrieving” relevant items and “verifying” them once surfaced?
- How can we build benchmarks that push search systems to capture such hidden patterns?
How they approached the problem
To study this, the authors created OBLIQ‑Bench, five search tasks that focus on different kinds of hidden (“latent”) relevance across real, messy collections:
- Descriptive (implicit signals):
- Tweets that subtly show a particular stance without saying it directly.
- Chat transcripts where an AI breaks a rule later in the conversation without acknowledging it.
- Analogue (shared structure):
- Math problems that require the same underlying solving trick, even if the topics look different.
- Articles by the same author across unrelated topics, so the only clue is writing style, not subject.
- Tip‑of‑the‑tongue (fuzzy memory):
- Finding a specific short exchange from long congressional hearing transcripts based on a vague recollection (no names or obvious keywords).
They built these tasks with an “attribute-first” pipeline:
- A person defines a hidden lens to read each document (e.g., stance, failure mode, proof strategy, author style, or scenario).
- A large AI labels each document once through that lens (this is cheaper than checking every document for every query).
- These labels are grouped into clusters of similar hidden attributes.
- The AI writes queries that describe each cluster while avoiding easy giveaways like unique words or names.
- After running search systems, a “pooling” step lets a strong reasoning AI double‑check top results to add any missed relevant items.
They then tested many search approaches:
- Lexical (word matching): a classic baseline.
- Dense embeddings (semantic search): modern models that find meaning-based similarities.
- Late interaction (token-level matching): keeps fine-grained signals without full heavy reading.
- Agentic pipelines: step‑by‑step AI agents that reformulate the query and search in multiple hops.
- A strong reasoning AI as a re‑ranker: it doesn’t search the whole collection, but if you give it a candidate list, it can reliably spot the right answers (this mimics “verification”).
To measure performance, they used simple ideas:
- NDCG@10: “How good are the top 10 results, with higher-ranked correct answers counting more?”
- Recall@10: “Did you find the right thing in your top 10 at all?”
What they found and why it matters
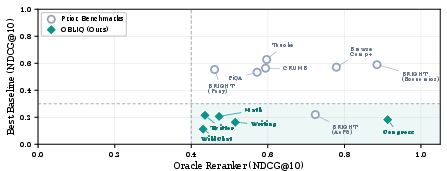
The big picture: OBLIQ‑Bench reveals a consistent gap. When the correct items are in the candidate list, a strong reasoning AI can reliably recognize them. But most search systems fail to surface those items in the first place.
Key takeaways explained plainly:
- Oblique queries expose a “retrieval vs. verification” gap.
- Retrieval = finding needles.
- Verification = checking “is this really a needle?”
- The strong AI is great at checking, but today’s search tools often don’t bring the needle to the top.
- The gap is small on many older benchmarks but big on OBLIQ‑Bench. On popular existing tests, fast retrievers already do almost as well as a strong AI checker. On OBLIQ‑Bench, they often score near zero while the checker would score much higher if given the chance.
- Different task types stress different weaknesses:
- Implicit stance and long chat failures: search struggled to find them, even though the checker can spot them when shown.
- Shared math strategies: some signal can be found, but a checker that reads both problem and solution does much better.
- Writing style across topics: rewriting queries or multi-step searching actually hurt; topic words don’t help style.
- Tip‑of‑the‑tongue hearings: best fast retrievers found the right passage only a small fraction of the time; the checker nailed it once the passage appeared in the candidate pool.
- “Try harder” tricks help only sometimes. Multi‑hop or query‑rewriting agents help for some oblique cases (like vague memories) but not others (like style). There’s no one-size-fits-all shortcut.
Why this work matters and what could happen next
If we want AI systems to support real, messy information needs—like auditing AI behavior, searching for subtle stances, spotting patterns in large archives, or finding similar reasoning across problems—we need search tools that can detect hidden signals, not just match obvious keywords or surface topics.
OBLIQ‑Bench gives researchers a way to measure real progress on that goal. It suggests new directions:
- Build retrieval systems that pre‑compute and index latent attributes (e.g., “behavioral patterns,” “argument structures,” “style fingerprints”) so they’re searchable at speed.
- Train on data that emphasizes subtle, implicit relations instead of only topic similarity.
