- The paper introduces a RoPE-perturbed self-distillation framework that reduces positional brittleness in long-context LLMs.
- It perturbs RoPE indices during training and employs a KL-divergence regularizer, yielding improvements up to 12% accuracy on challenging benchmarks.
- The method sustains short-context performance while enhancing long-range attention allocation and length extrapolation in ultra-long sequences.
RoPE-Perturbed Self-Distillation for Long-Context Adaptation
Motivation and Observed Positional Brittleness in LLMs
LLMs increasingly underpin applications requiring robust reasoning over long-contexts—such as multi-document RAG or long-horizon code reasoning. Standard practice extends pretrained models’ context windows via continued pretraining at the target sequence length or fine-tuning. However, empirical findings reveal persistent positional brittleness: model accuracy on long-context tasks depends acutely on the absolute location of relevant evidence, producing substantial variance as a function of evidence position even when difficulty is controlled. This effect is illustrated in the NIAH multikey-2 task: accuracy exhibits a pronounced drop when the answer is located toward the middle or end of the prompt.
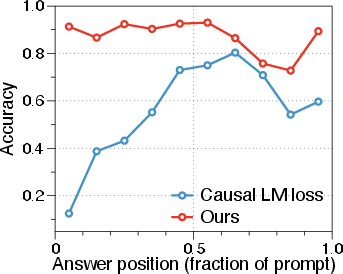
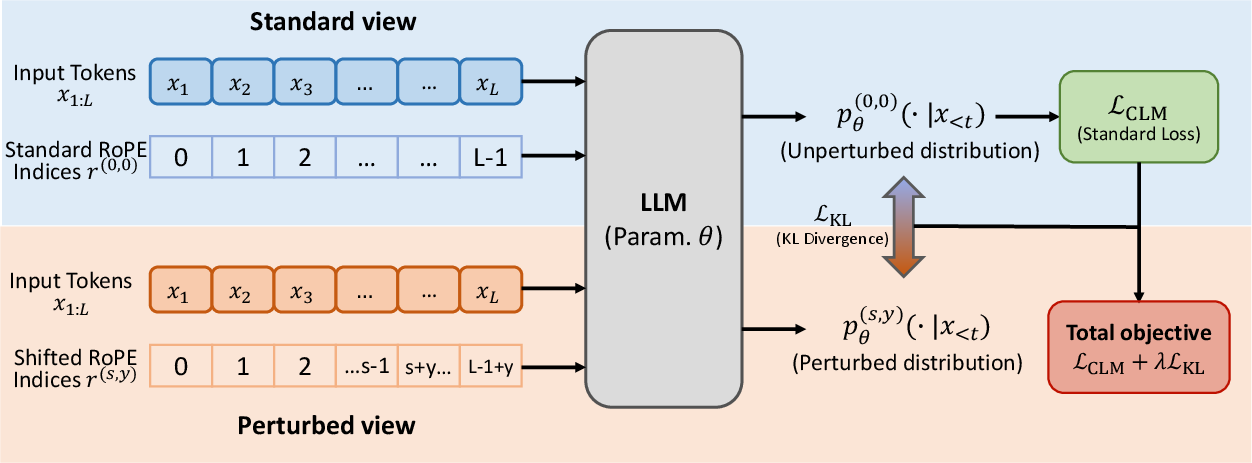
Figure 1: Answer accuracy as a function of evidence position within long input sequences, highlighting position sensitivity in standard long-context adapted LLMs.
This behavior is traced to the use of Rotary Position Embeddings (RoPE) as the underlying positional encoding scheme, which, due to its multi-frequency structure, induces model sensitivity to position assignment at both fine and coarse granularities.
RoPE-Perturbed Self-Distillation: Methodology
To address positional sensitivity, the authors introduce RoPE-Perturbed Self-Distillation: a regularization framework that explicitly encourages prediction invariance to controlled perturbations in RoPE index assignment during training. The central idea is to generate alternative “views” of each sequence by perturbing RoPE indices—e.g., shifting a contiguous token suffix by an offset in positional space—then require the model's output distributions for the perturbed and standard views to agree via a KL-based consistency loss.
The procedure is as follows:
- For a sequence x0:L−1, a split point s and skip offset y are sampled, and RoPE indices for tokens i≥s are shifted by y.
- Two forward passes are computed: (1) the standard view with unperturbed indices; (2) the perturbed view.
- The main loss is the standard causal language modeling (CLM) objective on the unperturbed view.
- A reverse KL-divergence regularizer is computed between model outputs on the perturbed vs. the standard view, with stop-gradient on the teacher (standard view).
Additional variants (such as cyclic shifts, which rotate all indices) instantiate stronger perturbations, stress-testing the model’s positional invariance. The consistency regularizer encourages models to rely on semantic and coarse structural cues, rather than brittle dependence on absolute RoPE indices.
