Perturbation is All You Need for Extrapolating Language Models
Published 5 May 2026 in stat.ML, cs.LG, and math.ST | (2605.04344v1)
Abstract: We introduce a simple yet powerful framework for training LLMs. In contrast to the standard autoregressive next-token prediction based on an exact prefix, we propose a perturbation-based procedure that first transforms the prefix into a semantic neighbor and then conditions on this perturbed variant for next-token prediction. This yields a hierarchical model with a pre-post-additive noise structure. Within this framework, we develop a rigorous theory of extrapolability, namely, the capacity of a model class to make reliable predictions for token sequences that lie outside the empirical support of the training corpus. We evaluate the finite-sample performance of the proposed procedure using both synthetic and real-world language data. Results show that the proposed method consistently improves out-of-support prediction while maintaining competitive in-support performance, demonstrating that perturbation offers a practical route to language modeling.
The paper demonstrates that integrating semantic perturbations at both training and inference enhances LLM extrapolation capabilities.
It employs a hierarchical generative process and provides rigorous theoretical bounds on extrapolation uncertainty using noise models.
Empirical results on synthetic and WikiText datasets show superior performance, with significant gains in measures like Mauve and ROUGE-1.
Extrapolability in LLMs via Semantic Perturbation: A Technical Overview of "Perturbation is All You Need for Extrapolating LLMs"
Introduction and Motivation
“Perturbation is All You Need for Extrapolating LLMs” (2605.04344) introduces a principled framework for augmenting the extrapolation capabilities of LLMs. The method centers on a semantic perturbation of input prefixes during both pretraining and inference, drawing inspiration from pre- and pre-post-additive noise models in regression and cognitive ideas regarding human linguistic resilience to semantic shifts. This approach is motivated by limitations in current LLM generalization when exposed to out-of-support prompts, a problem exacerbated as data and compute scaling laws approach saturation.
Methodology: Perturbed Autoregressive Language Modeling
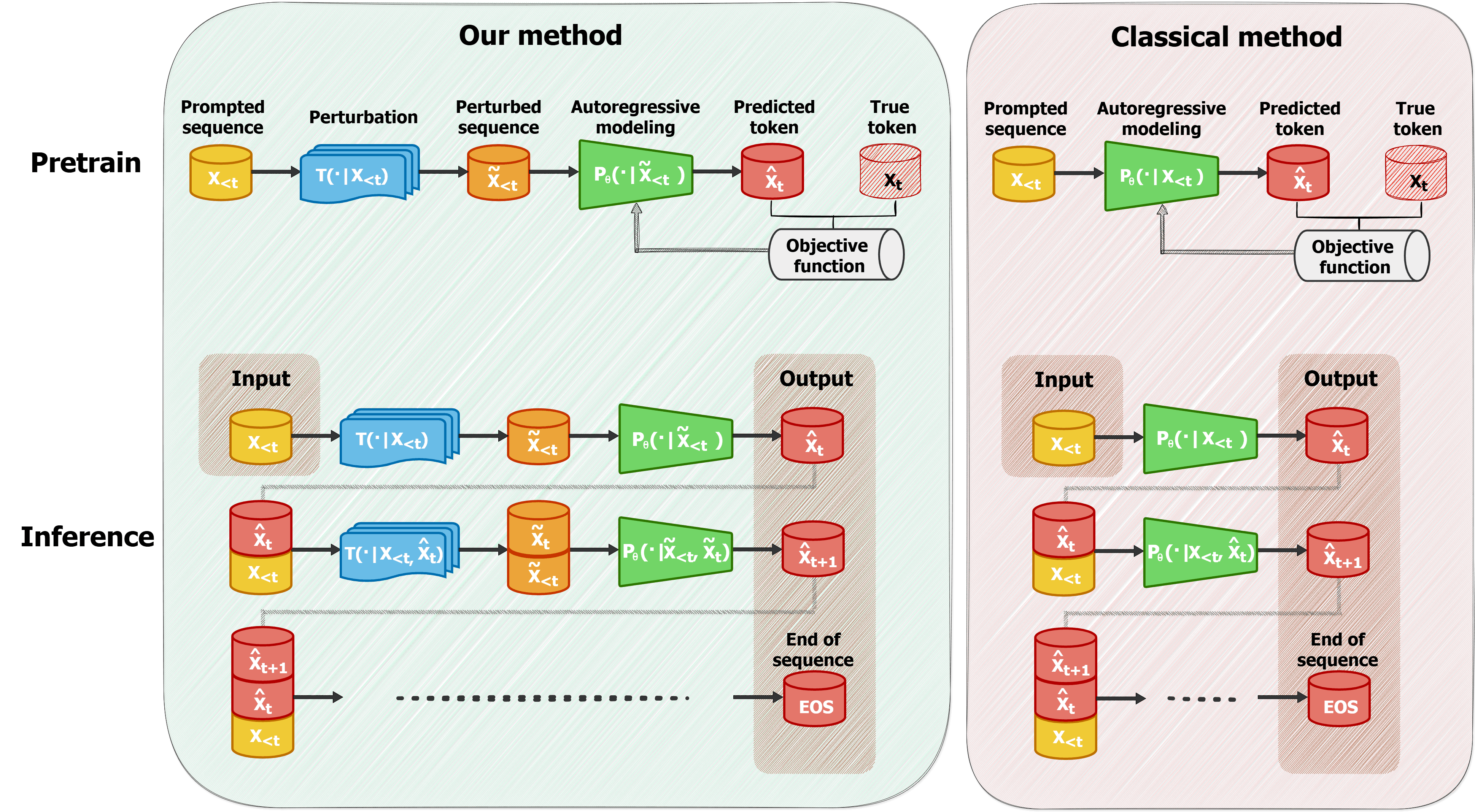