- Design hybrid systems where a fast retriever brings better candidates and a reasoning AI verifies them efficiently.
Bottom line: Today’s tools are good at recognizing the right answer when it’s in front of them. The next big step is learning how to surface those hidden answers in the first place. OBLIQ‑Bench is meant to catalyze that progress.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete knowledge gaps and open questions that the paper leaves unresolved, organized to help future researchers plan targeted follow-up studies:
- Dependence on proprietary frontier models
- How sensitive are the benchmark’s conclusions to the specific verifier and embedding models used (e.g., GPT-5.2, Gemini-2-Embedding)? Replicate all findings with strong open models (e.g., ColBERTv2/PLAID2, E5-Mistral, Jina/Instructor, ModernBERT, LLM-as-encoder) to assess robustness and reproducibility.
- Provide variance across multiple model seeds and versions; quantify how much the retrieval–verification gap shrinks or widens when swapping models.
- Verification reliability and calibration
- The “oracle” reranker’s judgments are not independently audited at scale. What are its false positive/negative rates on each task? Establish human-verified subsets to estimate verifier accuracy, calibration, and consistency (inter-rater reliability vs. LLM).
- Does the verifier’s performance degrade on adversarial or near-miss cases (e.g., sarcastic tweets misread as implicit stance; stylometric confounds)? Create adversarial test suites and measure verifier brittleness.
- Pooling bias and upper/lower-bound validity
- The reranker only sees a pooled candidate set; relevant documents missing from the pool cap the upper bound. Quantify residual pool bias by (i) deeper pooling baselines, (ii) stratified/importance sampling of the tail, or (iii) exhaustive re-ranking of full corpora for small datasets.
- Compare gold-infusion upper bounds with alternative bounds (e.g., randomized control pools, fusion of more retrievers, BM25+RM3, SPLADE) to determine sensitivity to pool composition.
- Cost, scalability, and practical feasibility
- End-to-end cost and compute are not reported. Provide precise CPU/GPU hours and dollar estimates for index-time annotation, clustering, query generation, and reranking, and extrapolate to web-scale corpora.
- Can index-time LLM passes (annotation/extraction) be made incremental for streaming corpora? What are maintenance/update costs under concept drift?
- Construction pipeline validity (annotation → clustering → query gen)
- Annotation fidelity: What is the error rate of the single-pass LLM annotation for each task (implicit stance, failure type, proof strategy, scenario)? Validate with human labels on stratified samples.
- Clustering stability: How sensitive are clusters to embedding choice, clustering algorithm, and hyperparameters? Report cluster purity/coverage metrics and ablations.
- Query generation leakage: Despite instructions to avoid source vocabulary, quantify lexical/style leakage from sources to queries (e.g., n-gram overlap, named entities, topical shibboleths). Add a leakage-detection audit and adversarial paraphrasing controls.
- Ground-truth adequacy and alternative interpretations
- Descriptive tasks: “Implicit stance” and “failure modes” are inherently subjective. Provide annotation guidelines and inter-annotator agreement among humans; release adjudicated gold subsets to measure construct validity.
- Math Meta-Program: The LLM-derived “proof technique” labels require domain validation. Obtain expert annotations, define a stable taxonomy, and quantify agreement with the LLM’s meta-program labels.
- Congress Hearings: Some queries may match multiple passages. Audit for legitimate multi-gold cases and support graded relevance or multi-label ground truth.
- Segmentation and granularity effects
- Congress Hearings: How do different segmentation strategies (turn-level vs. longer spans, sentence windows, overlap) affect retrieval and verifier performance? Provide sensitivity analyses and segment-length ablations.
- Writing-Style: Confirm that snippet boundaries do not leak source-specific artifacts (HTML remnants, formatting quirks) that act as shortcuts.
- Task scope, representativeness, and external validity
- Domain coverage: All tasks are English and text-only. Extend to multilingual corpora and multimodal settings (audio/video transcripts, code repositories) to test whether obliqueness persists across modalities.
- Corpus representativeness: Twitter dataset is restricted to a single conflict/time period; WildChat to 2025; Writing-Style to 64 authors. Quantify how conclusions change with broader/later corpora and different author pools (e.g., social media, fiction, policy memos).
