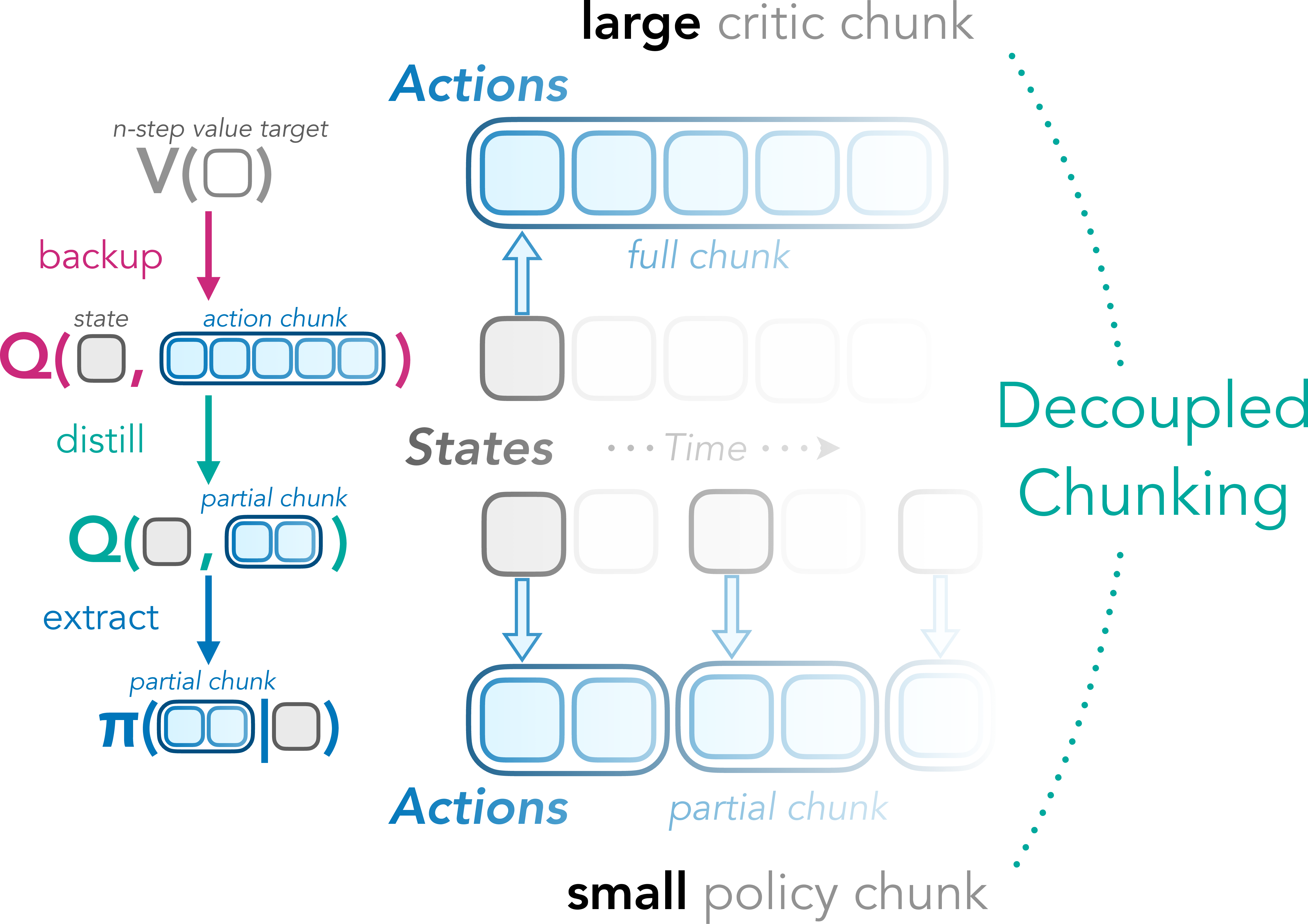
Decoupled Q-Chunking
Abstract: Temporal-difference (TD) methods learn state and action values efficiently by bootstrapping from their own future value predictions, but such a self-bootstrapping mechanism is prone to bootstrapping bias, where the errors in the value targets accumulate across steps and result in biased value estimates. Recent work has proposed to use chunked critics, which estimate the value of short action sequences ("chunks") rather than individual actions, speeding up value backup. However, extracting policies from chunked critics is challenging: policies must output the entire action chunk open-loop, which can be sub-optimal for environments that require policy reactivity and also challenging to model especially when the chunk length grows. Our key insight is to decouple the chunk length of the critic from that of the policy, allowing the policy to operate over shorter action chunks. We propose a novel algorithm that achieves this by optimizing the policy against a distilled critic for partial action chunks, constructed by optimistically backing up from the original chunked critic to approximate the maximum value achievable when a partial action chunk is extended to a complete one. This design retains the benefits of multi-step value propagation while sidestepping both the open-loop sub-optimality and the difficulty of learning action chunking policies for long action chunks. We evaluate our method on challenging, long-horizon offline goal-conditioned tasks and show that it reliably outperforms prior methods. Code: github.com/ColinQiyangLi/dqc.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to make good plans in tricky, long tasks by breaking actions into small groups called “chunks.” The authors show a new way to learn faster and more reliably by letting one part of the system look far ahead (to reduce mistakes that build up over time) while another part chooses short, reactive moves so it can still adapt to what’s happening right now. They call this idea Decoupled Q-Chunking (DQC).
The big questions the authors ask
- How can we reduce the “bootstrapping bias” in reinforcement learning—errors that grow when a system learns by trusting its own imperfect future predictions?
- How can we use “chunked” value estimates (which help with long tasks) without forcing the policy to commit to long, open-loop action sequences that are hard to learn and not very reactive?
- Can we prove when chunking is safe and beneficial?
- Does this approach work better in tough, long-horizon tasks learned from offline data?
Key ideas and terms (in simple language)
