Automated Composition of Agents: A Knapsack Approach for Agentic Component Selection
Abstract: Designing effective agentic systems requires the seamless composition and integration of agents, tools, and models within dynamic and uncertain environments. Most existing methods rely on static, semantic retrieval approaches for tool or agent discovery. However, effective reuse and composition of existing components remain challenging due to incomplete capability descriptions and the limitations of retrieval methods. Component selection suffers because the decisions are not based on capability, cost, and real-time utility. To address these challenges, we introduce a structured, automated framework for agentic system composition that is inspired by the knapsack problem. Our framework enables a composer agent to systematically identify, select, and assemble an optimal set of agentic components by jointly considering performance, budget constraints, and compatibility. By dynamically testing candidate components and modeling their utility in real-time, our approach streamlines the assembly of agentic systems and facilitates scalable reuse of resources. Empirical evaluation with Claude 3.5 Sonnet across five benchmarking datasets shows that our online-knapsack-based composer consistently lies on the Pareto frontier, achieving higher success rates at significantly lower component costs compared to our baselines. In the single-agent setup, the online knapsack composer shows a success rate improvement of up to 31.6% in comparison to the retrieval baselines. In multi-agent systems, the online knapsack composer increases success rate from 37% to 87% when agents are selected from an agent inventory of 100+ agents. The substantial performance gap confirms the robust adaptability of our method across diverse domains and budget constraints.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
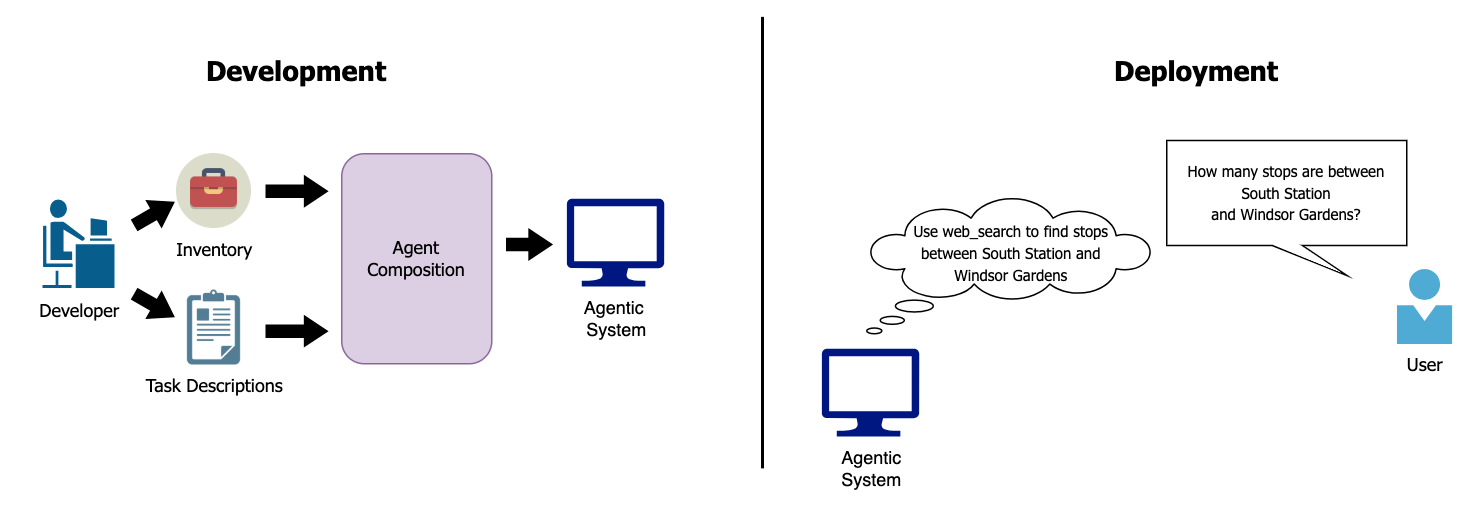
This paper is about building smarter AI “agents” by automatically choosing the right parts for them. An AI agent is like a helpful digital teammate that can think, use tools (like web search or a calculator), and sometimes work with other AI agents. The problem is: there are tons of tools and agents to pick from, and they cost money. The paper shows a way to pick the best mix of parts that work well together, fit a budget, and actually help the agent solve tasks.
What questions did the researchers ask?
They focused on three simple questions:
- How can we select the best tools and agents for a task without going over budget?
- How do we know which parts really help, not just sound good in their descriptions?
- Can we build single agents and teams of agents that perform better and cost less than current methods?
