Reinforced Fast Weights with Next-Sequence Prediction
Abstract: Fast weight architectures offer a promising alternative to attention-based transformers for long-context modeling by maintaining constant memory overhead regardless of context length. However, their potential is limited by the next-token prediction (NTP) training paradigm. NTP optimizes single-token predictions and ignores semantic coherence across multiple tokens following a prefix. Consequently, fast weight models, which dynamically update their parameters to store contextual information, learn suboptimal representations that fail to capture long-range dependencies. We introduce REFINE (Reinforced Fast weIghts with Next sEquence prediction), a reinforcement learning framework that trains fast weight models under the next-sequence prediction (NSP) objective. REFINE selects informative token positions based on prediction entropy, generates multi-token rollouts, assigns self-supervised sequence-level rewards, and optimizes the model with group relative policy optimization (GRPO). REFINE is applicable throughout the training lifecycle of pre-trained LLMs: mid-training, post-training, and test-time training. Our experiments on LaCT-760M and DeltaNet-1.3B demonstrate that REFINE consistently outperforms supervised fine-tuning with NTP across needle-in-a-haystack retrieval, long-context question answering, and diverse tasks in LongBench. REFINE provides an effective and versatile framework for improving long-context modeling in fast weight architectures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping certain kinds of LLMs remember and use very long texts better. These models are called “fast weight” models. Instead of using the usual attention system, they carry a small, constantly updated memory as they read. The authors introduce a new training method, called ReFINE, that teaches these models to predict not just the next word, but a short sequence of words that follows—so the model learns to keep its thoughts coherent over several steps. They do this using ideas from reinforcement learning (RL), which is a way to train models by giving them rewards for good behavior.
Key Objectives
The paper tries to answer these questions:
- Can we train fast weight models in a way that makes them handle long texts more accurately and consistently?
- Is predicting the next short sequence (instead of just the next token/word) a better training goal for these models?
- Can reinforcement learning help these models learn which parts of a long text are most important to practice on?
- Will this new method work at different times in a model’s life: during additional pre-training, during fine-tuning for specific tasks, and even at test time?
How They Did It (Methods)
What is a fast weight model?
Imagine you’re reading a very long book with a tiny notebook in your pocket. You don’t copy the whole book into your notebook. Instead, as you read, you write down small, important bits to help you remember. A fast weight model works like that: it has a fixed-size “memory” (the notebook) that it updates at each step to store useful information, rather than relying on a huge attention map over all past tokens. This keeps memory use steady, even for very long inputs.
Why next-token prediction falls short
Most LLMs are trained to guess the next word given the previous ones. That’s called next-token prediction (NTP). But NTP only cares about one immediate step. It doesn’t check if the next several words make sense together. For fast weight models—whose whole job is to carry forward useful context—this can lead to short-term thinking and weaker long-range memory.
The new idea: next-sequence prediction (NSP)
Instead of only predicting the next word, the authors train the model to predict the next few words (a short sequence) that continues the text in a meaningful way. This helps the model learn better “ongoing coherence,” which is crucial when reading and remembering long passages.
How ReFINE trains the model (four simple steps)
To make NSP practical on very long texts, ReFINE uses reinforcement learning:
- Entropy-based token selection
- Entropy is a measure of uncertainty. If the model is very unsure about what comes next at a certain position, entropy is high.
- The method splits the long text into chunks and, in each chunk, picks one “tricky” position based on entropy. This focuses training where it matters most.
- Rollout generation
- At each selected position, the model predicts the next few tokens (for example, 5 tokens). Think of this like asking the model to “continue the sentence for a few words.”
- Reward assignment
- The model gets a score (reward) based on how close its predicted continuation is to the true continuation.
- Instead of only checking exact word matches, ReFINE also compares the model’s internal “thoughts” (hidden states) for predicted vs. true tokens. If these internal representations are similar (like two sentences meaning the same thing), the model earns a smooth, helpful reward. This makes training more forgiving and encourages semantic correctness, not just exact wording.
- For certain cases (like at test time), they can also add a simple exact-match reward to sharpen memory.
- Optimization with RL (using GRPO)
- GRPO (Group Relative Policy Optimization) is a method to update the model using the rewards, emphasizing better-than-average predictions from the same example. In simple terms: the model tries different short continuations; those that score higher influence learning more.
- To avoid forgetting basic next-word skills, ReFINE blends the new sequence-level RL training with the usual next-token training.
Where ReFINE can be used
- Mid-training: extra training after pre-training to improve long-context skills.