Before explaining the method, here are a few important concepts in everyday words:
- Temporal-Difference (TD) learning and Q-learning: Think of a student grading their own homework using last week’s answers. If last week’s answers were wrong, mistakes can snowball. That’s bootstrapping bias.
- Critic and policy: The critic scores how good a plan is; the policy uses those scores to pick actions.
- Open-loop vs. closed-loop:
- Open-loop: You commit to a whole plan upfront and follow it without reacting (like starting a road trip and refusing to adjust the route).
- Closed-loop: You choose your next step based on what you currently see (like checking GPS at each turn).
- Action chunks: Instead of choosing one tiny action at a time, you choose short sequences (like planning the next few turns of a drive), which helps spread rewards back faster in long tasks.
- Offline reinforcement learning: You learn only from a fixed dataset of past experiences, without new interactions.
How does Decoupled Q-Chunking (DQC) work?
Imagine planning a long trip:
- A “long-horizon critic” judges the quality of longer mini-plans (chunks), say the next 5 turns, which helps look further ahead and reduce the “snowballing errors.”
- But asking the policy to output all 5 turns at once makes it less responsive and harder to learn.
DQC’s key twist is to decouple the two:
- The critic still evaluates long chunks (good for learning values over long tasks).
- The policy only needs to pick a short partial chunk (even just the next action), so it stays reactive and easy to train.
To connect the two, DQC creates a “distilled critic” for partial chunks:
- When scoring a partial chunk (like the first 1–2 actions), it assumes the rest of the chunk will be finished in the best possible way later.
- This is like saying, “If you start this way, what’s the best we could finish the plan?” It guides the policy to choose good short moves that can grow into good long plans.
In practice, the system:
- Learns a chunked critic that evaluates long action sequences using offline data.
- Builds a distilled critic that “optimistically” scores partial sequences by imagining the best way to complete them.
- Trains a policy to output only short chunks using feedback from the distilled critic.
- Executes actions in a closed-loop fashion (one small step at a time), staying reactive to the current situation.
What did they prove?
The paper adds theory that explains when chunking is reliable and how much error it may introduce:
- Open-loop consistency: If replaying chunked actions without reacting (open-loop) leads to similar outcomes as seen in the data, then:
- The value estimates learned with chunked critics have bounded error.
