- The paper introduces MacTok, a continuous tokenizer that prevents posterior collapse via innovative dual masking and hierarchical representation alignment.
- MacTok achieves state-of-the-art generation and reconstruction on ImageNet benchmarks, outperforming KL-VAEs even with token counts as low as 64.
- The framework’s integration of DINO-guided semantic masking and multi-scale alignment preserves semantic integrity and enhances downstream probing accuracy.
MacTok: Robust Continuous Tokenization for Image Generation
Motivation and Background
Continuous image tokenization is critical for high-throughput visual generative modeling, enabling effective training and inference by compressing images into informative latent representations. KL-based continuous tokenizers, particularly KL-VAEs, suffer from posterior collapse, especially under strong compression (i.e., when using few tokens), where the latent space degenerates into an isotropic Gaussian prior and loses meaningful semantics. Previous methods either rely on delicate KL annealing or hyperparameter tuning, which offer only transient stabilization and fail to fundamentally prevent collapse. State-of-the-art discrete tokenizers have achieved compactness via improved codebook learning, but continuous compressors lag due to lack of robust countermeasures for latent degeneration.
MacTok Framework
MacTok is a 1D continuous tokenizer that integrates dual masking schemes and hierarchical representation alignment to prevent posterior collapse and enforce the encoding of semantic information into compact latent vectors.
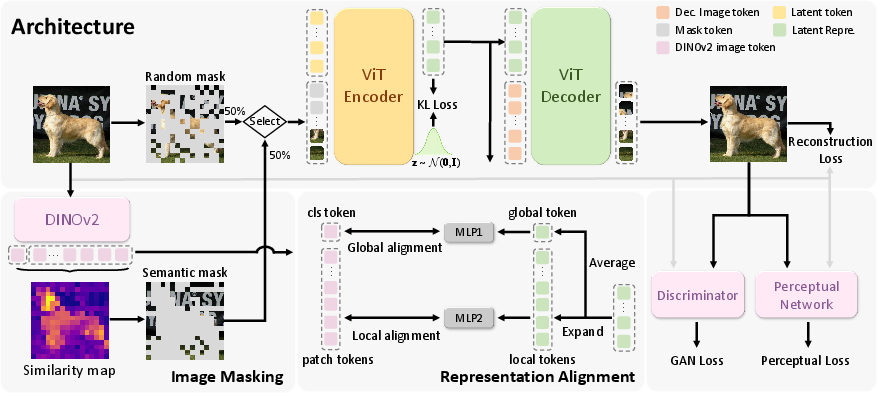
Figure 1: Overview of the MacTok framework, highlighting masked transformer encoding, semantic guidance via DINO, and multi-scale feature alignment.
Architecture
A ViT-based encoder partitions images into patches and concatenates learnable latent tokens with image tokens. The encoder outputs are parameterized as Gaussian distributions and regularized with KL divergence. The decoder reconstructs images from sampled latents and reconstruction tokens. 2D/1D positional embeddings ensure spatial coherence.
Masking Strategies
- Random Masking: Random patch replacement with mask tokens forces the model to infer missing regions, ensuring essential information flows through latents and mitigating posterior collapse, as shown by improved KL stability and latent diversity.
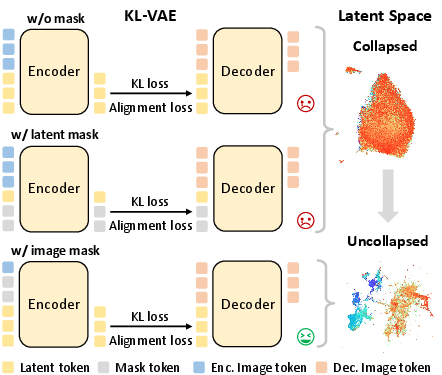
Figure 2: Comparative visualization of random masking effects; image token masking maintains latent diversity and prevents collapse.
- Semantic Masking: DINO-guided masking selectively occludes high-similarity regions (i.e., semantically important patches), compelling latent tokens to encode object-level structure and global context. This targeted corruption yields more discriminative latent embeddings.