- Post-training: fine-tuning for specific tasks (like question answering), using a “nested” strategy—first adapt on the prompt with ReFINE, then fine-tune the final answer.
- Test-time training: lightly adapt the model on the actual input it’s about to answer, without extra labels—perfect for long documents or multi-document questions.
Main Findings
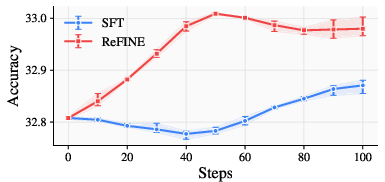
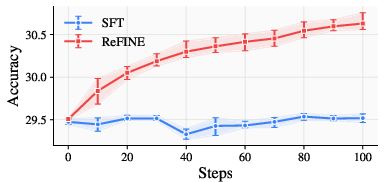
Across many tests, ReFINE helped fast weight models consistently:
- Needle-in-a-Haystack retrieval (finding a small piece of info in very long text): ReFINE improved performance over standard supervised training.
- Long-context question answering (like SQuAD and HotpotQA variants in the RULER benchmark): models trained with ReFINE gave more accurate answers, especially as the context length grew (4K, 8K, 16K tokens).
- LongBench (a suite of long-context tasks: QA, summarization, few-shot, coding): ReFINE boosted scores across a variety of tasks, not just one kind.
The authors tested on two fast weight models (LaCT-760M and DeltaNet-1.3B) and found improvements at all stages (mid-training, post-training, and test-time training). They also discovered practical tips:
- Choosing the most informative positions by entropy works better than random or always picking the highest-entropy spot.
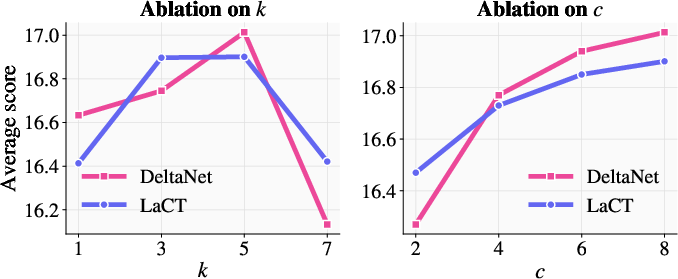
- Predicting around 5 tokens ahead often gave the best reward signal; very long rollouts could make the signal fuzzier.
- Mixing reward types (semantic similarity plus exact match) can be helpful, especially at test time.
Why This Is Important
As LLMs are asked to read and reason over longer and longer inputs, they need ways to remember and use context efficiently. Attention-based transformers can be expensive for very long inputs (their memory use grows fast). Fast weight models offer a way to keep memory steady, but they need training that matches their strengths. By shifting from “just the next word” to “the next short sequence” and rewarding coherent multi-step predictions, ReFINE teaches these models to think a bit further ahead. That’s exactly what long-context tasks need.
Implications and Potential Impact
- Better long-memory skills: ReFINE helps models store and reuse important information across long stretches of text, which is valuable for tasks like browsing lengthy documents, multi-document QA, and writing or reviewing code with long files.
- Efficiency: Fast weight models already use constant memory. Training them in a way that makes that memory more useful can make powerful long-context systems more practical.
- Flexible adoption: Because ReFINE works during mid-training, post-training, and even at test time, it’s easy to integrate into existing model pipelines.
In short, ReFINE shows a clear path to making long-context LLMs more accurate and coherent by training them to predict short sequences and rewarding good multi-step behavior, not just single next words.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, concrete list of gaps and open questions that remain unresolved and can guide future research:
- Scaling behavior beyond 16K tokens: The method is evaluated up to 16K context length; it remains unknown how ReFINE performs at 32K–1M tokens, including throughput, latency, and memory under realistic inference constraints.
- Compute and efficiency trade-offs: ReFINE requires multi-token rollouts and additional forward passes. There is no quantification of training/inference FLOPs, wall-clock time, and memory overhead versus SFT baselines, making cost–benefit unclear.
- Reward design limitations: The primary reward uses cosine similarity of the model’s own hidden states, which may induce reward hacking or representation collapse. It’s unclear how robust this is versus external rewards (e.g., BERTScore, BLEU/ROUGE, chrF, edit distance, CLIP/BGE embeddings, or larger-teacher embeddings).
- Task-specific reward selection at test time: For TTT, a binary exact match reward was used universally, yet it is ill-suited for open-ended tasks (e.g., summarization). A principled approach to selecting or mixing rewards per task and context type is missing.
- Convergence and stability theory: There is no theoretical analysis of GRPO convergence, bias/variance, or stability when updating fast weights, nor of how sequence-level rewards influence the dynamics of online parameter updates.
