- The paper introduces MUSE, which resolves manifold misalignment by decoupling semantic and structural gradients using topological orthogonality.
- It employs a novel Synergistic Transformer Block that routes topology loss to attention projections and semantic loss to value projections with stop-gradient isolation.
- Empirical evaluations on ImageNet-1K and ADE20K demonstrate state-of-the-art performance with a gFID of 3.08 and 85.2% linear probing accuracy, surpassing specialist models.
MUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality
Introduction and Motivation
The architectural unification of vision models—serving both understanding (semantic abstraction) and generation (pixel-level reconstruction)—has exposed critical optimization bottlenecks. Prior attempts at unified visual tokenization predominantly operate under a zero-sum paradigm: improvements in one modality degrade the other. The primary cause, as diagnosed, is Manifold Misalignment, an inherent gradient antagonism between objectives for high-fidelity generation and robust semantic understanding. The latent space optimization vector for pixel-level tasks (favoring surface details) is typically nearly orthogonal to, and thus in direct conflict with, the vector for semantic tasks (favoring invariance and abstraction).
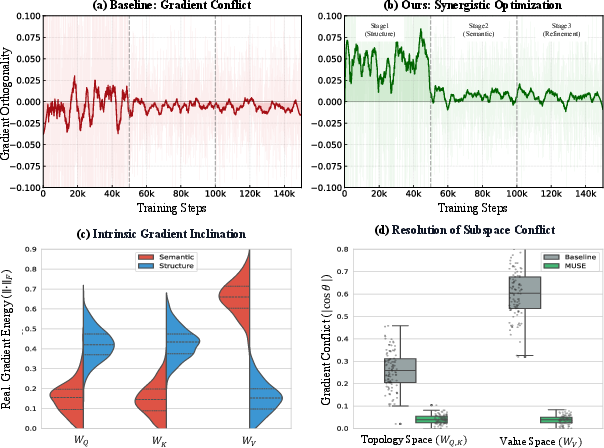
Figure 1: Verification of Manifold Orthogonality. (a-b) Naive optimization suffers from gradient conflict, with negative cosine similarity between gradients for semantics and generation; MUSE enforces near-orthogonality, yielding synergistic learning. (c-d) Violin plots show semantic gradients localize to WV and structural ones to WQ,K, confirming architectural decoupling.
The MUSE framework proposes that this conflict can be fundamentally resolved by physically decoupling the semantic and structural (topological) objectives in parameter space. It leverages the geometric insight that semantics and structural information can be mapped onto orthogonal subspaces of a Transformer.
The paper articulates a rigorous information-theoretic motivation: the objective is to maximize I(Z;X,Y), the mutual information between latent representation Z, inputs X, and semantics Y. By introducing an explicit structural latent S, the decomposition formalizes a curriculum where topology should be prioritized as geometric foundation, followed by semantic injection conditioned on S, and residuals left to the decoder:
I(Z;X,Y)≈I(Z;S)+I(Z;Y∣S)+I(Z;X∣S,Y).
This justifies the MUSE training protocol and the architecture that enforces manifold alignment through gradient orthogonality.
MUSE Architecture
MUSE implements Topological Orthogonality through a novel Synergistic Transformer Block, which enforces an explicit routing of gradient flow:
- Structural Topology Alignment: Gradients from a topology loss are routed to attention projections (WQ,WK), optimizing the adjacency matrix governing attention and thus structural relationships.
- Active Semantic Anchoring: Semantic gradients (from mutual information-driven contrastive losses) update only the value projections (WQ,K0), modulating content abstraction.
- Physical gradient isolation with a stop-gradient operator prevents mutual interference.
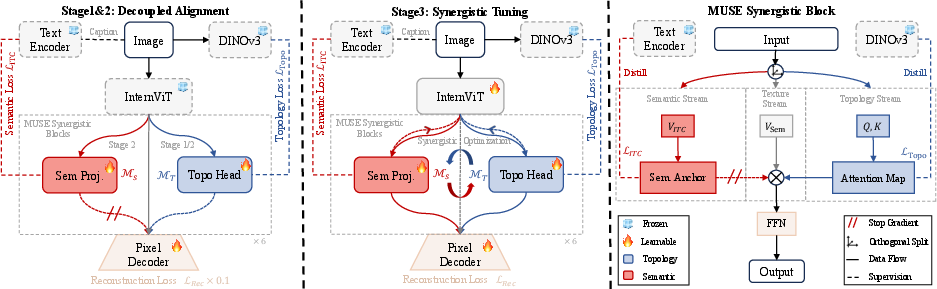
Figure 2: The MUSE architecture and training protocol. Topology alignment (Stage 1) trains attention topology via a structural teacher (DINO). Semantic injection (Stage 2) anchors token values via contrastive loss, preserving topology. Synergy (Stage 3): Unfrozen, unified optimization yields mutual reinforcement.
Empirical Evaluation and Analysis
Quantitative Resolution of the Trade-Off
MUSE demonstrates state-of-the-art generation and understanding on benchmarks such as ImageNet-1K and ADE20K. Its unified tokenizer is the first to simultaneously reach a gFID of 3.08 and linear probing accuracy (85.2%) that surpasses even specialist teacher models (InternViT-300M, 82.5%). Unlike previous unified models, MUSE does not sacrifice semantic integrity for generative power, but instead achieves mutual reinforcement.
Gradient Dynamics and Ablation
Analysis of gradient cosine similarity demonstrates that MUSE eliminates destructive interference, confirming the Gradient Orthogonality Hypothesis. Ablation studies confirm that naïvely mixing objectives or using only loss regularization is insufficient—architectural decoupling in the Synergistic Block is necessary and sufficient for optimal performance.
When integrated with a Dual-Condition unified multimodal model, MUSE consistently outperforms prior unified frameworks (e.g., UniLIP, Janus-Pro), with larger gains observed in tasks requiring fine spatial reasoning, structural segmentation, and complex editing (background consistency, sequential manipulation).
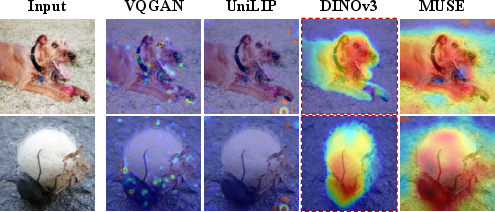
Figure 3: Visual Analysis of Attention Maps across Tokenizers. MUSE mirrors DINO's ground-truth-like object delineation (red boxes), validating topological alignment.

