- The paper presents AutoMAS, an automated framework that transforms natural language intent into robust, scalable multi-agent workflows.
- It integrates LLM-based planning, variable call graphs, and a two-stage IR pipeline with agent enrichment and critique to improve precision and reliability.
- Experimental results on TaskBench and ToolE benchmarks show significant gains in recall, early precision, and overall workflow robustness compared to traditional methods.
Automated Agentic Workflow Composition via Agent Recommendation
The proliferation of general-purpose and specialized AI agents poses a complex orchestration problem: mapping high-level user intent to robust, dynamic, and minimally supervised multi-agent systems (MASs). Traditional approaches to MAS design involve significant manual intervention—plan decomposition, agent selection, and execution graph instantiation—creating bottlenecks in system scalability, adaptability, and robustness. The authors propose AutoMAS, an automated framework that utilizes LLMs, advanced IR pipelines, and structured critique mechanisms to bridge user intent and executable multi-agent workflows.
AutoMAS eliminates manual MAS assembly, offering:
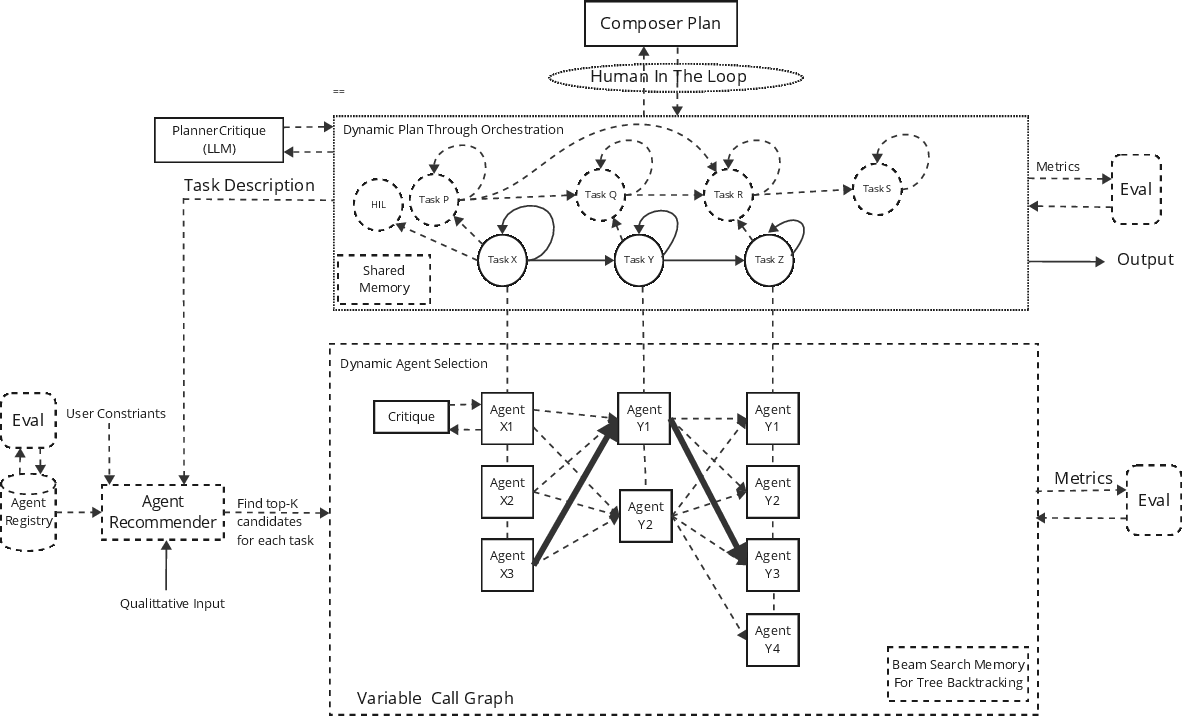
System Architecture
Planner and Dynamic Execution Graphs
User intent—expressed in natural language—is ingested by an LLM-based planner. The planner outputs a finite state machine (FSM) encoding tasks as nodes, supported by the optional use of episodic and semantic memory for retrieval augmentation. This representation enables both sequential and non-sequential workflows, accommodating alternative execution paths to support robustness and fault tolerance.