- Long-tail prevalence: Estimate how frequently oblique queries arise in real user traffic. Provide a taxonomy and prevalence estimates (e.g., % of implicit/latent queries) across domains.
- Metrics and evaluation design
- For single-gold tasks, Recall@k is informative, but NDCG may be less meaningful. Add Success@k and latency-adjusted metrics to reflect practical search quality.
- Report statistical significance tests and effect sizes across systems, and include per-query variance/long-tail breakdowns to identify failure clusters.
- Investigate alternative “obliqueness” measures beyond the retrieval–verification gap, which is model-dependent. Propose model-agnostic proxies (e.g., low lexical overlap, high topic distance, distributed evidence) and validate correlations with gap size.
- Agentic and multi-hop retrieval limits
- Only one multi-hop agent and fixed hop budget (four) were evaluated. Systematically vary hop count, memory, planning strategies, and retrieval–reading schedules; compare with more capable research agents and reinforced search policies.
- Analyze failure traces to understand when decomposition helps vs. harms (e.g., Writing-Style) and learn heuristics that predict when to enable agentic search.
- Late-interaction and hybrid retrievers
- Only a single small late-interaction model (LateOn 149M) was included. Evaluate stronger late-interaction baselines (e.g., ColBERTv2/er, PLAID2, SPLADE++) and hybrids (RAG with token-level matching) to determine whether token-level alignment can mitigate obliqueness.
- Training for obliqueness (not only zero-shot)
- The study primarily evaluates zero-shot (or lightly prompted) retrievers. Provide train/dev/test splits for OBLIQ-Bench to enable (i) supervised and distillation-based training from the verifier, (ii) contrastive hard-negative mining tailored to latent attributes, and (iii) curriculum learning across mechanisms (descriptive, analogue, tip-of-the-tongue).
- Open question: What index-time representations help? Explore “attribute indexes” (compact latent signatures extracted by LLMs), caching/verifier distillation, and compressed document-attribute graphs that can be searched efficiently.
- Fairness, safety, and ethics
- Implicit stance retrieval can amplify sensitive content and demographic biases. Measure disparate error rates across dialects, topics, and user groups; publish a data card and risk assessment; provide opt-outs for authors/content.
- Twitter/X data access may be restricted; clarify licensing and redistribution (IDs vs. text). Provide alternate open corpora to ensure equitable access for replication.
- Concept drift and benchmark longevity
- Obliqueness likely evolves with time and model capabilities. Design a protocol for periodic refresh (new conflicts, new transcripts, updated WildChat slices) and track “moving ceiling” as verifiers and retrievers improve.
- Open question: How to maintain benchmark difficulty without relying on proprietary models as the verifier?
- Detailed ablations currently missing
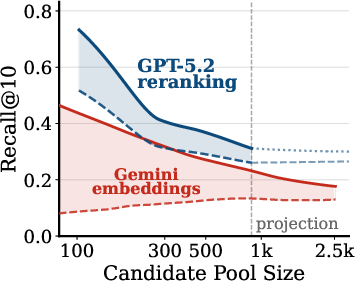
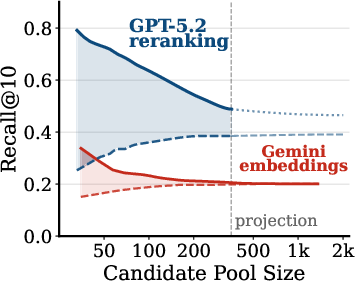
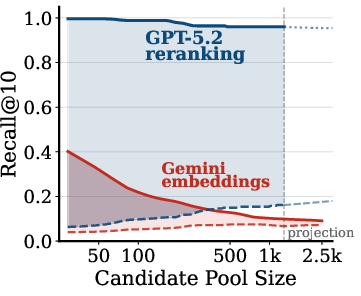
- Pool-size scaling plots are shown for 3 tasks only; extend to all five tasks and report where curves saturate.
- Provide per-task hard-negative analyses (which distractors fool which systems, and why) to inform targeted model improvements.
- Quantify the effect of giving the verifier solutions in Math (already partially shown) and test analogous “oracle hints” in other tasks (e.g., stance rationales, failure-chain summaries) to understand which latent signals are decisive.