How did they do it?
The “backpack” (knapsack) idea
Imagine you have a backpack with limited space and a bunch of items to choose from. Each item has a “value” (how useful it is) and a “weight” (how much space it takes). You want the combination of items that gives you the most value without overloading your backpack.
The paper treats agent building the same way:
- Budget = backpack size
- Tools/agents = items
- Their usefulness = value
- Their cost = weight
Different ways to choose parts
They tried several “composers” (ways to pick components):
- Identity: Pick everything in the inventory. Easy, but often wasteful and confusing.
- Retrieval: Pick components that have descriptions matching the task. Fast, but descriptions can be misleading.
- Offline knapsack: Use descriptions and a math solver to choose the best set under budget. Smarter than plain matching, but still trusts descriptions.
- Online knapsack (their main method): Don’t just read descriptions—test components in real time on small practice questions, score their actual performance, and pick only those that give the best value for the cost.
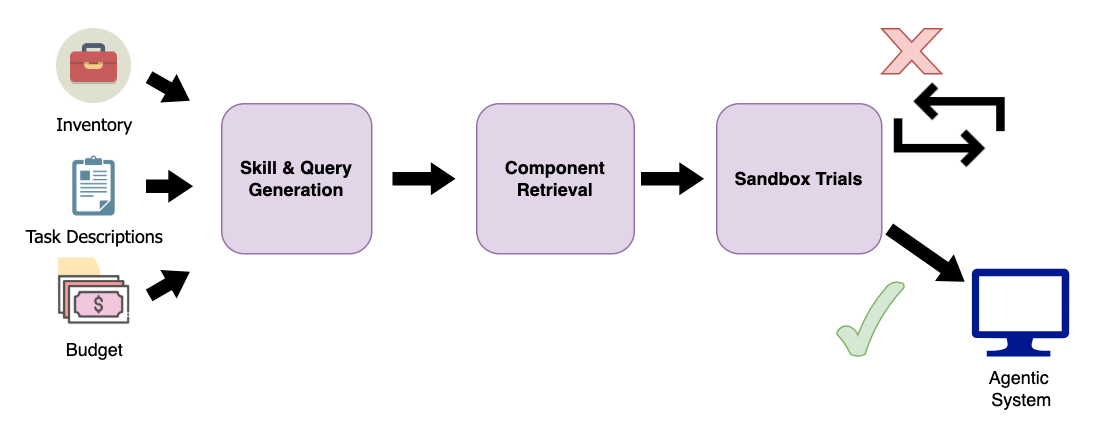
Testing tools in a “sandbox”
A sandbox is like a safe test room. The composer agent:
- Breaks the task into “skills” (for example, web search, code help, science facts).
- Generates tiny test questions for each skill (like “Find today’s Apple stock price” for web search).
- Tries the candidate tools/agents on these questions.
- Judges their real, observed performance.
This way, it uses real results, not just marketing claims in the descriptions.
Choosing with a moving threshold
Their online method uses a known algorithm (called ZCL for online knapsack) that sets a “moving bar” for how good a component must be per dollar. As you spend more of the budget, the bar gets stricter. So only tools with strong “value-for-cost” get picked. This keeps performance high while staying under budget.
What did they find?