- Fast-weight update stability metrics: The paper claims better long-horizon adaptation but does not measure stability of fast weight updates (e.g., update magnitudes, variance, memory retention, and forgetting rates across the context).
- Mechanistic memory capacity evaluation: Improvements are shown on downstream tasks, but the intrinsic memory capacity of fast weights (e.g., information stored, retrieval fidelity vs. position, decay over distance) is not quantified.
- Architectural generality: Results are limited to LaCT-760M and DeltaNet-1.3B. It remains unknown if ReFINE generalizes to other fast-weight or attention-replacement architectures (e.g., RetNet, RWKV, GatedDeltaNet) and larger models (7B–70B+).
- Cross-domain and multilingual robustness: The method is only tested on English, specific corpora, and task sets. Its behavior under domain shift, multilingual inputs, and code-switching is unexamined.
- Entropy-based token selection sensitivity: The method fixes a smoothing kernel and temperature; there’s no study of sensitivity to these hyperparameters, nor exploration of alternative informativeness criteria (e.g., gradient norms, KL divergence, Fisher information, mutual information).
- Adaptive rollout length: Although performance peaks at k≈5 and deteriorates for longer rollouts, no strategy is proposed to dynamically choose k per prefix (e.g., early stopping when reward saturates, uncertainty-based scheduling).
- Region-level or multi-position rollouts: The approach samples one token per chunk (n=1) and uses fixed chunking. It’s unclear whether multi-position rollouts, learned chunking, or adaptive segmentation would yield better coverage and gains.
- Off-target effects and catastrophic forgetting: While mixing NTP and NSP is used to “prevent forgetting,” the paper does not quantify knowledge retention on general benchmarks or unintended degradations in abilities not targeted by NSP.
- RL algorithm choice: GRPO is used without comparison to alternative policy-gradient methods (PPO/TRPO/A2C, off-policy variants, actor–critic baselines). The sensitivity to advantage standardization and baselines is unknown.
- Integration into full-scale pre-training: Mid-training used ≈200M tokens for 100 steps. Unknown how ReFINE scales when integrated into multi-trillion-token pre-training, including sample efficiency and stability under curriculum schedules.
- Test-time rewards without ground truth: TTT relies on prompt tokens to provide self-supervised targets. For tasks where ground-truth continuation is unavailable, strategies for deriving reliable rewards (e.g., self-consistency, retrieval-based checks, external verifiers) are missing.
- Safety, alignment, and robustness: No assessment of whether sequence-level RL affects toxicity, factuality, or preference alignment, nor robust evaluations on adversarial prompts and jailbreaks.
- Parameter update semantics across architectures: DeltaNet maintains fixed parameters with a parallel memory state, whereas LaCT updates fast-weight parameters. The exact objects updated by RL in each architecture and their differing impacts are not clearly delineated or compared.
- State reuse and rollout efficiency: The paper notes future work on transferring fast weights across truncated prefixes but provides no concrete mechanism or evaluation of state caching/reuse, off-policy rollouts, or prefix-sharing strategies.
- Hyperparameter robustness: Although k and c are ablated, key hyperparameters (temperature τ, entropy smoothing kernel, λRL/λSFT, learning rate, number of rollouts n, layer choice for hidden-state reward) lack systematic sensitivity analyses.
- Evaluation breadth: LongBench and RULER are informative, but broader tests on many-shot in-context learning, complex code generation (e.g., RepoBench), and extremely long-document reasoning are needed to validate generality.
- External validation of semantic equivalence: Rewarding hidden-state similarity assumes representations encode semantics adequately. A comparative study with external semantic validators and human judgments is needed to confirm true semantic gains.
- Privacy and data leakage at TTT: Reinforcing fast weights on prompts may increase memorization of sensitive content. Data leakage risks and mitigation strategies (e.g., bounded update magnitudes, privacy-preserving rewards) remain unexplored.
- ReFINE’s interaction with alignment pipelines: How NSP-based RL interacts with post-training methods like SFT, DPO, PPO/RLHF, or preference ranking (and whether the order of application matters) is not studied.
- Mixed sequence-level objectives: It remains unclear whether combining NSP with sequence-level supervised losses (teacher-forced multi-token CE, label smoothing, scheduled sampling) can match or exceed GRPO performance with fewer rollouts.
- Generalization mechanisms: NSP improved NTP accuracy empirically, but the mechanism is not explained. A formal or empirical causal analysis linking sequence-level reward shaping to improved token-level predictions is missing.