- From verification to retrieval architectures
- The paper motivates “index-time reasoning,” but does not prototype scalable architectures that make latent attributes searchable. Open questions:
- How to learn compact, updatable latent-attribute indices with bounded memory/latency?
- Can verifier signals be distilled into dense or late-interaction retrievers without catastrophic forgetting?
- What are effective routing/gating schemes that call verifiers sparsely yet reliably when obliqueness is detected?
These gaps outline a concrete roadmap: validate and stress-test the benchmark’s construction and verifier; broaden baselines and domains; formalize obliqueness; and invent efficient retrieval architectures that surface latent signals without heavy per-query LLM compute.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built now by combining current retrievers with LLM-based verification/reranking, and by adopting the paper’s corpus-annotation pipeline to bridge the retrieval–verification gap.
- Oblique monitoring of social media for implicit stances
- Sector: media intelligence, brand safety, geopolitical risk, public policy
- What: Index tweets/posts by latent stance (e.g., irony, implied blame, subtle endorsement) extracted via an offline LLM pass; support analyst queries that describe a stance rather than keywords; use LLM tournament reranking on candidate pools to prioritize latent matches.
- Tools/workflows: Offline “latent attribute indexer” (Stage 1–2 in paper), clustering and canonical theme labeling (Stage 3), stance-style query templates (Stage 4), dense retrieval + listwise LLM reranker.
- Assumptions/dependencies: Access to a capable LLM for annotation and reranking; social data access and compliance; ongoing cost controls for periodic re-annotation.
- Automated auditing of LLM conversation logs for failure modes
- Sector: software (AI product), compliance, QA, customer support
- What: Sweep conversation corpora to flag transcripts exhibiting behavioral failures (e.g., delayed constraint violations, hallucination uncorrected later), cluster failure modes, and surface representative cases for triage and model improvement.
- Tools/workflows: WildChat-style pipeline (LLM-based log annotation, failure-mode clustering, scenario queries), scheduled runs, dashboards with exemplar threads; dense retrieval + LLM reranker for targeted audits.
- Assumptions/dependencies: Privacy-preserving processing; stable prompts for error detection; availability of logs and consent; budget for offline annotation.
- Scenario-based search in long transcripts and hearings (tip-of-the-tongue)
- Sector: legal, policy, journalism, archives
- What: Enable investigators to find obscure transcript passages from abstract recollections (tone, rhetorical move, scenario) rather than named entities or quotes.
- Tools/workflows: Build a transcript index; at query time combine multi-hop decomposition with large candidate pools from diverse retrievers; apply tournament reranking to recover the target passage.
- Assumptions/dependencies: High-quality transcript segmentation; permissioned access; LLM reranking latency/cost acceptable for investigative workflows.
- Authorial-style retrieval across topics for editorial forensics
- Sector: media, academic integrity, enterprise knowledge management
- What: Retrieve writings by the same author across unrelated topics to assist ghostwriting detection, attribution checks, or continuity reviews; rely on stylistic invariants rather than topic overlap.
- Tools/workflows: Author-labeled corpora where available; style fingerprints via offline features or LLM annotations; hybrid retrieval (late interaction + dense) and LLM reranking for verification.
- Assumptions/dependencies: Legal and ethical use; absence of personally identifiable information that can shortcut retrieval; validated attribution criteria.
- Technique-aware math/technical content discovery
- Sector: education, research, content platforms
- What: Let educators and students find problems by underlying proof/solution technique (e.g., invariants, extremal arguments) across topics; support curriculum planning and targeted practice.
- Tools/workflows: Offline extraction of “meta-program” from solutions; cluster techniques; build “browse-by-technique” and “suggest similar by technique” features; listwise reranking to curate sets.
- Assumptions/dependencies: Availability of solutions or solution sketches; quality of technique extraction; manageable corpus sizes for periodic annotation.
- Retrieval–verification benchmarking for RAG systems
- Sector: software/AI infrastructure
- What: Use OBLIQ-Bench tasks to stress-test enterprise retrievers; measure retrieval–verification asymmetry to decide budgets for reranking, multi-hop, and index design.
- Tools/workflows: Integrate the “RVA dashboard” (gap between best reranker and best scalable retriever); candidate-pool scaling experiments; adjust retrieval fanout and reranker calls accordingly.