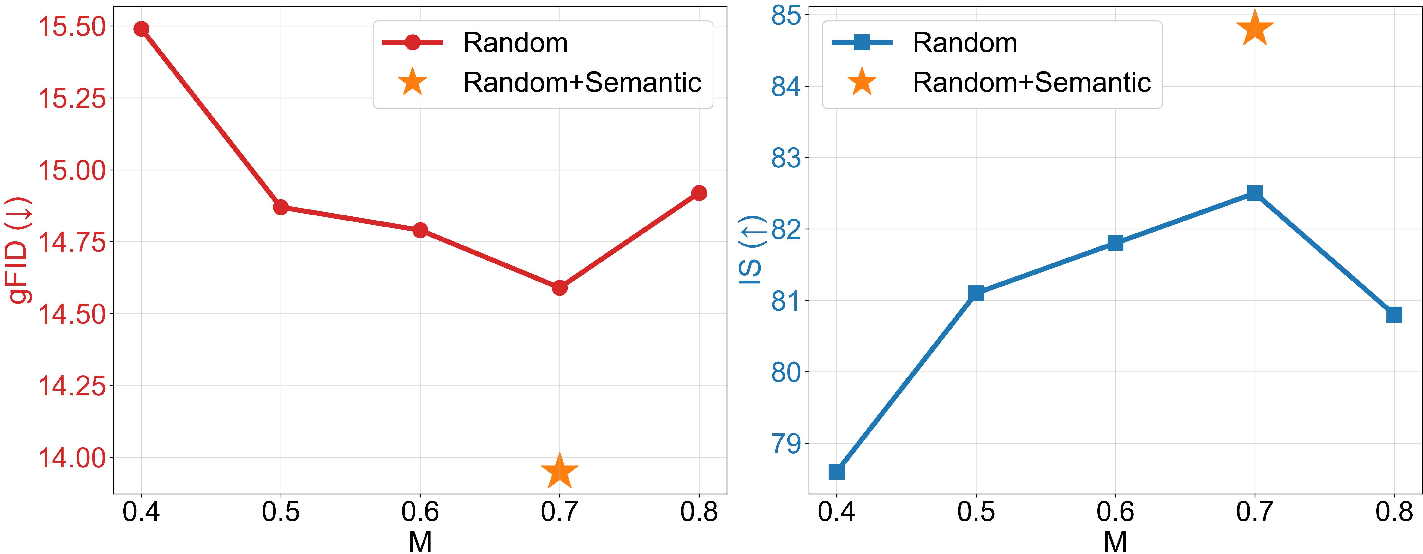
Figure 3: Generation performance of MacTok as a function of mask ratio and masking strategy.
Representation Alignment
Global and local alignment losses are imposed by projecting latents to match DINOv2 patch and classification tokens. The latent space is expanded to match regional granularity, and cosine similarity losses enforce structurally coherent and semantically clustered latent distributions.
Training Objectives
Combined loss consists of pixel-wise reconstruction, perceptual, adversarial, KL regularization, and representation alignment terms. Perceptual and adversarial branches ensure realism under generative modeling; representation alignment preserves semantic robustness across mask ratios and compression levels.
Empirical Results
Generation Quality
MacTok achieves competitive (and in several cases, state-of-the-art) generation FID (gFID) scores on ImageNet, outperforming baselines across both 256×256 and 512×512 benchmarks with up to 64× compression:
- SiT-XL/2 with MacTok: gFID 1.44 at 256×256 and SOTA 1.52 at 512×512 (with 128 tokens).
- Strong IS scores, e.g., IS=316.0 at 512×512.
Notably, MacTok maintains superior generation performance even as token counts decrease to 64/128, surpassing KL-based and VQ-based tokenizers that require 256–4096 tokens for comparable fidelity.

Figure 4: Visual samples of generative modeling on ImageNet at both 256×256 and 512×512 resolutions with 64/128 tokens.
MacTok achieves rFID of 0.43 (128 tokens) and 0.75 (64 tokens) at 256×256, ensuring robust reconstruction despite extreme compression. These scores outperform discrete tokenizers at equivalent or lower token counts.
Latent Space Analysis
Latent visualizations reveal:
- KL-VAE collapses to uninformative isotropic structure.
- MacTok with masking (but without alignment) yields compact, semantically enriched latents.
- Full MacTok with alignment achieves clear clustering, enhancing linear separability and downstream probing accuracy.