Glossary
- Advantage: A variance-reduction baseline-adjusted measure used in policy gradient methods to scale updates based on how much a rollout’s reward exceeds the expected value. "The rewards from the same sequence are standardized to compute the advantage following \citet{shao2024deepseekmath}."
- Attention-based transformers: Neural architectures that use self-attention to relate tokens across a sequence, typically with quadratic compute in context length. "Fast weight architectures offer a promising alternative to attention-based transformers for long-context modeling..."
- Booksum: A long-form summarization dataset often used for evaluating next-token prediction and generalization. "We also report the validation NTP accuracy on the Booksum~\cite{kryscinski2022booksum} dataset."
- Catastrophic forgetting: Degradation of previously learned capabilities when training on new objectives, often mitigated by mixing losses. "To prevent catastrophic forgetting, the final loss is a weighted sum of the NSP loss and the standard NTP loss..."
- Cosine similarity: A vector similarity metric based on the cosine of the angle between embeddings, used to measure semantic alignment. "We use cosine similarity for ."
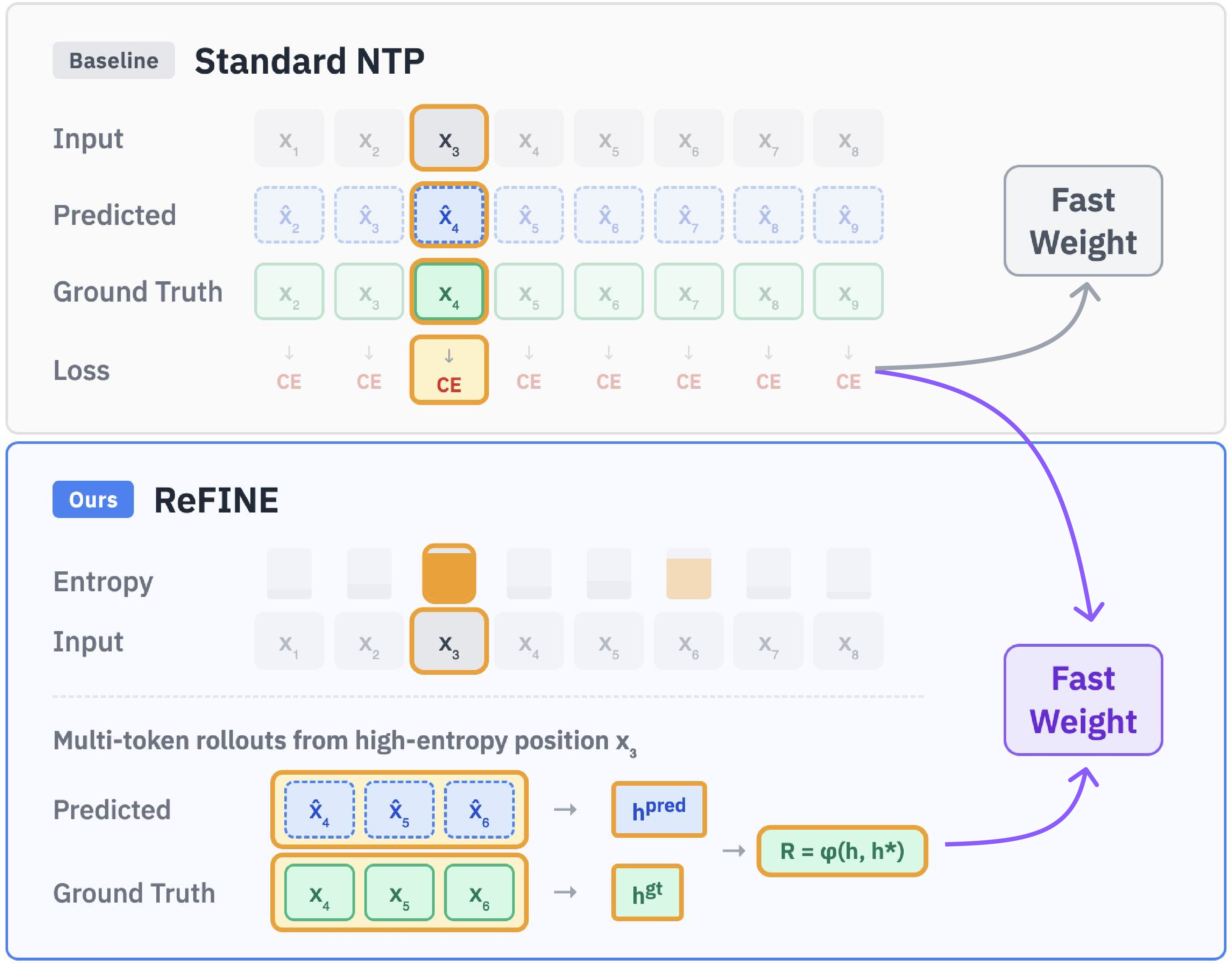
- Cross-entropy (CE) loss: A standard classification loss used in next-token prediction to penalize deviations from the ground-truth token distribution. "Standard NTP (top) computes cross-entropy loss at each token position..."
