- The paper introduces BRIGHT-PRO, a benchmark that annotates multi-aspect reasoning evidence to better evaluate retrievers.
- It presents RTriever-Synth, a synthetic data pipeline that fine-tunes retrievers using aspect-decomposed positives and positive-conditioned hard negatives.
- Experimental results demonstrate that aspect-aware training significantly improves retrieval performance in both static and agentic search settings.
Rethinking Reasoning-Intensive Retrieval: Evaluation and Training for Agentic Search Systems
Introduction
The paper "Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems" (2605.04018) addresses fundamental limitations in current Information Retrieval (IR) methods for multi-step, reasoning-intensive queries. As LLM-based agentic search systems become prevalent, effective retrieval of complementary evidence tailored to deep analytical tasks becomes essential. This paper identifies key bottlenecks: (1) benchmarks with restricted gold passage coverage and shallow aspect annotation that fail to capture true evidence diversity, and (2) synthetic corpora and training regimes optimizing for single-passage relevance rather than holistic, multi-aspect reasoning support. The authors propose two innovations: the BRIGHT-PRO benchmark, which models queries as decomposable aspect-portfolios accompanied by richly annotated evidence; and RTriever-Synth, a synthetic data pipeline that enables fine-tuning retrievers to select complementary, aspect-aligned evidence using positive-conditioned hard negatives. Together, these contributions frame and advance the evaluation and optimization of retrievers in agentic, iterative deep-research environments.
BRIGHT-PRO: Benchmarking Complementary Evidence Retrieval
BRIGHT-PRO extends the BRIGHT StackExchange benchmark by incorporating dense, multi-aspect annotation for each query. Field experts identify and weight reasoning aspects, collect aspect-specific positive evidentiary passages, and iteratively refine aspect schemas for precision and non-overlap. The annotation protocol produces aspect granularities that map explicitly to sub-problems and modes of inference critical for high-quality synthesis, rather than loosely-defined topical clusters. The resulting corpus enables evaluation in two dimensions:
- Static setting: Each retriever is assessed on its ability to retrieve a ranked list of passages covering the full aspect portfolio per query, penalizing aspect redundancy and rewarding coverage.
- Agentic setting: Retrievers are integrated into LLM-based agents operating under fixed- and adaptive-round protocols. This evaluates interaction efficiency, coverage completeness, and response quality in a realistic scenario where the agent iteratively issues and refines search queries on an evolving evidence frontier.
Evaluation metrics such as a-nDCG@k (aspect-normalized discounted cumulative gain) and weighted aspect recall directly operationalize multi-aspect portfolio retrieval, exposing the limitations of single-view-point NDCG as previously used.
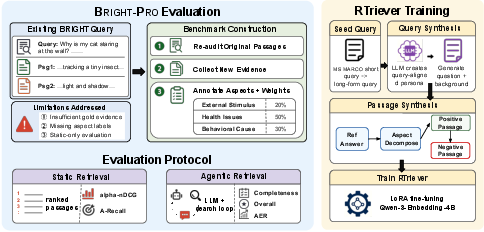
Figure 1: BRIGHT-PRO augments BRIGHT with re-audited gold passages and reasoning-aspect-level labels, enabling retriever evaluation under both static and agentic search protocols; RTriever-Synth generates aspect-decomposed positives and hard negatives for LoRA fine-tuning.
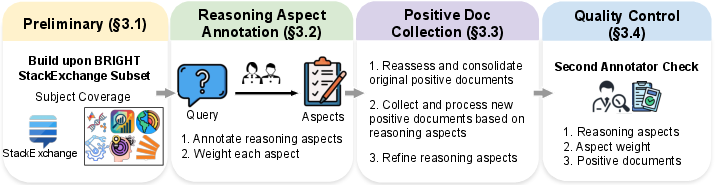
Figure 2: Construction pipeline for BRIGHT-PRO, from reassessment of original documents to aspect annotation, weighted importance assignment, and positive collection.
Training Reasoning-Intensive Retrievers: RTriever-Synth and RTriever-4B
Existing synthetic corpora—such as those derived from MS MARCO—enforce a single-positive, hard-negative paradigm, inadvertently encouraging models to overfit single-hop factual retrieval rather than diverse evidence construction. RTriever-Synth corrects this by:
- Generating analytical, deep-research-style queries from MS MARCO seeds using LLM-driven persona rewriting.