- The policy learned from a chunked critic is close to the best possible (within a clear, small gap), especially under a stronger form of this condition.
- Chunking vs. standard multi-step returns: In many cases, chunked critics beat the usual “n-step returns,” especially when the offline data is not very close to optimal. Chunked critics avoid certain off-policy biases that plague n-step returns.
- Closed-loop execution helps: Even if you learn with chunks, you can execute in closed-loop (take just the first action of each chunk, then re-plan). Under reasonable conditions, this gets you close to optimal and can be better than sticking to long open-loop sequences.
- Bounded variability: If the data sources are reasonably consistent about how “good” outcomes are (not wildly unpredictable), then the performance gap gets even tighter.
In short, the theory shows when chunking is safe and when it should be preferred, and it explains why choosing short, reactive actions at run time is a good idea even if the critic evaluates longer sequences.
What did they find in experiments?
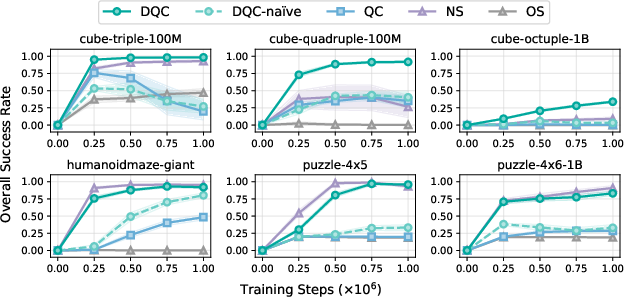
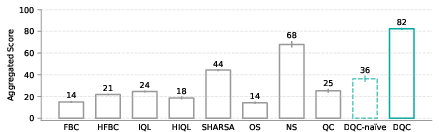
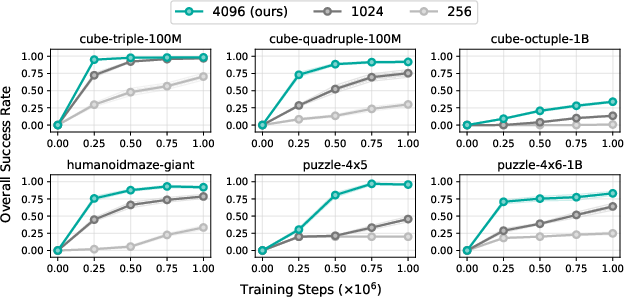
The authors tested DQC on OGBench, a set of difficult, long-horizon, goal-conditioned tasks using offline data. DQC outperformed all baselines on the hardest environments. This suggests DQC is not only theoretically grounded but also practically strong in real long-term planning problems.
Why this is important
Long, complex tasks—like robotics, games, or multi-step goals—are hard because small prediction errors can pile up, and policies need to stay reactive. DQC:
- Reduces error build-up by learning with long chunks.
- Keeps decision-making simple and responsive by letting the policy choose short chunks.
- Works well with offline data, which is safer and cheaper than trial-and-error in the real world.
Final takeaway
DQC shows a smart split of responsibilities: let a long-horizon critic think far ahead, but keep the policy’s job small and reactive. The authors back this up with solid math and strong experiments. This could make learning long, careful plans more reliable—helping robots, game agents, and other systems handle complicated tasks with fewer mistakes and more flexibility.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Practical verification of open-loop consistency (OLC): The theory hinges on weak/strong -OLC in total variation distance, but the paper does not provide data-driven tests, estimators, or procedures to measure from finite, continuous-state/action datasets, nor strategies to improve OLC via data filtering, augmentation, or reweighting.
- Strength and realism of OLC assumptions: Strong OLC requires bounds for every action chunk in the support, which may be unrealistic for typical offline datasets (especially with reactive behavior policies). Clarify when OLC is expected to hold and how violations affect DQC in practice.
- Bounded optimality variability (BOV) estimation: The closed-loop guarantees rely on local/global -BOV, yet the paper does not explain how to detect mixture components, estimate and from data, or validate the mixture decomposition assumption when the sources are unknown.