- DeltaNet: A fast weight model that replaces global attention with a parallelizable memory update mechanism. "Models such as DeltaNet~\cite{yang2024parallelizing}, GatedDeltaNet~\cite{yang2024gated}, and LaCT~\cite{zhang2025test} replace global attention with a fixed-size memory..."
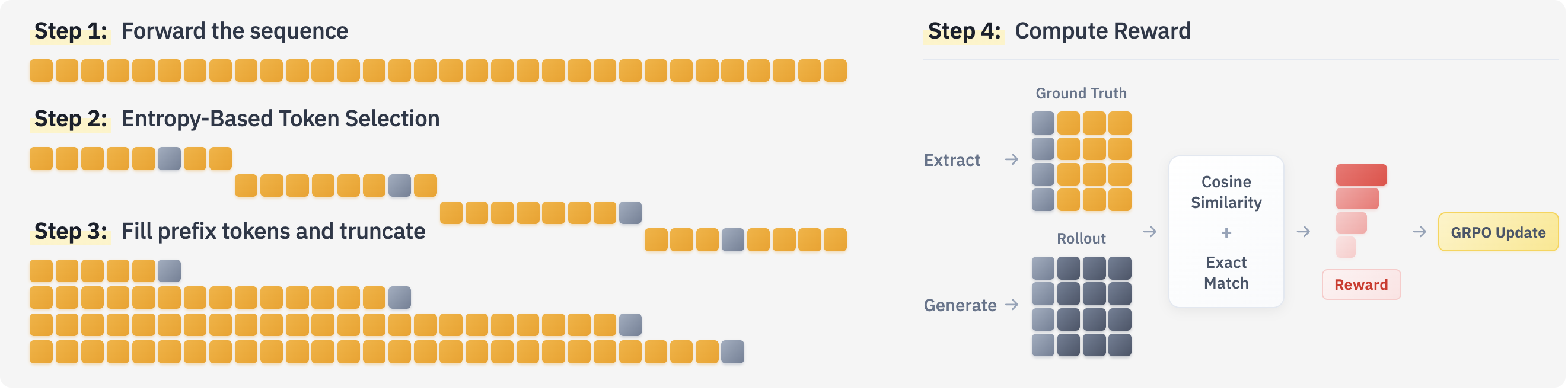
- Entropy-Based Token Selection: A strategy to focus training on uncertain regions by sampling positions proportionally to prediction entropy. "Sequences are split into chunks and a target token position is sampled from each chunk based on the entropy (Entropy-Based Token Selection)."
- Fast weight architectures: Models that maintain a fixed-size memory by dynamically updating weight matrices as tokens are processed, enabling constant memory overhead. "Fast weight architectures replace global attention in standard transformers with fixed-size memory parameterized as weight matrices."
- GatedDeltaNet: A variant of DeltaNet that incorporates gating mechanisms into fast weight updates. "Models such as DeltaNet~\cite{yang2024parallelizing}, GatedDeltaNet~\cite{yang2024gated}, and LaCT~\cite{zhang2025test}..."
- Group Relative Policy Optimization (GRPO): An RL optimization algorithm that uses relative advantages within a group of rollouts to stabilize policy updates. "We employ the GRPO algorithm \citep{shao2024deepseekmath} to compute the NSP loss based on the rollouts and their relative advantages."
- Hidden states: Internal layer representations (before logits) that encode contextual information used for reward computation and alignment. "We also extract the hidden states of the ground-truth continuation from the initial forward pass..."
- Key-value cache: A transformer memory mechanism storing per-token key and value vectors for attention over previous context. "Instead of keeping a growing key-value cache, fast weight models continually update the weight matrices..."
- LaCT: A fast weight LLM that adapts by updating fast weight parameters during processing. "LaCT adapts the model by updating its fast weight parameters, whereas DeltaNet keeps parameters fixed..."
- LongBench: A benchmark suite of long-context tasks evaluating retrieval, QA, summarization, few-shot reasoning, and coding. "We evaluate on 12 tasks in LongBench, filtered for samples with at most 16K tokens."