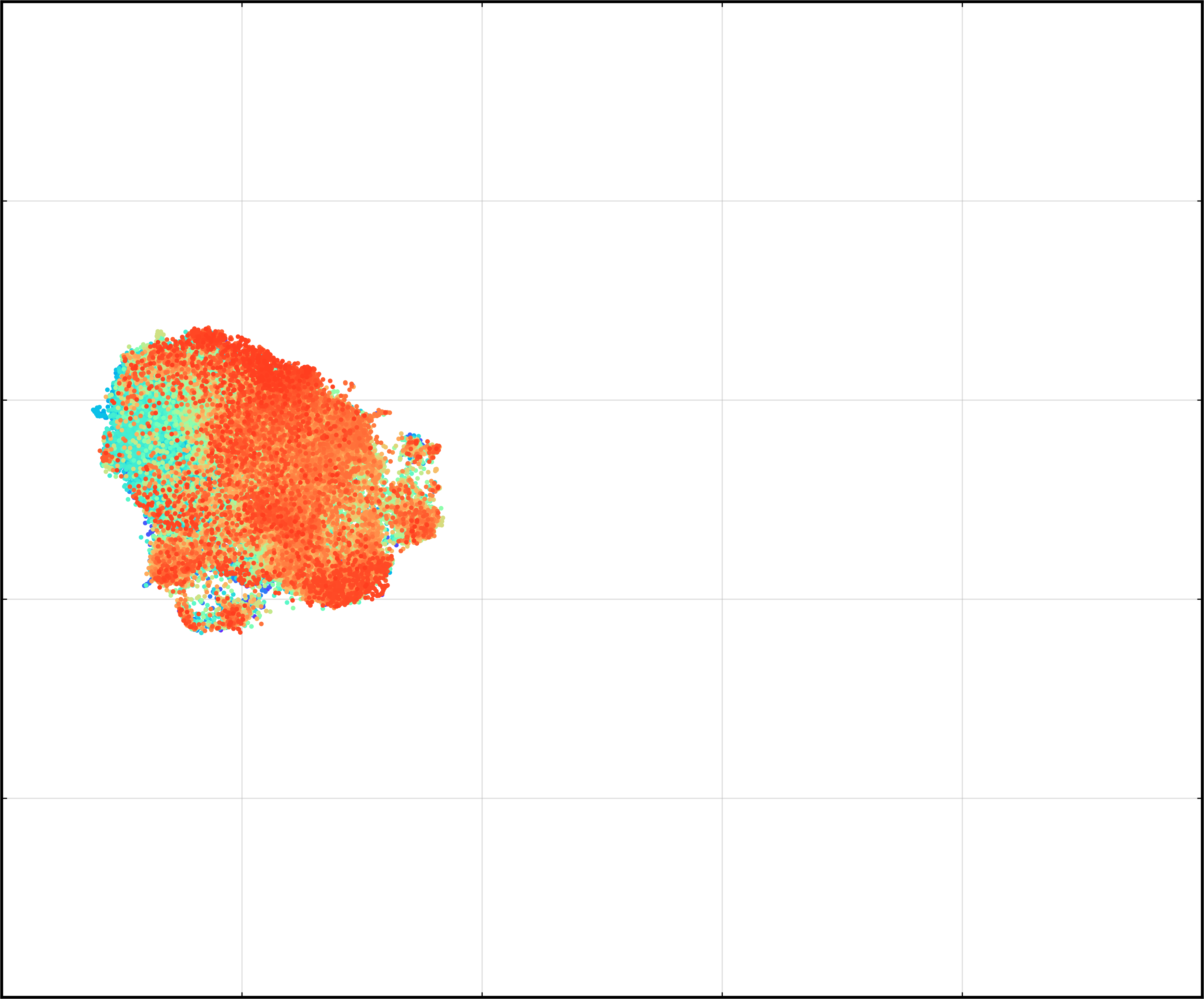
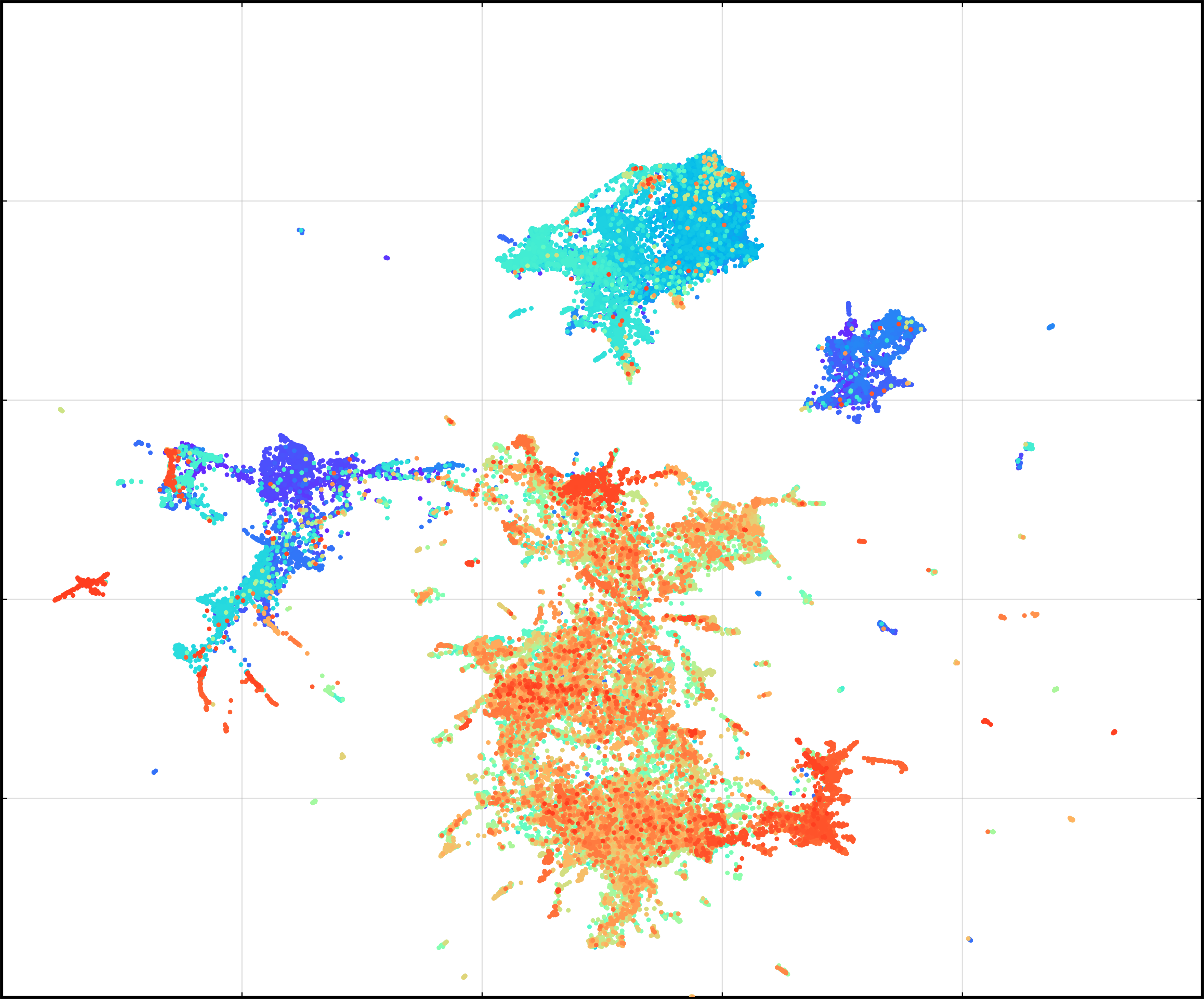
Figure 5: Visualization of latent space distributions with and without representation alignment.
Linear probing accuracy correlates strongly with generation metrics, evidencing