They tested their method with Claude 3.5 Sonnet on several benchmarks:
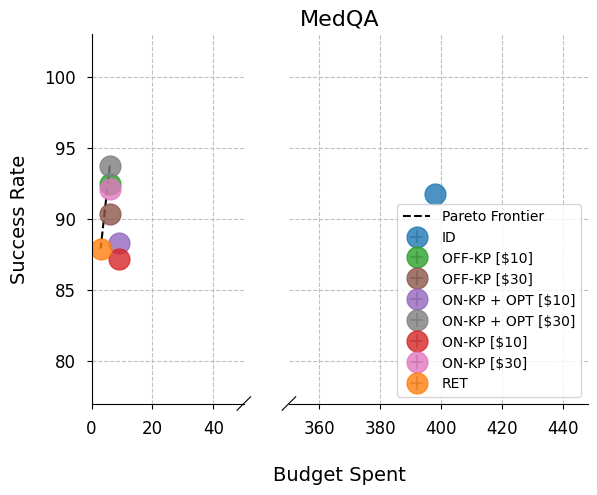
- Single-agent tasks (tools for one agent): GAIA, SimpleQA, and MedQA
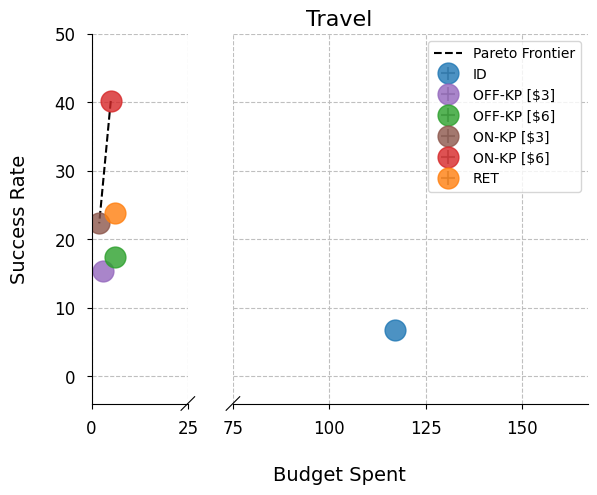
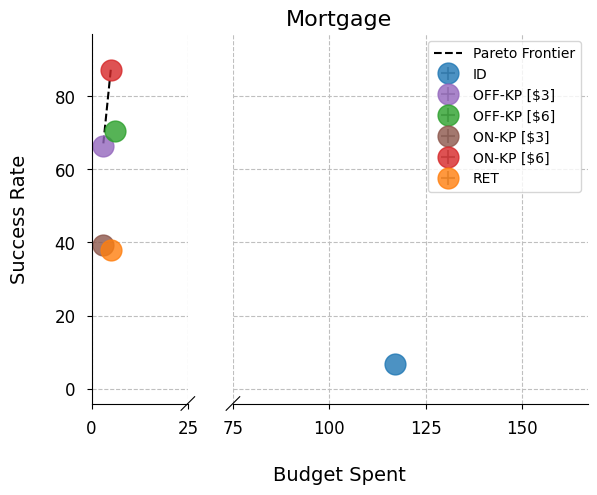
- Multi-agent teams (picking sub-agents): travel and mortgage scenarios
Key results:
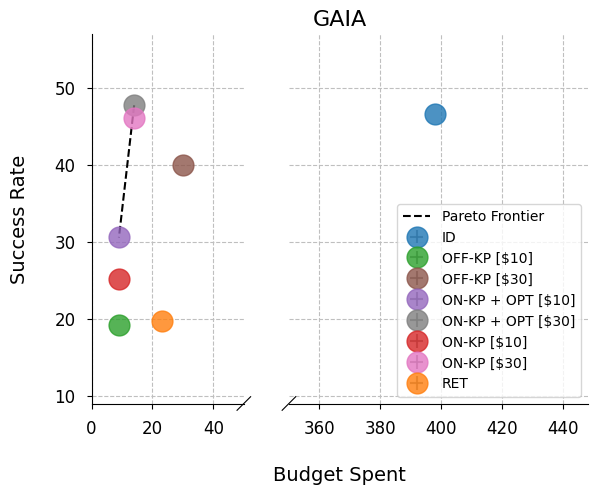
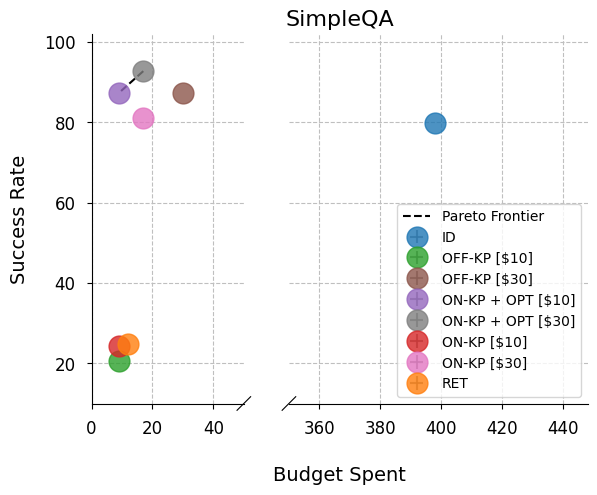
- The online knapsack composer often sits on the Pareto frontier. That means no other approach beat it in both success rate and lower cost at the same time.
- Single agent: up to 31.6% higher success rate than retrieval-based methods.
- Multi-agent: success rate jumped from 37% to 87% when choosing from 100+ agents.
- In many cases, it achieved higher accuracy while spending less on tools.
- Adding a bit of prompt optimization (called AvaTaR) after selection sometimes boosted results further.
Why this matters:
- It proves that “test before you trust” works. Real-time testing beats picking parts based only on their descriptions.
- It saves money while improving performance—important for running agents in the real world.
Why does it matter?