Figure 4: Qualitative task results. MUSE preserves edge sharpness and texture for reconstruction, enables precise semantic attribute binding in generation, and strictly maintains spatial consistency in editing.
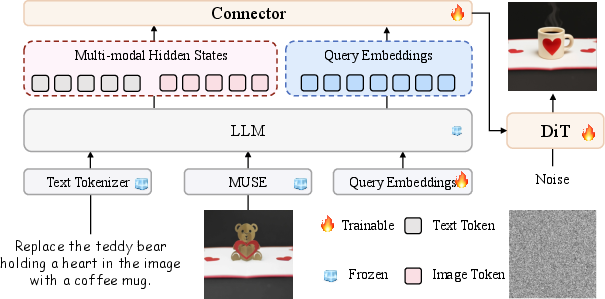
Figure 5: MUSE unified multimodal architecture: Dual-Condition connector aggregates multimodal hidden states and queries to condition the diffusion-based generator.

Figure 6: Comparative attention topologies. VQGAN attends to high-frequency background; UniLIP is spatially imprecise; MUSE attends semantically and structurally, matching DINO.

Figure 7: Qualitative comparison: MUSE generates complex, spatially aligned text-to-image samples.

Figure 8: Qualitative comparison: MUSE edits images with high instruction faithfulness and layout preservation.
Sensitivity and Efficiency
Sensitivity analysis shows MUSE's semantic accuracy peaks at WQ,K1 learnable queries, revealing a semantic density optimum. The Synergistic Block induces negligible (WQ,K23%) parameter and computational overhead compared to baseline unified models, yet provides major improvements over costly two-stream approaches.
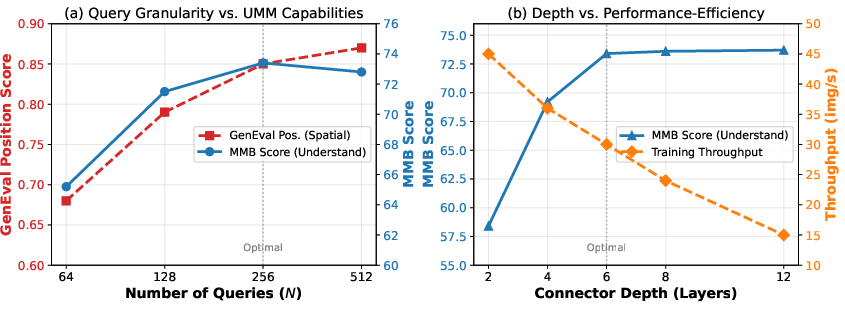
Figure 9: Sensitivity Analysis. Increasing query count improves reconstruction but degrades semantics past WQ,K3; connector depth saturation occurs at 6 layers with minimal further gain.
Broader Implications
Practically, MUSE enables unified models with competitive generation, robust global understanding, and fine-grained spatial control—all in a single codebook, facilitating more capable and efficient multimodal AI. Theoretically, the results substantiate that representational and optimization bottlenecks in multitask models are not intrinsic, but a result of architectural entanglement—resolvable via coordinated parameter-space decoupling. This principle is extensible to other multimodal and multi-objective learning systems.
Conclusion
MUSE provides compelling evidence that manifold misalignment is the bottleneck for unified visual tokenization, and that architectural enforcement of gradient orthogonality is both necessary and sufficient for achieving mutual reinforcement of generation and understanding. The success of MUSE implies that future unified multimodal architectures should systematically decouple conflicting optimization objectives, bridging task-specialist performance with a unified, efficient architecture. This insight will steer the next generation of scalable, controllable multimodal foundation models.
Reference:
"MUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality" (2605.05646)