- Synthesizing comprehensive, reference answers which are then decomposed into orthogonal reasoning aspects.
- For each aspect, producing a distinct positive passage, ensuring that the collective set spans all facets of the answer.
- Synthesizing positive-conditioned hard negatives that are topically plausible but intentionally omit required aspect evidence, increasing discriminative training signal for aspect-aware retrieval.
This training corpus is then used to fine-tune Qwen3-Embedding-4B using LoRA adapters (RTriever-4B). Training adopts a contrastive InfoNCE objective across sampled (query, positive, negative) triplets, with in-batch negatives yielding additional regularization.
Experimental Results
Static Evaluation
Results on BRIGHT-PRO show that reasoning-specific retrievers outperform general-purpose models—even those with larger parameter counts—by 4–14 a-nDCG@25 points. RTriever-4B significantly improves over its Qwen3-Embedding-4B base, ranking ahead of all general-purpose embedders at similar or even higher scales. Aspect-aware metrics reveal that models trained without portfolio-level objectives (e.g., ReasonIR-8B, which is optimized for single-positive recall) fail to achieve balanced coverage despite reasonable NDCG.
Agentic Evaluation
Within deep-research agent loops, static ranking results only loosely predict response quality and efficiency. For instance, BM25, despite low static performance, becomes competitive in agentic scenarios, since LLM-issued followups bridge vocabulary disparities. Models like BGE-Reasoner-8B and DIVER-4B-1020 consistently yield high aspectual completeness and final answer quality, yet RTriever-4B is often the most efficient among smaller (<8B) retrievers due to superior evidence portfolio construction.
Notably, aspect-aware and agentic protocols (e.g., a-nDCG and AER) highlight phenomena invisible to standard metrics: speculation bias when evidence is missing, repetition bias (surfacing the same aspect repeatedly across rounds), and aspect tunnel vision (focusing solely on major aspects while ignoring minor but needed ones). Early termination failures and excessive hypothesis hopping are also surfaced—outcomes that would be invisible in static-only evaluation.
Qualitative Patterns and Failure Modes
Qualitative analysis exposes distinct retriever-agent dynamics. Efficient retrievers facilitate rapid coverage of high-weighted aspects, shortening reasoning traces and enabling agents to stop early. In contrast, under aspect deprivation, LLM agents confabulate or produce speculative answers untethered from any gold evidence. Repetition and tunnel vision failures reinforce the need for aspect-diversity-aware training objectives in retrieval modules. Examples in the paper demonstrate both successful and pathological cases, with detailed trace alignment across rounds, query refinements, and aspect coverage progression.
Implications and Future Directions
The framework established in this work mandates a paradigm shift: retrievers for agentic search must be constructed and assessed in context, with sensitivity to the multi-aspect, multi-document nature of complex reasoning queries. This carries clear implications:
- Training: Aspect-decomposed and positive-conditioned datasets are necessary to align retriever representations with real-world analytical demands. Future work can extend to multi-positive objectives, aspect-aware negative mining, and hybrid human-LLM annotation pipelines for data efficiency.
- Evaluation: Deployment-ready retrievers must be assessed not just by top-k recall/NDCG, but by efficiency and completeness metrics in agent-in-the-loop settings.
- System Design: End-to-end agent performance is contingent not on static retriever ranking, but on interaction between retrieval behavior and system-level planning and synthesis, warranting joint, co-adaptive development.
The approach is extensible to new domains by broadening BRIGHT-PRO-like aspect portfolios, and by integrating portfolio-level curation into real-world IR system evaluation at scale.
Conclusion
This paper brings critical rigor to the evaluation and training of reasoning-intensive retrievers in agentic search systems. By introducing aspect-structured benchmarks and synthetic corpora for complementary evidence selection, and by measuring performance in agent-in-the-loop protocols, the work establishes that static, single-passage metrics are insufficient. The BRIGHT-PRO benchmark and RTriever-Synth pipeline create actionable standards for retriever portfolio quality, efficiency, and multi-aspect reasoning coverage, fundamentally raising the bar for retrieval models deployed in complex research automation systems.
Reference: "Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems" (2605.04018).