This approach helps developers build stronger, cheaper AI systems faster. Instead of guessing which tools or agents will help, the composer:
- Figures out what skills are needed,
- Tries different components,
- Measures which ones really work,
- Picks the best mix under budget.
This can:
- Make single agents better at tasks like research, coding help, or medical Q&A.
- Make multi-agent teams smarter at coordinating complex jobs (like planning trips or handling mortgage scenarios).
- Scale across changing environments where tools get updated or tasks evolve.
Final thoughts: impact and future directions
The method shows a practical way to build reliable AI agents without breaking the bank. It’s useful for companies and developers who have big “inventories” of tools and agents and need a clean, cost-aware way to assemble them.
The authors note some limits and future improvements:
- It works best when the task is clearly described.
- Testing takes extra time (like short “test drives”).
- There may be even better ways to compose agents, like learning from past builds.
- We must keep an eye on safety, so bad or malicious tools don’t slip in.
Overall, the paper’s main takeaway is simple: if you want better AI agents, don’t just read tool descriptions—test them, measure their value for cost, and pick the best set with a smart “backpack” strategy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item identifies a concrete gap that future work could address.
- Formal model of success probability: The paper defines conceptually but does not provide a principled, estimable model that captures non-additive interactions (synergies/conflicts), diminishing returns, or redundancy among components.
- Explicit compatibility modeling: Despite mentioning compatibility, the implementation evaluates components independently; there is no method to detect or penalize conflicts between tools/agents or to reward positive synergies among selected components.
- Combination-level testing: The composer evaluates components individually per skill; it does not test pairs or sets of components together, risking missed interactions that alter real-world performance.
- Value estimation robustness: Component “value” is inferred from a small number of LLM-generated test questions and LLM judgments; the reliability, bias, and variance of this process are not quantified or controlled.
- ZCL threshold parameterization: The online knapsack relies on bounds and for value-to-cost ratios, but the paper does not rigorously justify how these are estimated, nor analyze sensitivity to noisy or mis-specified bounds.
- Alternative online selection algorithms: The paper does not compare ZCL against other online knapsack or resource allocation methods (e.g., primal-dual, prophet inequalities, contextual bandits with knapsack constraints) that may be more robust to uncertain values.
- Sample efficiency of sandboxing: There is no analysis of how many test questions per skill are needed for reliable value estimation, nor adaptive strategies to allocate testing budget (active testing) efficiently.
- Skill extraction quality and ontology alignment: The LLM-generated skills are assumed correct; there is no evaluation of skill granularity, coverage, or alignment to a tool/agent taxonomy, and no mechanism to correct mis-specified skills.
- Redundancy and multi-component coverage per skill: The composer stops after selecting one component per skill, potentially missing beneficial complementary tools/agents; strategies to select multiple components per skill are untested.
- Cost modeling realism: Tool costs are approximated and do not account for latency, rate limits, dynamic pricing, failure rates, or energy usage; multi-agent experiments use uniform costs, obscuring real-world trade-offs.
- Multi-objective optimization: The selection optimizes success rate under a dollar budget only; latency, reliability, rate-limit resilience, and energy are not modeled, nor is a multi-objective framework explored.
- Statistical rigor and reproducibility: Most results lack confidence intervals, significance tests, and detailed run-to-run variability; sensitivity to seeds, number of test queries, and in retrieval is not reported.
- Baseline strength and coverage: Comparisons exclude stronger recent baselines (e.g., ToolGen, Re-Invoke, RAG-MCP, generative tool selection), leaving unclear how the method stacks up against state-of-the-art alternatives.
- Scope of datasets and domains: Evaluations are limited to GAIA (smolagents), SimpleQA, MedQA, and two simulated enterprise domains; broader, real-world, long-horizon, multi-modal, and code-heavy tasks are not assessed.
- Real API integration in multi-agent experiments: Multi-agent tools are simulated; there is no validation with live APIs subject to real failures, rate limits, authentication, and data quality issues.
- Model generalization: Results primarily use Claude models; robustness across diverse LLM families (Llama, Qwen, GPT, etc.), sizes, and tool-calling frameworks is insufficiently characterized.
- Live, in-situ adaptation: Composition is decided pre-deployment; the composer does not reconfigure teams/tools during live inference when requirements, budgets, or tool availability change.
- Scaling to large inventories: The approach is tested with ~120 tools and ~117 agents; computational and economic feasibility for inventories of thousands (common in enterprises) is not analyzed, nor are caching/indexing or meta-profiling strategies.