- Assumptions/dependencies: Access to evaluation corpora similar to target domain; ability to log and analyze candidate pool performance.
- Latent-attribute indexing for enterprise knowledge search
- Sector: enterprise search, product support
- What: Pre-annotate documents with latent attributes (e.g., failure scenario, workflow phase, risk posture) to improve discovery of content that “fits a pattern” rather than shares vocabulary.
- Tools/workflows: Adopt the paper’s Stage 1–3 pipeline; expose attribute facets; hybrid retrieval (attribute filters + dense retrieval); LLM reranking for top-k.
- Assumptions/dependencies: Domain-appropriate attribute definitions; governance for periodic re-annotation; validation against ground truth or expert review.
- Content moderation and safety for obfuscated content
- Sector: trust & safety
- What: Detect content that implicitly expresses prohibited stances or evades keyword filters (sarcasm, coded language).
- Tools/workflows: Offline attribute extraction for latent harms; cluster taxonomies; route candidate hits to human review aided by LLM verification.
- Assumptions/dependencies: Clearly defined policy taxonomies; human-in-the-loop for contested judgments; fairness and bias audits.
- Productizing the tournament reranker as a service
- Sector: AI platforms
- What: Offer a listwise, tournament-style LLM reranking API that scales to large candidate pools with compute budgeting, to improve precision@k on latent queries.
- Tools/workflows: Pooling across multiple retrievers; batched listwise comparisons; optional gold injection for evaluation; observability around cost vs. gain curves.
- Assumptions/dependencies: Frontier LLM access; cost visibility; safeguards for prompt injection and toxic content.
Long-Term Applications
These directions require further research, new models, or scalable systems engineering to make oblique retrieval efficient and routine.
- Oblique-aware first-stage retrievers that surface latent patterns
- Sector: search engines, AI infrastructure
- What: New architectures that expose latent document attributes at search time (e.g., attribute-aware indexes, multi-representation stores, learned “latent pattern” keys) so top-k contains true positives without heavy reranking.
- Potential products: Attribute-augmented ANN indices; hybrid token/attribute/graph retrieval; “pattern probes” akin to learned detectors.
- Dependencies: Training corpora labeled with latent attributes (from pipelines like OBLIQ-Bench); objectives beyond lexical/semantic similarity; efficient sublinear query-time execution.
- Training objectives and datasets for “latent similarity” retrieval
- Sector: AI research
- What: Curate and scale datasets where relevance is governed by implicit stance, behavior, technique, or style; train embedding/late-interaction models to capture these signals.
- Potential tools: Pretraining tasks that align queries with implicit document attributes; contrastive learning on clustered attribute labels; synthetic hard negatives from OBLIQ-style distractors.
- Dependencies: High-quality LLM-generated or expert-verified labels; robustness to noise and bias; reproducible evaluation (e.g., RVA-based metrics).
- Agentic retrieval that plans search for oblique targets
- Sector: AI agents
- What: Multi-hop agents that translate oblique needs into heuristic search actions (scouting, probing for telltale micro-features, iterative refinement) with guarantees on coverage and cost.
- Potential products: “Scenario search” agents for legal/policy research; analogical search assistants for code, math, or design patterns.
- Dependencies: Reliable subtask libraries, decision-theoretic budgeting, and fallback to attribute indexes; guardrails against topic drift.
- Enterprise-grade latent-attribute pipelines
- Sector: enterprise platforms
- What: Production workflows for periodic corpus-wide LLM annotation, clustering, and query generation—complete with data versioning, privacy, and governance.
- Potential products: “Latent Attribute Indexer” and “Cluster Studio” for taxonomizing attributes; audit logs; approval workflows.
- Dependencies: Cost-effective batch inference; privacy-preserving processing; drift detection and re-labeling strategies.
- Find-by-analogy features across verticals
- Sector: software engineering, legal, scientific literature, product design
- What: Search for items that share abstract structure with a query across surface differences (e.g., security incidents with the same kill-chain stage, code with the same concurrency pattern, case law with analogous reasoning).
- Potential products: Analogy search in IDEs and code hosts; legal research tools for reasoning patterns; literature search by methodological archetype.
- Dependencies: Domain-specific attribute ontologies; explainability of matches (why analogous); integration with existing workflows.