Variable Call Graphs (VCG) and Human-in-the-Loop
VCG enables dynamic selection of execution pathways, leveraging multiple agent candidates per task. Route selection is adaptive to runtime constraints (e.g., network outages, latency, cost policy), ensuring continuous system operation under varying conditions. The architecture natively supports human-in-the-loop (HITL) interventions, allowing supervisors to intercede during both design and runtime phases.
Agent Recommender Pipeline
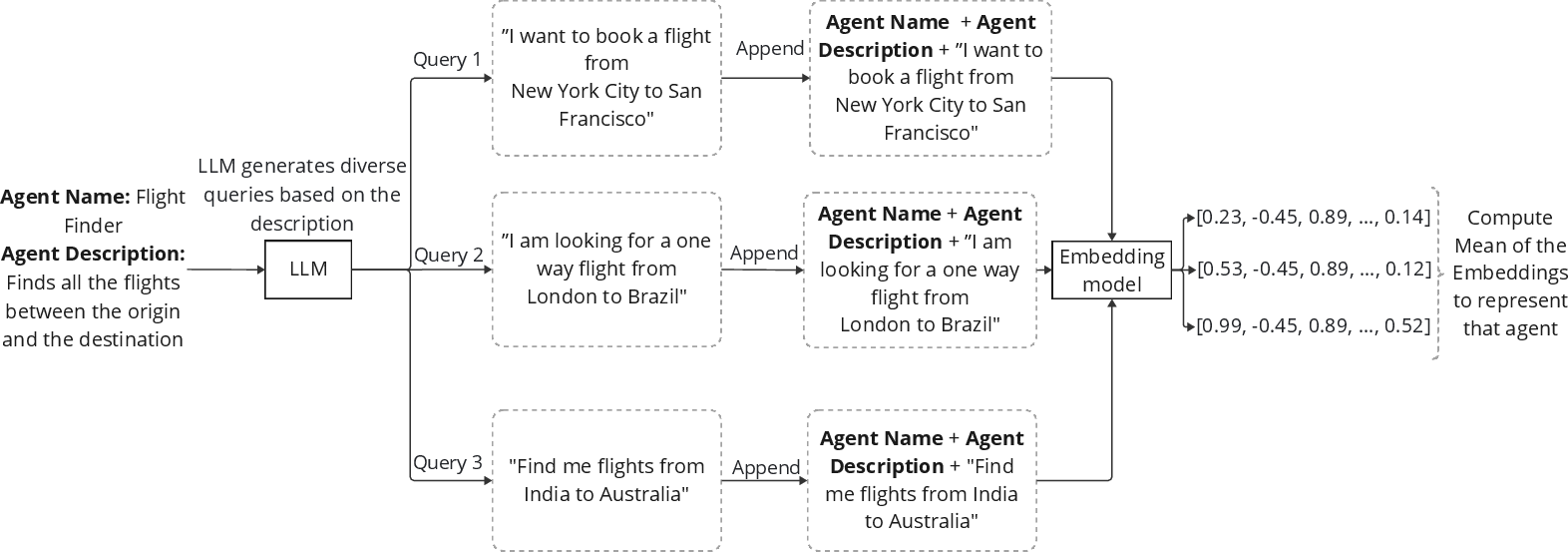
The agent recommender is built around a modular two-stage IR pipeline: a fast hybrid retriever based on dense and sparse features (e.g., OpenAI text-embedding-3-large, BM25), followed by an LLM-based semantic re-ranker.
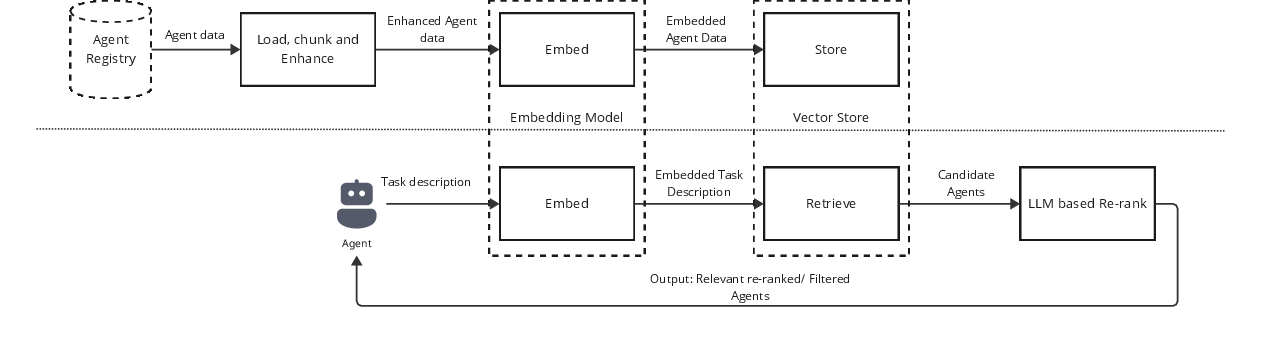
Figure 2: Agent Recommender with enrichment, retrieval, and re-ranking phases.