preservation of semantic structure and effective compression.
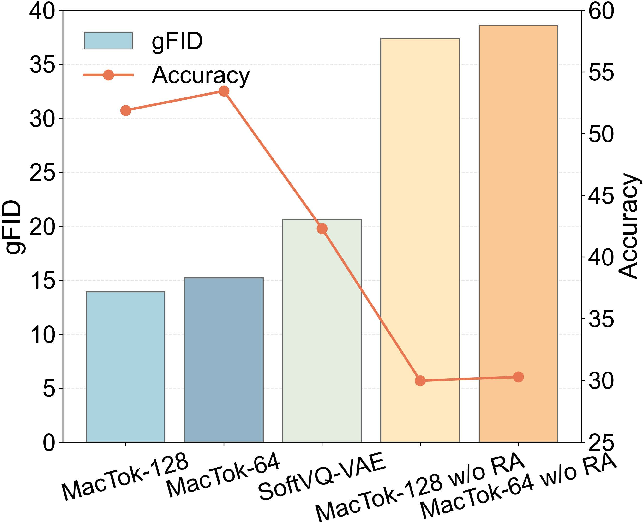
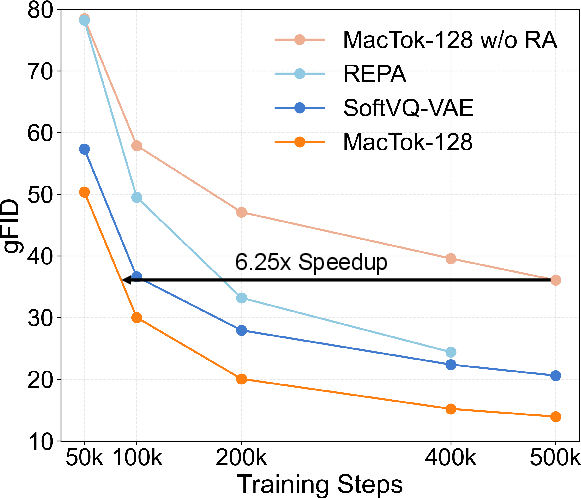
Figure 6: Relationship between gFID and probing accuracy; MacTok exhibits superior convergence and semantic retention.