- Long-Data-Collections: A corpus used for pretraining or mid-training to enhance long-context capabilities. "Specifically, we perform mid-training with Long-Data-Collections~\cite{longdatacollections}, which is the pre-training dataset for LaCT..."
- Long-context modeling: Training and inference paradigms handling sequences of thousands of tokens, emphasizing memory and retrieval over long horizons. "Long-context modeling has become essential for LLMs."
- Meta-learning: A learning paradigm where models are trained to rapidly adapt to new tasks or distributions, often associated with fast weight updates. "fast weight models are often associated with test-time training~\cite{behrouz2024titans} and meta-learning~\cite{clark2022meta}..."
- Needle-in-a-Haystack (NIAH): Long-context retrieval tasks where a model must locate specific information within large inputs. "across needle-in-a-haystack retrieval, long-context question answering, and diverse tasks in LongBench."
- Next-sequence prediction (NSP): An objective that optimizes multi-token semantic alignment of continuations given a prefix, rather than single-token likelihood. "We introduce ReFINE ... under the next-sequence prediction (NSP) objective."
- Next-token prediction (NTP): The standard LM objective that minimizes per-token cross-entropy to predict the immediate next token. "fast weight models are typically pre-trained with the same next-token prediction (NTP) objective..."
- Policy gradient: An RL method that updates model parameters by ascending the gradient of expected rewards under the policy’s rollout distribution. "optimizes for NSP using policy gradient updates."
- Policy model: The LLM viewed as a probabilistic policy generating token sequences for RL-based training. "We forward the sequence through the policy model and compute token-level entropy values."
- Reinforced Fast Weights with Next Sequence Prediction (ReFINE): The proposed RL framework that trains fast weight LMs with NSP using entropy-based sampling, sequence rewards, and GRPO. "We introduce ReFINE (Reinforced Fast weIghts with Next sEquence prediction), a reinforcement learning framework..."
- Reward assignment: The procedure of computing a scalar signal (e.g., similarity or exact match) for generated rollouts to guide RL updates. "Reward is computed based on the generated rollouts and ground truth tokens (Reward Assignment)."
- Rollout: A generated continuation sequence from a policy used to evaluate and assign rewards for sequence-level training. "generates multi-token rollouts"
- RULER: A long-context evaluation benchmark with retrieval and QA tasks across varying context lengths. "We evaluate mid-trained (MidTr) models on the NIAH tasks in RULER at 4K, 8K, and 16K context lengths..."
- Sequence-level rewards: Reward signals computed over multiple tokens of a continuation to capture semantic coherence beyond single-token accuracy. "assigns self-supervised sequence-level rewards, and optimizes the model with group relative policy optimization (GRPO)."
- Supervised fine-tuning (SFT): Gradient-based fine-tuning on labeled or instruction-response data, typically under the NTP objective. "SFT denotes the supervised fine-tuning with next-token prediction."
- Temperature parameter: A scalar controlling the sharpness of a probability distribution (e.g., softmax) during sampling. "where is a temperature parameter (we set if not specified)."
- Test-Time Training (TTT): Adapting model parameters during inference using self-supervised objectives to handle distribution shifts. "Test-Time Training (TTT) adapts model parameters at inference time using self-supervised objectives..."
Practical Applications
Overview
This paper introduces ReFINE (Reinforced Fast weIghts with Next sEquence prediction), an RL framework that improves long-context modeling in fast weight LLMs by optimizing a next-sequence prediction objective instead of traditional next-token prediction. ReFINE uses entropy-based token selection, multi-token rollouts, sequence-level rewards derived from hidden-state similarity, and GRPO optimization. It can be applied at mid-training, post-training (including nested within instruction tuning loops), and test-time training, and demonstrates consistent gains on long-context retrieval, multi-document QA, and diverse LongBench tasks.
The following lists summarize practical applications that can be deployed now and those that are more speculative or require further development. Each item includes sector alignment, potential tools/workflows, and assumptions or dependencies affecting feasibility.
Immediate Applications
These applications can be deployed with current tooling, leveraging the paper’s open-source implementation and demonstrated performance improvements on LaCT-760M and DeltaNet-1.3B.