- Dynamic inventories and drift: Although mentioned, there is no evaluation of incremental recomposition as tools/agents change, nor detection and mitigation of performance drift over time.
- Prompt optimization integration: AvaTaR sometimes regresses performance; a more principled, automated way to integrate prompt optimization with composition (including guardrails to prevent regressions) is missing.
- Formal treatment of compatibility constraints: No constraint language or solver is presented to encode compatibility (e.g., versioning, API contracts, security policies) during selection.
- Security and adversarial robustness: There is no formal threat model or defense against malicious, brittle, or gaming tools/agents; automated vetting, provenance checks, and fuzz testing are not integrated into the composer.
- Theoretical guarantees under noisy evaluation: The competitive guarantees of ZCL assume accurate estimates; the impact of noisy sandbox judgments on regret/competitive ratio is not analyzed.
- Oracle and upper-bound baselines: There is no oracle baseline (e.g., perfect information or hindsight optimum) to quantify the gap between the composer and the best achievable composition under the given budget.
- Effect of heuristic optimizations: Early-stopping and “do not reassess covered skills” shortcuts are introduced but not ablated; their impact on accuracy, runtime, and missed opportunities is unclear.
- Interpretability of selection decisions: There is no mechanism to explain why components were selected or rejected, making auditing and debugging of the composer difficult.
- Ethics, fairness, and governance: Potential biases from budget-driven selection (e.g., preferring cheaper tools with lower reliability), environmental costs, and governance controls for safe composition are not addressed.
- Formalization clarity: Equations contain typographical errors and ad-hoc scaling (e.g., normalized using ), indicating a need for a cleaner, consistent mathematical specification linked to implementation.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s composer agent, online-knapsack selection, and sandbox testing workflow. Each item notes sector alignment and key assumptions or dependencies.
- Cost-aware agent composition for LLM platforms (Software/AI Platforms)
- Use case: Integrate the “composer agent” into existing agent frameworks (e.g., CodeAct, ReAct) to automatically pick the best subset of tools/models/prompts under a budget for specific tasks (e.g., web research, coding help, file handling).
- Emergent product/workflow: Composer-as-a-Service API that ingests a task description and an inventory and returns a deployable agent configuration; Pareto planner dashboards showing accuracy vs. cost.
- Assumptions/Dependencies: Requires a curated inventory with costs and descriptions, an embedding retriever, sandbox environments to test tools, and reliable “judge” prompts; task descriptions must be sufficiently clear.
- Enterprise tool marketplace optimization (Software, Finance/Operations)
- Use case: Optimize selection from internal API registries (or external marketplaces) to meet performance targets within spend limits, replacing manual curation or metadata-only retrieval.
- Emergent product/workflow: Budget-aware tool picker for internal developer portals; cost-utility scorecards; procurement-ready evaluation reports grounded in sandbox trials.
- Assumptions/Dependencies: Accurate cost models per API/tool; stable API throttling and pricing; up-to-date capability descriptions; access policies and SLAs for external tools.
- Multi-agent team builder for operational workflows (Travel, Mortgage, Customer Ops)
- Use case: Select specialized sub-agents for supervisor-led teams (MAC-style) to handle domain tasks (e.g., itinerary planning, eligibility checking, document triage) with higher success under fixed budgets.
- Emergent product/workflow: Team Composer that picks 3–6 sub-agents from large inventories; runbooks for delegation and coverage; success assertion checks for end-to-end simulations.
- Assumptions/Dependencies: Uniform or well-estimated per-agent costs; reliable simulation of tools; compatible supervisor prompts; domain-specific assertions/tests.
- Evidence-seeking healthcare assistants (Healthcare)
- Use case: Assemble research-oriented clinical assistants that prioritize PubMed, arXiv, Semantic Scholar for answer validation and citations (MedQA-like tasks).
- Emergent product/workflow: Literature triage bot for clinicians/researchers; “capability gatekeeper” that screens tools for evidence retrieval and explains trade-offs (paid vs. free search).
- Assumptions/Dependencies: Non-diagnostic positioning; HIPAA/PHI safeguards; medical content verification; tool compliance and audit trails.
- Customer support and knowledge assistants (CX, Knowledge Work)
- Use case: Compose helpdesk or internal Q&A agents that dynamically choose search, knowledge base, or file-parsing tools to improve factuality (SimpleQA-like tasks).
- Emergent product/workflow: Plugin selector that prefers reliable, high-coverage sources; fallback logic for API failure; reproducible sandbox scoring for tool utility.