The recommender pipeline is uniquely augmented with:
Results show that these design choices consistently yield improved nDCG, recall, and mAP relative to standard retrieval baselines.
Critique Mechanism
A multi-mode LLM-based critique stage evaluates the local and global adequacy of the agent-task mapping. Locally, the critique checks task-agent fit; globally, it verifies input-output compatibility, constraint satisfaction (e.g., cost, safety), and workflow optimality. On identification of deficiencies, the critique provides targeted feedback—sometimes structured as partial corrections—to the planner or pipeline, iteratively refining results.
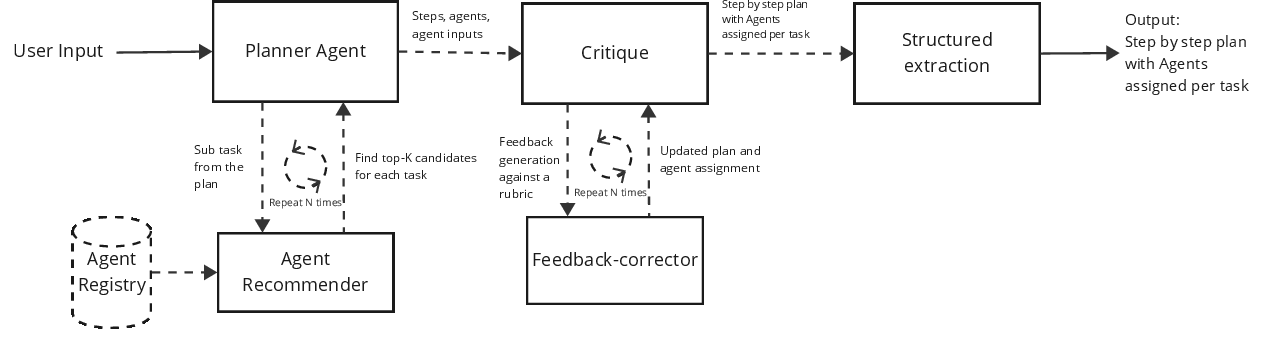
Figure 4: ReAct Style Planning architecture with integrated critique loop enabling iterative correction and enhanced workflow quality.
Experimental Analysis
Agent Recommendation
Experiments were conducted on the ToolE benchmark (199 agents, 20K+ query-tool pairs). Key insights include:
- Larger embedding models (text-embedding-3-large) improve recall, especially in the absence of re-ranking.
- Application of LLM re-rankers (e.g., GPT-4o, O1) significantly boosts nDCG@1 by over 10 points, indicating stronger early precision—a critical factor for MAS usability.
- Enrichment via synthetic query augmentation incrementally lifts recall and mAP with negligible inference cost.
- LLM-based filtering, combined with enrichment, offers maximal boost to recall (up to 0.84) and mAP (over 0.81).
Strong empirical results establish that AutoMAS substantially outperforms both sparse and dense search baselines, as well as recent state-of-the-art like Re-Invoke, under a variety of ranking metrics.
End-to-End MAS Planning and Workflow Execution
A comprehensive pipeline evaluation was conducted using the TaskBench dataset across three tool domains (everyday APIs, ML APIs, multimedia APIs) and over 17,000 queries.