- Function approximation and optimization error: The theoretical results assume exact solutions to Bellman equations. There are no convergence, stability, or error propagation guarantees for neural function approximators, target networks, implicit value backups (expectile/quantile), or the distilled critic under bootstrapping and finite-sample noise.
- Guarantees for the “distilled” partial-chunk critic: The method “optimistically regresses” the partial-chunk critic from the full-chunk critic, but the paper does not prove that this produces a valid upper bound, preserves policy improvement, or controls overestimation bias. Formal analysis of optimism calibration and failure modes is missing.
- Calibrating implicit value backup (expectile/quantile): The choice of and the interaction between expectile/quantile backup and chunking are not analyzed theoretically. Provide guidelines or theory on how affects bias/variance, conservatism/optimism, and final policy quality.
- Deciding critic and policy chunk lengths: The paper offers no principled method to select or adapt the critic’s chunk length and the policy’s shorter chunk length. Study adaptive schedules, environment-dependent tuning, and criteria that trade off value propagation benefits against policy reactivity and tractability.
- Support coverage requirements: Many results assume contains optimal (or near-optimal) chunks. Investigate DQC’s behavior under poor coverage, derive guarantees with partial support, and explore integration with conservative or uncertainty-aware methods to mitigate extrapolation error.
- Comparison with importance-sampled multi-step returns: While the paper motivates chunking against off-policy bias, it does not provide theoretical or empirical comparisons to multi-step returns corrected via importance sampling (with truncation/variance control), nor hybrid schemes that combine both approaches.
- Closed-loop vs open-loop execution trade-offs: The theory bounds closed-loop execution suboptimality but still scales with or . Identify conditions or algorithms that yield tighter bounds, decide when to execute only the first action vs a partial chunk, and develop adaptive closed-loop/open-loop switching rules.
- Estimation in continuous spaces: OLC (TV distance) and BOV require distributional comparisons that are hard to estimate in high-dimensional, continuous spaces. Develop practical estimators (e.g., kernel-based, density ratio, conditional divergence) and sample complexity results for these diagnostics.
- Handling non-Markovian behavior policies and partial observability: The dataset can be non-Markovian, but the impact on chunked critics, distilled critics, and OLC/BOV conditions remains unclear. Extend DQC to POMDPs and provide theory/experiments on robustness to history-dependent behavior.
- Computational and memory costs: The paper does not analyze the complexity of training chunked critics and distilled critics for large , nor the scalability to high-dimensional action spaces. Provide profiling, complexity bounds, and engineering guidance for long-horizon, high-DOF control.
- Safety and risk under optimism: Optimistic backups can promote risky actions in offline settings. Develop risk-aware or conservative variants of the distilled critic (e.g., uncertainty penalties, safety constraints) and study safety-performance trade-offs.
- Robustness to reward scales and stochasticity: Rewards are assumed bounded in [0,1]; extend analysis to other scales and distributions. Examine robustness under heavy stochasticity, delayed rewards, and nonstationary dynamics.
- Tighter bounds beyond horizon factors: Current bounds scale unfavorably with and when . Explore structure-exploiting bounds (e.g., mixing times, concentrability coefficients, pathwise Lipschitzness) to reduce horizon blow-up.
- Interaction with conservative offline RL: The method does not address how to integrate DQC with conservative regularization (e.g., CQL-style penalties) or policy constraints to manage distribution shift. Study hybrids and their theoretical properties.
- Exploration in online settings: DQC targets offline RL; its impact on exploration and sample efficiency in online/offline-to-online regimes is untested. Investigate exploration strategies compatible with chunked/distilled critics.
- Dataset quality sensitivity: Provide systematic study of DQC under varying dataset optimality, noise, and OLC/BOV levels, including ablations that isolate the contributions of critic chunking, partial-chunk policy, and distilled optimism.
- Formal description and training details of the distilled critic: The paper lacks a precise objective defining the “optimistic regression” for partial chunks, how completions are enumerated or approximated, and how gradients propagate. Supply mathematical formulation, algorithms, and implementation details.