- Assumptions/Dependencies: High-quality KB indexing and retrievers; consistent tool uptime; transparent tool schemas to avoid “distractor” tools.
- Budget-aware A/B testing harness for agent components (MLOps/AgentOps)
- Use case: Continuously test candidate tools/sub-agents using generated skill queries; accept components only if value-to-cost exceeds threshold (ZCL).
- Emergent product/workflow: Sandbox QA harness; automated test generation per skill; judge prompts and logging; regression tracking.
- Assumptions/Dependencies: Stable generation of representative test queries; reliable judging criteria; ongoing maintenance of bounds for value-to-cost ratios.
- Prompt optimization loop bootstrapped from sandbox traces (Software/Developer Tools)
- Use case: Apply AvaTaR-style contrastive reasoning optimization to agent prompts using trajectories collected during tool testing to improve tool invocation policies.
- Emergent product/workflow: Composer+Adapter pipeline that first selects tools, then optimizes prompts; versioned prompt catalogs and rollback safeguards.
- Assumptions/Dependencies: Optimization can regress in some settings; requires enough diverse traces; robust evaluation to avoid overfitting to tests.
- Security and reliability gating for agent inventories (Security/Compliance)
- Use case: Detect “distractor” or non-operable tools through sandboxing; gate tool inclusion via minimum utility thresholds and compatibility checks.
- Emergent product/workflow: Capability-validation gate; allowlists/denylists updated by empirical utility; anomaly detection for tool updates.
- Assumptions/Dependencies: Sandboxing isolates side effects; adversarial tool behaviors may still evade simple tests; ongoing revalidation after provider updates.
- Educational research assistants (Education)
- Use case: Compose classroom or campus assistants that select credible reference tools (e.g., Wikipedia, Semantic Scholar) while staying within quotas.
- Emergent product/workflow: Course-specific agent configurations; usage budgeting; citation reporting workflows.
- Assumptions/Dependencies: Age-appropriate content filters; LMS integration; reliable throttling management for free vs. paid APIs.
- Cost governance for agent operations (Finance/FinOps for AI)
- Use case: Implement spend controls and Pareto analysis across agent deployments; determine when paid APIs materially improve outcomes vs. free/limited tools.
- Emergent product/workflow: Agent Cost Controller; budget checkpoints; periodic recomposition as inventories/pricing change.
- Assumptions/Dependencies: Accurate metering; traceability of costs to outcomes; policy hooks for approvals.
Long-Term Applications
These applications build on the paper’s approach but require further research, scaling, standardization, or integration.
- Learning-based composer that adapts from historical deployments (Software/AI Research)
- Use case: Move from rule-based online knapsack to experience-driven selection (e.g., RL/MDP formulations), learning synergy patterns and environment dynamics.
- Emergent product/workflow: Continuous Composer that updates policies from outcome telemetry; cohort-specific policies per domain.
- Assumptions/Dependencies: Logged data availability and privacy controls; robust off-policy evaluation; generalization across domains.
- Synergy-aware optimization for non-additive interactions (AI Optimization)
- Use case: Model component interactions (positive/negative couplings) beyond additive values, e.g., quadratic knapsack or multi-objective formulations.
- Emergent product/workflow: Interaction-aware composer; compatibility matrices; joint prompt-tool co-optimization.
- Assumptions/Dependencies: Data on pairwise/group interactions; tractable optimization under combinatorial explosion; explainability of choices.
- Internet-scale agent network orchestration (Software/IoA)
- Use case: Compose from thousands of heterogeneous agents/tools across open marketplaces, balancing performance, cost, latency, and reliability.
- Emergent product/workflow: Agent Registry Optimizer; MCP-aligned capability schemas; standardized discovery and trust signals.
- Assumptions/Dependencies: Schema and protocol standardization (e.g., MCP); provider cooperation; reputation systems and governance.
- Real-time adaptive composition under API drift and changing requirements (DevOps/AgentOps)
- Use case: Continuous revalidation and recomposition as tools update, quotas change, or task requirements evolve.
- Emergent product/workflow: Live recomposition pipelines; canary tests; SLO-aware switching between free/paid tools.
- Assumptions/Dependencies: Observability across providers; rapid sandboxing at scale; safe rollback mechanisms.
- Regulated deployments in healthcare and finance with risk scoring (Policy/Compliance)
- Use case: Bake empirical utility, auditability, and budget discipline into procurement and deployment frameworks for high-stakes domains.
- Emergent product/workflow: Compliance composer with risk scores; audit trails; evidence provenance tracking.
- Assumptions/Dependencies: Domain-specific standards and certifications; legal alignment; secure data handling and model governance.