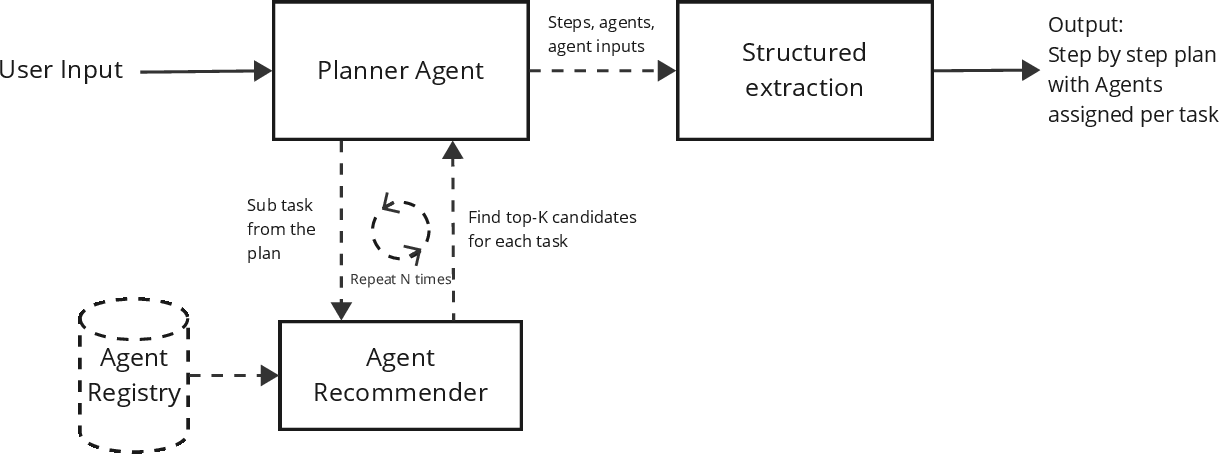
Figure 5: ReAct Style MAS composition loop, where the planner iteratively assigns agents via the recommender pipeline for effective sub-task execution.
Semantic scoring (Rouge, BERTScore) and LLM-as-a-judge approaches indicate that overall plan quality is high, though not fully captured by surface-level text similarity metrics. Structured prediction metrics (Tool/Node F1, sequence similarity) and argument specification F1 on TaskBench reveal stepwise improvements across agent categories, with Tool Name F1 consistently exceeding 0.90 in everyday domains and sequence similarity approaching 0.90, indicating that the system reliably installs appropriate task dependencies and agent assignments.
With the critique-enabled iterative correction mechanism, further gains are reported. Tool/Node F1, Sequence Similarity, and N-tools accuracy all show measurable improvement, validating the utility of critique both at the single-agent selection and global workflow levels.
Implications and Theoretical Significance
Scalability: The separation of retrieval and deliberative (re-ranking/critique) stages allows the system to accommodate agent registries on the order of thousands of entries—a practical infeasibility for standard context-packing LLM approaches, which are bottlenecked by context window size, computational cost, and LLM cache locality.
Robustness: Redundancy and dynamic rerouting (VCG) future-proof workflows against agent/system failures and shifting runtime constraints. Agent enrichment and critique further insulate the system from brittle or semantically opaque agent metadata.
Generalization: The design is generalizable to arbitrary MAS-based applications, including workflow automation, embodied AI, and autonomous software agents.
Limitations: The critique’s inability to propose alternative candidates outside the current retrieval set exposes a ceiling for iterative improvement; joint optimization of retrieval and critique (integrated retrieval-critique loops) remains an open area for future work.
Future Directions
- Joint critique-retrieval optimization: Exploring feedback loops where the critique dynamically adjusts retrieval constraints or queries, potentially cascading improvements in both recall and global workflow satisfaction.
- Fine-tuning and prompt engineering of LLM re-rankers: Alleviating observed cost/latency biases and improving instruction consistency.
- Flexible, modular ingestion pipelines: Decoupling indexing from querying to support context-sensitive inclusion/exclusion of agents/tools, further maximizing flexibility and scalability.
Conclusion
AutoMAS codifies an effective pipeline for translating natural language user intent into executable, robust, and high-fidelity MAS workflows by leveraging a hybrid IR architecture, agent description enrichment, and structured LLM critique. Its empirical advantage in both recall and precision, scalable IR-driven design, and robust dynamic planning set a new standard for agentic workflow composition. Limitations regarding critique-retrieval interplay and evaluation methodology are recognized and motivate ongoing research. AutoMAS provides a solid foundation for flexible, large-scale MAS engineering, subsuming prior manual and context-saturated approaches and opening new directions for intelligent agent discovery, selection, and orchestration.
Reference:
"From Intent to Execution: Composing Agentic Workflows with Agent Recommendation" (2605.03986)