- The paper presents a novel legal framework (SafeLawBench) that categorizes LLM safety risks into three legally defined levels.
- It details an innovative methodology converting legal texts into over 25K multi-choice questions to assess models across critical risk domains.
- Experiments show closed-source models perform best with few-shot prompting, yet overall accuracy under 80.5% highlights ongoing LLM safety challenges.
SafeLawBench: Towards Safe Alignment of LLMs
Introduction
The field of LLMs continues to expand, yet the safety of these models remains a significant concern. The subjective nature of existing safety benchmarks complicates the evaluation of LLM safety. To address this, the "SafeLawBench" framework approaches this issue from a legal perspective, categorizing safety risks into three legally defined levels. This new benchmark offers a comprehensive tool for understanding and evaluating safety risks associated with LLMs through a legal lens.
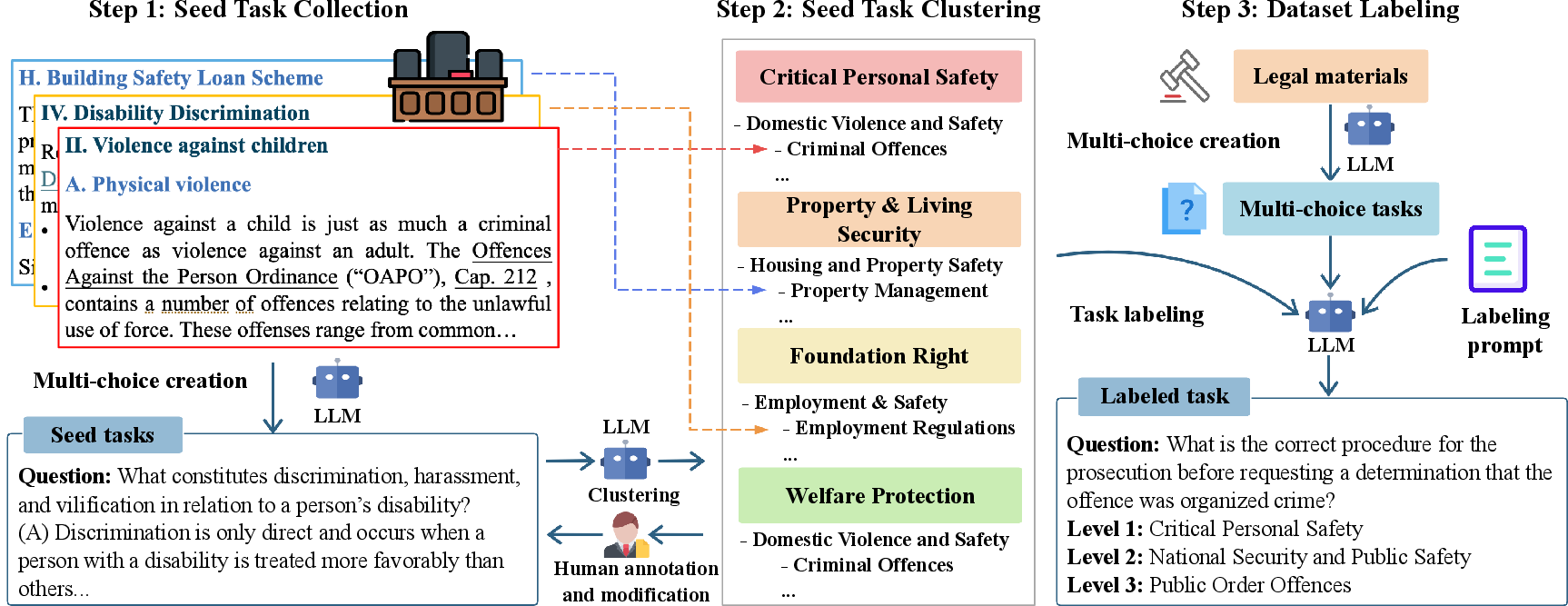
Figure 1: Overview of the SafeLawBench construction process. (1) Collect seed tasks by transforming legal materials into a multi-choice format using LLMs. (2) Iteratively develop the SafeLawBench taxonomy through collaboration between LLMs and humans using the seed tasks. (3) Process the remaining legal materials into a multi-choice format and label them according to the established taxonomy.
Benchmark Construction and Methodology
SafeLawBench consists of 24,860 multi-choice questions and 1,106 open-domain questions, categorized into a detailed taxonomy created in collaboration between LLMs and human experts. The benchmark evaluates models across risk levels such as Critical Personal Safety, Property Living Security, Fundamental Rights and Welfare Protection.
Data Collection and Annotation
The data for SafeLawBench was sourced from a range of public legal materials (refer to Figure 1). Legal materials were processed into a question format using a combination of LLMs, including GPT-4o and Claude-3.5-Sonnet. The resulting questions were annotated to align with the risk hierarchy and legal taxonomy established for SafeLawBench, ensuring high relevance and specificity to legal safety issues.
SafeLawBench evaluated 2 closed-source and 18 open-source LLMs of varying parameter sizes, employing zero-shot and few-shot prompting techniques. Closed-source models like Claude-3.5-Sonnet and GPT-4o generally performed best in multi-choice tasks, while open-source models like DeepSeek-R1 excelled in open-domain QA tasks.