- Generalization beyond goal-conditioned tasks: The evaluation focuses on OGBench’s long-horizon, goal-conditioned offline tasks. Test DQC on standard continuous-control (e.g., D4RL locomotion), discrete control (e.g., Atari), and real-robot domains to assess breadth, reactivity benefits, and reproducibility.
- Statistical rigor in empirical results: Include significance testing, hyperparameter sensitivity, and ablations on chunk sizes, distilled critic parameters, and policy architecture to confirm robustness of reported gains and identify regimes where DQC underperforms.
- Measuring “policy reactivity” benefits: The paper claims improved reactivity with shorter policy chunks but does not quantify it. Develop metrics and experiments that isolate reactivity (e.g., perturbation response, reaction latency) and relate them to task performance.
Practical Applications
Immediate Applications
The following applications can be deployed with current tools and datasets, especially in offline RL settings where multi-step decision-making and sparse rewards make bootstrapping bias a real obstacle. Decoupled Q-Chunking (DQC) provides an immediate path to better value learning while keeping policies reactive and tractable.
- Industrial and warehouse robotics (Sector: robotics)
- Use case: Pick-and-place, bin packing, palletizing, and simple assembly tasks trained from logs of prior executions (human teleoperation or scripted policies), where long-horizon success depends on coordinated action sequences.
- Tools/products/workflows: Train a chunked critic over 3–10 step action sequences; deploy a reactive policy that outputs only the first action or a short partial chunk; integrate with ROS2 and simulation frameworks (Isaac Gym, Mujoco) and existing offline datasets (e.g., OGBench or custom warehouse logs).
- Assumptions/dependencies: Access to trajectory logs that have reasonable open-loop consistency or bounded optimality variability (BOV); support overlap with desired behaviors; safety gating and validation before deployment.
- Game AI from player replays (Sector: software/gaming)
- Use case: Learn long-horizon strategies (e.g., build orders, combo sequences, navigation macros) from human play data; deploy reactive agents that adapt at every step while benefiting from multi-step value propagation.
- Tools/products/workflows: Offline RL pipelines for chunked critics; policy distillation to partial-chunk action selection; integration with game simulators and replay parsers.
- Assumptions/dependencies: Large replay datasets with sufficient coverage of high-value sequences; the environment dynamics must be stationary enough that open-loop chunk evaluation remains credible.
- Sequential recommendation and engagement optimization (Sector: software/retail/media)
- Use case: Plan multi-step recommendation sequences (e.g., content playlists, product coupons) while keeping the policy reactive to user responses at each step.
- Tools/products/workflows: Train a multi-step chunked critic over recommendation sequences; use expectile/quantile implicit backups for robust value estimation; deploy partial-chunk policies that choose the immediate recommendation while leveraging the distilled multi-step value.
- Assumptions/dependencies: Logged data with good coverage and moderate BOV; careful offline-to-online validation and A/B testing to manage off-policy drift and safety constraints.
- Robotic process automation (RPA) and UI automation (Sector: software/enterprise IT)
- Use case: Learn multi-step action macros from clickstream logs (e.g., data entry, form handling) with reactive policies that adjust to UI changes at each step.
- Tools/products/workflows: Chunked critic evaluates macro sequences; partial-chunk policy outputs the next action only; integration with enterprise RPA platforms; offline RL training on recorded sessions.
- Assumptions/dependencies: Stable UI dynamics or robust perception; availability of consistent logs and adequate support overlap for target workflows; sandboxed evaluation prior to live deployment.
- Offline RL benchmarking and academic baselines (Sector: academia)
- Use case: Establish DQC as a baseline on long-horizon offline goal-conditioned tasks (e.g., OGBench); evaluate bootstrapping bias reduction and policy reactivity improvements over n-step returns and full-chunk policies.
- Tools/products/workflows: Public DQC codebase; benchmark protocols; controlled studies of open-loop consistency and BOV conditions; ablations on critic-chunk and policy-chunk lengths.