- Data decontamination and provenance by structure
- Sector: AI model training
- What: Identify training examples that share latent solution strategies with test sets (e.g., same proof template) to audit contamination and leakage.
- Potential tools: Structural-similarity detectors; batch screening pipelines before model training; RVA-based acceptance criteria.
- Dependencies: Access to solutions or latent-method labels; thresholds tuned to avoid over-pruning; compute budgets for large corpora.
- Policy and procurement standards using retrieval–verification asymmetry
- Sector: public policy, enterprise procurement
- What: Mandate RVA-style evaluations for search and RAG systems used in safety-critical contexts; set minimum standards for surfacing latent risks or failure evidence.
- Potential tools: Standardized RVA metrics and benchmark suites; audit guides for third-party systems.
- Dependencies: Community consensus on metrics; curated public benchmarks covering sensitive domains; governance frameworks.
- Personal “memory by scenario” in consumer apps
- Sector: consumer software, productivity
- What: Tip-of-the-tongue retrieval for personal notes, emails, and recordings, using fuzzy scenario recollections (“that meeting where someone pushed back on timelines calmly”).
- Potential products: Scenario-search in note-taking and email; voice assistants with latent memory retrieval.
- Dependencies: On-device or privacy-preserving indexing; compute-efficient reranking; user controls and transparency.
- Robust trust & safety for coded/implicit content
- Sector: platforms, regulators
- What: Detect evolving coded language and implicit harms proactively by monitoring latent clusters and their drift.
- Potential tools: Continuous attribute re-clustering; human review queues seeded by high-RVA gaps (where verifiers spot positives but retrievers don’t).
- Dependencies: Bias mitigation; appeals and remediation; careful taxonomy updates.
- Cross-lingual and low-resource oblique retrieval
- Sector: global platforms, multilingual enterprises
- What: Extend latent-attribute retrieval to multilingual corpora where surface cues are sparser; leverage shared attribute spaces across languages.
- Potential tools: Cross-lingual attribute extraction; alignment of attribute embeddings; culturally aware stance models.
- Dependencies: Multilingual LLMs; culturally calibrated annotation; evaluation datasets with verified cross-lingual relevance.
Notes on feasibility across applications
- Cost/latency: Many immediate applications rely on offline annotation plus lightweight retrieval; at query time, use LLM reranking selectively (e.g., top-100/300 pools) to bound cost.
- Data governance: Conversation logs, internal documents, and social data require privacy, consent, and compliance controls.
- Model availability: The paper uses frontier LLMs (e.g., GPT-5.2); practical deployments may substitute available high-reasoning models, trading accuracy for cost.
- Reliability: LLM-based labels and verifications must be audited; human-in-the-loop review is recommended where stakes are high.
- Distribution shift: Latent attributes and coded patterns drift; plan for re-annotation and model refresh cycles.
Glossary
- agentic multi-hop search: An iterative search strategy where an LLM plans multi-step queries and reading actions to gather evidence across hops. "query rewriting, agentic multi-hop search, and bigger and better embedding models."