The core methodology defines a hierarchical generative process. For each input prefix X<t in the sequence, a perturbed version X<t is sampled from a stochastic perturbation operator T(⋅∣X<t)—e.g., random insertion, synonym replacement, or deletion. The LLM then predicts the next token conditioning on X<t, not the original X<t, thereby explicitly training and deploying the model on neighborhoods of the empirical support.
Figure 1: Illustration of perturbed autoregressive modeling, which injects noise at the prefix level, contrasting classical autoregressive modeling that conditions only on the exact observed prefix.
Formally, the log-likelihood objective across a dataset D becomes:
LLog(Pθ;X):=m1i=1∑mt=1∑LlogPθ(Xt∣X<t(i))
where m is the number of perturbation samples per context during training. Inference is run analogously, typically using a single perturbation sample for efficiency. This augmentation is distinct from data augmentation regimes: perturbations are applied symmetrically at both training and inference, making the noise process an intrinsic architectural element.
Theoretical Results: Adaptivity, Robustness, and Extrapolability
A rigorous theory of LLM extrapolability is developed. Let X be the empirical training support and d(X,X) a semantic metric (e.g., Hamming) from test prefix X<t0 to the training set. Extrapolation uncertainty X<t1 quantifies the maximal divergence between models in a class X<t2 that agree on X<t3, across all prefixes within X<t4-distance from X<t5.
Three main results are established:
Adaptivity: If the base model class is extrapolable, so is its perturbed variant, under mild invertibility assumptions on the perturbation.
Robustness: The extrapolation uncertainty of perturbed models is bounded above by a constant X<t6 that is independent of the base class, depending only on perturbation properties. Thus, perturbed models retain a nontrivial guarantee even when the base LLM class extrapolates poorly.
Extrapolability: For a sufficiently “rich” perturbation X<t7 (i.e., one that stochastically maps out-of-support prefixes to training support neighborhoods), the extrapolation uncertainty vanishes, achieving perfect extrapolability.
Formal analysis is supplied for common perturbations such as synonym replacement, showing that the bound on extrapolation uncertainty decays linearly with perturbation intensity under the Hamming metric. The framework can be extended in RKHS settings or to general conditional measure classes, ensuring applicability to a wide array of model formulations.