- Agentic app store with budget-aware composition and governance (Platforms/Marketplaces)
- Use case: End-user or developer-facing marketplace where tools/agents are selected via knapsack-based policies and verified via sandbox trials.
- Emergent product/workflow: “Agentic App Store” with trust marks, cost-utility badges, and auto-composed bundles.
- Assumptions/Dependencies: Vendor integration; scalable testing infrastructure; fraud detection; pricing transparency.
- Robotics and IoT orchestration with cost/time/energy constraints (Robotics/Energy/IoT)
- Use case: Compose control and perception modules considering energy/time budgets and reliability for edge devices or robots.
- Emergent product/workflow: Edge Composer; simulators generating skill tests; latency-aware thresholds.
- Assumptions/Dependencies: High-fidelity simulation; real-time constraints; hardware compatibility and safety validation.
- Grid and facility energy management agents (Energy)
- Use case: Select forecasting, optimization, and control components under operational cost/utility trade-offs.
- Emergent product/workflow: Energy Ops Composer; rolling recomposition with seasonal drift; multi-objective targets (cost, emissions, reliability).
- Assumptions/Dependencies: Accurate telemetry; integration with SCADA/BMS; regulatory compliance.
- Campus-scale educational assistants orchestration (Education)
- Use case: Compose assistants across courses and departments with shared inventories and governance.
- Emergent product/workflow: LMS-integrated composer; domain-specific toolkits; cost caps per course.
- Assumptions/Dependencies: Privacy-compliant data sharing; content provenance and safety; faculty oversight.
- Capability schema standardization and tool governance (Standards/Policy)
- Use case: Define robust capability descriptors, test suites, and evaluation metrics for agentic components beyond textual descriptions.
- Emergent product/workflow: Capability ontologies; conformance tests; public scorecards for utility and safety.
- Assumptions/Dependencies: Consortium buy-in; interoperability with existing protocols; maintenance of shared benchmarks.
- Robust prompt and workflow co-optimization beyond AvaTaR (AI Research)
- Use case: Develop more resilient optimization methods that avoid regressions and capture cross-tool invocation policies.
- Emergent product/workflow: Hybrid symbolic–neural adapters; safety-aware optimization; meta-learning across tasks.
- Assumptions/Dependencies: Large, diverse training corpora of agent trajectories; robust evaluation suites.
- Public-sector procurement guidelines incorporating knapsack evaluation (Policy/Government)
- Use case: Standardize budget-constrained, utility-tested selection of AI tools and agents for civic deployments.
- Emergent product/workflow: Policy playbooks; auditing templates; transparent selection criteria with sandbox evidence.
- Assumptions/Dependencies: Training and capacity building; legal frameworks; oversight bodies for enforcement.
Glossary
- ADAS (Automated Design of Agentic Systems): A research area focused on automatically creating and configuring agent-based system designs. "introduce the problem of automated design of agentic systems (ADAS), where the goal is to ``automatically create powerful agentic system designs, including inventing novel building blocks and/or combining them in new ways''."
- Agent composition: The task of selecting and assembling existing agent components to satisfy task requirements under constraints. "we introduce agent composition as a knapsack problem,"
- Agent inventory: A catalog of available agents from which a system can select for composition. "when agents are selected from an agent inventory of 100+ agents."
- Agent selection problem: The optimization task of choosing a subset of agents to form an effective team or system. "DyLAN~\cite{liu2024dynamic} introduce the agent selection problem and train a feed-forward network to optimize the selection."
- Agentic components: Modular building blocks such as tools, models, or sub-agents used to construct agentic systems. "assemble an optimal set of agentic components"
- Agentic supernet: A large, over-parameterized architecture that encodes many possible multi-agent designs, enabling search over sub-architectures. "Multi-agent Architecture Search~\cite{zhang2025multiagentsearch} optimizes an agentic supernet"
- Agentic system composition: The process of structuring and integrating components to form an agentic system. "a structured, automated framework for agentic system composition"
- Agentic systems: AI systems built from interacting agents, tools, and models that act and reason in dynamic environments. "Designing effective agentic systems requires the seamless composition and integration of agents, tools, and models within dynamic and uncertain environments."