- Long-document analysis and retrieval for enterprises
- Sector: finance, legal, compliance, insurance
- Use case: Needle-in-a-haystack retrieval across contracts, filings, and policy documents; long-context QA over heterogeneous document collections
- Tools/workflows: Insert a “ReFINE TTT step” before inference to adapt the model to each prompt; entropy-based token selection and sequence-level rewards on selected chunks; retain standard NTP loss to avoid catastrophic forgetting
- Assumptions/dependencies: Requires fast weight LLMs exposing entropy and hidden states; compute overhead for multi-token rollouts; governance for using test-time adaptation on regulated data
- Knowledge management and enterprise search assistants
- Sector: software, enterprise IT
- Use case: Multi-doc QA over intranet wikis, emails, and ticket histories; improved retrieval accuracy in long threads
- Tools/workflows: Deploy mid-trained ReFINE models; add nested ReFINE during post-training on task-specific prompts; enable configurable rollout length k and chunks c
- Assumptions/dependencies: Access to model internals and pretraining-like corpora for mid-training; content privacy constraints
- Code assistance across large repositories
- Sector: software engineering
- Use case: Cross-file navigation and generation in long repos; more robust reasoning over multi-file contexts
- Tools/workflows: Integrate a “ReFINE-in-IDE” plugin that runs TTT on the current workspace context; mid-train models on repo-like data
- Assumptions/dependencies: Hidden-state similarity reward correlates with semantic code understanding; policy safeguards to avoid drift during TTT
- Education: course notes and lecture transcript QA
- Sector: education
- Use case: Summarization and question answering over multi-lecture transcripts or long textbooks
- Tools/workflows: TTT on each lecture’s transcript; nested ReFINE within instruction tuning for educational QA tasks
- Assumptions/dependencies: Domain vocabulary alignment; careful reward configuration to avoid penalizing valid paraphrases
- Healthcare: longitudinal patient record summarization and cross-document QA
- Sector: healthcare
- Use case: Summaries and QA across EHR notes spanning thousands of tokens; improved information retrieval for clinical decision support
- Tools/workflows: On-prem ReFINE TTT on per-patient context; hybrid reward (exact match + hidden-state similarity) for memorization-sensitive tasks
- Assumptions/dependencies: HIPAA compliance; robust evaluation to mitigate hallucination; careful treatment of model drift during test-time updates
- Policy and legislative analysis
- Sector: public policy, government
- Use case: QA and synthesis across long bills, regulations, and committee reports
- Tools/workflows: Mid-train on public legislative corpora; apply nested ReFINE in post-training to adapt to legal QA tasks
- Assumptions/dependencies: Model access in secure environments; alignment with agency data policies
- Customer support and CRM analytics
- Sector: customer service, SaaS
- Use case: Retrieval and reasoning across long multi-ticket histories; improved multi-doc QA on support logs
- Tools/workflows: ReFINE TTT per customer session; entropy-guided token selection to focus on uncertain segments
- Assumptions/dependencies: Latency budgets for rollout generation; auditability of test-time updates
- On-device and edge long-context assistants
- Sector: mobile/edge computing
- Use case: Long-context summarization and QA within memory-constrained environments (fast weights have constant memory overhead)
- Tools/workflows: Lightweight ReFINE TTT with small k and c; cosine-similarity rewards for smooth adaptation on-device
- Assumptions/dependencies: Efficient inference kernels; secure handling of local data; performance scaling on edge hardware
- Model training and fine-tuning pipelines
- Sector: ML platforms/MLOps
- Use case: Drop-in “Nested ReFINE” module within instruction-tuning loops; mid-training for long-context capability uplift
- Tools/workflows: GRPO-based RL integration; dual-loss scheduling (λRL and λSFT); monitoring NTP accuracy improvements
- Assumptions/dependencies: RL stability tuning; reproducibility across runs; compute budgets for rollouts
- Label-efficiency improvements via self-supervised sequence rewards
- Sector: academia, industry R&D
- Use case: Reduce dependence on exact sequence labels by rewarding hidden-state alignment, enabling broader training over unlabeled corpora
- Tools/workflows: Sequence-level reward computation on pretraining-like data; entropy-weighted sampling for coverage
- Assumptions/dependencies: Hidden-state similarity is a suitable proxy for semantic alignment; domain adaptation may require hybrid rewards
Long-Term Applications
These applications likely require further research, scaling, architectural enhancements (e.g., fast-weight transfer across truncated prefixes), or broader ecosystem development.