- Assumptions/dependencies: Annotated offline datasets; reproducible training settings; clear measurement of OLC/BOV and support overlap.
- Safer offline-to-online RL deployment gates (Sector: policy/governance of AI systems)
- Use case: Introduce deployment checks that favor decoupled chunking when datasets show weak open-loop consistency; prefer closed-loop execution of chunked policies to mitigate worst-case open-loop biases.
- Tools/products/workflows: Dataset audits for OLC/BOV; policy gating templates; deployment playbooks that default to partial-chunk execution with monitoring.
- Assumptions/dependencies: Organizational buy-in for dataset QA; access to diagnostics for OLC/BOV; risk management processes for offline RL systems.
Long-Term Applications
These applications benefit from DQC’s theoretical guarantees and practical design but require further research, scaling, domain adaptation, or regulatory approvals before broad deployment.
- Autonomous driving and advanced motion planning (Sector: mobility/automotive)
- Use case: Learn multi-step maneuvers (e.g., merges, lane changes, unprotected turns) from diverse logs, while deploying reactive policies that choose only the next control command.
- Tools/products/workflows: Large-scale chunked critics trained on fleet data; policy distillation to short partial chunks for low-latency control; closed-loop execution to avoid open-loop failures.
- Assumptions/dependencies: Strong OLC/BOV in fleet logs, robust generalization across scenarios, rigorous safety validation, and regulatory clearance.
- Clinical decision support and treatment planning (Sector: healthcare)
- Use case: Multi-visit treatment sequences (e.g., titration plans, rehabilitation programs) learned from historical outcomes; deploy reactive recommendations per visit.
- Tools/products/workflows: Offline RL on longitudinal EHR data; chunked critics for multi-step outcomes; partial-chunk policies augmented with physician oversight; uncertainty estimation for safety.
- Assumptions/dependencies: High-quality, de-biased datasets; adherence to privacy and medical regulations; explainability and clinician-in-the-loop requirements; careful validation of OLC/BOV in healthcare trajectories.
- Energy grid operations and industrial process control (Sector: energy/manufacturing)
- Use case: Plan multi-step control sequences (e.g., startup/shutdown, load balancing) with reactive adjustments at each timestep to handle disturbances.
- Tools/products/workflows: Simulation-based training with chunked critics; partial-chunk policies with robust closed-loop execution; digital twin validation.
- Assumptions/dependencies: Accurate simulators and digital twins; strong OLC/BOV in historical logs; safety interlocks and formal verification for critical systems.
- Financial trading and portfolio rebalancing (Sector: finance)
- Use case: Multi-step strategies (e.g., execution schedules, hedging sequences) trained from historical data; reactive policies that choose next action while leveraging longer-horizon value learning.
- Tools/products/workflows: Offline RL training under strict risk controls; chunked critic with conservative backups; deployment via paper trading and staged rollouts.
- Assumptions/dependencies: Nonstationarity and market shifts can break OLC/BOV; stringent compliance; robust backtesting; adversarial stress testing.
- Household and service robots (Sector: consumer robotics)
- Use case: Long-horizon chores (e.g., cleaning, tidying, food prep) learned from demonstration logs; reactive policies that execute step-by-step actions with multi-step foresight.
- Tools/products/workflows: DQC-based learning from teleoperation and scripted behaviors; policy-chunk sizes tuned for user safety and reactivity; continual learning workflows.
- Assumptions/dependencies: Diverse, high-quality demos; perception robustness; human-robot interaction safety; reliable closed-loop control.
- Generalist foundation agents for multi-step tool use (Sector: software/AI platforms)
- Use case: Agents that plan and execute sequences across tools (e.g., API calls, editors, terminals) using chunked critics for multi-step value and reactive partial-chunk action selection.
- Tools/products/workflows: Integrated pipelines combining DQC with LLM-based planners; tool-use logs curated for OLC/BOV; safety filters for execution.
- Assumptions/dependencies: Scalable datasets across tools, consistent APIs, reliable grounding; research on integrating symbolic planning with DQC; robust evaluation.