Ablations
Mask ratio analysis indicates optimal generation performance at moderate masking (M=0.7), balancing information robustness and reconstruction fidelity. Equal random/semantic masking further boosts quality. Module ablations demonstrate the progressive gains achieved by random masking, local/global representation alignment, and semantic masking.
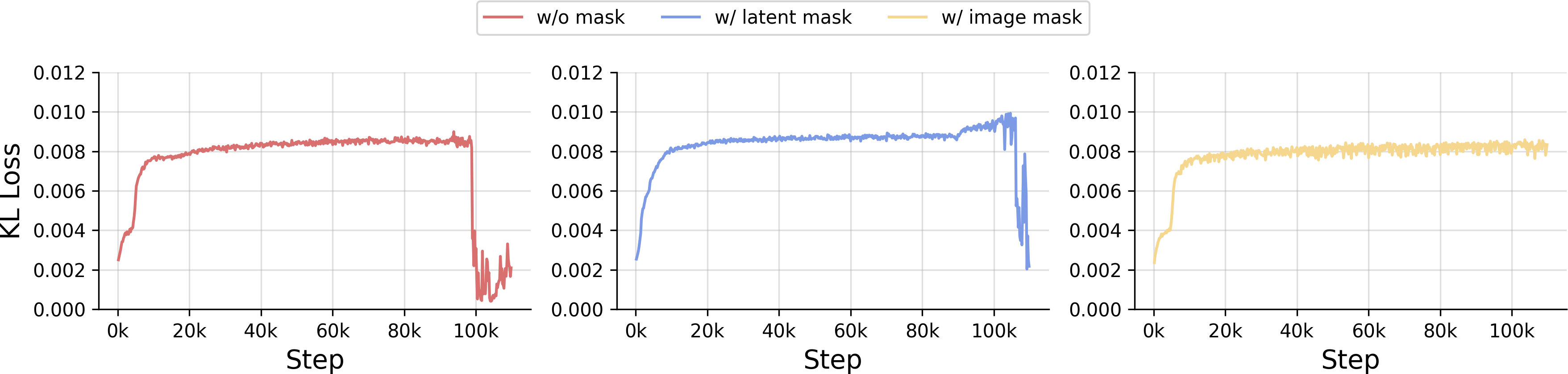
Figure 7: KL loss dynamics for various masking strategies, demonstrating only image token masking reliably prevents collapse.
Theoretical Implications
Masking fundamentally shifts the corrupted ELBO, increasing effective mutual information between input and latent, and forcing Z to encode context features that cannot be trivially reconstructed. This closes the loophole exploited by collapsed posteriors and maintains generative quality under strong KL regularization. The combined representation alignment systematically structures the latent space, linking local and global semantics, fostering richer conditional generation and more efficient downstream tasks.
Practical Impact and Future Directions
MacTok sets a new standard for continuous tokenization efficacy, enabling generative models to operate efficiently with minimal token budgets while retaining high-fidelity reconstruction and semantic integrity. The prevention of posterior collapse via mixed masking and semantic guidance is broadly extensible to other latent generative frameworks, potentially impacting low-bandwidth visual synthesis, efficient image search, and scalable diffusion modeling.

Figure 8: MacTok reconstruction results with 64 tokens demonstrating preservation of global and local structure.
Future research may investigate adaptive mask scheduling, hierarchical multimodal alignment, and deployment in large-scale conditional generation scenarios (e.g., text-to-image diffusion), as well as integration with domain-specific semantic encoders.
Conclusion
MacTok advances KL-based continuous tokenization by robustly preventing posterior collapse and efficiently structuring latent space via image-level masking and multi-scale feature alignment. Empirical results validate superior generative quality and reconstruction at unprecedented compression levels, and theoretical analysis substantiates the information preservation mechanism. MacTok's design principles are likely to influence further developments in visual generative compression and latent modeling (2603.29634).