- Next-generation long-context LLMs with fast weights as standard
- Sector: AI model providers
- Use case: Make ReFINE-style NSP + RL a default component of model training lifecycle for long-context performance without quadratic attention
- Tools/products: “ReFINE Adapter” library; fast-weight aware training schedulers; sequence-reward services
- Dependencies: Broader adoption of fast weight architectures; standardized APIs for hidden-state access; tuning stable rollout strategies
- Domain-specialized long-horizon memory agents
- Sector: healthcare, legal, scientific research
- Use case: Agents that continuously track and reason over patient timelines, case law corpora, or literature streams
- Tools/products: Persistent fast-weight memories with controlled TTT; dynamic rollout length selection; memory auditing tools
- Dependencies: Safety, transparency, and memory governance; dynamic reward functions beyond cosine similarity
- Large-scale codebase reasoning and refactoring agents
- Sector: software engineering
- Use case: Agents performing multi-step reasoning, refactoring, and design evolution across massive repositories
- Tools/products: Fast-weight code agents with ReFINE-based NSP training; project-wide memory scaffolds
- Dependencies: Program semantics-aware rewards; integration with CI/CD and version control; long-horizon correctness guarantees
- Financial analysis across long filings and time-series narratives
- Sector: finance
- Use case: Reasoning over lengthy 10-Ks, 10-Qs, and earnings call transcripts; tracking narratives across filings
- Tools/products: Financial Long-Context Assistant with hybrid rewards; rollouts tuned for narrative segments
- Dependencies: Compliance-approved deployment; robustness against subtle language shifts; reliable calibration of uncertainty
- Energy and industrial operations logs
- Sector: energy, manufacturing
- Use case: Sequence-level modeling of long operational logs; anomaly detection and cross-document incident reconstruction
- Tools/products: Fast-weight log intelligence systems; entropy-guided adaptation to uncertain segments
- Dependencies: Domain-specific reward engineering; stream processing infrastructure; causal analysis integration
- Edge robotics with long-horizon instruction following
- Sector: robotics
- Use case: Maintain coherent, multi-step plans from lengthy instruction streams with constant memory overhead
- Tools/products: Fast-weight policy modules; ReFINE-trained long-horizon planners
- Dependencies: Embodied reward shaping for sequences; safety and recovery mechanisms; hardware-aware training
- Long-form creative and editorial assistants
- Sector: media/publishing
- Use case: Track narrative consistency across book-length drafts; cross-chapter QA and style enforcement
- Tools/products: Editorial ReFINE workflows; semantic consistency rewards
- Dependencies: Rich semantic reward functions; tooling for editorial review and traceability
- Knowledge-graph-aware long-context reasoning
- Sector: research, enterprise data integration
- Use case: Sequence-level reasoning that aligns textual sequences with evolving knowledge graphs
- Tools/products: Hybrid reward combining hidden-state similarity and KG alignment; NSP-in-the-loop graph updates
- Dependencies: Scalable KG interfaces; semantic reward learning; evaluation protocols
- Distillation of NSP-improved fast weights into static models
- Sector: AI tooling
- Use case: Transfer long-context gains from fast weight models into standard transformer checkpoints
- Tools/products: Sequence-level distillation pipelines; teacher–student reward alignment
- Dependencies: Effective mapping from fast-weight dynamics to static parameters; evaluation on long-context benchmarks
- Architectural advances for efficient rollout generation
- Sector: AI systems research
- Use case: Efficient transfer of fast weights across truncated prefixes to reduce rollout costs, enabling larger k and c
- Tools/products: Memory-transfer operators; rollout schedulers; adaptive token selection strategies
- Dependencies: New kernels and runtime support; theoretical analyses of fast-weight stability and generalization
Cross-cutting assumptions and dependencies
- Access to fast weight models and internals: Entropy values, hidden states, and fast-weight update interfaces must be accessible for ReFINE.
- Reward design matters: Hidden-state cosine similarity rewards are effective but degrade with overly long rollouts; dynamic or richer rewards (e.g., edit distance, semantic similarity models) can improve robustness.
- Stability and safety: Test-time training introduces adaptation risks; dual-loss optimization (NSP RL + NTP SFT) and standardized advantages (as in GRPO) help prevent catastrophic forgetting and drift.
- Compute and latency trade-offs: Entropy-based selection and limited rollout lengths (e.g., k≈5, c≈8) balance adaptation efficacy with inference budgets; production systems need profiling and guardrails.
- Data governance: Applying TTT on sensitive data requires careful policy, logging, and opt-out mechanisms; compliance (HIPAA, GDPR, SOC2) must be considered.
- Generalization across domains: The assumption that hidden-state similarity is a good proxy for semantic alignment holds empirically but may need domain-specific calibration.
By integrating ReFINE into training and inference workflows, organizations can achieve practical, near-term gains in long-context tasks while laying the groundwork for more advanced, sequence-aware systems that scale efficiently and adapt robustly to complex, lengthy inputs.
Collections
Sign up for free to add this paper to one or more collections.