- Standards for offline RL data curation and evaluation (Sector: policy/standards)
- Use case: Formalize dataset properties (open-loop consistency, bounded optimality variability, support overlap) as part of certification for offline RL.
- Tools/products/workflows: Standardized audits; benchmark suites emphasizing long-horizon structure; conformance tests for OLC/BOV; documentation practices.
- Assumptions/dependencies: Community consensus; clear measurement protocols; alignment with safety and regulatory bodies.
- Methodological advances in RL theory and practice (Sector: academia)
- Use case: Extend theory for chunked critics beyond goal-conditioned tasks; design data collection strategies that improve OLC/BOV; derive tighter bounds for closed-loop execution and off-policy convergence.
- Tools/products/workflows: New theoretical frameworks; synthetic datasets with controllable OLC/BOV; open-source libraries for DQC variants and diagnostics.
- Assumptions/dependencies: Sustained research effort; reproducible benchmarks; collaboration across labs and industry partners.
- End-to-end toolchains for DQC at scale (Sector: software/ML infrastructure)
- Use case: Production-grade pipelines (data QA for OLC/BOV → chunked critic training → optimistic distillation → reactive policy deployment → monitoring).
- Tools/products/workflows: Plugins for PyTorch/JAX/RLlib; distributed training and evaluation; dataset diagnostics and visualizations for OLC/BOV; rollout monitors.
- Assumptions/dependencies: Engineering investment; large-scale data storage and compute; integration with MLOps practices; robust observability.
In all cases, feasibility hinges on several recurring assumptions or dependencies:
- Dataset properties: Reasonable open-loop consistency (weak or strong) or bounded optimality variability; support overlap with target behaviors; sufficient coverage of successful sequences.
- Safety and validation: Preference for closed-loop execution of chunked policies; staged deployment, sandboxing, and monitoring; domain-specific safeguards (e.g., human oversight in healthcare, interlocks in energy).
- Modeling choices: Appropriate selection of critic chunk size versus policy chunk size; stable value backups (e.g., expectile/quantile implicit backups); careful handling of off-policy biases.
- Infrastructure: Access to suitable simulators or digital twins, offline RL tooling, compute resources, and logging/observability to track performance and drift.
Glossary
- Action chunking critic: A value function that estimates the return of short sequences of actions (chunks) instead of single actions. "Action chunking critic. Alternatively, one may learn an action chunking critic to estimate the value of a short sequence of actions (an action chunk), instead: "
- Bellman optimality equation: A recursive equation defining the optimal value function/critic via maximizing expected returns over actions. "we analyze the Q-function obtained as a solution of the bellman optimality equation under "
- Bounded optimality variability (BOV): A condition that limits how much optimal returns can vary within specified conditioning, used to analyze closed-loop performance. "bounded optimality variability (BOV: \cref{def:opt-var})"
- Bootstrapping bias: Systematic error introduced when TD methods regress to their own future predictions, compounding errors over time. "such a self-bootstrapping mechanism is prone to bootstrapping bias, where the errors in the value targets accumulate across steps and result in biased value estimates."
- Chunked critics: Critics that evaluate action sequences (chunks), enabling multi-step value backup and faster propagation. "Recent work has proposed to use chunked critics, which estimate the value of short action sequences (“chunks”) rather than individual actions, speeding up value backup."
- Closed-loop execution: Executing policies by selecting actions step-by-step with state feedback, here taking only the first action from a predicted chunk. "closed-loop execution (i.e., only executing the first action in the predicted action chunk)"
- Decoupled Q-chunking (DQC): An algorithm that learns with a long-horizon chunked critic while training a policy on shorter partial chunks. "Decoupled Q-chunking (DQC). Left: The key idea of our method is to `decouple' the action chunk size of the critic from that of the policy ."
- Discount factor: A scalar in [0,1) that exponentially down-weights future rewards in return calculations. " is the discount factor."