- agentic retrieval: Retrieval pipelines that use LLM “agents” to plan, reformulate, and read documents across steps. "For agentic retrieval, we evaluate two types of pipelines"
- Analogue queries: Queries seeking documents that share an abstract pattern or archetype with the query despite different surface topics. "Analogue queries seek all documents that share an archetype with the content of the query"
- ANCE: A dense retrieval training approach that mines “hard negatives” from an ANN index to improve learning. "ANCE showed that realistic hard negatives from an approximate nearest-neighbor index substantially improve dense retriever training"
- approximate nearest-neighbor index: Data structure and methods for fast similarity search approximating nearest neighbors in high-dimensional spaces. "realistic hard negatives from an approximate nearest-neighbor index"
- BM25: A classical lexical scoring function for information retrieval that ranks documents by term frequency and document length normalization. "BM25 is mostly not competitive,"
- candidate pool: A set of documents collected (often from multiple retrievers) for downstream reranking or verification. "we construct a candidate pool by taking the union"
- ColBERT: A late-interaction retrieval model that matches token-level embeddings while enabling precomputed document representations. "ColBERT introduced late interaction"
- cosine similarity: A vector similarity measure commonly used to rank documents by angle between embedding vectors. "retrieve by cosine similarity"
- dense retriever: A retrieval model that maps queries and documents to dense vector embeddings for similarity search. "the state-of-the-art dense retriever Gemini-2-Embedding"
- dual-encoder paradigm: A retrieval architecture with separate encoders for queries and documents enabling offline indexing and fast ANN search. "DPR popularized the supervised dual-encoder paradigm"
- gold documents: Ground-truth relevant documents used as positives in evaluation or injected into pools to bound performance. "along with an injection of gold documents"
- hard distractors: Non-relevant documents that are intentionally challenging and semantically similar to the query to stress retrievers. "a very large pool of hard distractors infused with the gold results"
- hard negatives: Challenging non-relevant examples used in training retrieval models to improve discrimination. "realistic hard negatives"
- late interaction: A retrieval approach that preserves token-level interaction signals between query and document representations at scoring time. "late interaction models"
- listwise ranker: A ranking method that scores or orders a set of candidates jointly rather than pairwise or pointwise. "as a listwise ranker"
- listwise reranking: Reranking candidates using a listwise objective or algorithm to produce a refined ordering. "a tournament-style listwise reranking algorithm"
- long-tail corpora: Collections dominated by rare or niche content where relevant items are infrequent and harder to surface. "over real long-tail corpora"
- meta-program: An abstract reasoning or solution strategy that multiple problems instantiate, independent of surface details. "identifies the underlying meta-program of each solution"
- multi-hop agent: An LLM-controlled search pipeline that performs multiple search-and-read hops to iteratively refine results. "GPT-5.2 Multi-Hop Agent"
- multi-vector late interaction model: A model that represents queries/documents with multiple vectors to capture fine-grained matching signals in late interaction. "a recent multi-vector late interaction model, LateOn"
- NDCG@10: Normalized Discounted Cumulative Gain at rank 10; a graded relevance metric emphasizing high-ranked results. "NDCG@10"
- obliqueness: A property of queries where relevance depends on latent attributes with little surface expression, making retrieval hard. "three mechanisms through which obliqueness may arise"
- Oracle GPT-5.2 Tournament: A strong listwise reranking method using GPT-5.2 in a tournament fashion over a large candidate pool (with gold injection) to approximate an upper bound. "Oracle GPT-5.2 Tournament"
- parametric knowledge: Information stored in an LLM’s parameters (as opposed to retrieved), which can be leveraged during generation or rewriting. "LLM parametric knowledge"
- PLAID algorithm: An indexing and retrieval algorithm supporting efficient late-interaction scoring. "for indexing with the PLAID algorithm"
- pooling (TREC): Evaluation practice of judging only the union of top results from multiple systems to approximate ground truth efficiently. "This is inspired by pooling"
- pool scaling experiment: An evaluation where the size of the candidate pool is increased to study performance of retrievers and rerankers. "we run a pool scaling experiment"
- query decomposition: Breaking a complex query into simpler sub-queries to guide multi-hop search. "iteratively applies query decomposition and document reading"
- query rewriting: Reformulating a user query to better match retrieval models and evidence sources. "query rewriting pipelines"
- Recall@10: The fraction of relevant documents (or success rate for single-target tasks) retrieved in the top 10. "Recall@10"
- retrieval--verification asymmetry: The gap where powerful verifiers can recognize relevance but scalable retrievers fail to surface relevant items. "the retrieval--verification asymmetry"
- reranker: A model used to reorder an initial set of retrieved candidates for better accuracy. "The oracle reranker generally does well"
- sublinear (time): Algorithmic complexity growing slower than linearly with corpus size, crucial for scalable retrieval. "should be sublinear in the corpus size"
- tip-of-the-tongue queries: Queries based on partial, lossy recollections that target a specific obscure passage. "tip-of-the-tongue queries"
- top-: The first k results returned by a system; a common cutoff for evaluation and pooling. "top-"
- TREC (Text REtrieval Conference): A long-running IR evaluation initiative that established standard practices like pooling. "TREC's standard approach for evaluating retrievers"
- zero-shot robustness: A model’s ability to generalize to unseen tasks/domains without task-specific training. "zero-shot robustness remains a distinct problem"
Collections
Sign up for free to add this paper to one or more collections.