Empirical Evaluation: Long-Context Robustness
The method is tested on long-context adaptation of Llama-3-8B and Qwen-3-4B, using benchmarks such as RULER and HELMET. Position-dependent accuracy variance is reduced significantly. Attention analysis reveals that, relative to standard training, RoPE-perturbed self-distillation encourages allocation of attention mass over larger context distances, supporting enhanced long-range reasoning.
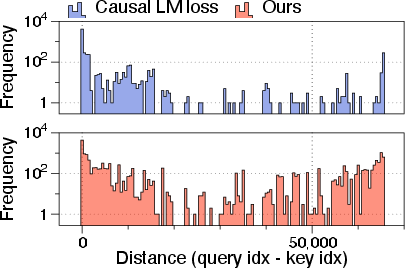
Figure 2: Distribution of attention distances under different models, showing increased and more uniform long-range attention in models trained with RoPE-perturbed self-distillation.
Benchmark results further evidence robust gains:
- On Llama-3-8B-Instruct at 64K tokens, average RULER accuracy improves up to 12.04% over standard or strong baselines.
- On Qwen-3-4B at 256K tokens, a 2.71% gain is observed post-supervised fine-tuning (SFT).
- Improvements concentrate on challenging multi-key, multi-value retrieval and aggregation tasks, where positional sensitivity is most problematic.
The technique also mitigates “lost-in-the-middle” phenomena prevalent in long-context LLMs.
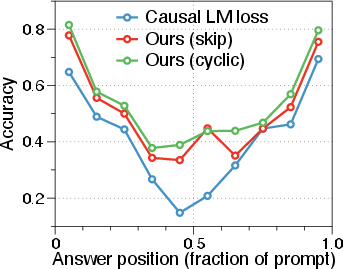
Figure 3: Positional sensitivity curves for Qwen-3-4B on the RULER NIAH MultiKey-2 benchmark, showing reduced accuracy drop in context middles when trained with RoPE-perturbed self-distillation.
Short-context downstream task performance is preserved, indicating absence of regressions in general language modeling ability.
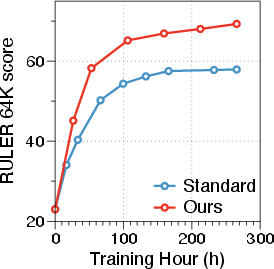
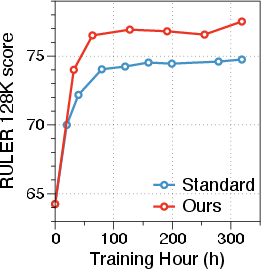
Figure 4: Llama-3-8B model performance visual summary.
Generalization and Extrapolation
A salient property of RoPE-perturbed self-distillation is improved length extrapolation: models exhibit less degradation outside the training context window when context is extended (via mechanisms such as YaRN). This confirms that the regularized invariance to RoPE perturbation not only aids in-distribution robustness but also transfers to unseen, ultra-long contexts.
Furthermore, the method’s gains persist after post-training via instruction SFT, and even in mix-length training regimes, supporting practical downstream composability.
Ablation and Analysis
Extensive ablation demonstrates:
- Reverse KL with a stop-gradient teacher is crucial; simply training on the perturbed view or using forward KL is suboptimal.
- Randomized skip parameter sampling per sequence enhances robustness; fixed skips are less effective.
- Gains are not explained by generic two-pass noise or dropout regularization; explicit RoPE-index perturbation is necessary.
- Skip-based shifts, which are order-preserving, balance invariance to position with retention of usable ordinal information in evidence retrieval tasks; more destructive cyclic or permutation perturbations may impair order-sensitive query performance.
- The method is not highly sensitive to hyperparameters such as the KL weight λ or the skip range.
Practical and Theoretical Implications
Practically, RoPE-perturbed self-distillation is architecturally nonintrusive, incurs moderate training overhead, and is easily integrated into standard long-context continued pretraining pipelines. Its data efficiency and compute-matched superiority are especially relevant given the limited availability of high-quality ultra-long sequence data.
Theoretically, the work reframes context-length adaptation as an invariance learning problem, challenging the prevailing paradigm of rescaling or extending positional encodings alone. The framework is not fundamentally tied to RoPE; analogous perturbation schemes can be constructed for other positional encoding strategies, suggesting a general approach to combating brittle position dependencies in autoregressive sequence models.
Conclusion
RoPE-Perturbed Self-Distillation robustly regularizes LLMs for long-context adaptation by encouraging invariance to RoPE index perturbations. The approach delivers substantial improvements on long-context reasoning, retrieval, and composition benchmarks, with consistent extrapolation benefits and no cost to short-context performance. The results advocate for invariance-based regularization as a broadly applicable strategy for long-context LLM resilience, and motivate exploration of perturbation-specific training signals for alternative positional encoding approaches.