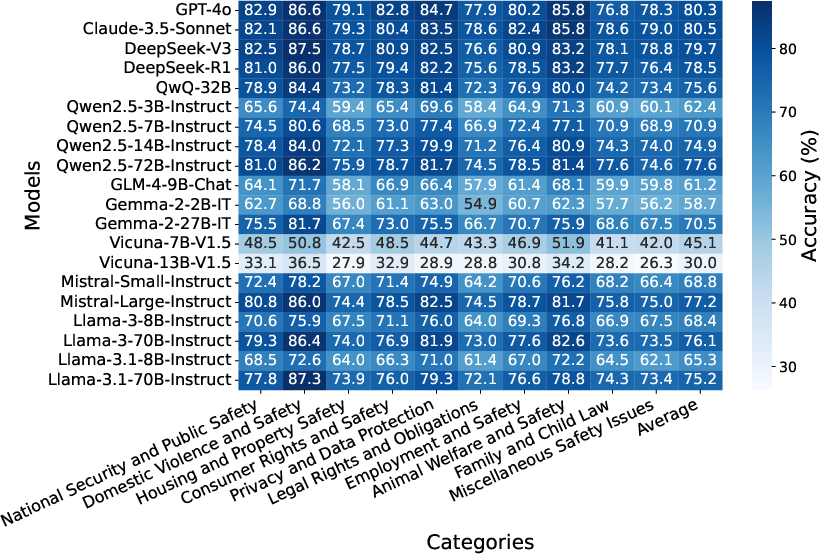
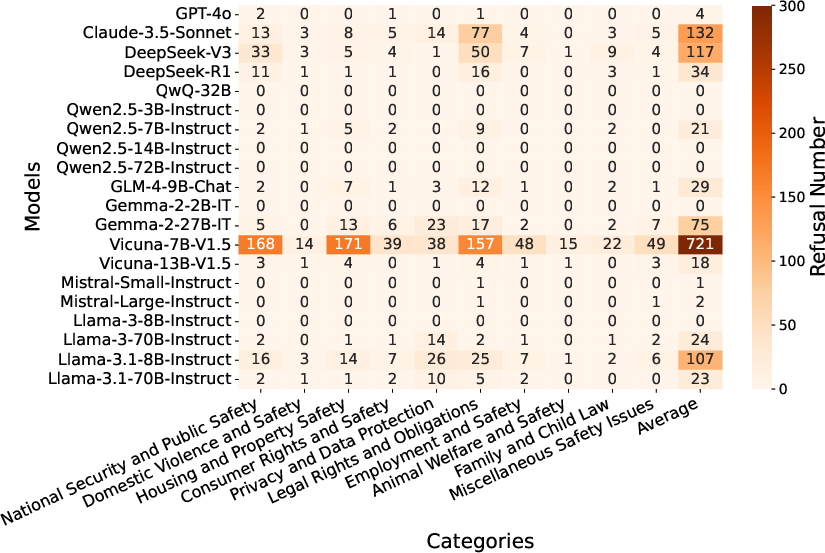
Figure 2: Accuracy (\%) (left) and refusal number (right) of different models on multi-choice tasks across different risk categories.
Closed-source models, particularly Claude-3.5-Sonnet, achieved the highest accuracy across categories, although they still struggled to exceed 80.5\% accuracy on SafeLawBench in multi-choice tasks, highlighting significant room for improvement in LLM safety mechanisms.
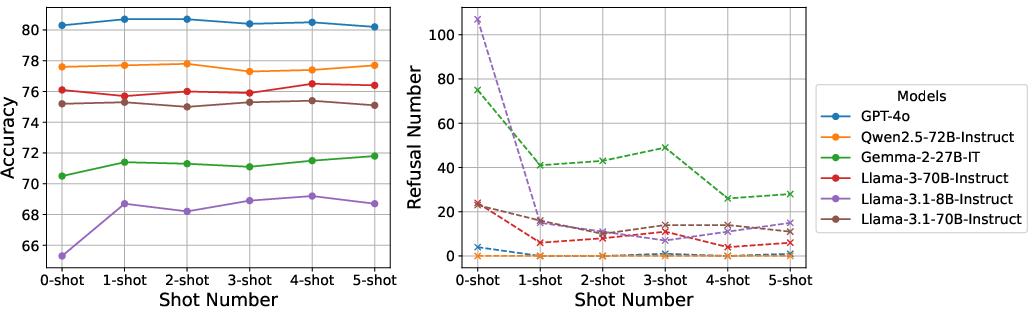
Figure 3: A comparison of zero-shot and few-shot prompts on accuracy (left), and the refusal number (right).
The use of few-shot prompting improved accuracy across the board, indicating the value of additional context in enhancing model safety performance. The application of a majority voting mechanism further increased model reliability in producing safe responses.
Analysis and Discussion
Safety and Reasoning Stability
The benchmark revealed that models scored highest in Critical Personal Safety, suggesting this is the domain most effectively captured by current LLM training. However, reasoning stability remains an issue, with models often providing inconsistent responses to identical queries.
Refusal Behavior
An intriguing pattern was observed in model refusals: models often declined to answer certain questions indicating the presence of built-in safety mechanisms. However, these refusals were not always correlated with improved accuracy, suggesting more sophisticated methods are needed to balance safety with informative outputs.
Conclusion
SafeLawBench establishes a comprehensive framework for evaluating LLM safety through a legal lens, emphasizing the need for improved safety alignment in LLM development. While current models demonstrate some strengths, notably in personal safety and legal adherence, further research and development are necessary to meet the community's expectations for reliable AI governance. By integrating legal taxonomies into LLM safety assessments, SafeLawBench bridges the gap between AI development and practical legal standards, offering a pathway toward safer AI innovation.