Empirical Validation
Synthetic Analysis
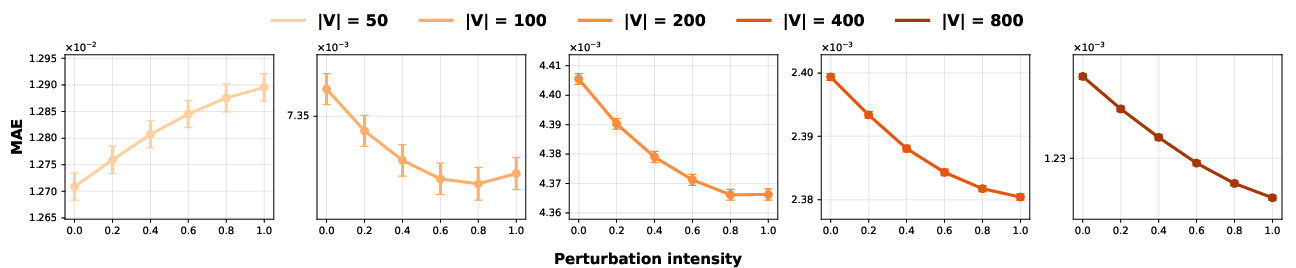
On synthetic data sampled from a ground-truth bigram model (with variable vocab sizes), the mean absolute error on out-of-support transition pairs decreases substantially with increasing perturbation intensity in the perturbed approach as compared to the classic pipeline. The benefit is largest in sparse data regimes, demonstrating the capacity to generalize to novel n-grams not seen in training.
Figure 2: Mean absolute error of estimated transition matrices on unobserved token pairs as a function of perturbation intensity and vocabulary size.
Real-World Data
Using WikiText-2 for training, the method is evaluated on both in-domain and significant distribution shifts (WikiText-103, WebText, WritingPrompts), and across multiple Transformer architectures (OPT-125M, GPT-2, GPT-Neo-1.3B). The principal metric is Mauve, which measures alignment of generated output to human text, complemented by ROUGE-1 for lexical overlap.
The perturbed approach consistently achieves the highest Mauve and ROUGE-1 scores across all models and test sets, including substantial improvements (up to +0.1 in Mauve) on domain-shifted evaluation sets. The advantage is pronounced for more challenging out-of-support settings, underscoring extrapolative generalization gains.
Ablation Analysis
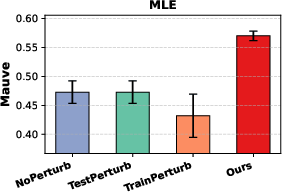
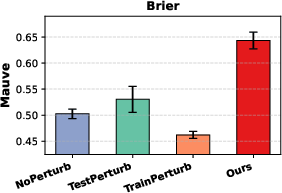
An ablation isolating the contribution of perturbation at training/inference highlights that symmetric incorporation is necessary: applying perturbation at only one stage (either “TrainPerturb” or “TestPerturb”) yields negligible improvements over baseline. Significant gains are observed uniquely when both stages incorporate perturbations.
Figure 3: Ablation experiment demonstrates that only perturbing during both training and inference yields nontrivial gains in the Mauve score.
Figure 4: Ablation with the Brier score objective replicates the superiority of combined perturbation across evaluation runs.
Sensitivity Studies and Perturbation Design
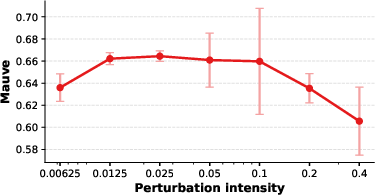
Experiments varying intensity and type of perturbation reveal that moderate levels optimize performance, with excessive perturbation leading to performance collapse; various perturbation strategies (replacement, deletion, insertion) yield robust improvements, confirming generality.
Figure 5: Mauve score as a function of perturbation intensity, showing optimal performance at moderate levels of applied noise.
Implications and Prospective Directions
The derived properties—distributional adaptivity, robustness under base model failure, and provable perfect extrapolability—mark the perturbed LLM framework as a theoretically sound and practically effective strategy for closing LLM generalization gaps. The method's simplicity and agnosticism to model architecture promote broad applicability within NLP and, by extension, to multimodal and vision-LLMs.
A notable research direction is parameterizing the perturbation operator X<t8 for joint optimization, further harmonizing the stochastic process with model learning dynamics. Potential exists for integrating learned perturbation processes as differentiable modules, or for data-driven selection of perturbation intensity/coupling with uncertainty quantification.
Conclusion
This work presents a unified framework blending cognitive and statistical perspectives for extrapolation in LLMs. By embedding semantic perturbations directly into the modeling pipeline—across both pretraining and inference—the approach secures rigorous theoretical properties, delivers strong empirical advantages on synthetic and real-world LLM tasks, and provides a general recipe for robustness to out-of-support shifts. The paradigm opens new directions for architecture-agnostic improvements in generalization, suggesting a broader principle of noise-augmented representation learning for large generative models.