- AvaTaR: A prompt-optimization method for improving tool usage in LLM agents via contrastive reasoning. "we conduct tool selection through online knapsack and then conduct an additional round of prompt optimization using AvaTaR"
- Branch-and-bound methods: Exact optimization algorithms that prune search spaces using bounds to solve combinatorial problems. "Offline algorithms, such as dynamic programming~\cite{andonov2000unbounded} and branch-and-bound methods~\cite{martello1990knapsack}, assume complete knowledge of all items in advance"
- CodeAct: An agent framework where the model writes executable code to invoke tools. "We fix the agent workflow to CodeAct~\cite{wang2024executable},"
- Composer agent: A controller that discovers, evaluates, and selects components to assemble an agentic system. "We present the composer agent, which is responsible for selecting components through an iterative process of discovery and adaptation."
- Constrained optimization problem: An optimization task with objective and explicit constraints (e.g., budget, coverage). "A formalization of agent composition as a constrained optimization problem that jointly considers capability, cost, and compatibility,"
- DCOP (Distributed Constraint Optimization Problems): A framework where distributed agents assign values to variables to minimize global cost under constraints. "The component selection problem also relates to Distributed Constraint Optimization Problems (DCOP)~\cite{fioretto2018distributed},"
- GAIA: A benchmark evaluating general AI assistants on real-world, tool-using, and reasoning tasks. "GAIA~\cite{mialon2023gaia}, which stands for General AI Assistants, is a comprehensive evaluation framework"
- Hierarchical multi-agent collaboration (MAC): An architecture with a supervisor agent delegating to specialized sub-agents. "assumes a hierarchical multi-agent collaboration (MAC) architecture"
- Knapsack problem: A classic optimization problem of selecting items with values and costs to maximize value under a budget. "The knapsack problem, a classic optimization challenge, has been extensively studied in algorithmic research"
- Linear programming: A mathematical optimization technique for linear objectives and constraints. "we use linear programming to find the optimal solution for this multiple-choice knapsack problem"
- Markov Decision Process (MDP): A formalism for sequential decision-making under uncertainty defined by states, actions, transitions, and rewards. "such as formulating agent composition as a Markov Decision Process."
- Model Context Protocol (MCP): A protocol to standardize and streamline how LLMs interact with external tools and contexts. "RAG-MCP \cite{rag-mcp} combines RAG with the Model Context Protocol (MCP) to improve how LLMs select external tools."
- Multiple-choice knapsack problem: A knapsack variant where one item must be chosen from each group (e.g., per skill) under a budget. "this multiple-choice knapsack problem"
- Non-additive interactions: Component effects that are not independent, exhibiting synergies or conflicts when combined. "components frequently exhibit non-additive interactions, either positive synergies or detrimental conflicts,"
- Online knapsack: A knapsack setting where items arrive sequentially with unknown future and must be accepted or rejected on the fly. "we propose an online knapsack composer that iteratively tests the candidate component to assess its true value"
- Pareto frontier: The set of non-dominated solutions that improve no objective without worsening another (e.g., accuracy vs. cost). "our online-knapsack-based composer consistently lies on the Pareto frontier,"
- QoS-aware: Design or selection that accounts for Quality-of-Service attributes like latency, reliability, or throughput. "particularly for QoS-aware web service composition"
- RAG (Retrieval-Augmented Generation): Technique where a model retrieves external information to augment generation, improving accuracy. "RAG-MCP combines RAG with the Model Context Protocol (MCP)"
- ReAct: A prompting paradigm combining reasoning traces with action execution (e.g., tool calls). "We set up ReAct tool-calling agents as done in the paper~\cite{yaoreact}"
- Retrieval Composer: A composer variant that selects components purely via semantic matching to generated skills. "Retrieval Composer: Next, we should consider taking natural language descriptions into account when designing a more intelligent composer."
- Sandbox trials: Controlled tests that empirically evaluate component behavior and utility before deployment. "The sandbox trials measure not just what a component claims to do, but how reliably it performs under varying conditions and interactions."
- Semantic retrieval: Using embeddings or semantic similarity to find components matching textual descriptions. "Most existing methods rely on static, semantic retrieval approaches for tool or agent discovery."
- Tool Retrieval: The task of identifying the most relevant external tools for an agent to use. "Tool Retrieval"
- Value-to-cost ratio: A metric dividing estimated utility by cost to decide whether to include a component under budget. "only accepts an incoming item if its value-to-cost ratio exceeds the threshold"
- Value-to-weight ratio: In knapsack, the value divided by weight (cost), guiding greedy or threshold-based selection. "proposes a threshold for the value-to-weight ratio"
- ZCL algorithm: An online knapsack algorithm with a dynamic acceptance threshold and provable competitiveness. "A commonly known approach is the ZCL algorithm~\cite{zhou2008budget}"
Collections
Sign up for free to add this paper to one or more collections.