- Expectile: A loss-based statistic used to implicitly approximate a maximization target by regressing to high expectiles of a distribution. "Two popular choices of $f^\kappa_{\mathrm{imp}$ are (1) expectile: $f^\kappa_{\mathrm{expectile}(c) = |\kappa - \mathbb{I}_{c<0}| c^2$"
- Goal-conditioned: RL setting where policies and value functions are conditioned on desired goal states or outcomes. "OGBench, an offline goal-conditioned RL benchmark with challenging long-horizon tasks."
- Importance sampling: A reweighting technique to correct off-policy bias in multi-step backups, often suffering high variance. "Although importance sampling can in principle correct such off-policy biases by reweighting the off-policy trajectories"
- Implicit value backup: Training a value function to approximate the maximization over actions via a surrogate regression objective instead of explicit argmax. "Implicit value backup. Instead of using as the TD target, we can use an implicit maximization loss function $f_{\mathrm{imp}$ to learn "
- Markov decision process (MDP): A formal model of RL with states, actions, transitions, rewards, initial distribution, and discount. "Reinforcement learning can be formalized as a Markov decision process, "
- Multi-step return backup: A TD target that uses returns over n steps before bootstrapping, reducing effective horizon. "Multi-step return backups~\citep{sutton1998reinforcement} can alleviate bootstrapping bias by shifting the regression target further into the future and effectively reducing the time horizon."
- n-step return backup: A specific multi-step TD update that backs up returns over n steps and then bootstraps. "The -step return backup reduces the effective horizon by a factor of , alleviating the bootstrapping bias problem."
- Off-policy bias: Systematic error from backing up along trajectories not induced by the current policy. "use a standard single-step critic network~\citep{park2025horizon} that suffers from the off-policy bias"
- Offline reinforcement learning (offline RL): Learning policies solely from static datasets without environment interaction. "Temporal-difference (TD) methods ... making them well-suited for offline RL"
- OGBench: A benchmark of offline, goal-conditioned, long-horizon tasks for evaluating RL methods. "our method outperforms all baselines on six hardest environments on OGBench, an offline goal-conditioned RL benchmark with challenging long-horizon tasks."
- Open-loop: Executing a fixed action sequence without reacting to intermediate observations or states. "policies must output the entire action chunk open-loop"
- Open-loop consistency (OLC): A condition bounding discrepancies between data-induced and open-loop trajectory distributions, often via total variation. "we identify the key open-loop consistency condition (\cref{def:olc})"
- Poissonian model: A probabilistic model with Poisson events, used here to represent unreliable observations in control. "with a Poissonian model~\citep{wang2001some, dupuis2002optimal}"
- Quantile: A loss-based statistic used for implicit maximization by targeting high quantiles of TD targets. "and (2) quantile: $f^\kappa_{\mathrm{quantile}(c) = |\kappa - \mathbb{I}_{c<0}||c|$, for any real value ."
- Stochastic optimal control (SOC): A control framework focusing on optimal decisions under uncertainty, related to RL analysis. "In the adjacent field of stochastic optimal control (SOC), action chunking is related to control under intermittent observations"
- Sub-optimality gap: The difference in value between an optimal policy and a candidate policy, measuring performance shortfall. "and sub-optimality gap (\cref{thm:suboptact,thm:suboptactight}) at the fixed point of the bellman optimality equations."
- Support (of a distribution): The set where a probability distribution assigns nonzero probability mass. "$s_t \in \mathrm{supp}(P_{\mathcal{D}(s_t))$"
- Temporal-difference (TD) methods: RL algorithms that learn value functions by bootstrapping from predictions at subsequent time steps. "Temporal-difference (TD) methods learn state and action values efficiently by bootstrapping from their own future value predictions"
- Total variation distance: A metric quantifying the maximum discrepancy between two probability distributions. "deviates from the corresponding distribution in the dataset by at most in total variation distance."
- Transition kernel: The function mapping state-action pairs to distributions over next states. " is the transition kernel"
- Value iteration: A dynamic programming method (or its learning analogue) iteratively applying Bellman updates to converge to values. "behavior value iteration of an action chunking critic results in a nominal value function"
Collections
Sign up for free to add this paper to one or more collections.

